
Frank M. Freimann Collegiate Professor at Notre Dame CSE | Data Mining | NLP | AI
Joined August 2012
- Tweets 215
- Following 557
- Followers 1,591
- Likes 355
14 Photos and videos













Jun 8
Thought #3: Is the widespread use of AI code-generation tools amplifying inequalities among programming languages, where some languages are more popular and therefore more widely created, used, and represented, while others remain less popular and are created and used far less?
1
3
408
Jun 8
As this imbalance intensifies, are the flaws of programming languages more likely to be exposed because of the dominance of a single language, or less likely to be exposed because of the availability of variety?
1
1
322
Jun 8
Is the motivation to create emerging programming languages nurtured by the exposure of flaws in existing languages? If so, will AI code generation make it easier for new languages to emerge, or will it suppress the possibility of new languages being created?
2
174
Jun 5
Random thought #2: When the solution space is huge, humans may only know <1% of the strategies for finding optimal solutions. If AI can explore more broadly and receive accurate feedback, it may discover much of the remaining 99%. The key is feedback: ...
1
2
223
Jun 5
The key is feedback: its accuracy and efficiency determine how much value AI can add.
For AI to truly empower art, engineering, and science, we need scalable even modelable evaluators. Creation and the evaluation of creation both depend on *modeling and simulation*.
1
1
174
Jun 3
My students keep telling me to tweet more, and I keep making excuses. One excuse is thinking every social media post has to be polished or joyful. I know that’s not true, so I’m practicing: one random thought a week.
1
4
262
Jun 3
Big AI skills are distilled into small AI. Human skills are distilled into AI systems. But AI users worry about losing their own skills and ability to learn. Is distilling knowledge from AI into humans (through reading AI outputs, coding with AI, and other uses) simply too slow?
2
205
Jun 1
Best conference experience this year so far! Conference organizers are awesome; speakers are super super good!

@CAISconf was sold out but small, focused on a particular well-scoped area (compound agentic systems). Some workshop papers were submitted as late as just a couple weeks before (fresh content), and good thing, too! Agentic systems already look quite different today than even 3 months ago.
Perhaps the systems focus naturally attracts researchers who are inclined to build prototypes and libraries (not just publish), but I was still pleasantly surprised to see how many members of the Laude community had independently identified this conference as one they wanted to submit to and attend. On top of that, throwing a lounge after hours with food, drinks, demos, salon-style conversation, (and a mini podcast studio, because why not?) made it easy to get an even higher concentration of interesting people with interesting half-baked ideas in a particular niche that happens to be on fire right now.
Loved the experience. Well-done, CAIS organizers (@heathercmiller, @lateinteraction, @matei_zaharia, @deeptir18, et al). Same time, same place next year?



6
243
Meng Jiang retweeted

May 26
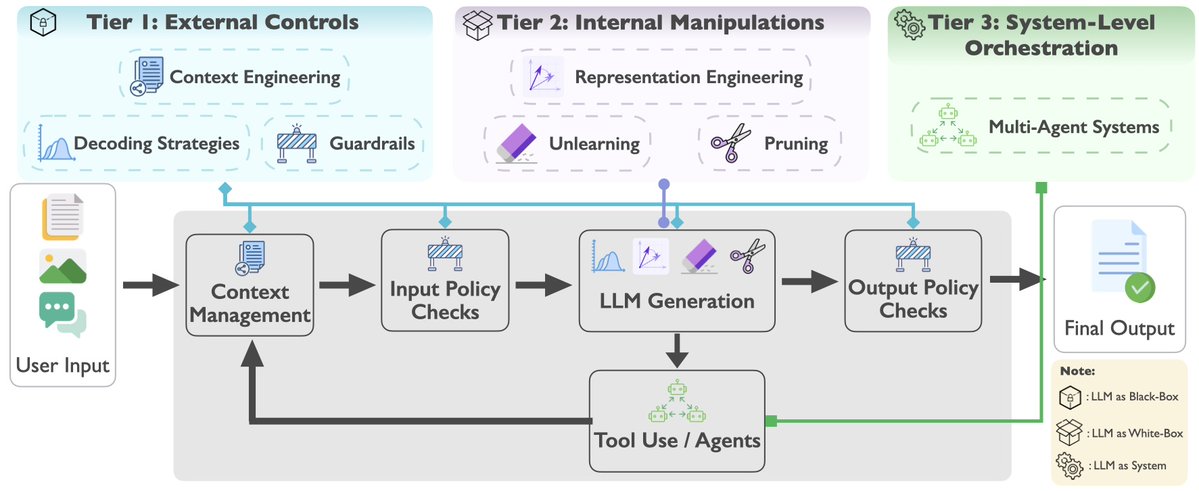
🔥 New survey: Inference-Time Control for Trustworthy LLMs.
Once a model ships, training-time alignment can't keep up. Inference-time control is how we patch the gap.
🚀 We collected 200 papers (2020–2026) and built the first pipeline-grounded taxonomy that unifies seven method families: context engineering, guardrails, decoding, representation engineering, unlearning, pruning, and multi-agent orchestration.
📄 Paper: doi.org/10.20944/preprints20…
Existing surveys cut the field by harm type or by one method family. We treat inference-time interventions as a unified control plane over the generation pipeline.
💡 The Framework: Three tiers, by where the intervention happens.
🛡️ External: around the model (prompts, guardrails, decoding)
🧠 Internal: inside the model (steering, unlearning, pruning)
🤝 System-level: across models (debate, verification)
📊 The Coverage:
🔍 200 papers indexed (2020 → 2026)
🧠 7 method categories, one pipeline-grounded map
📈 4 trustworthy dimensions ✕ 5 evaluation axes = a meta-axis grid
🗂️ Repo (live, 200 papers indexed):
github.com/leopoldwhite/Awes…
🌐 Website: leopoldwhite.github.io/Aweso…
👇 Full thread below.

11
17
52
9,704
Meng Jiang retweeted

🚨Typical RL algorithms and on-policy distillation methods are blind samplers: they use privileged info to score rollouts, but not to *find* them.
We ask: can we use privileged info to *actively sample* the rollouts RL wishes it can stumble upon with compute?
⤵️ Pedagogical RL

16
87
498
114,437
Meng Jiang retweeted

Apr 29
I’m thrilled to share that I’ll be starting my CS PhD at @NorthwesternU this fall, advised by @ManlingLi_! I’ll be researching areas in trustworthy AI and spatial intelligence to build reliable AI systems that are grounded in the physical world. I’m also happy to announce that I was awarded the @NSF GRFP fellowship, which will support my PhD for 3 years!
This wouldn’t have been possible without my wonderful mentors @nunompmoniz, @Meng_CS, @frank_liu_01, @NoahZiems, and countless others who’ve guided me throughout my undergrad.
And so… I guess I won’t be leaving the midwest :)
5
4
73
9,863
Meng Jiang retweeted

Apr 29
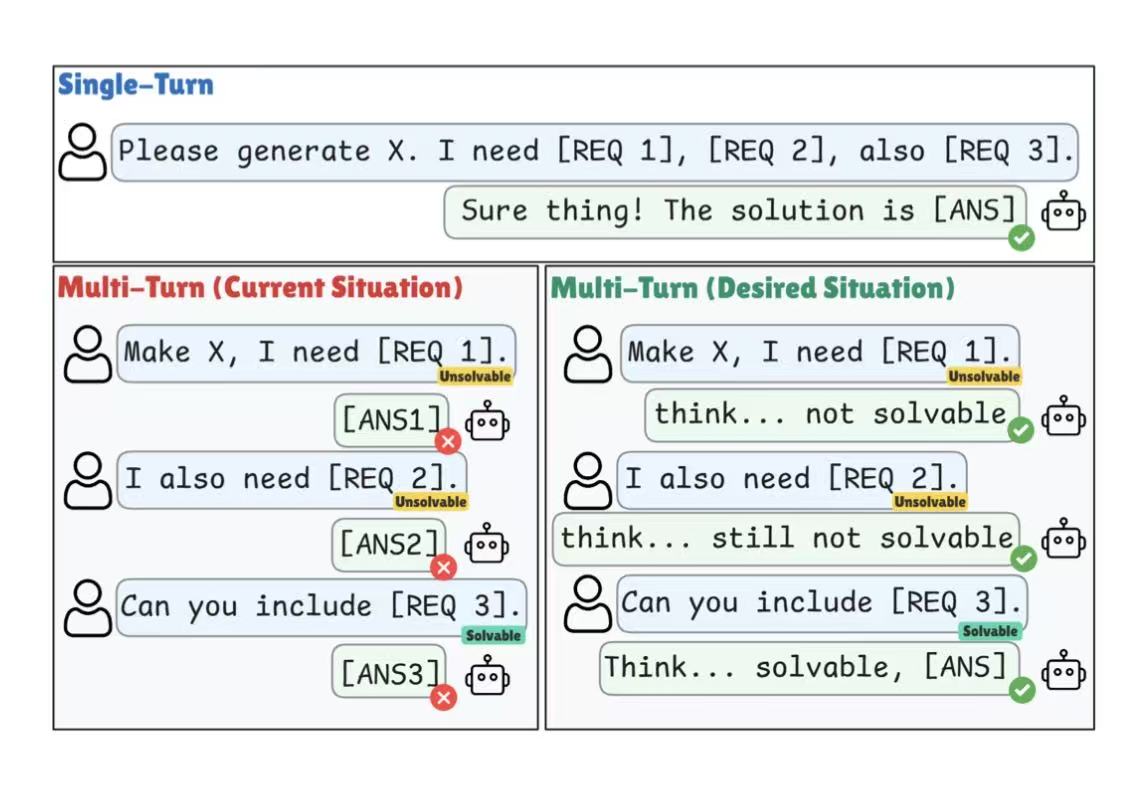
Excited to share our ACL 2026 work, trying to solve the issue raised by the ICLR Outstanding Paper “LLMs Get Lost In Multi-Turn Conversation”!
Our RLAAR (arxiv.org/pdf/2510.18731) is an RL framework that trains LLMs to both answer correctly and wait when context is insufficient, using verifiable accuracy and abstention rewards.
This tackles a key weakness in today’s conversational LLMs: they often answer too early, make wrong assumptions, and struggle to recover as conversations unfold.
We’re also excited to see this challenge highlighted by “LLMs Get Lost In Multi-Turn Conversation” (arxiv.org/pdf/2505.06120) being recognized as an ICLR 2026 Outstanding Paper.
Reliable conversational AI needs to know when to answer — and when to hold back.
#ACL2026 #ICLR2026 #LLM #RLVR #ConversationalAI
1
11
73
5,560
Meng Jiang retweeted

Thrilled to present GEPA as an Oral Talk and Poster at ICLR 2026 this Friday in Rio! 🇧🇷
Apr 24
Oral Session 3A (Agents), 10:30 AM BRT, Amphitheater
Poster Session 4, 3:15 PM, Pavilion 3
x.com/LakshyAAAgrawal/status…
Let's recap what's happened since we released GEPA last year 🧵

28 Jul 2025

How does prompt optimization compare to RL algos like GRPO?
GRPO needs 1000s of rollouts, but humans can learn from a few trials—by reflecting on what worked & what didn't.
Meet GEPA: a reflective prompt optimizer that can outperform GRPO by up to 20% with 35x fewer rollouts!🧵
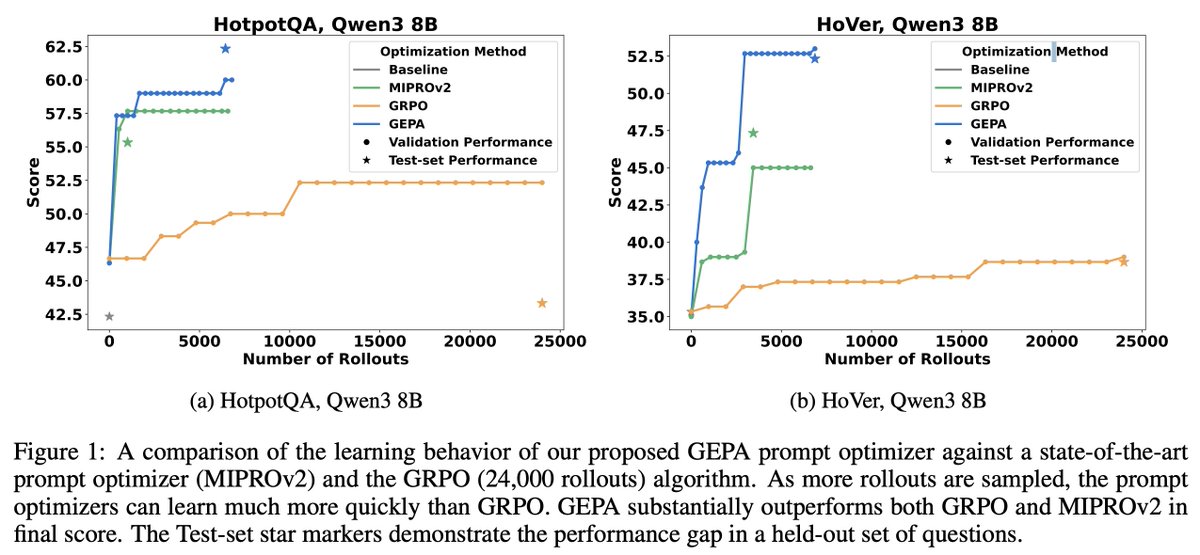
11
38
221
58,484
12 Nov 2025
Decentralized RAG allows your database to benefit all LLM clients. On the other side, not all data sources are reliable. Managing source reliability on blockchain can avoid third-party manipulation. Introducing dRAG Blockchain Truth Discovery: arxiv.org/abs/2511.07577
1
7
1,354

𝗕𝗲𝗰𝗮𝘂𝘀𝗲 𝟵.𝟭𝟭>𝟵.𝟵 𝗮𝗻𝗱 𝗮 𝘁𝗿𝗶𝗮𝗻𝗴𝗹𝗲 𝗵𝗮𝘀 𝗳𝗼𝘂𝗿 𝘀𝗶𝗱𝗲𝘀, 𝘁𝗵𝗲𝗿𝗲𝗳𝗼𝗿𝗲 𝟭 𝟭=𝟮.
LLMs and Language Agents can sometimes generate correct answers from blatantly incorrect reasoning, which is more often in complex tasks, and exacerbated by reinforcement learning (RL), the commonly believed silver bullet to complex reasoning in LLMs.
This is due to a well-known phenomenon called reward hacking, where if the only training signal LLMs are getting from the training data exclusively regards the final result, then LLMs are incentivized to match the correct final output through whatever means possible on its training data, leading to inconsistent and ungeneralizable reasoning processes in RL's wake.
With our intern Mengzhao Jia, we (@ignaciocases and myself, plus folks from @Meng_CS
s lab at Notre Dame) explore a simple fix: can we use the LLM's own reasoning to provide some additional supervision signal for the reasoning process itself, so that besides the final result, the LLM is also encouraged to stay consistent in its reasoning during training?
We design an algorithm to automatically create rubrics for LLM reasoning processes, and train the model to adhere to these rubrics alongside generating correct final answers during RL. The resulting model not only produces significantly more consistent reasoning, but also generalizes better on a wide range of complex reasoning tasks we benchmarked, even with just 10% of the training data. We hope this technique helps pave the way to more powerful and generalizable reasoning models for complex tasks.
Read more in our preprint: arxiv.org/pdf/2510.14738
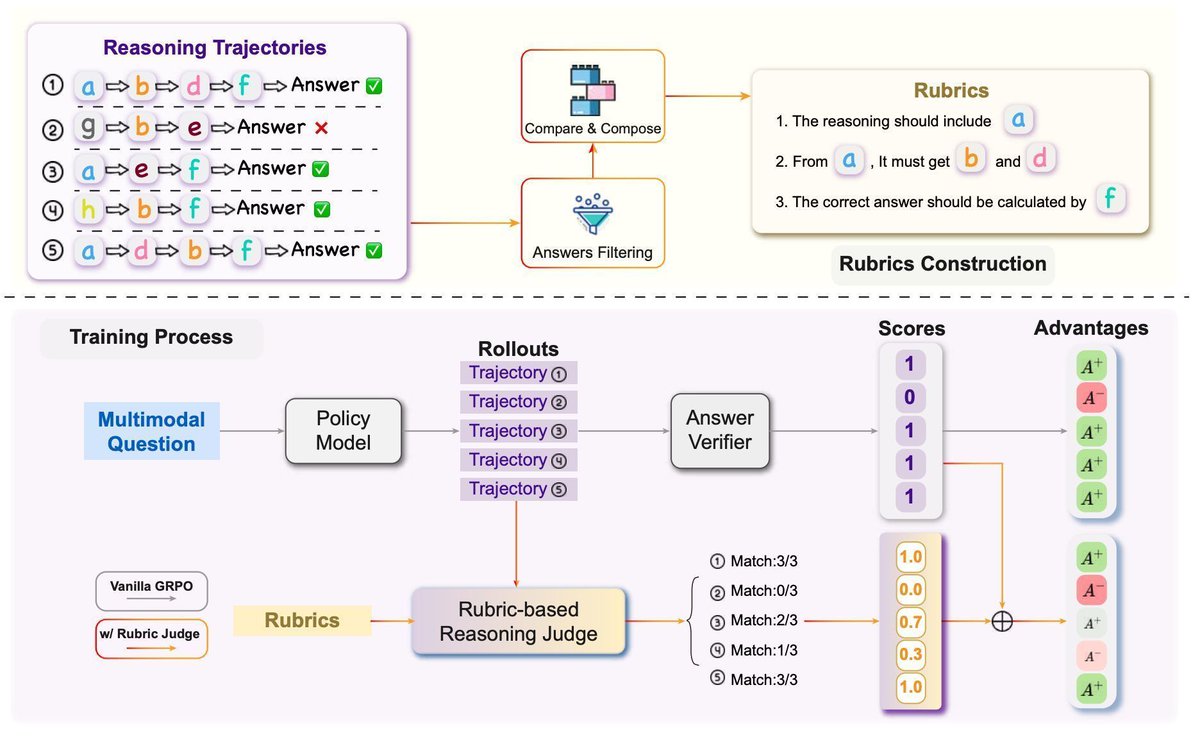
4
10
67
7,517

Thrilled to share that “Improving Large Language Models Function Calling and Interpretability via Guided-Structured Templates” paper has been accepted to EMNLP 2025 (Main Conference)!🎉
📄 Check it out on
arXiv: arxiv.org/abs/2509.18076
project page: hygiadang.com/publication/em…
1/3
1
1
3
776
Meng Jiang retweeted

16 Sep 2025
.@DomSoos from @WebSciDL and @oducs is presenting "Can LLMs Beat Humans on Discerning Human-written and LLM-generated Science News?" They explored whether LLMs can outperform humans for LLM-generated vs. human written news.
🔗doi: 10.1145/3720553.3746674
#LLM #NLP @fanchyna




4
2
481
17 Sep 2025
Job opportunity (postdoc at Notre Dame Foundation Models Lab):
apply.interfolio.com/173333
1
9
20
2,461
Meng Jiang retweeted

16 Sep 2025
✴️ Pleased to introduce our new paper yining610.github.io/dynamic-…
- Rebalance multiobjectives during training through dynamic reward weighting
- Build Pareto-dominant front over static baselines across online RL algorithms, datasets, and model families
- Faster convergence rate
1/8

1
8
23
5,466
Meng Jiang retweeted

11 Sep 2025
Come be my colleague! @ND_CSE at @NotreDame is hiring a tenure-track professor in computer vision! (And robotics and quantum.)
More info here: careercenter.cra.org/job/uni…

5
9
1,165