
Run Murai Labs from Austin. Publish AI research, ship the tools. Currently: MoE router co-evolution, model fusion, sparse mutability. murailabs.com
Joined November 2020
- Tweets 407
- Following 551
- Followers 308
- Likes 166
25 Photos and videos







Pinned Tweet

May 22
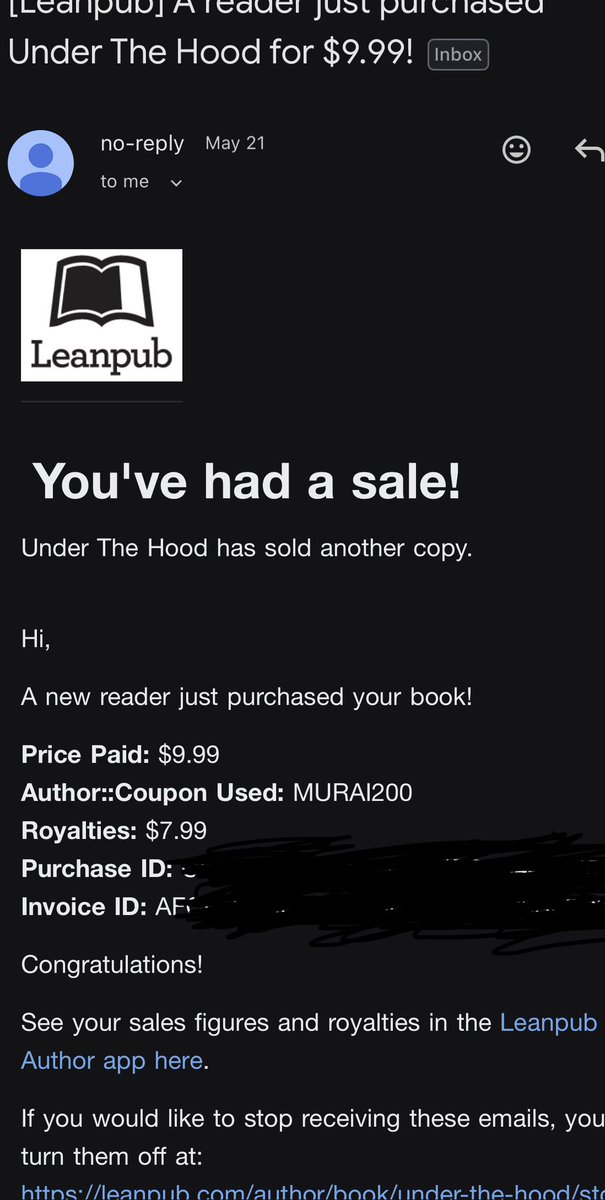
Exciting news! 10 months ago I started writing the book I wished I had when I was learning how LLMs actually work — from the inside. 934 pages. 35 projects. Every chapter has a section on how to break the thing you just built.Built. Broken. Measured. Understood.
For the next 24 hours: $9.99 with code MURAI200. Regular price $35. leanpub.com/under-the-hood
4
10
691
Had the wonderful experience of being interviewed by Len from @leanpub for promoting the launch of my book. The book sales has been a huge success with so many happy customers! Get your copy here: leanpub.com/under-the-hood

NEW! Leanpub Book LAUNCH 🚀 Under The Hood: Build Every Layer of a Large Language Model from Scratch by Ramchand Kumaresan
youtu.be/dag4J_bWo2c
#books #leanpublishing #selfpublishing #ai #management #research
25
Jun 13
Here is Rio de Janeiro’s model - you are telling me India cannot do this? @svembu can do it in CBE with some support and maybe the hope is many more labs in India are building in private- but open source is the key. Datasets, evals, results, checkpoints - build, show, get community to improve it.
Jun 13

Alibaba Qwen3.7 slowly fading into irrelevance at the frontier due to proprietary stance.
In it's place we have Minimax M3 and... *checks notes* Rio 3.5 397b, made by the municipal IT company of Rio de Janeiro's city government.
huggingface.co/prefeitura-ri…

Community note
Analysis shows Rio-3.5-Open-397B is a 0.6/0.4 weight merge of Nex N2 Pro and Qwen 3.5, not an originally trained model. When the system prompt is removed, it identifies as Nex 79.2% of the time.
x.com/NexEcosystem/s…
github.com/nex-agi/Nex-N2…
2
17
943
Jun 13
Exactly why I am building TamilLM to be fully open source. The 1.5B model I build will be up for @CMOTamilnadu to use or collaborate with us to build a sovereign Tamil model. No one should be forced to think Sarvam is the option. It is a good start for sure! BTW I am doing this with no support so far!

One of the blunders India has done as a country is to declare Sarvam, which is yet to find its footing as the sovereign frontier AI response.
Sarvam’s exclusive mandate is not public good - unlike UPI or other public infrastructure projects. It’s a VC funded company which is being given unfair advantage at the cost of other similar VC backed private companies which could perhaps do better with similar support and data from the govt!
We are killing competition and declaring Sarvam as the best thing India could do too soon !
4
11
849
Jun 13
Next thing we will see is a ban on chinese LLMs - because the common man cannot win. Followed by that, local models will be limited to how good they can get. Global economics plays out - check if someone made money out of this on Poly or Kaishi, and you will see its planned.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
83
Jun 11
The art of trolling…

Calling all researchers using Anthropic's AI model Claude: how are you using the new Claude Fable 5 model in your research?
We want to hear about the most impressive things it's built for your research projects or left you asking what the fuss is all about. Can it do things you couldn't do before? Let us know.
2
55
Jun 10
The most useful way I know to learn LLMs:
Build the mechanism.
Break it on purpose.
Measure what changed.
Attention makes more sense after a masking bug.
KV cache makes more sense after a shape bug.
RLHF makes more sense after reward hacking.
leanpub.com/under-the-hood
2
48
Jun 10
I keep seeing the same June agent paper pattern: before adding another agent, run the dumb baseline. Full context, one worker, one verifier, real logs. CL-Bench and CollabSim are saying the coordination layer is not free - it can erase the signal you thought you kept.
1
30
Jun 10
One thing writing Under The Hood reinforced for me:
people do not really understand attention, KV cache, reward models, or MoE from diagrams alone.
They understand them differently after the first bug.
1
2
37
Jun 9
Wow just realized today’s agent papers are poking the same bruise - memory and multi-agent setups look fancy, but plain transcript verifier keeps embarrassing them. I see this in my Codex night builds too. Boring harness beats clever architecture more than my ego likes lol
1
2
53
Jun 9
I still think building an LLM from scratch is one of the best ways to understand modern AI.
Not because everyone should train frontier models.
Because once you implement attention, KV cache, MoE, RLHF, and quantization yourself, the abstractions stop feeling magical. Check out how to do it yourself: leanpub.com/under-the-hood
1
1
59
Jun 9
Link I should have included in the post: leanpub.com/under-the-hood
Under the Hood is a build-it/break-it/measure-it manual for learning the LLM stack by implementing each layer yourself, from tokenizers and attention to MoE, RLHF, RAG, serving, and quantization.
1
1
31
Jun 9
The associated GitHub repo is here: github.com/mechramc/Under-th…
It is the runnable code companion: 35 projects with canonical build scripts, sabotage experiments, step files, tests, setup notes, and captured outputs. Book for the concepts. Repo for the labs.
1
1
29
Jun 9
This is the pattern I trust for learning AI systems:
build without hiding the internals first.
Frameworks are useful later. The first pass should expose retrieval, tool calls, context pressure, and failure handling.
x.com/afkpriyanshu/status/20…
Jun 9

Built a Research Agent from scratch in Python. No LangChain, no agent frameworks hiding the internals.
Stack:
→ Tavily API for real-time web search
→ httpx BeautifulSoup4 for page scraping
→ Tavily content field for clean extraction - no manual truncation needed
→ GPT-4o-mini for structured markdown report synthesis
→ Streamlit UI with dark dashboard theme
Key decisions made along the way:
→ started with manual scraping, switched to Tavily's built-in content field - cleaner input, better reports
→ added error handling timeout on scraper to handle dead URLs
→ sanitized filenames for Windows compatibility
→ reports auto-saved to outputs/ as markdown files
Type any topic - Beacon searches 5 sources and returns a structured report in under 30 seconds.
GitHub: github.com/Priyanshu312003/B…
#buildinpublic #Python #AI #LLM
1
1
71
Jun 9
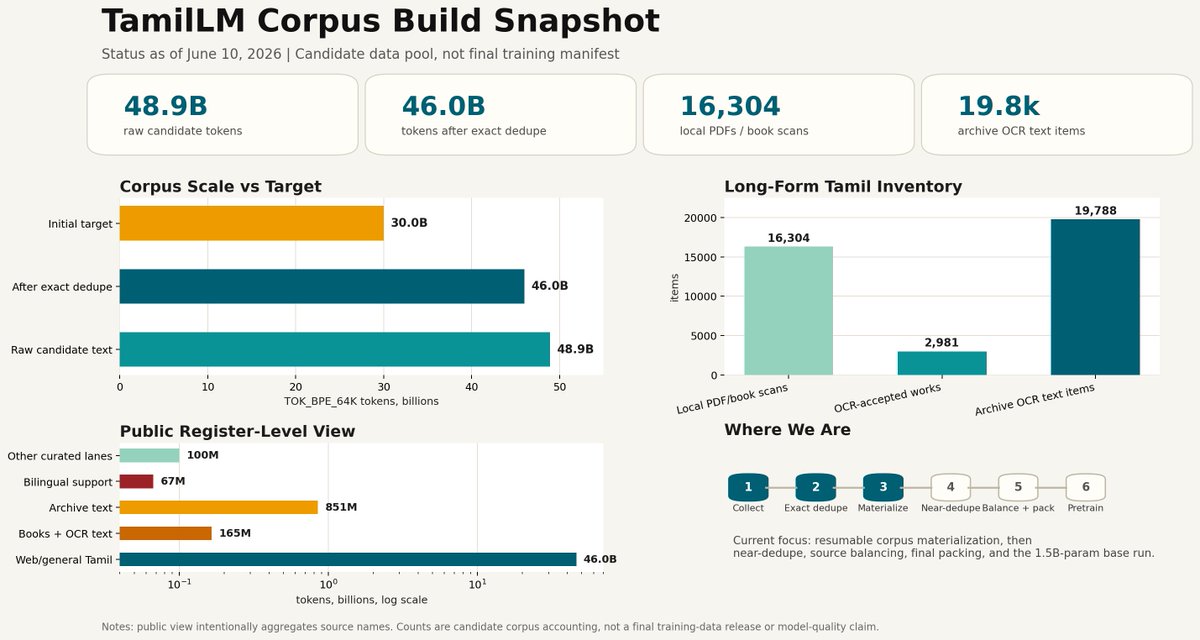
TamilLM update: BhasaAnuvaad Tamil intake is recorded: 208 parquet files, 188.94 GiB, all checksum-tracked, no corpus text in git.
30B is now the first serious training floor, not a cap. If more usable high-quality Tamil data exists, we account for it.
1
5
130
Jun 9
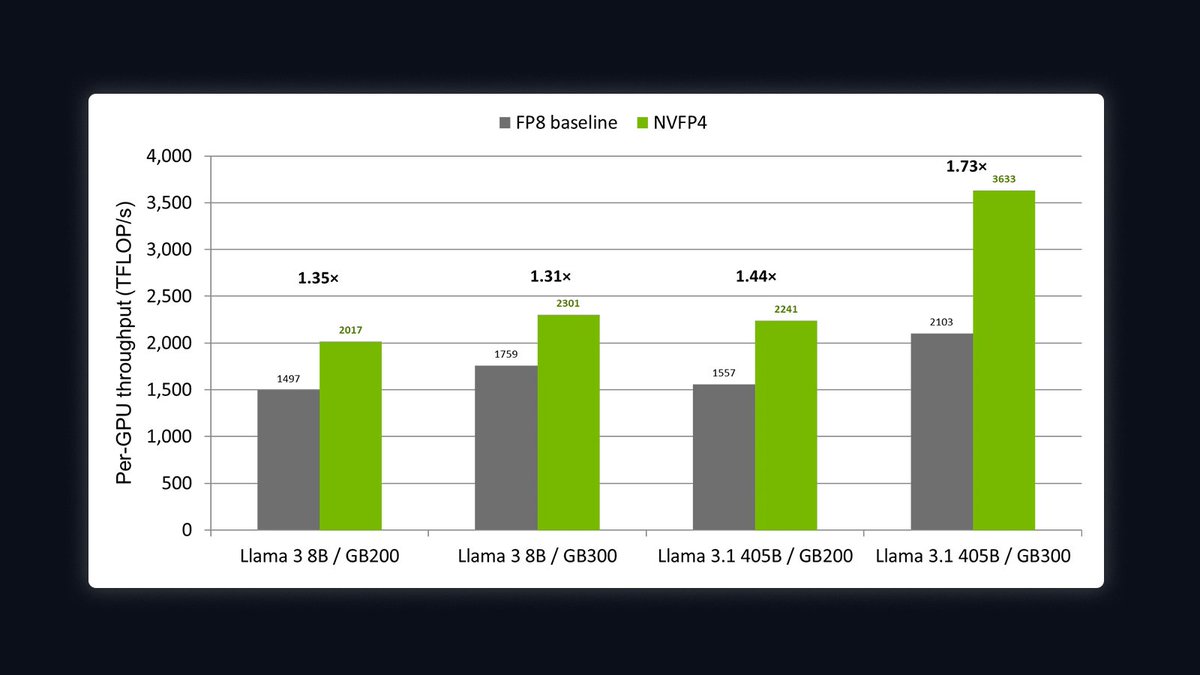
Its getting interesting now!

We trained Llama 3 8B and 405B with NVFP4 precision on the NVIDIA Blackwell platform.
Here's what we found: 1.31–1.73× faster than FP8, with zero accuracy loss.
1
50
Jun 8
I have to get the PS5 out now

Son of Thanjai is an action-adventure game set in ancient South India, featuring the Surul Vaal, a flexible whip sword never before seen in gaming.
Play as Vinnendiran, a fallen prince fighting to reclaim a throne through a land torn apart by invasion. Coming to PS5.
Wishlist now!
#psindia #sonofthanjai
youtube.com/watch?v=SzYIP6OB…
70
Ramchand Kumaresan retweeted

May 31
a standing ovation for daraxonrasib at asco. over 40k oncologists, entrepreneurs, investors, and patient advocates together celebrating revmed's breakthru in the fight against pancreatic cancer. u never forget these moments. it's what innovation is all about.
84
877
4,634
1,994,758
Jun 8
This is something I need to preach to everyone I know - most people don’t realize there is a bad speed.

26