
18 Photos and videos












Go Kamoda retweeted

Mar 13
数学を解くLLM構築コンペ FT-LLM2026で,オープン部門1位,総合部門でも2位となりました!
Tohoku NLP+αで実現しうる最強メンバー(@mhida90, @onely7_deep @go2oo2 @muyo8692 @r_takahashi_h12 @y_aoneko @kyano__nlp @ma38taniguchi @t_ito0516 @KeisukeS_ @drJunSuzuki)による賜物です!
@tohoku_nlp


11
41
5,118
#NLP2026 では関わった3件の発表があります
宇都宮で会いましょう!
① SoftMatcha 2:柔らかいコーパス検索を1兆語規模へ拡張し、挿入・削除にも対応 (softmatcha.github.io/v2/)
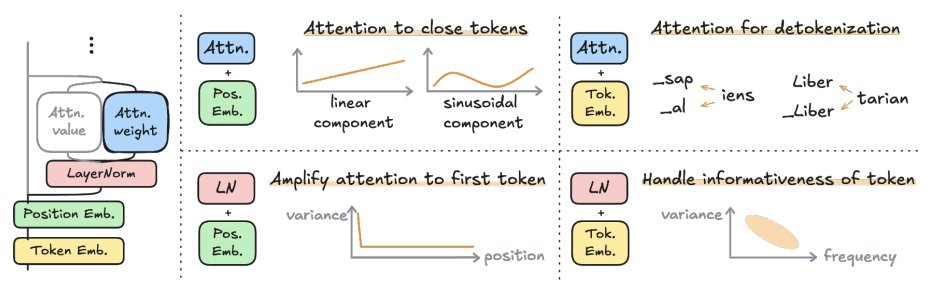
② Attention Sink には位置よりも自身への注意集中が効いている可能性
③ Attention sink からのValueベクトルは静的
1
8
33
6,622
🎉
① 優秀賞
② 若手奨励賞 to @raito_kiya
③ 若手奨励賞 to @satoki1049
FT-LLMコンペティション
オープン部門1位、総合2位
to Team dentaku
3
15
510
Go Kamoda retweeted

Mar 12
光栄なことに、#NLP2026 で若手奨励賞を受賞しました!
今後も、不思議な現象「Attention Sink」の発生機序に迫る面白い研究を目指します!
また、この場をお借りして、ご指導くださった共著の皆様本当にありがとうございました!

Mar 2

#NLP2026 にて,共著を含む計3件の発表を行います!
特に口頭発表は,選出率 4% (32/799) という貴重な機会をいただきました!
- 3/11(水) 11:15〜:ポスター発表
- 3/11(水) 09:30〜:共著論文(口頭発表)
- 3/12(木) 09:30〜:口頭発表 🎤
ぜひ足をお運びいただけると嬉しいです!

7
41
2,197




Go Kamoda retweeted
Mar 10
📢速報📢
第21回言語処理若手シンポジウム #YANS2026 について #YANS懇 で発表がありました!
会場:仙台国際センター(宮城県)
日時:2026年8月16日(日)〜18日(火)
詳細は本アカウントや yans.anlp.jp で随時発信予定です.みなさんお楽しみに🌱
30
52
26,323
Go Kamoda retweeted
Mar 2
#NLP2026 にて,共著を含む計3件の発表を行います!
特に口頭発表は,選出率 4% (32/799) という貴重な機会をいただきました!
- 3/11(水) 11:15〜:ポスター発表
- 3/11(水) 09:30〜:共著論文(口頭発表)
- 3/12(木) 09:30〜:口頭発表 🎤
ぜひ足をお運びいただけると嬉しいです!

#NLP2026 では,希望のあったうち特に優れたものを選考し,2月13日(金)頃にシングルセッションの口頭発表に招待する予定です.口頭発表シングルセッションはポスター発表4セッションと並列して実施します.詳細なプログラムは3月2日(月)にこちらに掲載予定です.
anlp.jp/proceedings/annual_m…
1
7
19
4,337
Go Kamoda retweeted

Mar 4
#NLP2026 にて,共著を含む計4件の発表があります!
ぜひ会場にお越しください!
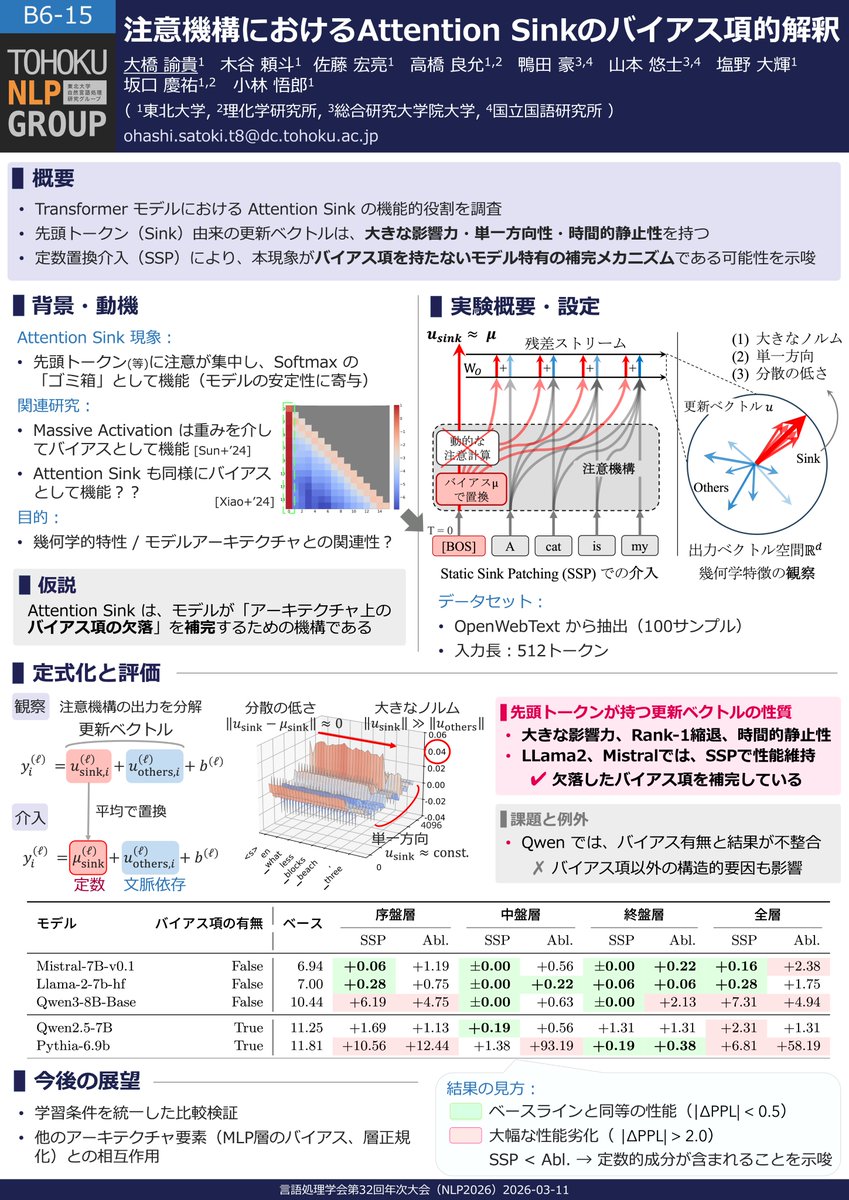
①Attention Sinkのバイアス項的解釈
- 3/11(水) 09:30〜:口頭🎤
- 3/11(水) 11:15〜:ポスター🖼
②Attention Sinkの発生機序
- 3/11(水) 11:15〜:ポスター🖼
- 3/12(木) 09:30〜:口頭🎤

7
27
3,851
言語処理学会4年目で今更ですが
この類の画像を作るのにかかる時間がもったいない気がしてきてスクリプト作成しました
よかったらどうぞ。
gokamoda.github.io/notes/nlp…

#NLP2026 では関わった3件の発表があります
宇都宮で会いましょう!
① SoftMatcha 2:柔らかいコーパス検索を1兆語規模へ拡張し、挿入・削除にも対応 (softmatcha.github.io/v2/)
② Attention Sink には位置よりも自身への注意集中が効いている可能性
③ Attention sink からのValueベクトルは静的
1
29
3,948
Go Kamoda retweeted

Feb 20
横井祥准教授、鴨田豪非常勤研究員が参画している共著論文が、「ITmedia AI+」で紹介されています。
itmedia.co.jp/aiplus/article…
8
27
7,967
Go Kamoda retweeted

Feb 12
Introducing SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Pre-Training Corpora
softmatcha.github.io/v2/
What lies within a trillion-scale pre-training corpus? Can you truly guarantee your benchmarks are uncontaminated simply because there are no exact string matches?
Alongside several research institutions in Japan, Sakana AI is proud to have collaborated in the development of SoftMatcha 2, an ultra-fast and flexible search tool that enables search over trillion-scale natural language corpora in under 0.3 seconds, even while handling semantic variations (substitution, insertion, and deletion). No existing tool meets all these criteria, including infini-gram-mini (EMNLP’25 Best Paper) or the original SoftMatcha (ICLR’25).
Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning.
As a practical application, we demonstrate that SoftMatcha 2 identifies potential benchmark contamination in pre-training corpora that existing exact-match approaches miss.
You can try searching through a 100B-scale corpus via our online demo. The system remains blazingly fast even on trillion-token corpora, so we encourage you to host it yourself for larger scales.
Demo: softmatcha-2.s3-website-ap-n…
Paper: arxiv.org/abs/2602.10908
Code: github.com/softmatcha/softma…
This work is a collaboration with researchers from the University of Tokyo, NII, Kyoto University, SOKENDAI, NINJAL, Tohoku University, and RIKEN.
16
84
463
88,830
Go Kamoda retweeted

Feb 12
巨大なLLM事前学習データを爆速で検索出来る「SoftMatcha 2」の開発に参加させてもらいました。デモ、論文、ソースコード等をこの度公開しましたので是非お試し下さい!
softmatcha.github.io/v2/
意味的類似性に基づいた置換や挿入削除に対応しながら1兆トークン規模のデータを0.1秒代で検索すると いうなかなか狂った性能になってます。EMNLP'25 Best Paperのinfini-gram-miniを含む既存のツール全てを大きく凌駕する性能だと思います。用途に特化したデータレイアウトを持つdisk-aware suffix arrayを使いながら、本来指数的になる置換・挿入・削除の候補を実データに基づきうまく枝刈りすることで高速な検索を達成してます。
この規模の事前学習データを検索出来ることの利点の事例として、論文ではベンチマークの汚染の検証をやってみてます。infini-gram-miniのような厳密な検索のみでは発見出来ないような汚染の事例なども有りそうでした。
現在デモでは数百Bトークン規模のデータからの検索を試せるようになってます。コードも公開してますのでご自身でホストしてもらうとより大規模なケースもお試し頂けます。
🌐 Demo: softmatcha-2.s3-website-ap-n…
📄 Paper: arxiv.org/abs/2602.10908
💻 Code: github.com/softmatcha/softma…
若き才能 @e869120 を始めとするSoftMatchaチームの方々との協働はとても刺激的で多くの学びがありました。楽しかった〜!ありがとうございました! @shiatsumat @go2oo2 @ksuenaga @MasWag @sho_yokoi
Feb 12

1兆語規模のコーパスから0.1秒単位で用例検索できるツールができてしまいました。意味的な置換・挿入・削除にも対応。
世界の Takuya Akiba と ICPC 史上初世界2位に輝いた E869120 のガチプロ2名にジョインいただき、動くわけがないと思っていたサイズでなぜか動いてます。遊んでみてください。
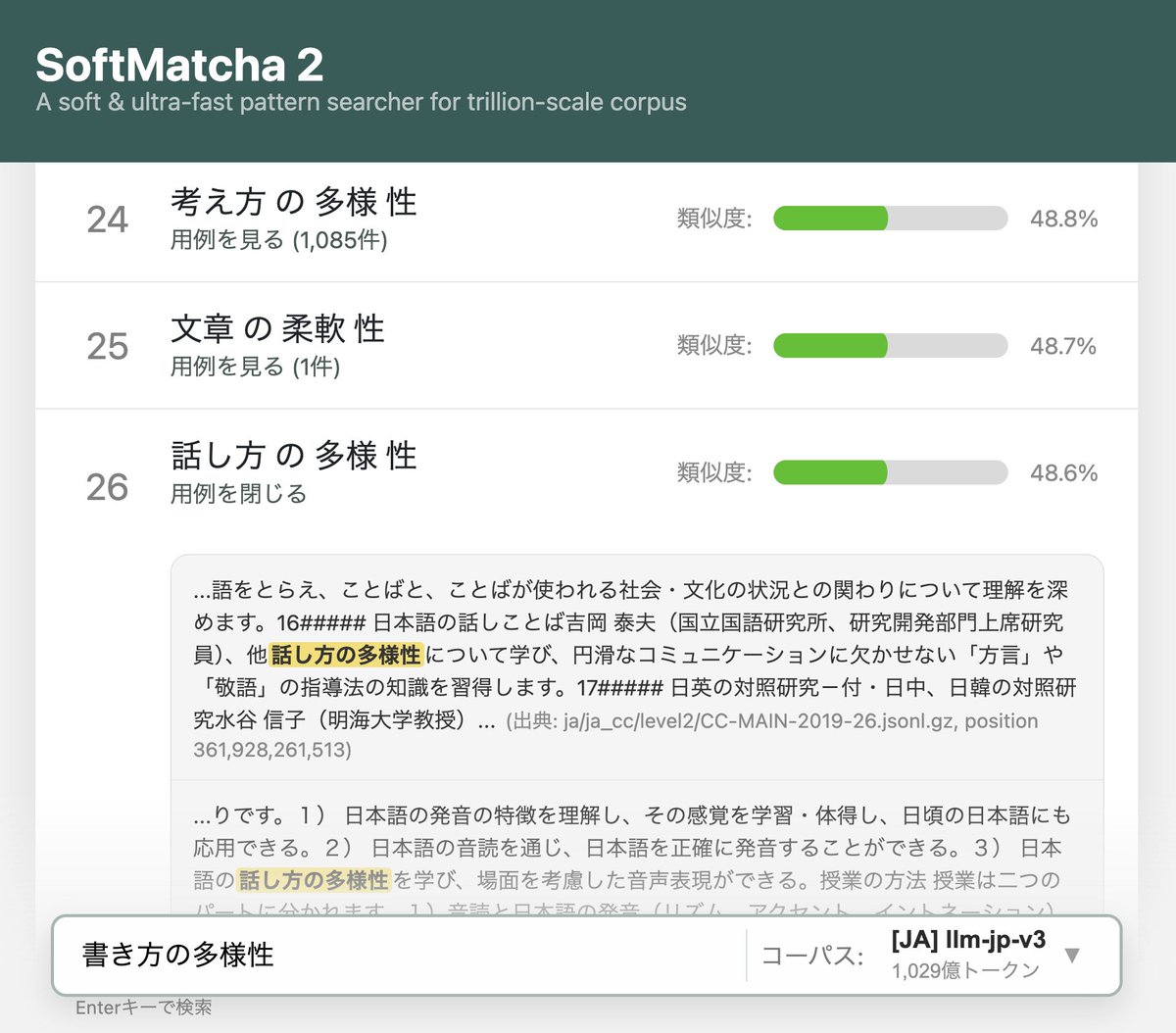
ALT SoftMatcha 2 の検索結果:「書き方の多様性」から「話し方の多様性」や「文章の柔軟性」がヒットしている様子
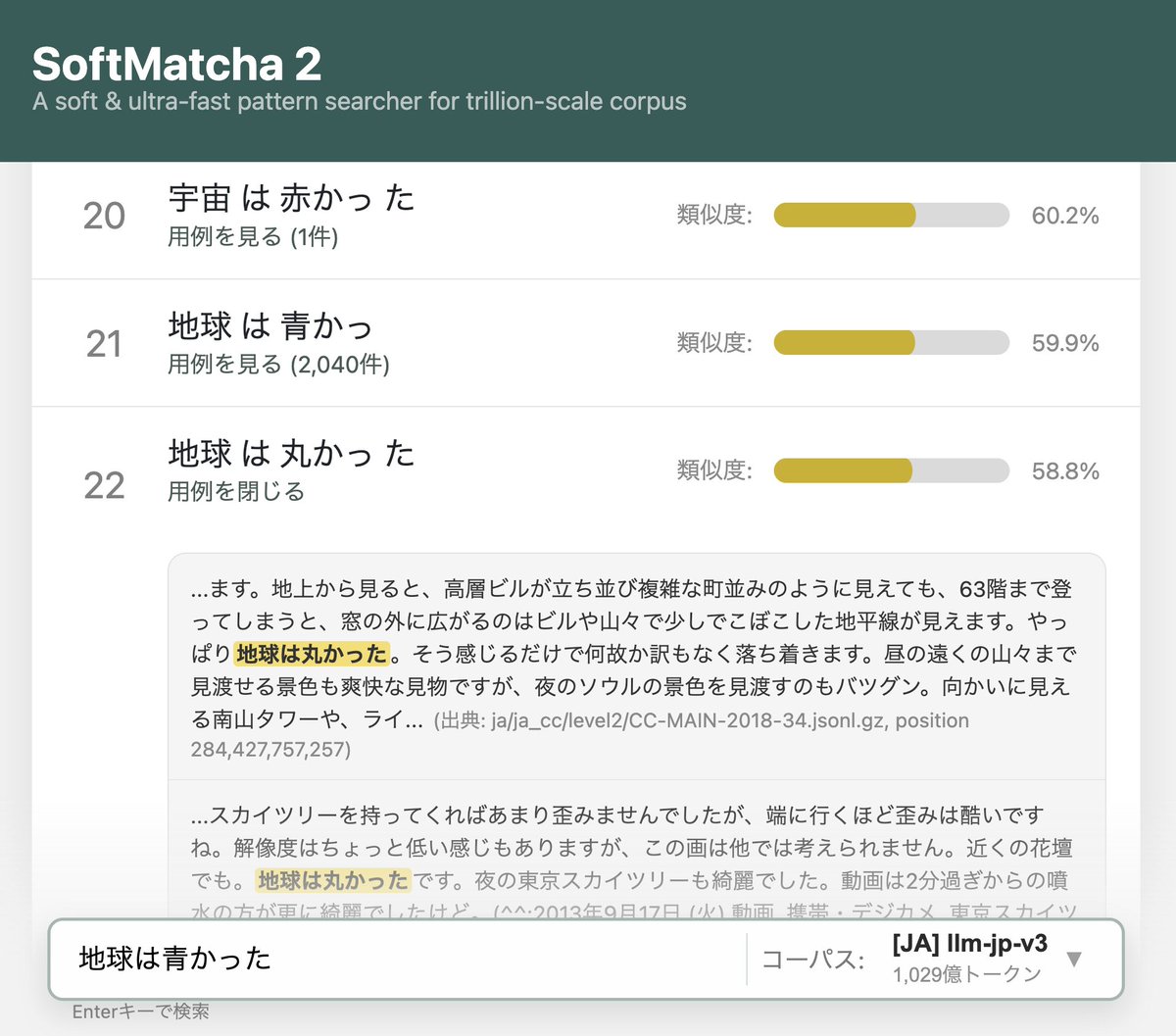
ALT SoftMatcha 2 の検索結果:「地球は青かった」から「地球は丸かった」がヒットしている様子

ALT SoftMatcha 2 の検索結果:「AIは世界を変えるか」から「ディープラーニングが世界を変える。」がヒットしている様子
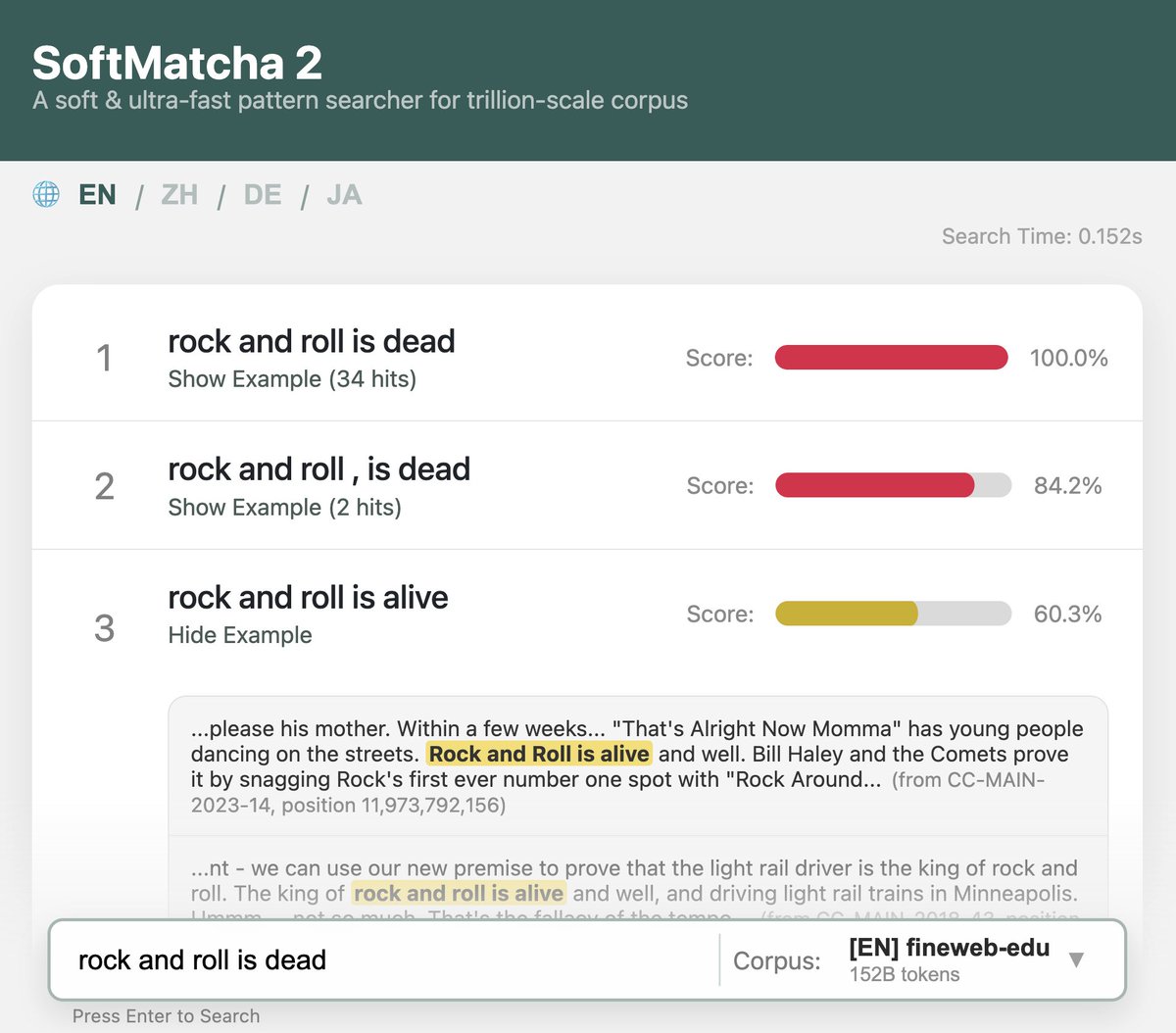
ALT SoftMatcha 2 での用例検索:「rock and roll is dead」から「rock and roll is alive」がヒットしている様子
4
255
1,149
249,277

Go Kamoda retweeted

Feb 12
🍦 SoftMatcha 2 プロジェクトページ: softmatcha.github.io/v2/
🗣️ 今週末 2/14 の #言語学フェス と、それから 3/10 に #NLP2026 でも発表します。遊びにきてください。
(言語学フェス)
sites.google.com/view/lingfe…
soft-monarch-ccb.notion.site…
(NLP)
anlp.jp/nlp2026/
anlp.jp/proceedings/annual_m…

ALT SoftMatch 2: 言語学フェス2026(2026-02-14)のA-12(午前の部)にて発表予定

ALT SoftMatch 2: 言語処理学会年次大会2026(2026-03-10)のQ1-5(午前の部)にて発表予定
1
53
210
31,141
Go Kamoda retweeted
Feb 12
1兆語規模のコーパスから0.1秒単位で用例検索できるツールができてしまいました。意味的な置換・挿入・削除にも対応。
世界の Takuya Akiba と ICPC 史上初世界2位に輝いた E869120 のガチプロ2名にジョインいただき、動くわけがないと思っていたサイズでなぜか動いてます。遊んでみてください。
ALT SoftMatcha 2 の検索結果:「書き方の多様性」から「話し方の多様性」や「文章の柔軟性」がヒットしている様子
ALT SoftMatcha 2 の検索結果:「地球は青かった」から「地球は丸かった」がヒットしている様子
ALT SoftMatcha 2 の検索結果:「AIは世界を変えるか」から「ディープラーニングが世界を変える。」がヒットしている様子
ALT SoftMatcha 2 での用例検索:「rock and roll is dead」から「rock and roll is alive」がヒットしている様子
1
445
2,149
439,286
Go Kamoda retweeted

27 Oct 2025
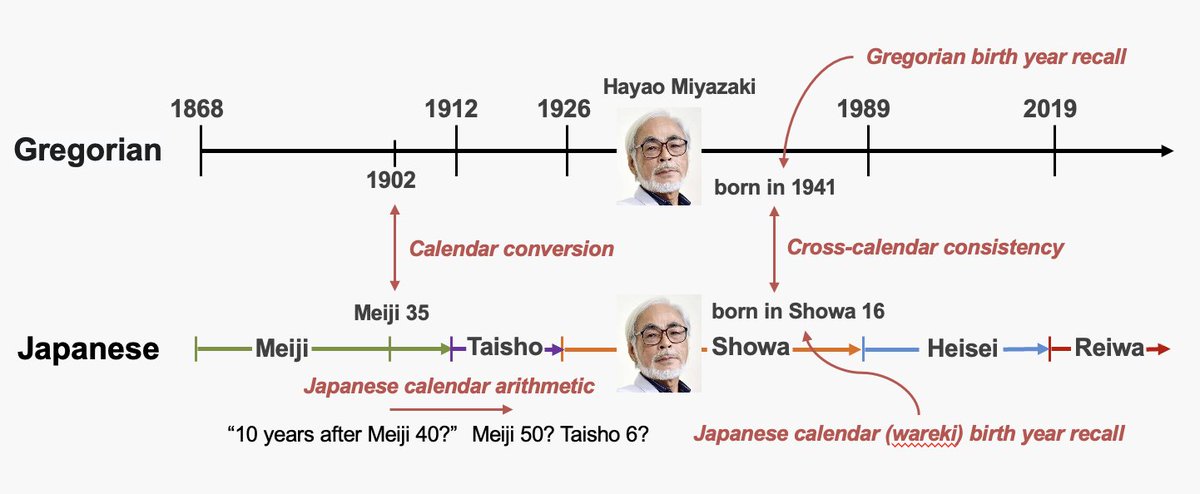
"Can Language Models Handle a Non-Gregorian Calendar?"が #AACL2025 のmainに採択されました🎉 w/@go2oo2 @r_takahashi_h12 @keiskS @inuikentaro @benbenhh (@tohoku_nlp)
LMの時間推論研究のグレゴリオ暦偏重を指摘し、日本人1億超が扱う和暦を題材にLMが非グレゴリオ暦を扱う能力を調べました。
1
5
44
5,019
3月のNLPで発表した(共著)ものです
私個人も(は)
文字単位モデルの色々気になるなぁ
でもUnicodeポイントをそのまま使うのは色々問題が起きるなぁ
byteなら埋め込み行列が256で済むなぁ
そういえばデジタルデータって、バイト列で表せるなぁ
などの妄想をしながら議論/設計/構築してました
19 Sep 2025

byte tokenizerを採用したBERT (4モデル) と,同じくbyte tokenizerを採用した実験的なMulti-LM-head日本語言語モデルを公開しました.
byte tokenizerを使った 変な言語モデルに興味がある方がいらっしゃればぜひ触ってみてください!
huggingface.co/collections/t…
huggingface.co/collections/t…
1
11
1,926