
Founder of @humancoders • Phoenix, Rails and WebGL developer • Art : @MatthieuArt
Joined May 2009
- Tweets 2,322
- Following 663
- Followers 2,117
- Likes 5,429
36 Photos and videos












Matthieu Segret retweeted
Une explication bien faite du fonctionnement interne des LLMs : tokens, embeddings, positional encoding, attention, feed-forward…
0xkato.xyz/how-llms-actually…

1
5
37
2,271
Matthieu Segret retweeted

Jun 13
Bottega, l'outil d'orchestration d'agents de code de Vincent Daubry, est désormais open source — après 1 000 user stories livrées en production.
vdaubry.github.io/bottega-la…

3
6
33
3,396
Matthieu Segret retweeted

Jun 10
mlx-vlm v0.6.3 is here 🚀
Day-0 support for TWO new models from our partners we work closely with:
🔥 @GoogleDeepMind DiffusionGemma — a genuinely new architecture. Instead of token-by-token, it generates 256-token blocks in parallel with bi-directional attention and iteratively self-corrects the whole block, image-generator style. 26B MoE, only 3.8B active, fits in 18GB quantized. Day-0 MLX support via our Google DeepMind partnership, with long-context prefill tuned and ready.
🔥 @cohere's North Mini Code 1.0 — a 30B MoE with just 3B active, running ~66 tok/s in BF16 before any compression. Day-0 on MLX thanks to our close collaboration with the Cohere team.
Get started today — install from source:
> uv pip install -U mlx-vlm
Then serve the model and point your favorite agent at it (pi, opencode, hermes, etc.):
uv run mlx_vlm.server --model MODEL-REPO
Model collection 👇🏽
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
12
18
136
15,009

Text Diffusion — une approche de génération de texte par diffusion, présentée par Google DeepMind
youtube.com/watch?si=GEm31rd…
1
39
Matthieu Segret retweeted

Jun 5
Vous maîtrisez les bases de Claude Code ? Voilà 3 manières de monter d'un cran :
→ industrialiser Claude Code (MCP, sous-agents)
→ construire un workflow multi-agents en équipe
→ concevoir vos propres agents, jusqu'en prod
Où vous voulez aller 👇
blog.humancoders.com/apres-f…
2
4
306
Une conf très intéressante sur l'utilisation de l'IA agentique chez Doctolib. Je remarque deux points qui reviennent assez souvent : la spéc devient centrale et les agents de plus en plus asynchrones.
Vous faites le même constat ?
youtube.com/watch?si=670Y1Xl…
1
72
Matthieu Segret retweeted
May 19
« Vous avez formé mes devs sur Claude Code. Vous pourriez aussi former mon équipe marketing ? »
On l'entend toutes les semaines depuis un an. Alors on a construit une vraie offre.
7 formations à l'IA pour vos équipes non-tech, animées par nos dev 👇
blog.humancoders.com/formati…
1
1
5
1,676
Matthieu Segret retweeted
May 19
Mon top 13 des skills et plugins Claude Code qui ont marqué 2026 :
→ celui qui coupe 63 % des tokens de sortie
→ celui qui rejoue tes sessions comme une vidéo
→ celui qui transforme une codebase en graphe explorable
→ et 10 autres encore !
camilleroux.com/top-skills-p…
4
23
132
15,129
RYBitten, un outil pour explorer les espaces colorimétriques avec une approche peinture — mélange RYB, presets de gamut et génération de palettes directement dans le navigateur.
rybitten.space/
1
102
Matthieu Segret retweeted

Apr 23
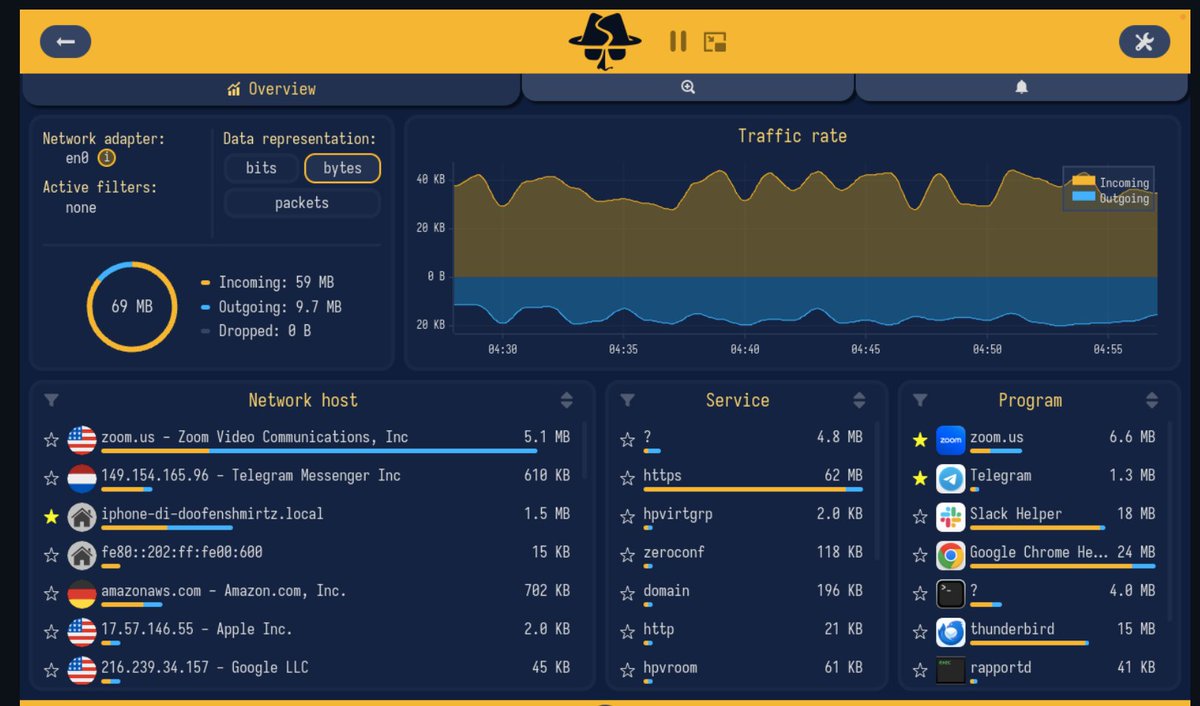
sniffnet diye rust ile yazılmış bir araç var, internet trafiğini izlemek için. açıp ağ kartını seçiyorsun ve o an hangi cihaz nereye paket gönderiyor, hangi servisle konuşuyor, hangi ülkeye bağlanıyor hepsini
görebiliyorsun.
windows mac linux hepsinde çalışıyor, tek binary. hostların domain ve asn bilgisini çözüyor coğrafi konumu gösteriyorr.
açık kaynak ve ücretsiz.
25
305
2,187
128,132
Matthieu Segret retweeted

Apr 22
OpenAI just open sourced a new 1.5B (50m active) model on HuggingFace with Apache 2.0 license!
It's not a new LLM, this one is called Privacy Filter, and it's a PII detection model (checking if text has private information)
A few interesting tidbits from the release links:

24
142
1,146
175,135
Matthieu Segret retweeted

🚀 Nous avons retenu @Scaleway_fr comme nouvel hébergeur de notre plateforme technologique !
👉 La migration vers ce nouvel hébergeur s’inscrit dans une stratégie de réversibilité engagée dès 2019 et va permettre d’accélérer la mise à disposition de données de santé.
🔎 Ce choix repose sur une analyse approfondie de la PDS qui a bénéficié de l'accompagnement de la DINUM, d’@Inria et du ministère @Sante_Gouv, et met en valeur l’évolution de l’offre cloud souveraine.
Lire le communiqué 👉 health-data-hub.fr/actualite…

12
51
141
20,956
Matthieu Segret retweeted

Apr 21
Today, we’re open-sourcing the draft specification for DESIGN.md, so it can be used across any tool or platform. We’re also adding new capabilities.
DESIGN.md lets you easily export and import your design rules from project to project. Instead of guessing intent, agents know exactly what a color is for and can even validate their choices against WCAG accessibility rules.
Watch David East break down this shared visual language in action👇. New capabilities and links in 🧵
208
2,012
18,277
6,830,015
Matthieu Segret retweeted

Apr 20
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…

943
2,391
18,129
7,520,177
Matthieu Segret retweeted
Apr 16
Bravo Xavier ! Super conf pour savoir comment marche Claude Code, OpenCode et autres.
J'avais déjà vu le replay de la version donnée au @HumanTalks mais c'est mieux en vrai ! (coucou MiXiT)
PS: Le sticker @humancoders sur le Mac fait très plaisir :p


1
3
7
1,344

Matthieu Segret retweeted
Apr 10
J'ai créé un skill Claude Code qui agrège l'actu dev francophone et te sort un récap trié par jour directement dans ton terminal.
/veille
👉 github.com/camilleroux/veill…
9
21
166
16,438
Matthieu Segret retweeted
Apr 10
Anthropic lance les Claude Managed Agents : une infrastructure gérée pour faire tourner Claude comme agent autonome, sans avoir à construire sa propre boucle d'exécution. ⬇️
news.humancoders.com/t/ia/it…
1
2
5
866
Matthieu Segret retweeted

Apr 7
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
anthropic.com/glasswing
1,985
6,645
44,011
31,426,281
Matthieu Segret retweeted
Apr 3
Cursor 3 repense l'interface autour des agents : multi-dépôts, exécution parallèle d'agents locaux et cloud, passage fluide entre les deux, et tout ça sans quitter l'IDE. ⬇️
news.humancoders.com/t/ia/it…
2
2
2
552