
Joined May 2014
- Tweets 859
- Following 547
- Followers 286
- Likes 6,384
206 Photos and videos







i14 Journal Club: Foundation Models Where Math Meets Cognitive Science
i14 is launching a weekly online discussion group for researchers exploring the intersection of generative AI, mathematics, and cognitive science. We analyze how architectural design impacts learning, memory, and reasoning in foundation models.
Join us to dissect training dynamics and explore how cognitive principles can inform the next generation of architectures.
Our next session will be hosted via Google Meet on: Sunday, April 13 · 12:00 PM AEST (Melbourne) which is Sunday, April 13 · 10:00 AM CST (Shanghai) which is Saturday, April 12 · 7:00 PM PDT (San Francisco)
Apply to join HERE: i14.ai/journal-club/
5
5
103

Mar 31
We're building something different at @i14labs — and the people who get it tend to find each other. Researchers, engineers, curious minds: apply to join our journal club to go deep into the building blocks of LLMs.

i14 Journal Club: Foundation Models Where Math Meets Cognitive Science
i14 is starting a weekly online discussion group for AI researchers and engineers exploring the intersection of generative AI, mathematics, and cognitive science. We analyze how architectural design impacts learning, memory, and reasoning in foundation models.
Join us to dissect training dynamics and explore how cognitive principles can inform the next generation of architectures,
with our first session hosted via Google Meet on
Monday, March 30 · 12:00 PM AEDT (Melbourne time), which is
Sunday, March 29 · 6:00 PM PDT (San Francisco time)
Apply to join HERE:
i14.ai/journal-club/
1
4
44
Massimo Bardetti retweeted

21 Oct 2025
At NEMES nemes.app/, we're building a future where young hackers can create DIY brain wave kits.
Imagine, teenagers exploring their own cognition through games, just like Neha's pioneering research.
1
3
137
Massimo Bardetti retweeted
28 Oct 2025
I recently spoke at @gamesforum in SF
I discussed how curriculum should adapt to each student. I learned that great games need years of experiments. Ads must fit the game's story. Metrics like ARPUU and ROAS are vital. Segmentation is also key to understanding players.

1
1
6
260
19 Oct 2025
First time writing a C lambda function and using the auto keyword.
Its like writing Javascript...
This is to test the MLX library mlx::compile functionality.
2
15
2,315
19 Oct 2025
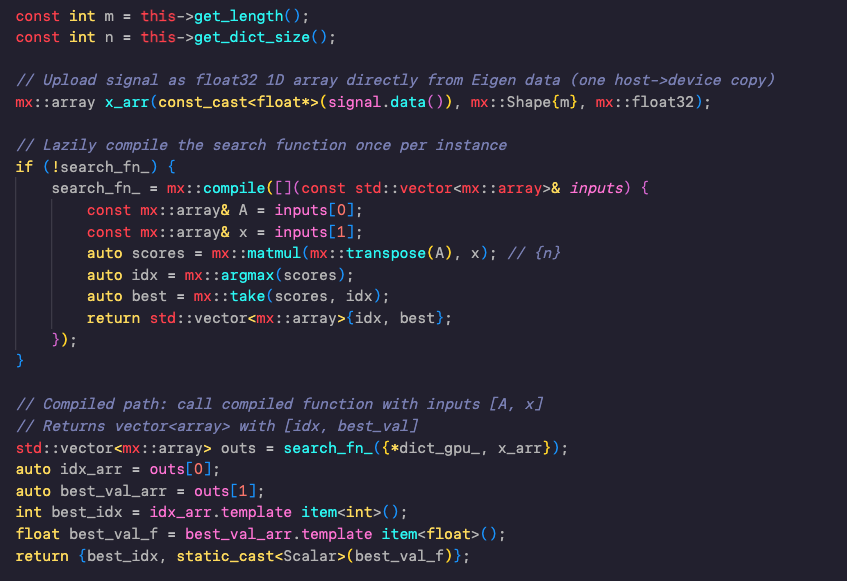
Continuing my side quest into the Apple MLX library...
First I wanted to test mlx::compile from c , then I wanted to compare the performance of the mlx CUDA backend with a cuBLAS version of the algorithm.
The core algorithm is quite simple, a matmul and a argmax, the two versions are in the picture.
My test results showed the cuBLAS version performing approximately 20% faster than MLX with CUDA... I wanted to know why.
1
3
26
2,023
19 Oct 2025
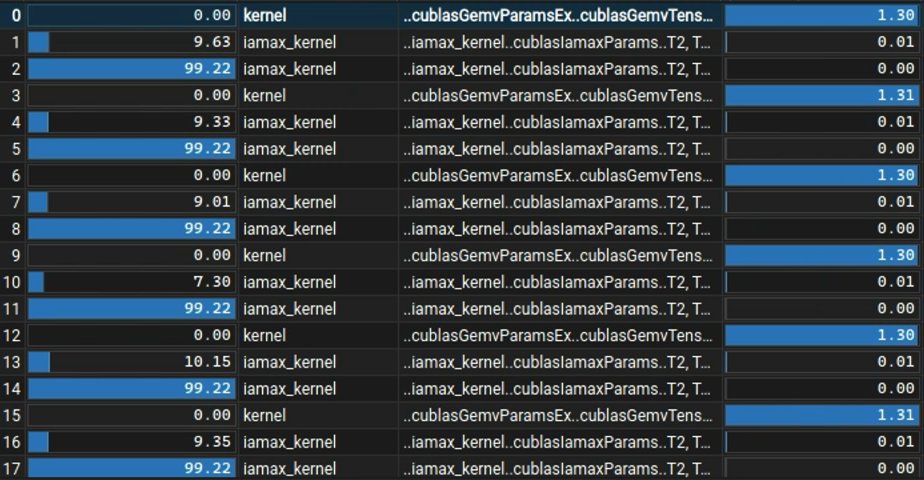
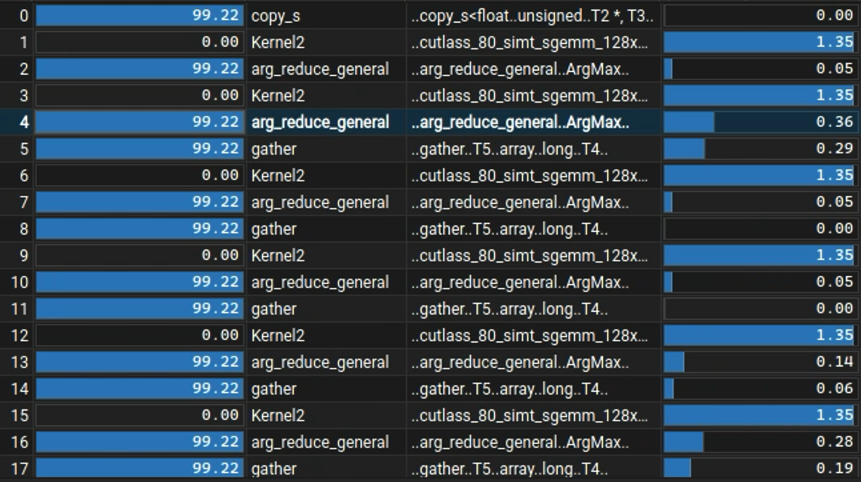
I used NVidia ncu to profile my test code, and discovered how the two implementations differ slightly.
Seems like the arg_reduce_general gather of MLX is not as fast as iamax (multipass?) of cuBLAS.
For now, this is how far I got to.. more to come as I take a look at the MLX kernels.
1
3
225
10 Oct 2025
This is a very interesting paper which formalizes the way myself, and probably many other AI engineers, been optimizing the prompt context.... by just changing sections of it.
I, very early on, realized that having an orchestrator LLM rewrite the whole prompt, is just moving the problem up one level.
On a positive note I hope that AI agents will expand out of the systems engineering and MLOps/DevOps field, and begin to be formalized and be used to replicate human brain models from cognitive science.
9 Oct 2025

RIP fine-tuning ☠️
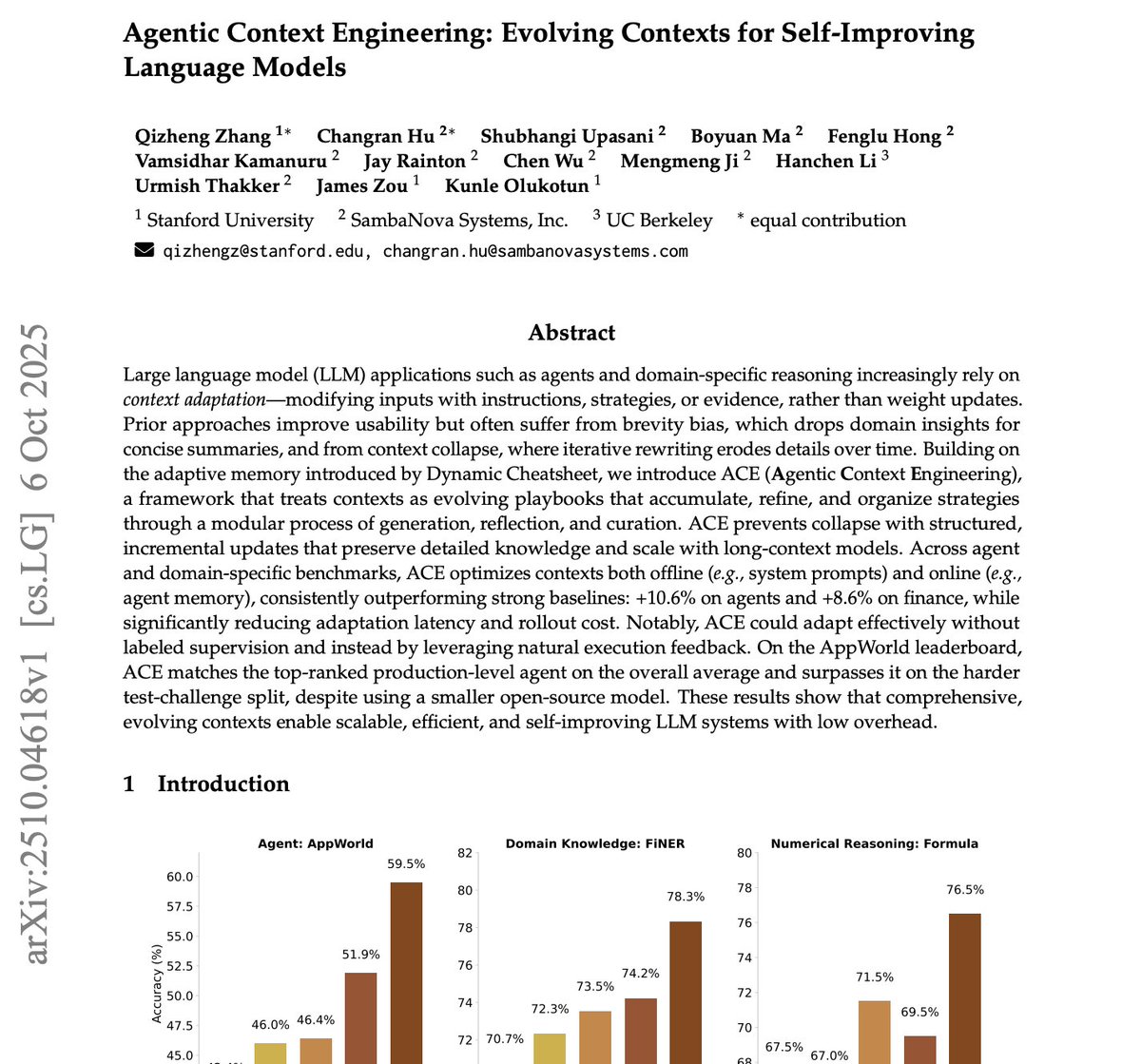
This new Stanford paper just killed it.
It’s called 'Agentic Context Engineering (ACE)' and it proves you can make models smarter without touching a single weight.
Instead of retraining, ACE evolves the context itself.
The model writes, reflects, and edits its own prompt over and over until it becomes a self-improving system.
Think of it like the model keeping a growing notebook of what works.
Each failure becomes a strategy. Each success becomes a rule.
The results are absurd:
10.6% better than GPT-4–powered agents on AppWorld.
8.6% on finance reasoning.
86.9% lower cost and latency.
No labels. Just feedback.
Everyone’s been obsessed with “short, clean” prompts.
ACE flips that. It builds long, detailed evolving playbooks that never forget. And it works because LLMs don’t want simplicity, they want *context density.
If this scales, the next generation of AI won’t be “fine-tuned.”
It’ll be self-tuned.
We’re entering the era of living prompts.
1
1
158
Massimo Bardetti retweeted

29 Sep 2025
New in-depth blog post time: "Inside NVIDIA GPUs: Anatomy of high performance matmul kernels". If you want to deeply understand how one writes state of the art matmul kernels in CUDA read along.
(Remember matmul is the single most important operation that transformers execute both during training and inference. Most of NVIDIA compute is spent on it. Gaining 1% in efficiency translates to massive savings in the order of many nuclear reactors :P)
I, yet again, realized i underestimated the effort. 😅 Here is one more booklet (lol). 47 figures!
I covered:
* The fundamentals of the GPU architecture with an emphasis on the memory hierarchy, building mental models for GMEM, SMEM, and L1/L2, and then connecting them to the CUDA programming model. Along the way we also looked at the "speed of light," how it's bounded by power, with hardware reality leaking into our model.
* PTX/SASS, and how to steer the compiler into generating what we actually want (is that loop being unrolled, are we using vectorized loads like LDG.128, etc.). I've annotated one PTX/SASS example for a simple matmul kernel in excruciating detail. Even if you're new to compilers you should find this useful.
(i actually found various inefficiencies in both compilers - fun!)
* Many core concepts such as tile/wave quantization, occupancy, ILP (instruction-level parallelism), roofline model, etc. Also building intuition around fundamental equivalences: dot product as a sum of partial outer products, why square tiles are the right shape for high arithmetic intensity, etc.
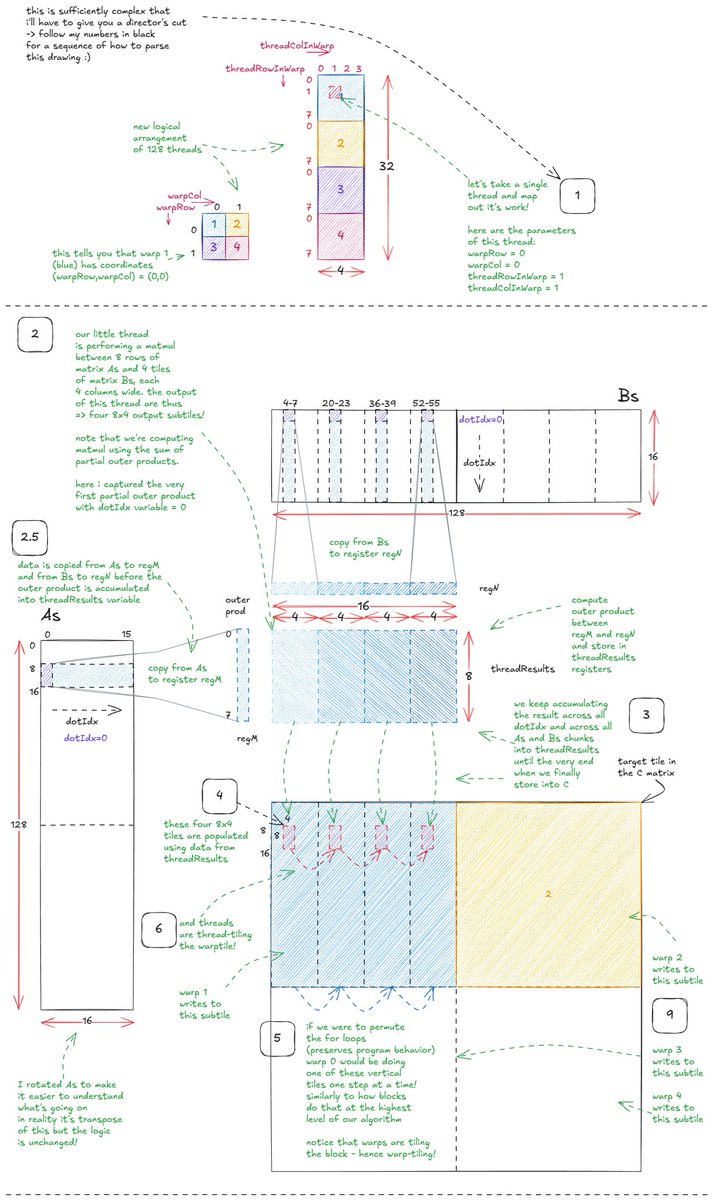
* The warp tiling method - which is near SOTA assuming you can't use tensor cores, TMA, async mem instructions, and bf16. Just maximizing GPU's performance using nothing but CUDA cores, registers and shared memory.
* Finally, we step into Hopper (H100): TMA, swizzling, tensor cores and the wgmma instruction, async load/store pipelines, scheduling policies like Hilbert curves, clusters with TMA multicast, faster PTX barriers, and more.
As always lots of examples, lots of visuals. This is the first time i could see warp tiling kernel and be like "oh i get it completely". I just needed my mental image transformed into an actual image.
A few years ago I was really inspired by @Si_Boehm's excellent blog post on how matmul works, but I also found it had several errors, some unclear explanations, and it was quite outdated. Building on @pranjalssh amazing work (who did a great job building sota kernels for H100) and my own research, this is the final result.
---
Again a huge thank you to @Hyperstackcloud (GPU cloud) for giving me an H100 (PCIe) node to run some of the experiments and analysis that i needed to write this up.
Also a big thank you to my friends Aroun (who did a very thorough review of the post; Aroun's doing cool GPU/AI stuff at Magic and was previously GPU architect at Apple and Imagine, he's one of the best GPU people i know and we worked together on llm.c w/ @karpathy) and the amazing @marksaroufim! (PyTorch) for taking the time during weekend when they didn't have to. :)
50
389
2,534
282,299
4 Oct 2025
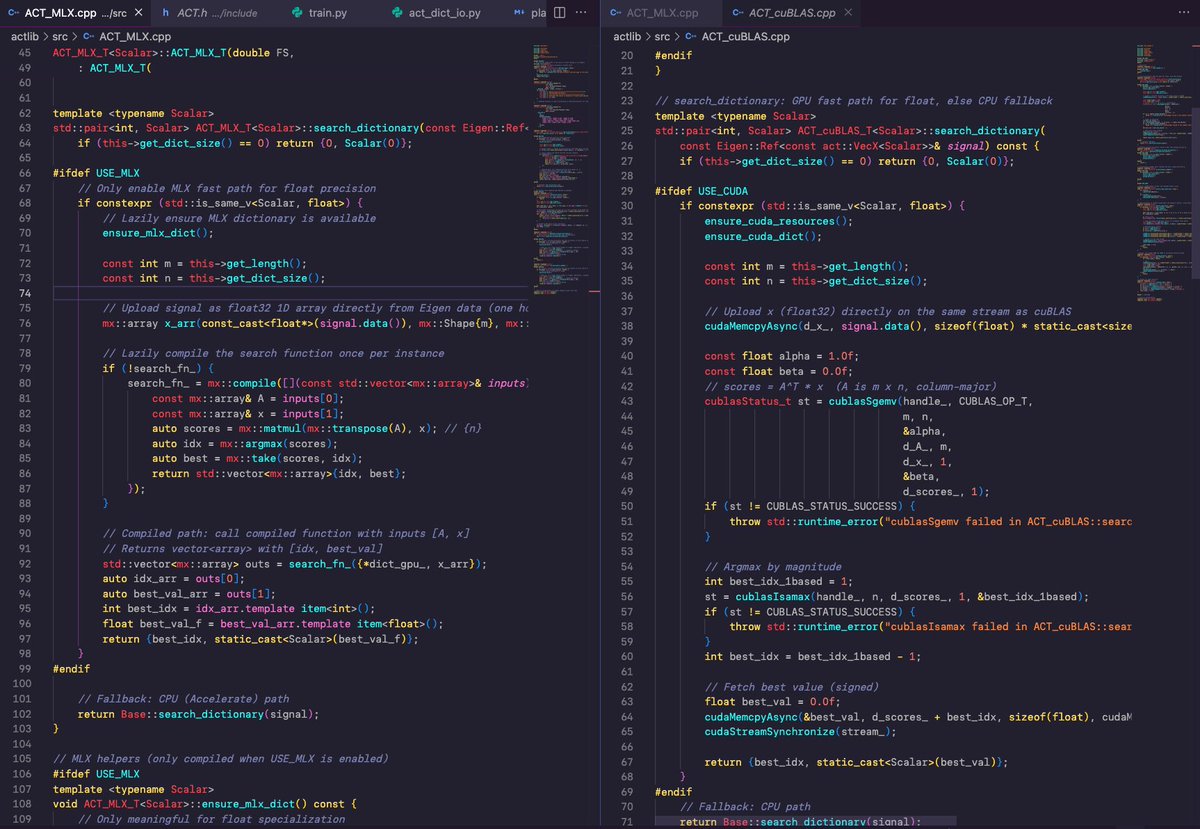
The Apple MLX library is very handy! It has Apple Metal and CUDA backends, and can be easily cross-compiled on MacOS and Linux.
Here is my implementation of a matching pursuit dictionary search, which is a greedy inner product of a source signal over a multi dimensional matrix of atoms.
The code compiled effortlessly on my Macbook Pro M1 Max, and a Ubuntu Linux Intel i9 with NVidia RTX4090 GPU, with the GPU branching fully working.
I tested it successfully on a dictionary of 600K atoms (1.1GB in memory).
11
24
398
32,302
4 Oct 2025
I have been working on an algorithm to decompose a signal into "chirplets" primitives, i.e. the Adaptive Chirplet Transform.
I was researching EEG signal analysis, and an expert in the field pointed me to a few studies that used the chirplet transform to analyze EEG brain signals.
It turned out to be a very interesting programming challenge, as only a handful of public reference implementations are available, mostly Matlab code.
I decided to write a C version of the ACT algorithm, that I could also use as an introduction to CPU and GPU hardware acceleration, which led me to BLAS and Apple MLX libraries.
1
4
212
4 Oct 2025
Notes on my progress here : byron-the-bulb.github.io/
Github repo here : github.com/nemes-inc/ACT-lib
2
51
2 Oct 2025
In case you ever wondered what a brain sounds like, here is an audio-synthetical interpretation of a mathematical dissection of the digitized electrical signals emitted by my brain a few days ago.
Details in reply.
1
3
59
25 Sep 2025
Working with Unreal Engine to prototype various materials and colors.
The neuromodulation unit will sit on the forehead of the user and we are exploring using a Neoprene layer to house the two stimulating electrodes for added comfort.
3
7
416
20 Sep 2025
The OMY UP! neuromodulation device is taking shape ... and textures.
Coming soon!
6
128
23 Aug 2025
The life of founders Friday night at 10PM.
We will need our BCI device to recover...
This tweet is unavailable
1
1
1
105
21 Aug 2025
We have been working on a low cost, open sourced, BCI device with the purpose of providing easy access for folks to play with NeuroTech.
We have designed a custom ESP32C3 based board with EEG signal processing and transcranial direct current stimulation (tDCS) which will enable users to analyze brain states and stimulate with safe current levels.
Open source hardware, open source firmware and open source brainwave analysis platform!
To make it fun we will have custom 3D printed shells ... personally I can't wait to put a tiny LCD screen on one of those that displays my state of mind.


5
116