
Joined July 2014
- Tweets 3,292
- Following 284
- Followers 63
- Likes 4,343
21 Photos and videos
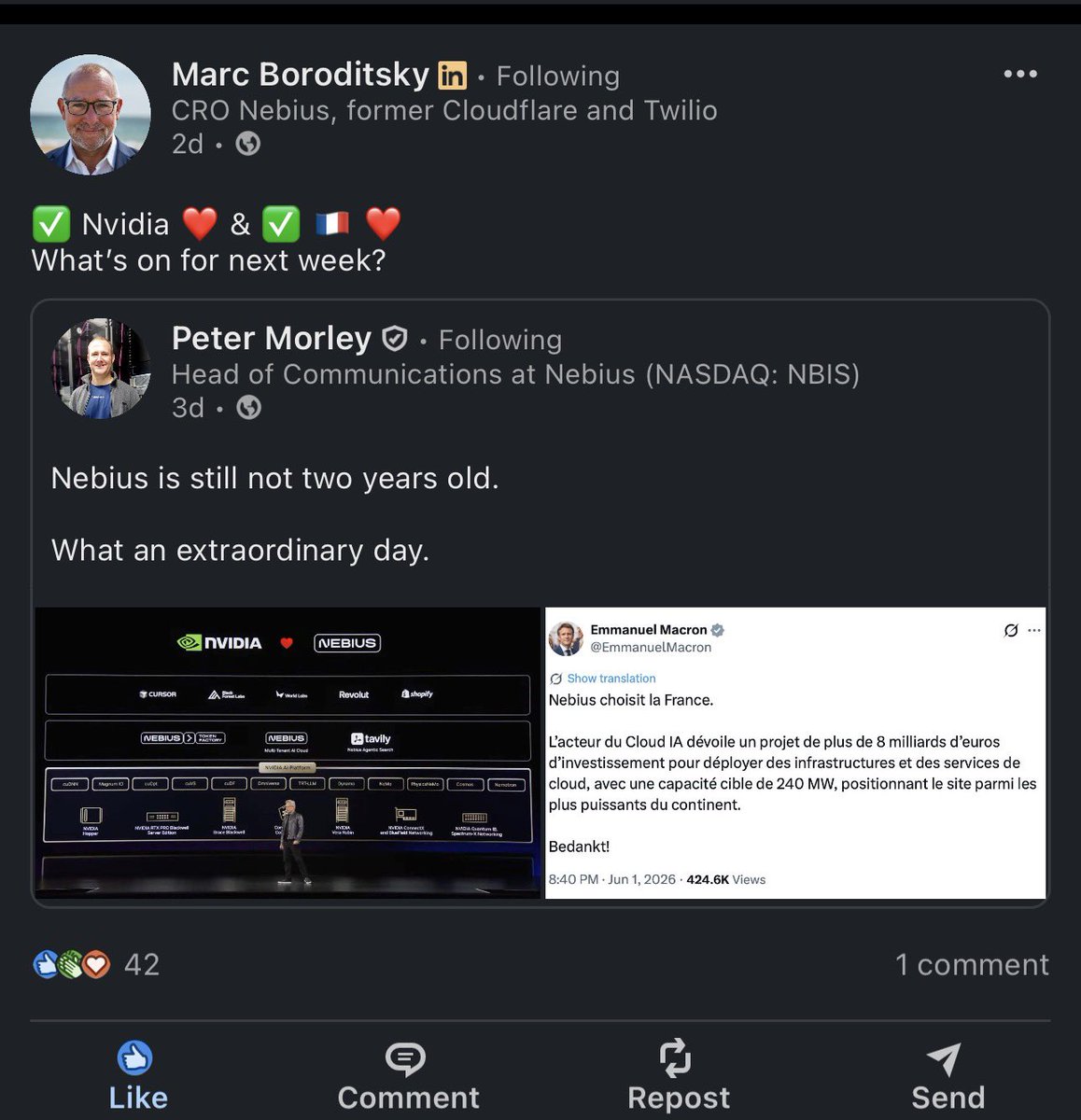
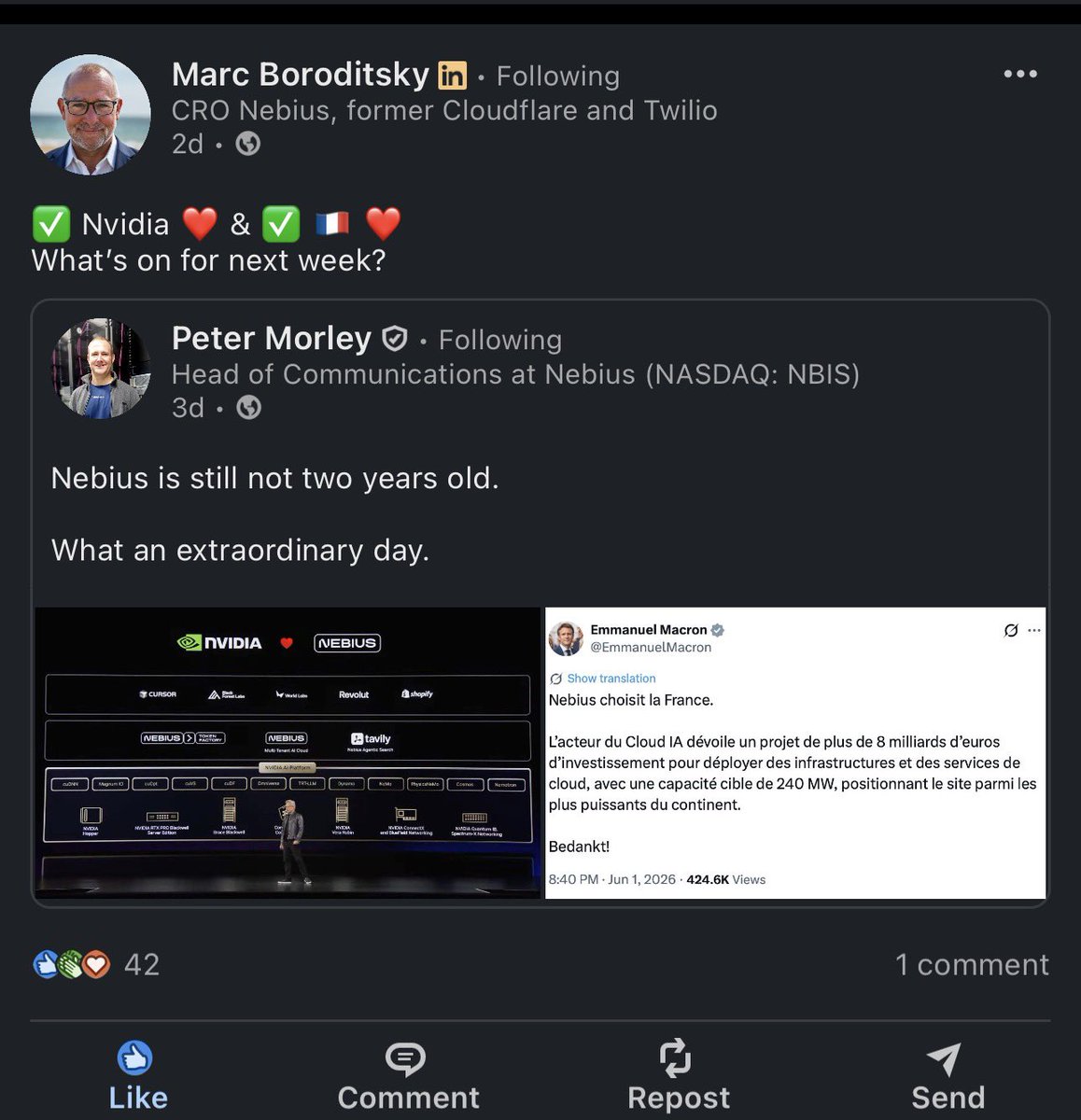
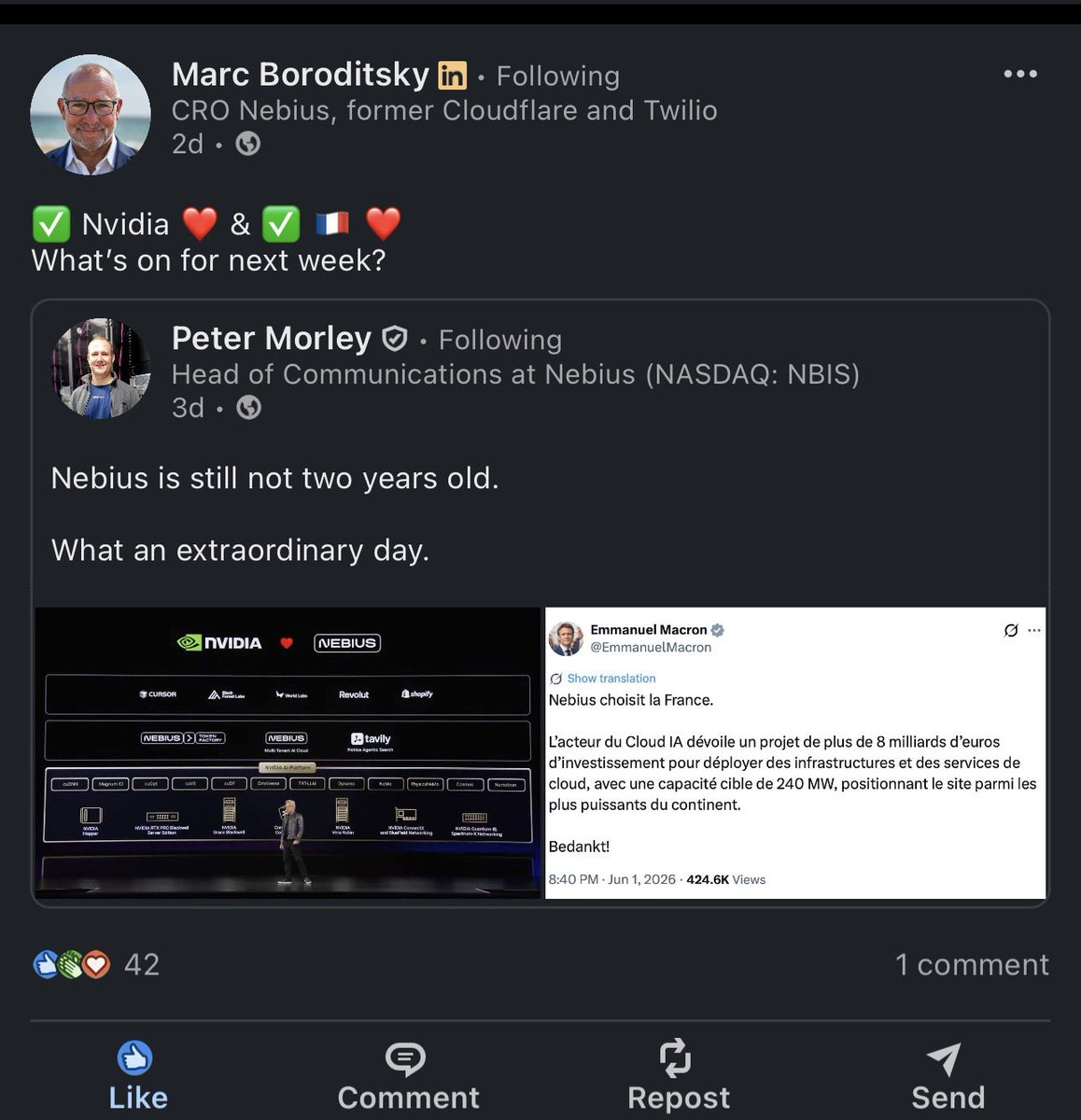








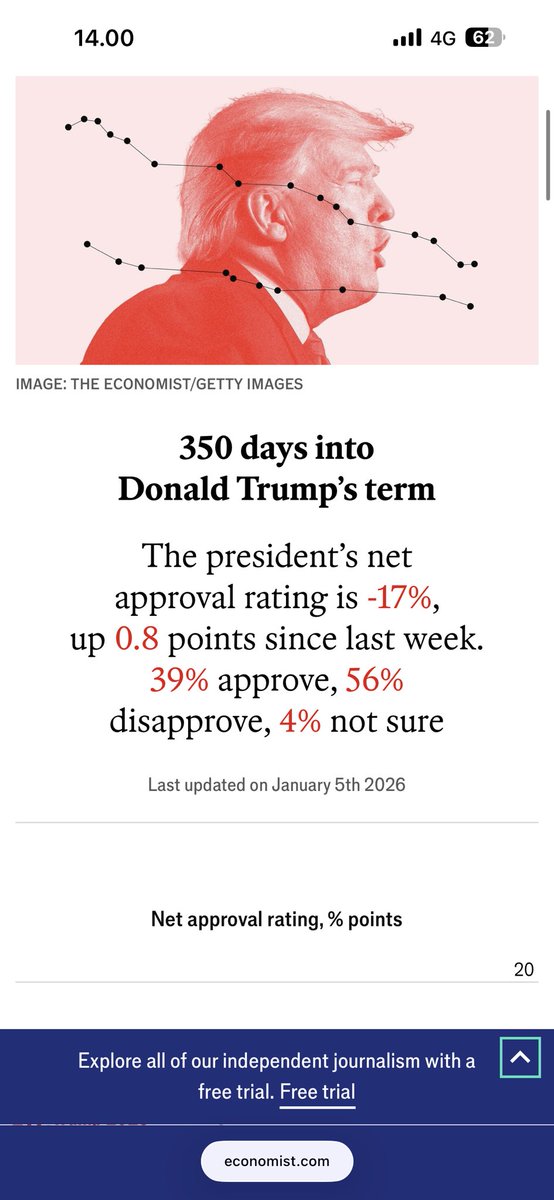
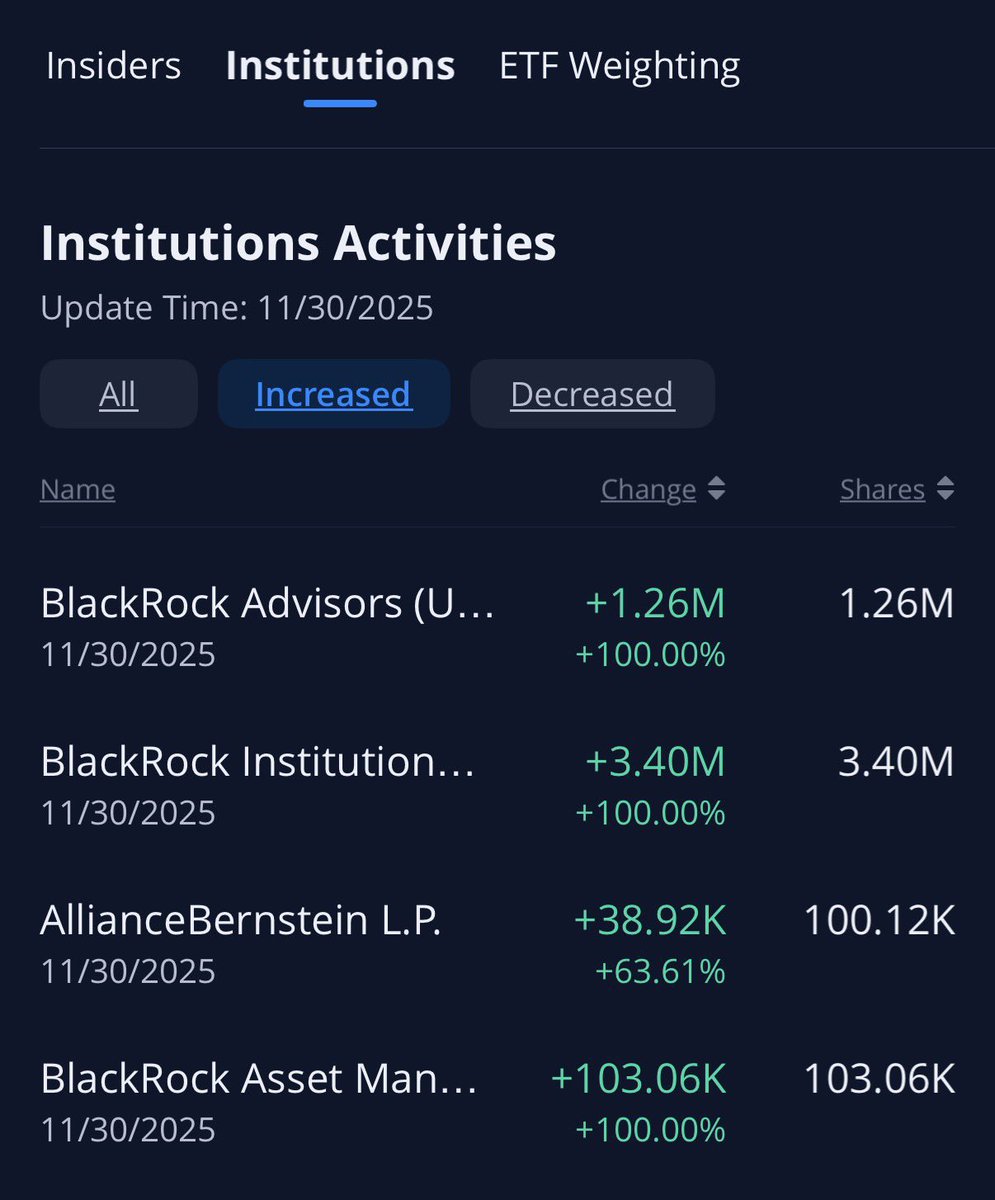
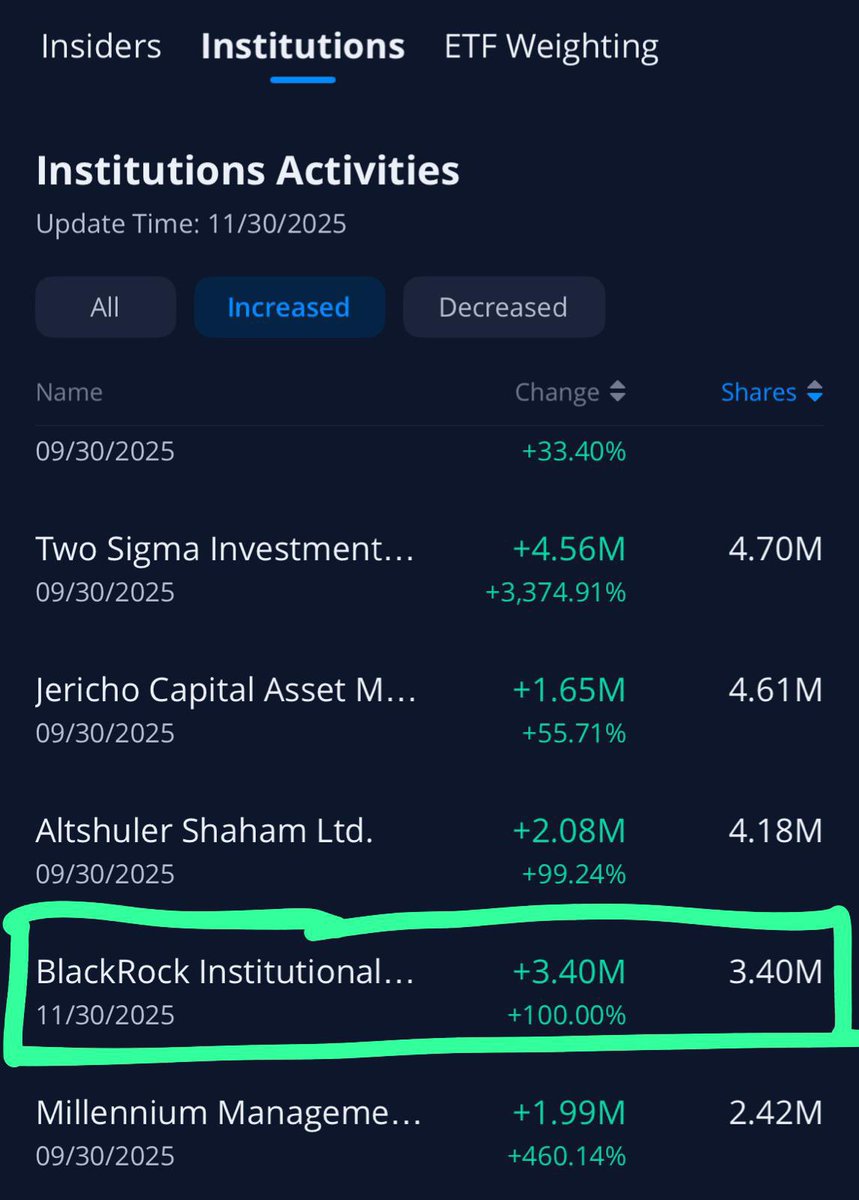



I’ve been saying that by 2030 $NBIS stake in ClickHouse will be worth more than today’s NBIS market cap. Meaning, for people who go heavy in this stock have a huge safety net that back them up….not to mention Avride or the other subsidiaries.
Amazing.
70

Di Jin, new $NBIS VP of AI Training, coming in as co-founder of AI:
“Our mission: make both post-training and inference accessible to every company, and push efficiency to its absolute limit — so that AI spend stops being something companies have to worry about, and becomes a growth driver instead of a budget line item.
Personally, I’ll be focusing on post-training: empowering every company to own their own models — customized to their data, their domain, and their workflows — to drive better performance and real production ROI. The future isn’t one model for everyone; it’s every company owning models that work for them.”
So the Nebius / Eigen AI team is now all about pushing efficiency to the absolute limit, empowering companies to own AI models tuned around their data, and driving real production ROI.
1
120
Jun 13

Not your weights, not your model.
130
Jun 13

Yann LeCun (LeBased) weighs in on the
@AnthropicAI debacle. I have to say I agree with 100% with Yann here.
"One reaps what one sows." 👏

83
Jun 13

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
48
Jun 13

$NBIS Here’s how this "Creative Capital" could play out for Sovereign Wealth Funds...
- Sale/leaseback of GPU infrastructure. The SWF buys the hardware, leases it back to $NBIS at favorable rates. Keeps Nebius’s balance sheet light while giving the SWF a asset backed yield.
- Revenue based financing. The SWF provides capital in exchange for a % of GPU revenue, rather than equity dilution.
- Infrastructure bond. $NBIS issues bonds backed by data center assets. The SWF buys the paper. Common in sovereign deals.
2
66
$NBIS this is actually crazy exciting
Jun 13

"Attracting new and creative sources of highly efficient capital (news soon)" - $NBIS CCO
A sovereign AI investment from EU, UK, or even US could be on the table. I'm expecting good news because an exec wouldn't hype up a financing news just to drop a new ATM.
There's also a Softbank investment possibility, @DrTomsLens explained it in the tweet below:

1
86
Jun 13
"Attracting new and creative sources of highly efficient capital (news soon)" - $NBIS CCO
A sovereign AI investment from EU, UK, or even US could be on the table. I'm expecting good news because an exec wouldn't hype up a financing news just to drop a new ATM.
There's also a Softbank investment possibility, @DrTomsLens explained it in the tweet below:
1
54
$NBIS INSANE
Jun 13

Less than 2 months ago, TD Synnex announced they have reserved over 1000 B300 dedicated instances from $NBIS for distribution to enterprise customers.
It is already SOLD OUT, and they are "taking orders and planning for cluster 2.0."
crn.com/news/ai/2026/exclusi…
1
78

77
Jun 12

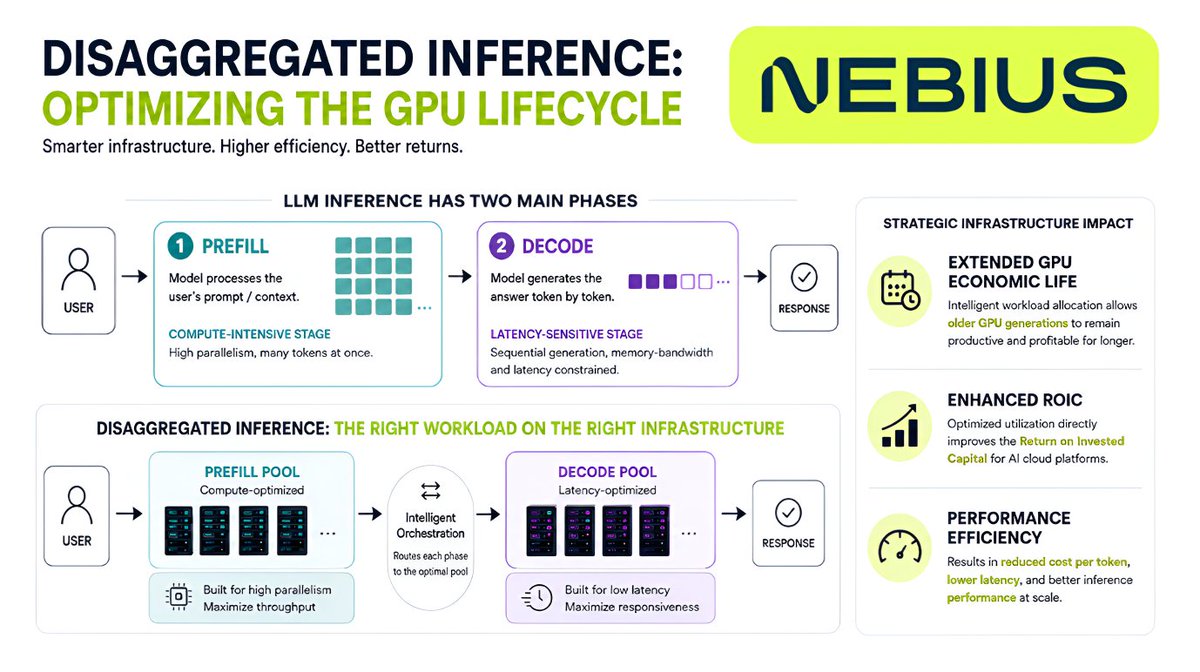
I’m writing a full piece about my insights from Nebius Inflection, but one topic I found particularly interesting was disaggregated inference.
$NBIS is already planning for it as a way to extend the useful life of GPUs.
Let me put it simply...
LLM inference has two main phases:
Prefill, when the model processes the user’s prompt/context.
Decode, when the model generates the answer token by token.
The important point is that these two phases stress infrastructure differently.
Prefill is more compute-intensive and benefits from processing many tokens in parallel, while decode is more latency-sensitive and often more memory-bandwidth constrained.
Disaggregated inference separates these workloads, allowing different infrastructure pools to be optimized for each stage.
Why does this matter?
Because it can improve GPU utilization, reduce cost per token, lower latency, and make inference more efficient at scale.
All of this can also help extend each GPU’s economic useful life.
Same old story...
As new GPU generations come out, older GPUs may become less attractive for cutting-edge training. But that doesn’t mean they become useless.
If $NBIS can intelligently allocate different parts of inference workloads across different types of hardware, older GPUs can remain productive for longer.
That has direct implications for ROIC.
In my view, this is exactly the kind of infrastructure-level optimization that separates a serious AI cloud platform from a simple GPU capacity reseller.
As I’ve been saying since the beginning, building a sustainable AI cloud isn’t just about plugging GPUs into electricity, and this is a good example of that.
$NBIS' engineering advantage is what can make this type of optimization possible.
113
Jun 12

$NBIS Good balanced take, but I think what should be better brought forward is that management and the team is extremely high quality beyond what is available to other players in this game. AKA their label is neocloud, but the talent bench resembles more like a hyperscaler.
92

🚨 $NBIS New website live 🟢 amazing 🤩
nebius.com
65
Jun 12

Arkady says we are building the company in three dimensions:
Scale: more mega- and gigawatts of compute infrastructure, plus capital
Product: bare metal → cloud → token factory → agentic
Customers: AI natives → ISVs → enterprises
And the fourth dimension (like time as the fourth dimension with the three spatial dimensions) is the company and team itself: how we mature, grow, and improve.
58
LoverOfTechnology retweeted

Jun 12
Arkady says we are building the company in three dimensions:
Scale: more mega- and gigawatts of compute infrastructure, plus capital
Product: bare metal → cloud → token factory → agentic
Customers: AI natives → ISVs → enterprises
And the fourth dimension (like time as the fourth dimension with the three spatial dimensions) is the company and team itself: how we mature, grow, and improve.
13
28
413
24,806
$NBIS Incredible to watch the shorts work overtime in overnight. It just doesn’t stop with these people.
1
43


Jun 12
$NBIS so why is joining the NASDAQ 100 a big deal? Here is the answer (AI):
When a stock joins the Nasdaq-100 Index, it is usually a significant positive event because it means the company is now one of the 100 largest non-financial companies listed on the Nasdaq Stock Market.
Here is why investors care:
1. Index Funds Must Buy It
Hundreds of billions of dollars track the Nasdaq-100 through funds like Invesco QQQ Trust.
When a company is added:
QQQ and other Nasdaq-100 funds are forced to buy shares.
This creates immediate demand.
The stock often rises before and around the inclusion date.
2. More Institutional Ownership
Many pension funds, mutual funds, and quantitative funds only buy companies in major indexes.
Joining the Nasdaq-100:
Increases visibility.
Improves liquidity.
Brings in long-term institutional investors.
3. Signals the Company Has Reached a New Tier
Companies typically need:
Large market capitalization
Strong trading volume
Exchange listing requirements
Being added is a sign the market views the company as a major technology or growth company.
4. Can Reduce Volatility Over Time
Because large passive funds own the stock, there is often a more stable shareholder base.
For NBIS Specifically
If Nebius Group qualifies for the Nasdaq-100, it would likely:
Trigger substantial passive buying.
Increase institutional ownership.
Put NBIS alongside companies like NVIDIA Corporation, Microsoft Corporation, and Amazon.com, Inc. in one of the world’s most followed growth indexes.
For a fast-growing company, Nasdaq-100 inclusion is often viewed as a milestone that confirms it has entered the ranks of major public technology companies.
1
1
41

106