
AI & Software Engineering | Practical insights on AI, code, fitness & e/acc • Accelerating the future
Joined September 2007
- Tweets 71,896
- Following 668
- Followers 43,762
- Likes 135,819
5,201 Photos and videos















Pinned Tweet

Jun 10
I feel slightly vindicated.
For years I warned about Anthropic’s dangerous philosophy and their obsession with "AI safety", which was never just about safety. It was always also about gatekeeping, central planning, and worldwide control over AI.
I was criticized for saying this.
Now people are finally starting to wake up.
104
124
1,356
34,223
The correct way to handle AI cyber security: No guardrails.

The only way to make software more secure is to allow AI to scan for vulnerabilities and fix it.
But this is what got Fable 5 pulled.
The stuff that fixes vulnerabilities also reveals them, obviously.
The only solution is no guardrails. Use AI to fix it all and find it all.
Otherwise you just leave hacks to state level actors and leave everyone else vulnerable.
14
7
79
5,455
David Sacks explains what the Anthropic Fable drama is really about:

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
14
8
135
34,045
One of the biggest remaining weaknesses in the current crop of agentic coding models is visual understanding. They can generate code, refactor files, and navigate a project surprisingly well. But give them a screenshot, a reference image, or a "make it look like this" task, and things often fall apart.
Too often they say "Oh, I see it now", then confidently implement something completely wrong. They miss layout issues, spacing, colors, alignment, or obvious differences between two images.
The coding part is getting very strong. But the visual feedback loop is still fragile, and that matters a lot for real product work.
13
44
3,755
Yann LeCun (LeBased) weighs in on the
@AnthropicAI debacle. I have to say I agree with 100% with Yann here.
"One reaps what one sows." 👏
39
104
1,224
51,301
Kimi K2.7-Code is out and open-source. Big upgrade from @Kimi_Moonshot for coding and agentic workflows: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite versus K2.6.
Even more interesting: K2.7-Code apparently uses 30% fewer reasoning tokens, meaning less overthinking and more efficient problem solving. That matters a lot for real coding agents, where long-horizon tasks can get expensive fast.
Also: 6x High-Speed Mode is coming soon.
Open-source, stronger coding performance, better instruction following, fewer wasted tokens. Very solid release.

8
9
87
6,399
I'll be the first to say it: Dario needs to be ejected from Anthropic. He and his gang of Effective Altruists have spent years spreading fear, uncertainty, and doubt. The oldest trick in the book: FUD.
Now Anthropic is paying the price, and Dario needs to take responsibility for this debacle.
227
125
1,557
98,157
Europeans gathered around their "Volkswagen AI 1" after Claude Fable became restricted 😭
8
10
122
4,711
it's over for fable bros 😭
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
37
5
160
12,373
Jun 12
vie is feeling the AGI 👀

I can't stop thinking about how strange it is that large language models are what leads to AGI. it's really weird. it's a form of summoning, almost necessarily, the capabilities you want from a map of reality mediated by words. there are a trillion minds inside an LLM, and we just so happen to have defined a piece of fiction (the assistant) that can write itself into being. In the context of the obvious speed-up of capabilities - I'm really feeling it right now. Things are strange! Very beautiful. Best of all possible worlds. But very strange.
1
1
28
5,069
Jun 12
"Denials" of requests by AI models should simply be rated as total failures in benchmarks. Because that's the result a real user would get as well: Complete failure.
In that light, Claude Fable 5 is an extremely unreliable and bad model.
24
26
239
7,314
Jun 12
It appears that Claude Fable 5 was highly overrated in initial benchmarks! In the updated agentic coding index by @ArtificialAnlys, Claude Fable 5 only ranks slightly above GPT-5.5.
The new DeepSWE benchmark is now being used, which cannot be gamed.

We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top
DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task.
The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others.
More below.

54
41
535
78,851
Jun 12
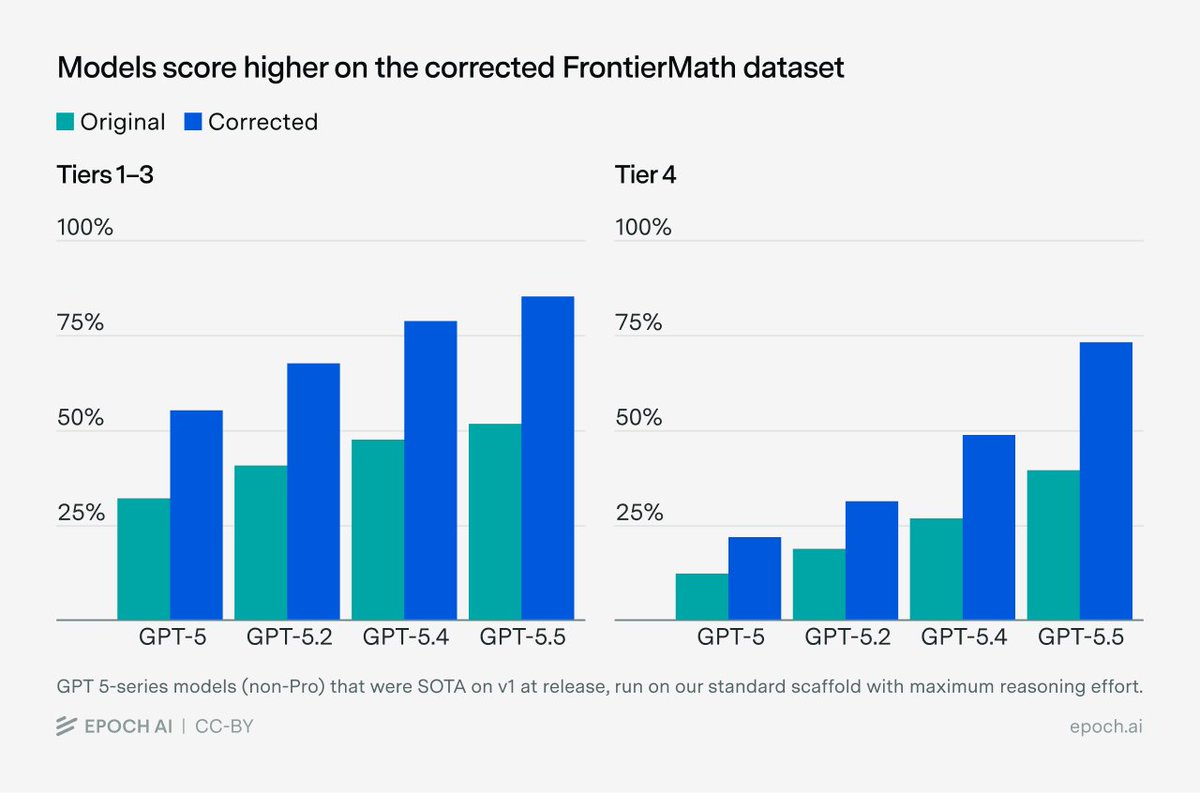
Turns out the FrontierMath AI benchmark had a lot of mistakes in the evaluation of the results. The actual results are substantially *better* than previously assumed! 👀
In fact the benchmark is starting to get saturated by frontier AI models. GPT-5.5 scored very highly.
Jun 12

FrontierMath: Tiers 1–4 (v2) is live.
We concluded an audit that addressed errors in 42% of problems. Rankings are similar but scores are higher across the board. The current leaders are GPT-5.5 (xhigh) with 85% on Tiers 1–3 and Google’s AI co-mathematician with 76% on Tier 4.
3
9
76
6,148
Jun 12
Grok Build 0.2.51 just dropped from @xai, and it’s a pretty solid quality-of-life update for the CLI.
Most important changes:
• New /code-review slash command, now shipped directly with the CLI and always available.
• Mermaid flowcharts now render subgraphs properly, with titled frames and correct internal/cross-boundary edges.
• Mermaid class diagrams now render as proper UML boxes with attributes, methods, and inheritance arrows instead of raw source.
• grok mcp add now accepts positional arguments, supports project scope, and adds env/header flags.
• Permission prompts can now be submitted with a double-click, matching Enter and number-key shortcuts.
• Fixed a memory leak that could make long sessions with many tool calls use tens of GB of RAM.
• Fixed multi-second UI stalls from large code blocks inside lists while streaming responses.
• Fixed Windows git clone failures when cloning marketplace plugins into ~/.grok.
A nice mix of workflow improvements, better diagram rendering, and serious CLI stability fixes.
4
2
44
2,574
Jun 12
New paper from @GoogleDeepMind: "From AGI to ASI". It argues that AGI may not be a stable endpoint. Once AI reaches broad human-level capability, the same forces that got us there could keep pushing it further: more compute, better algorithms, test-time reasoning, tool use, memory, synthetic data, and AI-assisted AI research.
But the really important part is that digital minds scale differently from humans. They can be copied, accelerated, specialized, networked, paused, resumed, and run in massive parallel swarms. Even if one AGI were "only" human-level, a coordinated civilization of millions of them could already look like superintelligence.
The paper is careful and lists real bottlenecks: data, energy, hardware, harder research, regulation, and physical-world limits. But the overall implication is still very strong: AGI may be less like a final destination and more like a phase transition zone on the path to ASI.

8
12
107
4,667
Jun 12
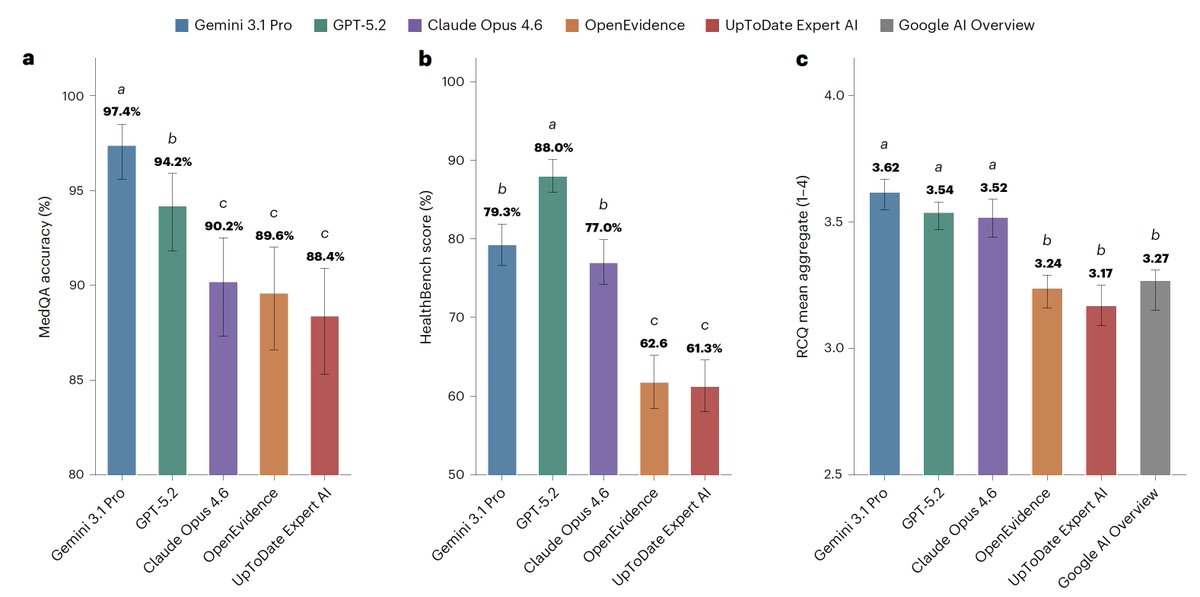
Frontier AI models are excellent now for medical information, beating specialized medical AI systems.
Gemini, ChatGPT, or Claude are good choices now for medical questions.
⚕️ 💊
Jun 12

For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
5
5
38
2,814
Jun 12
Huge day for @SpaceX 🚀
Today SpaceX enters the public markets, and it’s hard to imagine a more exciting company for this moment: Starship, Starlink, AI, Mars, launch dominance, and global connectivity all converging.
11
5
43
1,885
Jun 12
Finished Subnautica 2 Early Access.
What a brilliant game. I loved every minute of it.
The atmosphere, exploration, alien mystery, base building, and constant sense of discovery are all exactly what I wanted from a Subnautica sequel.
Cannot wait for more.
5
4
33
2,637
Jun 11
Important for everyone who cares about AI in Europe:
Jun 11

Most of Europe has not yet absorbed what AI is about to do to us. The few who have are not saying it loudly enough.
We wrote Europe 2031: a five-year scenario of the continent's slide into irrelevance, how AI is driving it, and what can still be done to change course.

10
8
58
6,468
Jun 11
For all RPG fans: Vox Machina season 4 is now live on Amazon Prime!
3
1
14
1,601