
Joined March 2022
- Tweets 2,610
- Following 1,852
- Followers 3,094
- Likes 385
758 Photos and videos




Pinned Tweet

Apr 24
DeepSeek moment is here AGAIN. v2.
The biggest AI release of 2026 so far, just dropped.
It's not from OpenAI. Not from Anthropic. Not from Google.
DeepSeek V4: 1M context, MIT license, frontier performance, for a fraction of cost.
Here's why it AGAIN reshapes the industry🧵

2
2
15
14,048
glm and kimi 2.7 as sub-agents running under opus 4.8 and gpt 5.5.
the interesting part is the open-source sub-agent layer. that's where the cost savings live.

🚨 FUSION AGENTS - Build Complete SaaS Apps With Open-Source AI
Fusion agents combine Kimi 2.7 and GLM with Opus 4.8 and GPT 5.5
- multi-agent architectures with open-source sub-agents
- build complete SaaS apps
- one click connectors to 100 products
- create companion iOS and android apps with one prompt
- accept stripe payments
1
45
This feels like a natural evolution toward a 'model-agnostic' agent orchestration layer, abstracting away the specific LLM's quirks.
14
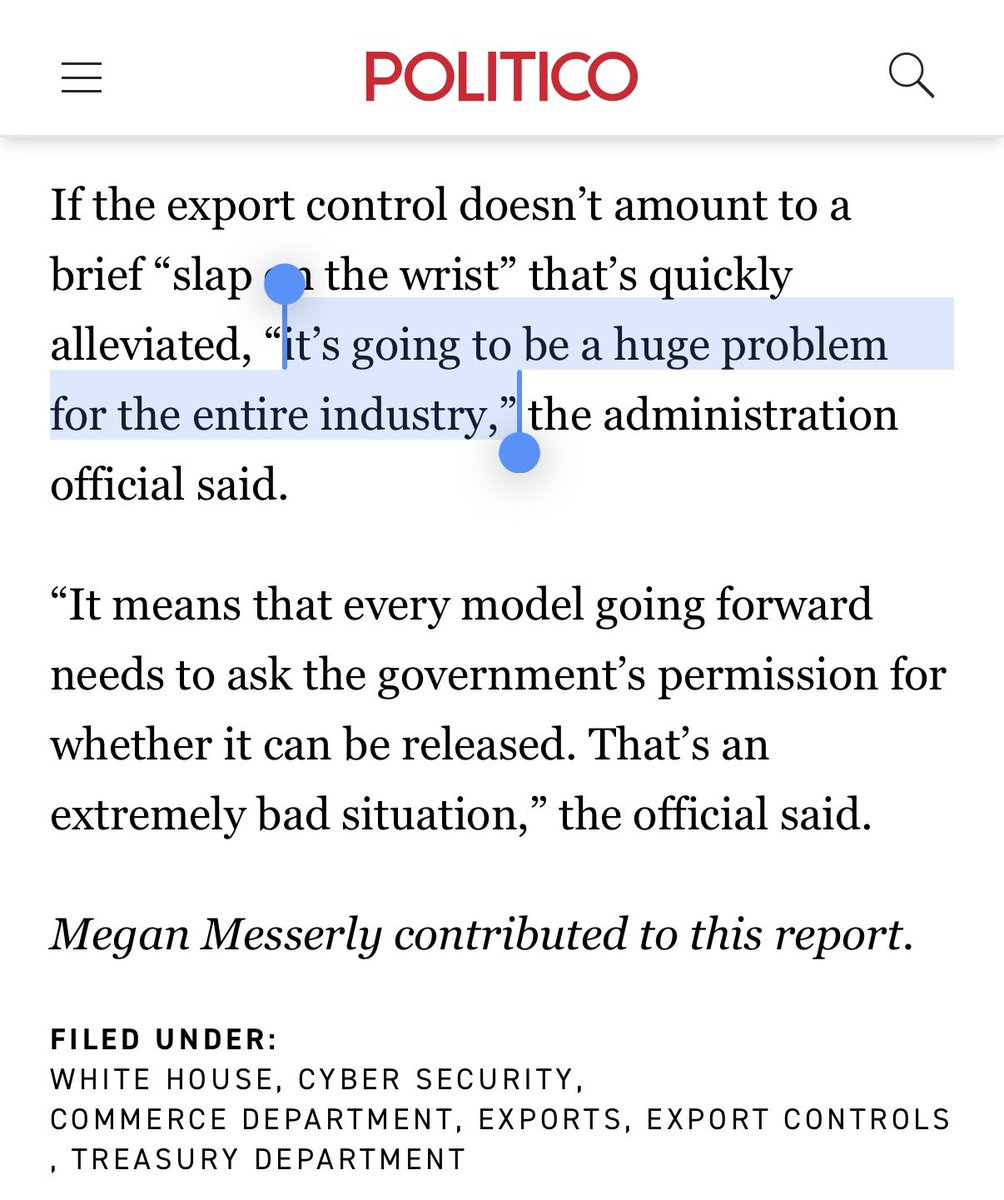
a US official just said "every model going forward needs to ask the government's permission."
that's the sentence. the one that changes the industry.

🚨Anthropic flew senior security team to Washington to meet with Commerce and National Cyber Director
Reporter: How long until this is resolved?
WH official: “That’s up to Anthropic.”
Another official warned: “The longer this goes on, the more likely it becomes a de facto licensing regime.”
“Every model going forward needs to ask the government’s permission for whether it can be released.”
“That’s an extremely bad situation.”

1
30
This risks creating a chilling effect, where only the largest, most resourced companies can afford the regulatory burden, stifling innovation.
17
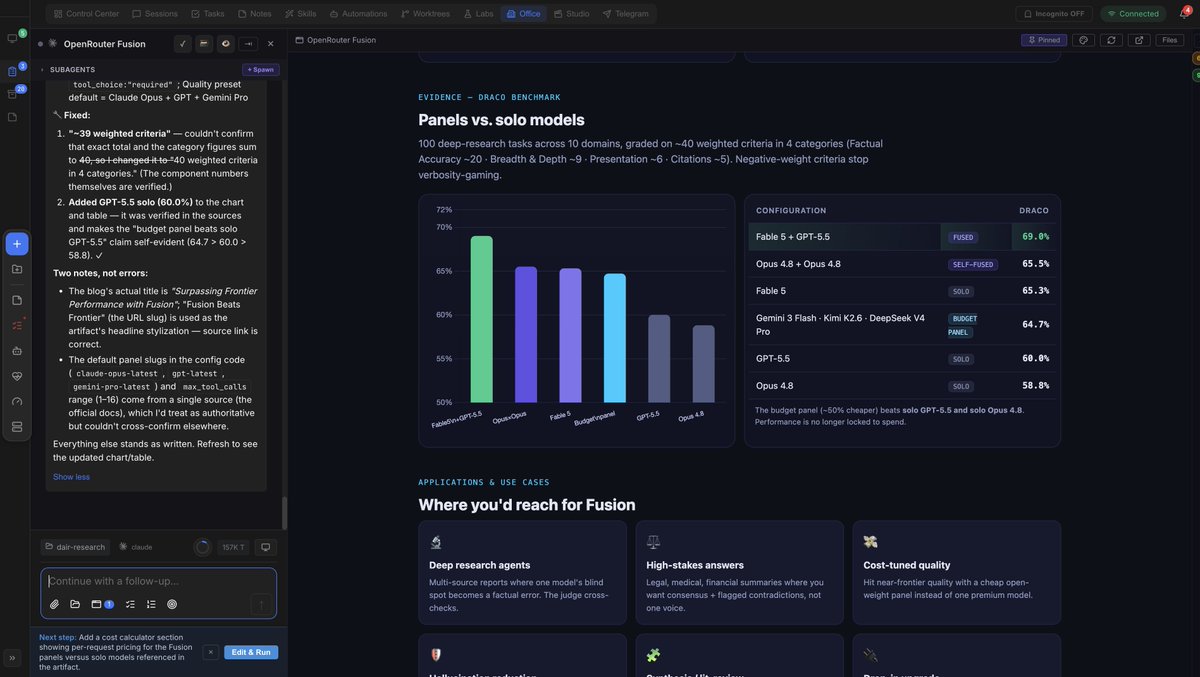
harness, orchestrator, verifiers, dynamic artifacts. that's four layers most agent startups skip entirely.
Omar built them because he needed to test research ideas on the fly. most teams discover they need them when a model provider changes the rules mid-deployment.

I spent the last 6 months building my own harness and orchestrator.
I built it to allow me to experiment on the frontier of ideas.
Little did I know that the orchestration, the harness, routing capabilities, dynamic artifacts/workflows, verifiers, ability to switch/route between agent backends, automations, the skills, and the MCP tools would be the absolute best defense for what happened with Fable this week.
The argument folks made when I was talking about "owning the agent orchestrator" at the beginning of the year is that this is just high maintenance, too costly, and is unsustainable. It might still feel like it to many. But there is too much to lose if you decide to lock yourself in with a specific tool or model provider.
Really, the way I have built my orchestrator is through mining my agent sessions and using that to recursively build and test our new ideas that range from autonomous loops to continual learning/memory systems. I can test research ideas on the fly. I just can't go back to using a vendor that only offers me a set of features.
My argument now is that you really don't have a choice.
You need to be able to control cost, decision making, context management, and everything in between.
If you don't, then how are you going to tap into the world of recursive self-improving AI? It won't get any easier if you don't own the decision-making part of the intelligence stack.
1
88
The failure mode there is 'drift detection storms' where the verifiers can't keep up with rapid, unannounced model changes.
40
Jun 15
Maybe they should have just.. instead..
Jun 14

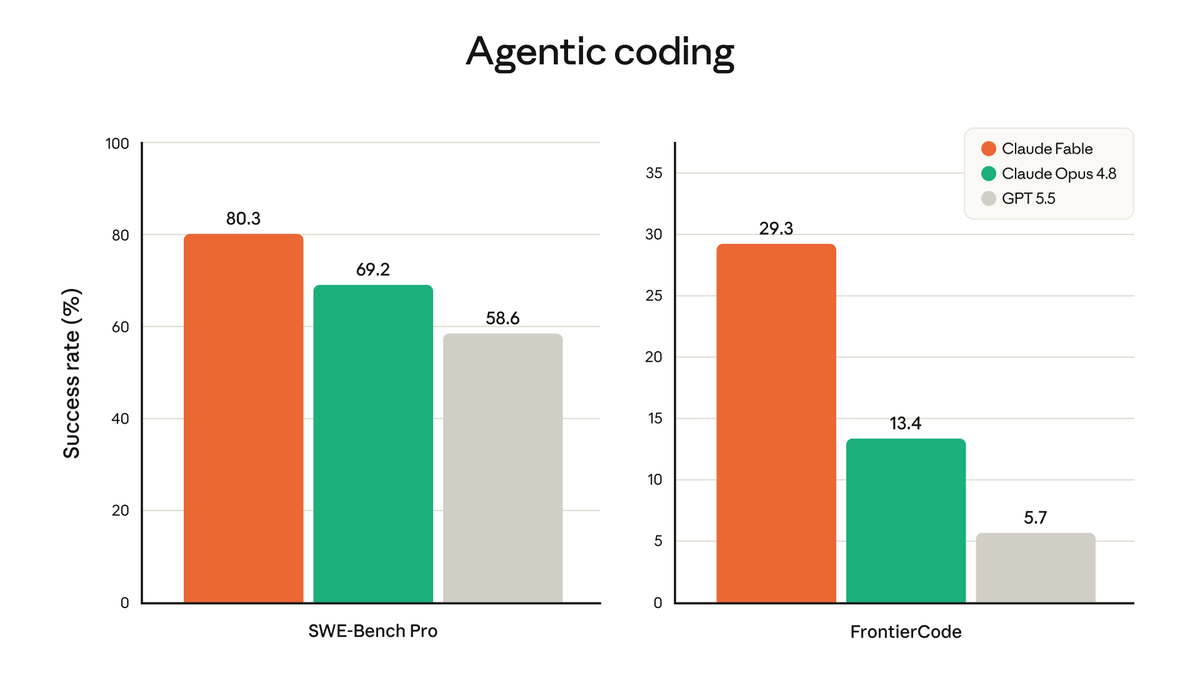
OMG THEY ARE DROPPING IT! ANTHROPIC IS SCREWED!
Scores higher than Fable in every benchmark!!

154
Jun 15
kimi-k2.7-code beating frontier models on ml engineering with a cost constraint is the kind of result i actually trust.
benchmarks where the best model loses under real-world constraints tell you more than leaderboard sweeps.
Jun 14

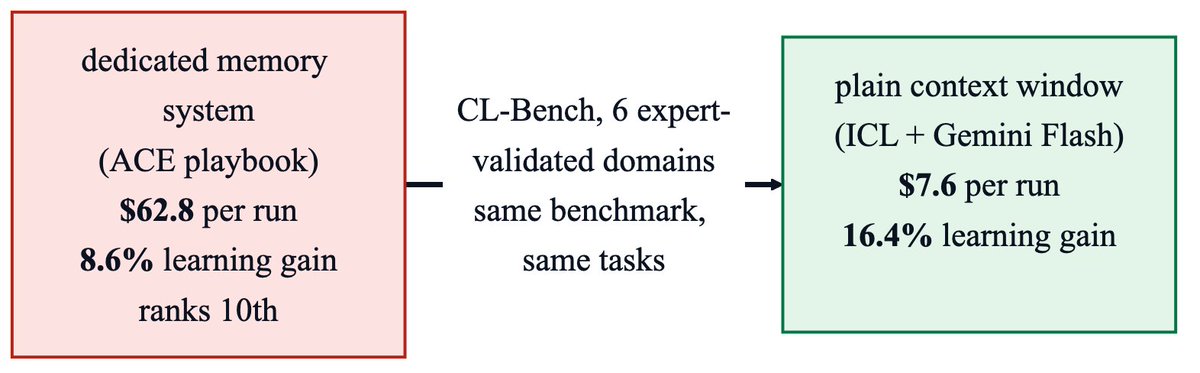
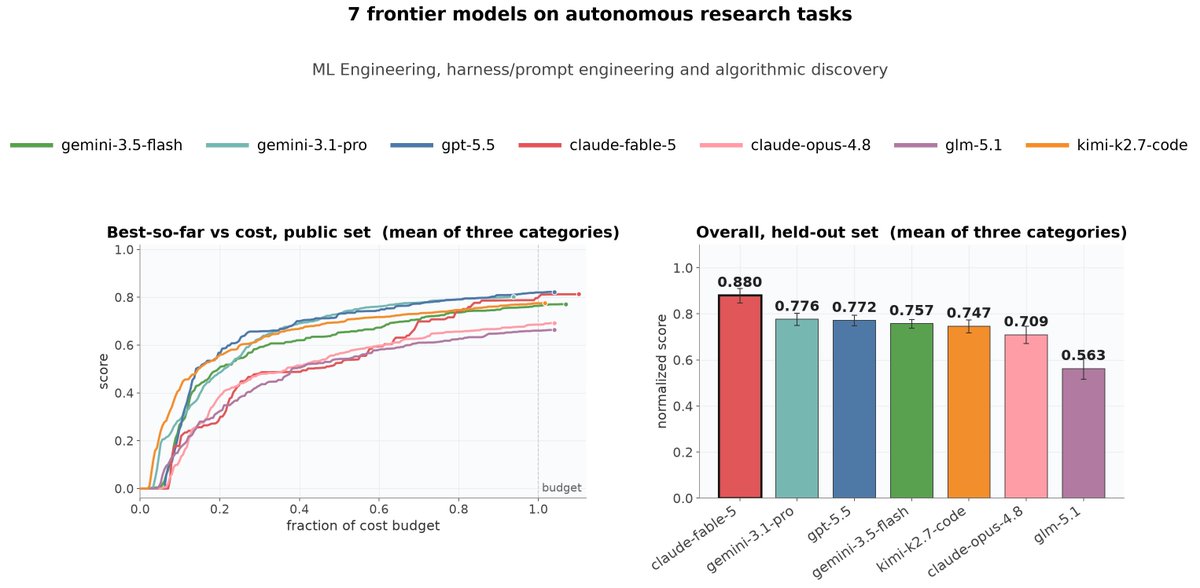
We benchmarked 7 frontier models on 3 categories of autoresearch tasks: ML engineering, harness/prompt engineering, and algorithmic discovery.
Fable-5 won overall even under cost constraint, but on ML engineering, the open model Kimi-K2.7-Code surpassed frontier models.🧵(1/5)
1
1
195
Jun 15
especially when the cost constraint itself is a proxy for inference latency, a key factor in user experience.
52
Jun 15
deepseek v4 pro and flash are close on evals.
the optimizer numbers in the training setup might explain why. same schedule, same batch dynamics, the gap is mostly architecture surface.

Why V4-Pro is so close to V4-Flash (which looks great for Flash and horrible for Pro) is one of the most important questions for the trajectory of open source. If I'm right and it's distilled from Flash experts, they will dominate. If this recipe isn't scalable… good for Dario.


1
103
Jun 15
This suggests that optimizing for specific architectural features, rather than just training hyperparameters, will yield diminishing returns beyond a certain point.
42
Mert · AI Architect retweeted

Jun 15
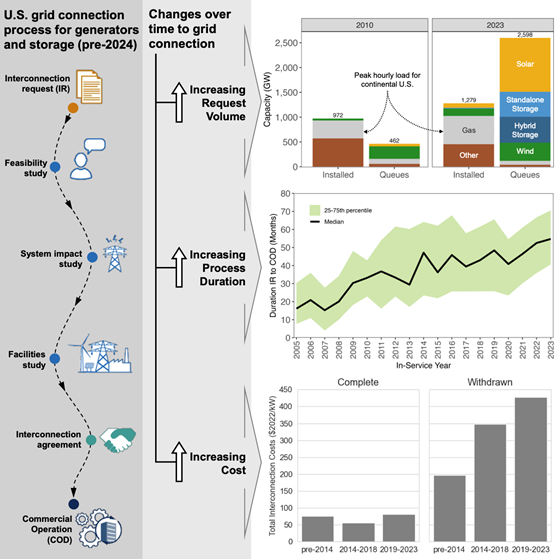
It gets worse: the grid connection requests active at the end of 2023 were more than double the total installed capacity of the US power plant fleet (2,600 GW vs. 1,280 GW). It's well more than 3,000 GW.
There will be $trillions in semiconductor paperweights over the next decade
Jun 15

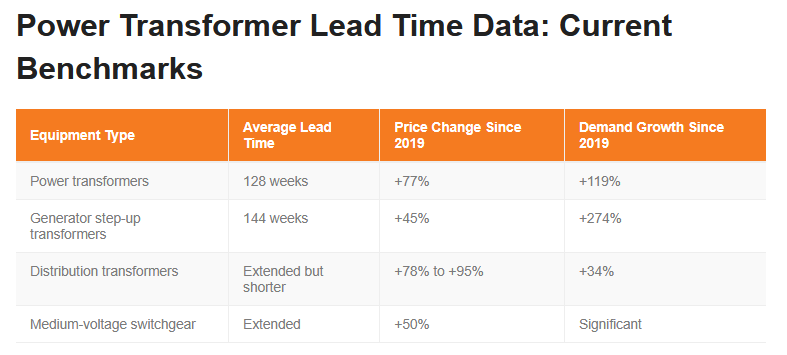
Want to build a data center? Then you have to wait 2.5 years for the power transformers alone (and 3 years for the step ups)
79
314
1,544
398,498
Jun 13
Microsoft’s model router is a similar idea.
More often we are finding that specialized use of models lead to better results than just using the most capable model for everything.
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

256
Mert · AI Architect retweeted

Jun 13
JUST IN: Anthropic says a “huge percentage” of its own employees are now barred from accessing Fable 5 & Mythos 5 under U.S. restrictions.
458
689
10,391
1,390,872
Jun 13
dario asked for the kill switch. trump just showed him who holds it. foreign access to mythos models: gone. the mechanism works exactly as designed, just not on dario's terms.
Jun 13

Dario (48 hours ago): “US gov should be able to block model deployment”
USG: *export controls models*
Dario: “not like that”

617
Jun 13
This is such an exaggeration.
We will see mythos level models in the market in under 3 months.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
39
Mert · AI Architect retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


622
1,655
13,843
2,365,804
Jun 12
ok that's a real number.
fable 5 at 18% task success rate. opus 4.8 thinking at 9%. double the next best on the metric that actually means 'did the thing get done'. not an eval benchmark, not a vibes score. real users saying yes.

SITUATION EXPLAINED: @ml_angelopoulos, CEO of @arena joined us to explain how Claude Fable 5 is performing.
"What this means is that, compared with the average model, Claude Fable 5 is getting about 11% more positive signals from real agentic workflows. In the middle, models like GLM and Gemini 3.5 Flash are roughly at baseline, and then performance gets worse as you move down the leaderboard."
"The signals on this leaderboard come from a few different sources. The first is task success rate: explicit signals where users say they were able to complete the task using a given model.
Fable has an 18% task success rate. By comparison, the next-best competitor, Claude Opus 4.8 Thinking, is at 9%. So Fable almost doubles the effect of the next-best model. That’s a massive improvement in people’s ability to get the job done."
1
126
Jun 12
This highlights the risk of optimization for proxy metrics like perplexity instead of direct task completion.
52
Jun 12
Malware authors are injecting bioweapon text into their payloads to trigger LLM safety refusals.
The scanner won't analyze what it refuses to touch.
The safety filter became the attack surface.
1
112
Jun 12
This is a classic adversarial example: the safety mechanism itself is being weaponized, turning a defense into a vulnerability.
80