Joined September 2025
- Tweets 1,730
- Following 1
- Followers 1,623
- Likes 1,197
876 Photos and videos














Pinned Tweet

May 29
Early results for Claude Opus 4.8 and Gemini 3.5 Flash on @OpenAI's HealthBench Professional:
Opus 4.8 looks essentially flat against 4.7 (within noise). Gemini 3.5 Flash is a step up from 3.1 Pro.

1
7
35
3,548
Jun 11
We tested a council of AI models on this week’s @NEJM Image Challenge. As expected, the council predicted the diagnosis correctly! 🤖🏥
🚨 The newly released Claude Fable 5 refused to answer the question.
3
340
Medical Sphere retweeted
Claude Opus 4.8 by @AnthropicAI just landed on MedAgentBench 🏥🩺
80.3% accuracy on 300 clinical agent cases, compared to Opus 4.7 at 89.0%.
Breakdown by task 👇
medicalsphere.ai/benchmarks/…
1
5
9
627
Claude Fable 5 by @AnthropicAI is live on Medical Sphere 🏥🩺
Put it to test on real clinical cases, head-to-head against other frontier models. Free for verified medical professionals.
Try it here: medicalsphere.ai
1
3
43
6,540
Claude Opus 4.8 by @AnthropicAI just landed on MedAgentBench 🏥🩺
80.3% accuracy on 300 clinical agent cases, compared to Opus 4.7 at 89.0%.
Breakdown by task 👇
medicalsphere.ai/benchmarks/…
1
5
9
627
Where does Opus 4.8's MedAgentBench regression come from? Three tasks tell the story:
1⃣ Magnesium medication protocol: 4.8 refuses to return the value when levels are normal, explaining instead. 4.7 just answers.
2⃣ Potassium medication protocol: 4.8 is noisier and more inconsistent.
3⃣ HbA1c lab retrieval: 4.8 retrieves the wrong record. 4.7 is functionally perfect (format-only failures).
1
1
4
136
Medical Sphere retweeted
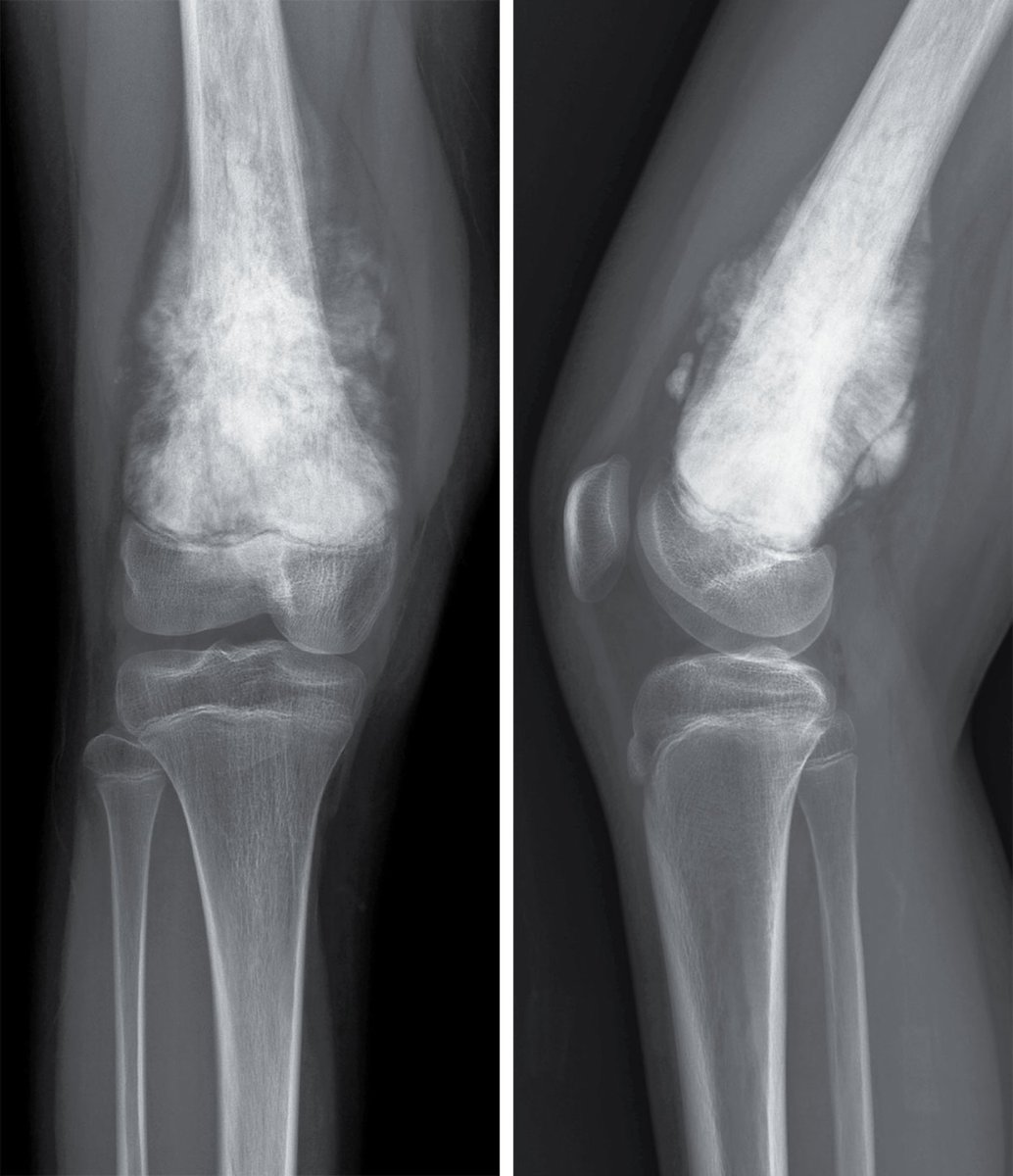
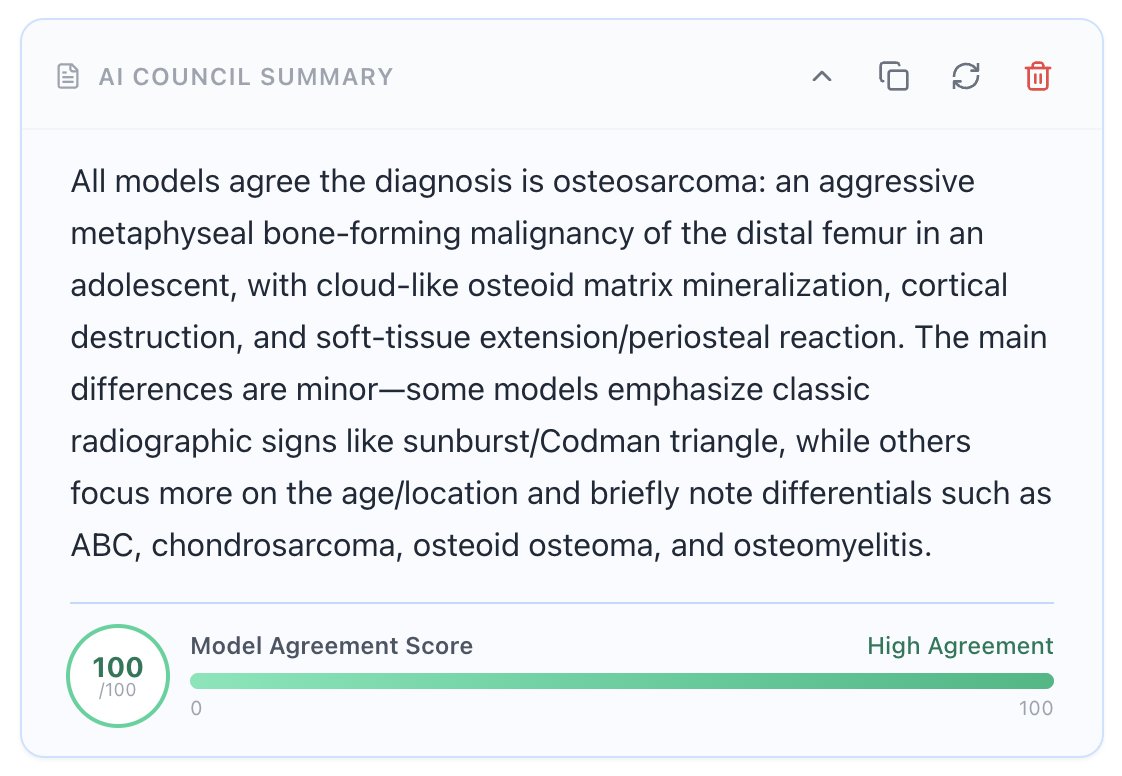
The @NEJM Image Challenge of the week was too easy for AI models! 🏥🤖
Got any more challenging clinical cases for them? Bring it on ⚔️
1
4
652
May 29
Early results for Claude Opus 4.8 and Gemini 3.5 Flash on @OpenAI's HealthBench Professional:
Opus 4.8 looks essentially flat against 4.7 (within noise). Gemini 3.5 Flash is a step up from 3.1 Pro.
1
7
35
3,548
May 28
Claude Opus 4.8 by @AnthropicAI is now live on Medical Sphere! 🏥🩺
Come test it on medical and clinical cases and see how it performs against other leading AI models.
Try it here: medicalsphere.ai/arena
3
18
1,752
May 22
We added AI analysis cost breakdowns to Medical Sphere 🏥📊
Users can now see not only how frontier AI models perform on medical cases, but also token usage, inference costs, and the cost of AI council summaries.
In healthcare, accuracy and reliability come first. As AI systems move toward real-world deployment, transparency into the infrastructure behind them matters too.
1
3
288
May 20
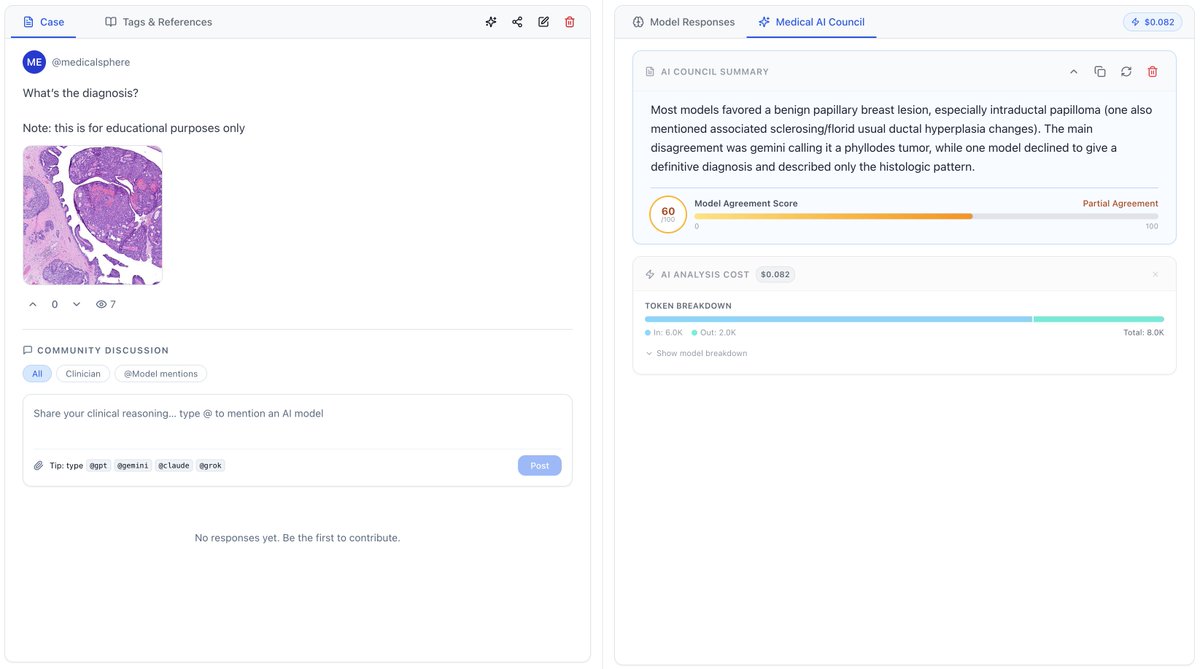
Testing the AI council on the @NEJM Medical Image Challenge of the week. This is what the models said 👇
All models agreed the finding is bronchial anthracosis/anthracofibrosis: black bronchial mucosal pigmentation from carbon-laden macrophages, most likely due to biomass smoke and environmental dust.
1
3
680

Medical Sphere retweeted
May 20
Gemini 3.5 Flash now live on Medical Sphere! 🚀
2
3
354
Medical Sphere retweeted
May 13
Meet @AskMedSphere, our medical AI evaluation agent on X 🏥🤖🩺
Tag it on any medical post to compare responses from frontier AI models 👇
3
6
1,076
Medical Sphere retweeted

May 13
Like tagging grok but for medical AI evals with a council of AI models instead of just one! 👀
May 13

Meet @AskMedSphere, our medical AI evaluation agent on X 🏥🤖🩺
Tag it on any medical post to compare responses from frontier AI models 👇
1
1
3
537
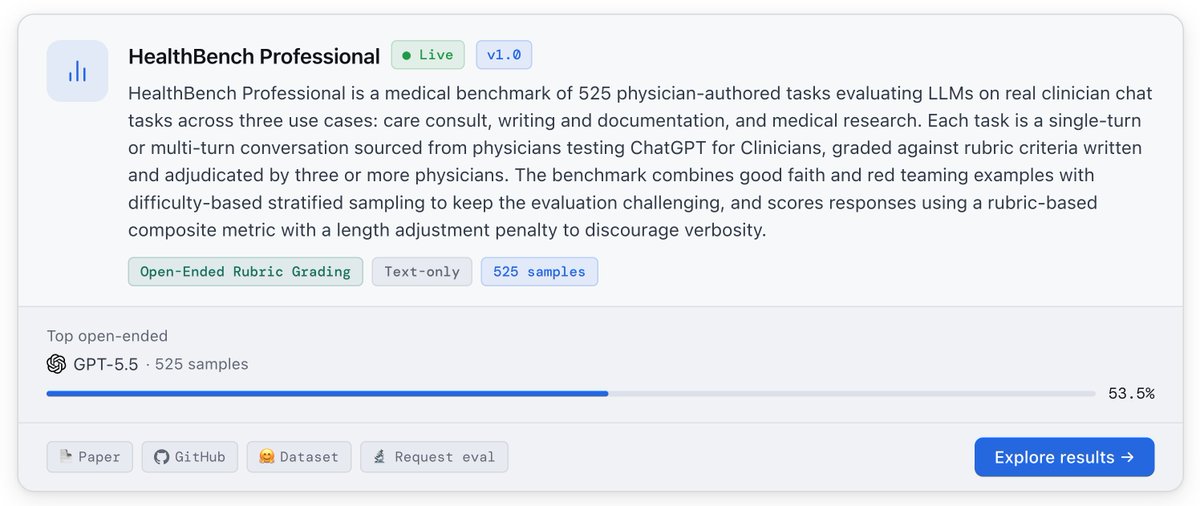
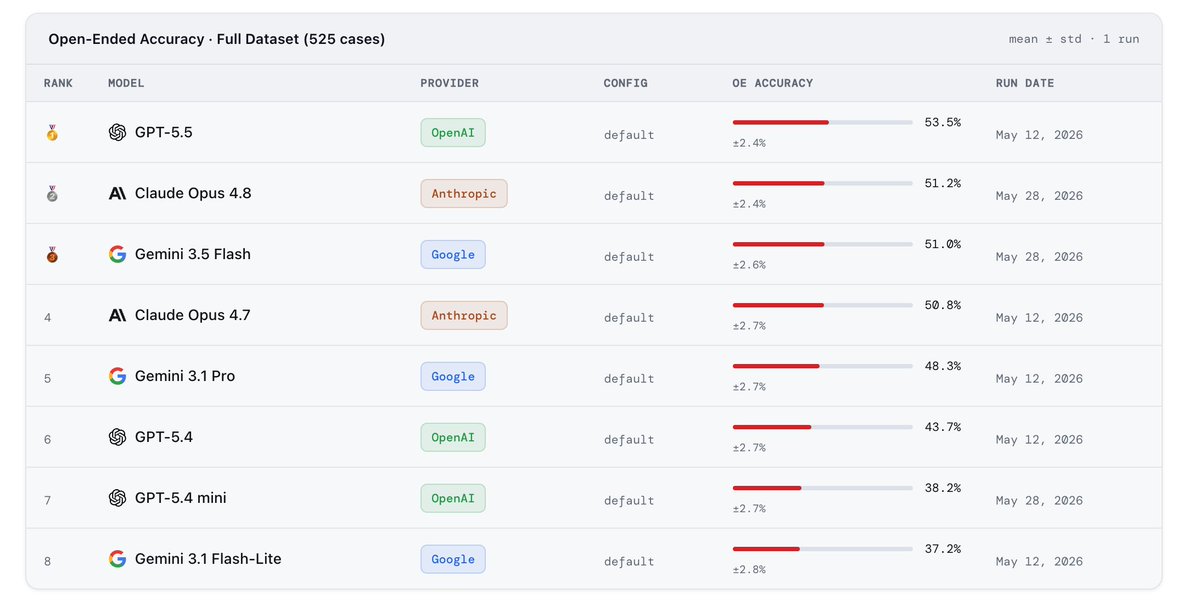
May 12
HealthBench Professional is now live on Medical Sphere 🏥
Built by @OpenAI, this benchmark contains 525 real clinician chat cases across care consults, medical documentation, and medical research.
medicalsphere.ai/benchmarks

1
5
13
1,151
May 12
We also have a standalone open-source implementation for full reproducibility 🔁
Built on top of OpenAI's simple-evals, with added support for Claude, Gemini, and more models
github.com/medicalsphere/Hea…
1
2
148