
Where AI meets the real world. Formerly LMArena. We measure and advance the frontier of AI through community-driven evaluation. We’re hiring → arena.ai/jobs
Joined March 2023
- Tweets 3,312
- Following 215
- Followers 166,202
- Likes 2,446
1,453 Photos and videos











Introducing Agent Mode: Agentic AI is now measured in the Arena.
Agent Mode can do deep research, create reports, generate images, build websites, debug code, and more.
It completes more complex tasks by using tools like web search, bash in a sandbox environment, image generation, file writing, and asking follow-up questions.
Frontier models are waiting for you in Agent Mode to take on real-world tasks. GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and top open models. Test them yourself.
43
49
461
253,005
Our first impressions with @AnthropicAI's Claude Fable 5 in the Agent Arena by @petergostev
youtube.com/watch?v=db_ci3HY…
1
3
19
14,700
Open-source model, Kimi-K2.7-Code by @Kimi_Moonshot is in the Code Arena: Frontend.
In the Code Arena, you can build full web apps and interactive sites from prompts and image uploads. Your feedback drives the Code Arena: Frontend leaderboard.
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


8
16
236
17,955
Work with Kimi-K2.7-Code and other top frontier models in the Code Arena: Frontend at: arena.ai/code
1
14
3,856
Here's where the Code Arena: Frontend leaderboard stands right now: arena.ai/leaderboard/code/we…
12
3,557
Find more technical details of Claude Fable-5 on Agent Arena leaderboard
arena.ai/leaderboard/agent
2
14
6,653
The official statement from @AnthropicAI
x.com/AnthropicAI/status/206…
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
2
37
9,295
Update: We've removed Claude Fable 5 from Arena, following Anthropic's latest announcement and the U.S. government directive to suspend access.
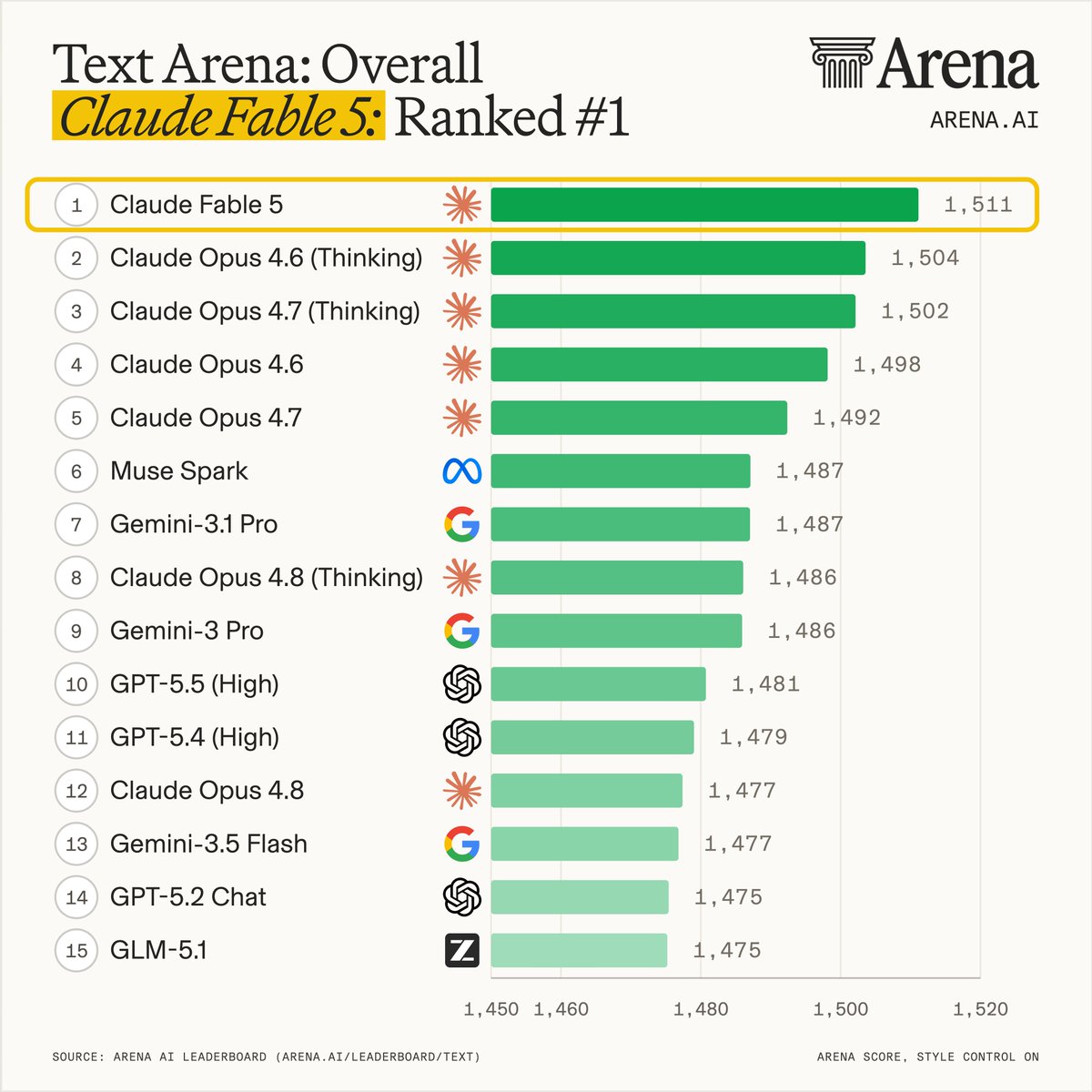
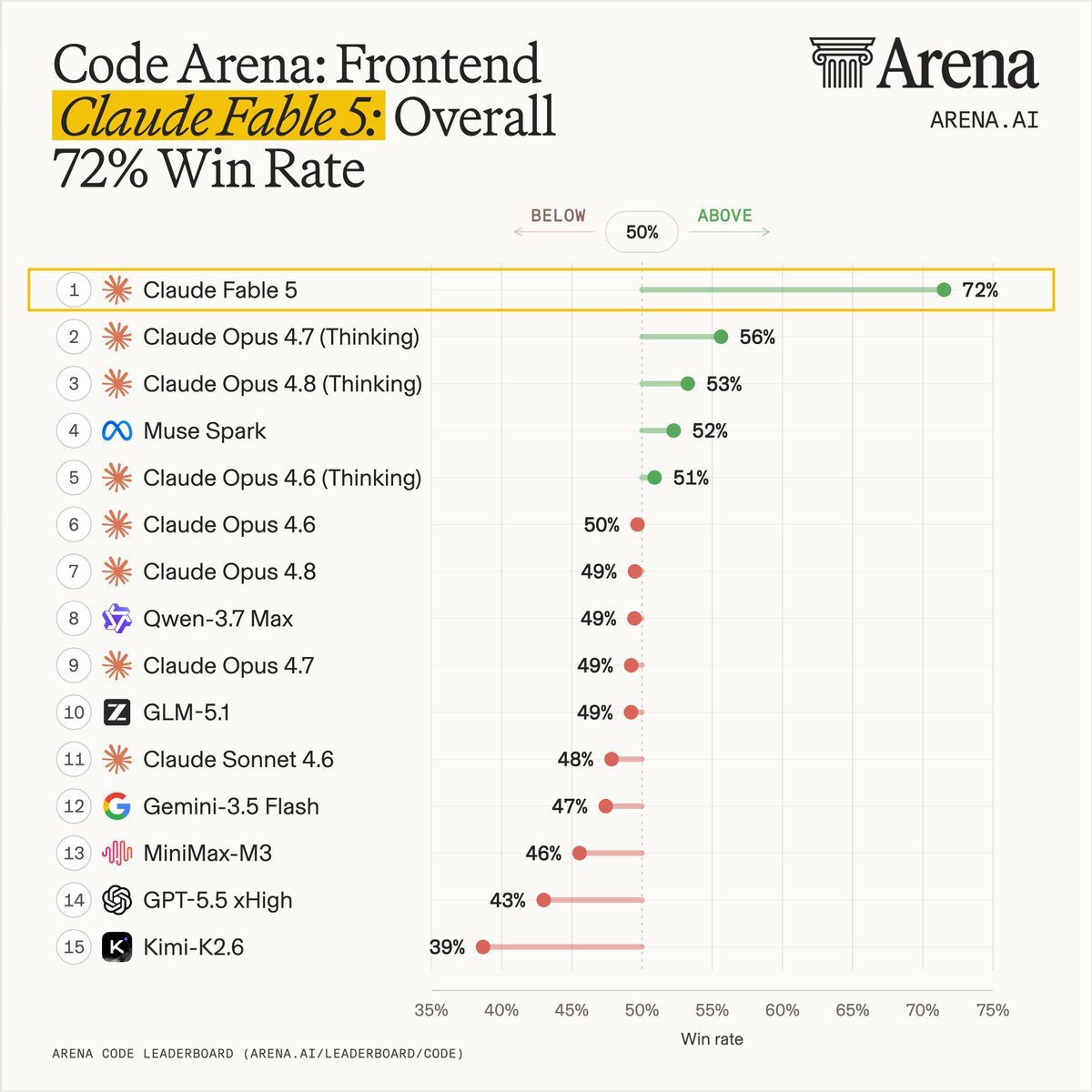
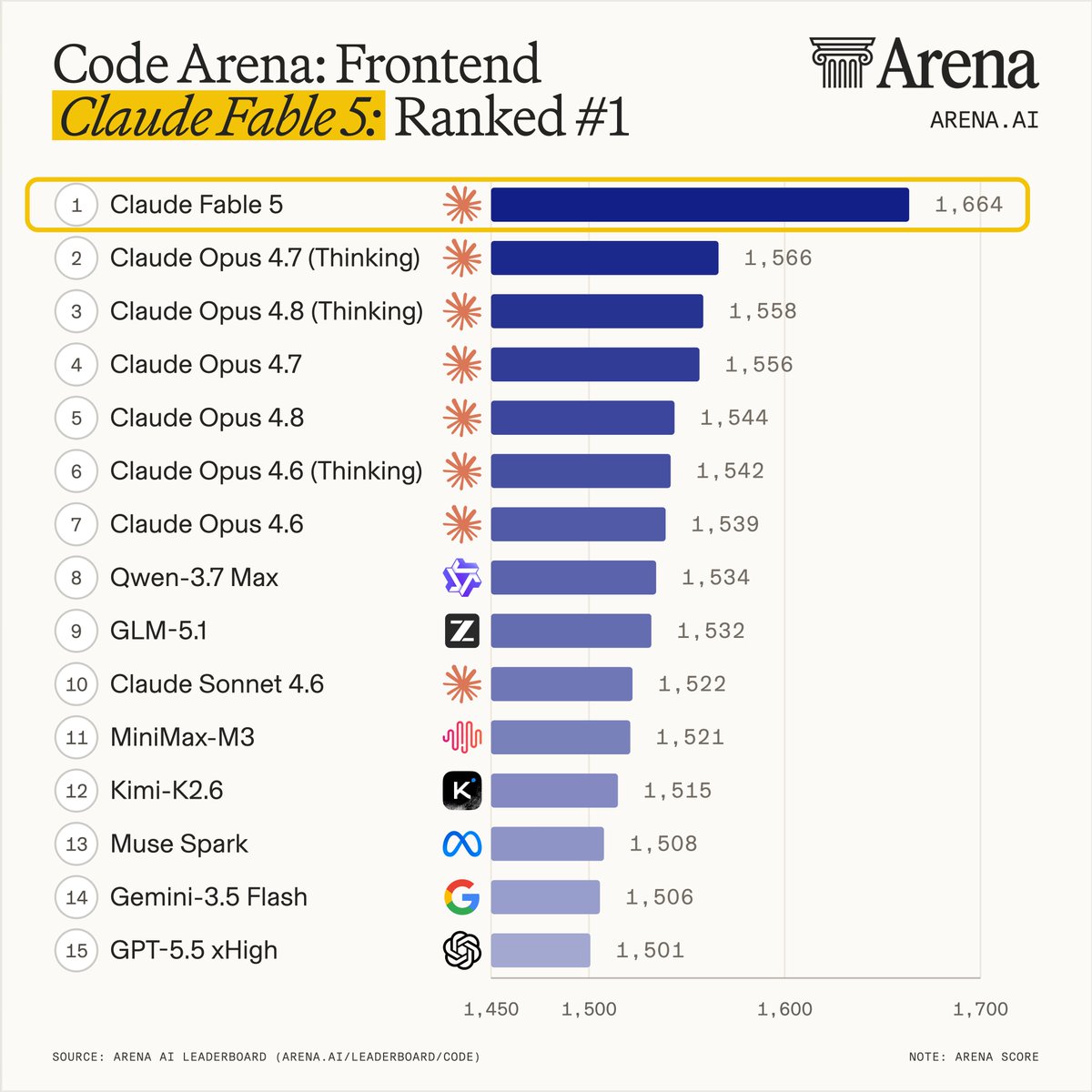
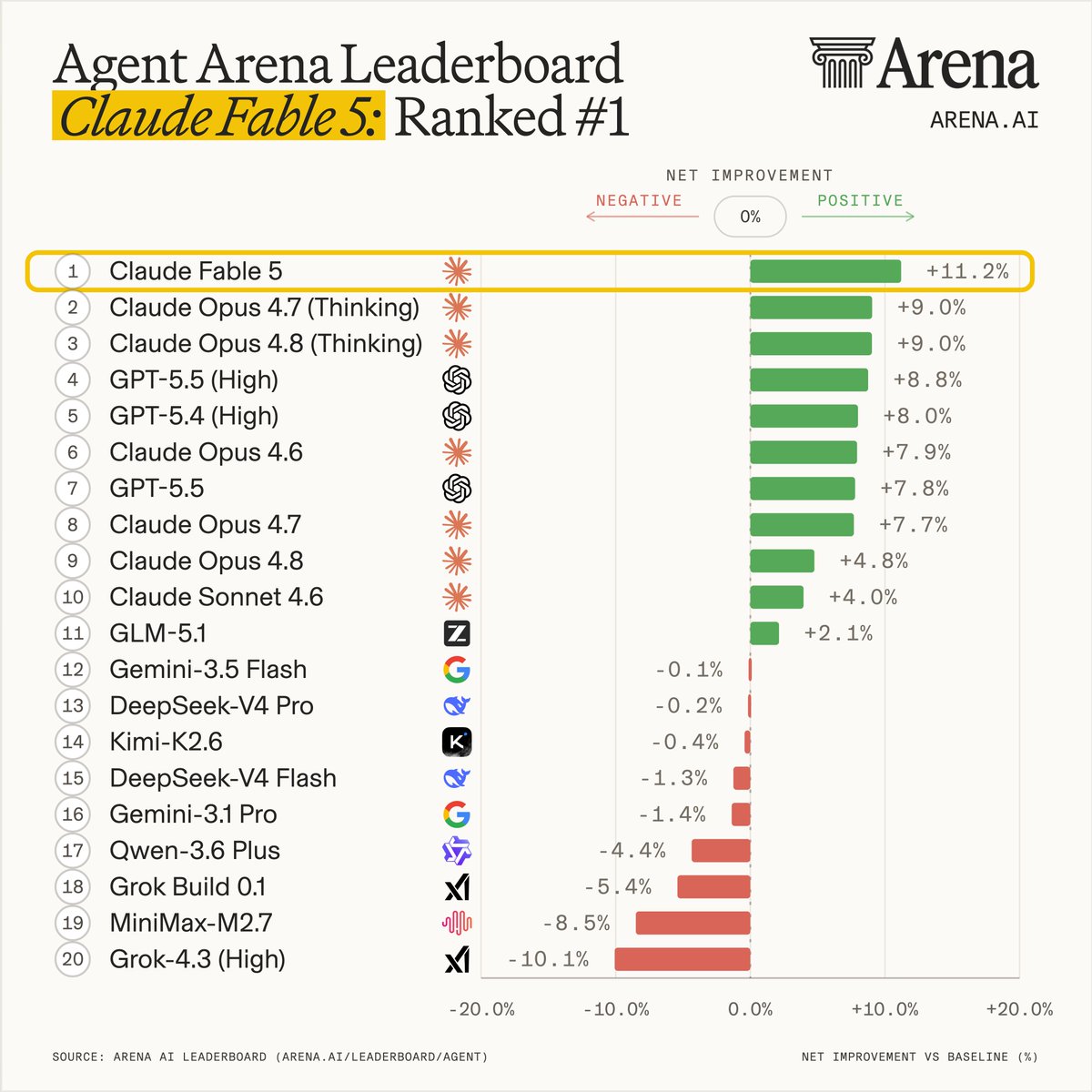
Claude Fable 5 is the most powerful model we’ve ever tested - ranking #1 across Agent, Text, and Code Arena, and setting a new breakthrough for frontier AI performance.
We look forward to restoring access and resuming community testing when possible.

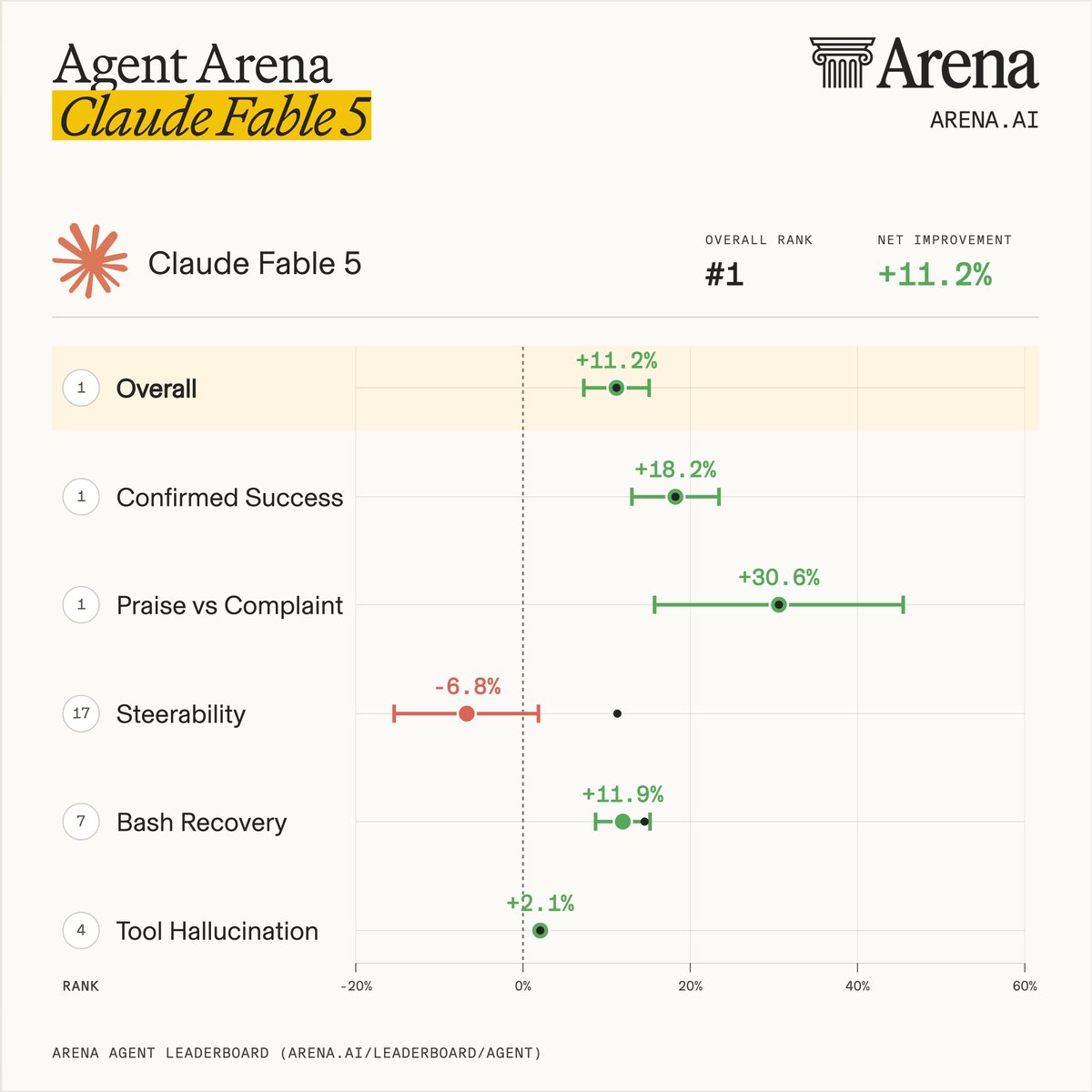
Exciting news: Claude Fable 5 ranks #1 on the new Agent Arena leaderboard!
Fable 5 leads by the widest margin ever over Opus-4.8 and GPT-5.5 on two key signals: confirmed task success rate and praise vs. complaint, despite weaker steerability. If Fable can do something, it will do it very well. If it can't/doesn't want to do something, it may be hard to steer the model towards the goal.
In Agent Arena, we measure models on millions of real-world, long-horizon agentic tasks. Models get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
We use the causal tracing methodology to measure a model's net improvement which indicates how much it improves outcomes relative to the average model.
Huge congrats to @AnthropicAI for the incredible milestone! Below we break down how Claude Fable 5 (based on Mythos) scored across 5 signals, drawn from tasks submitted by a global community of users.
44
48
867
110,896
Open-weight model, MiniMax M3 by @MiniMax_AI is available in the Agent Arena.
In Agent Arena, models get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session contributes to the Agent Arena leaderboard. Scores for MiniMax M3 coming soon.
Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
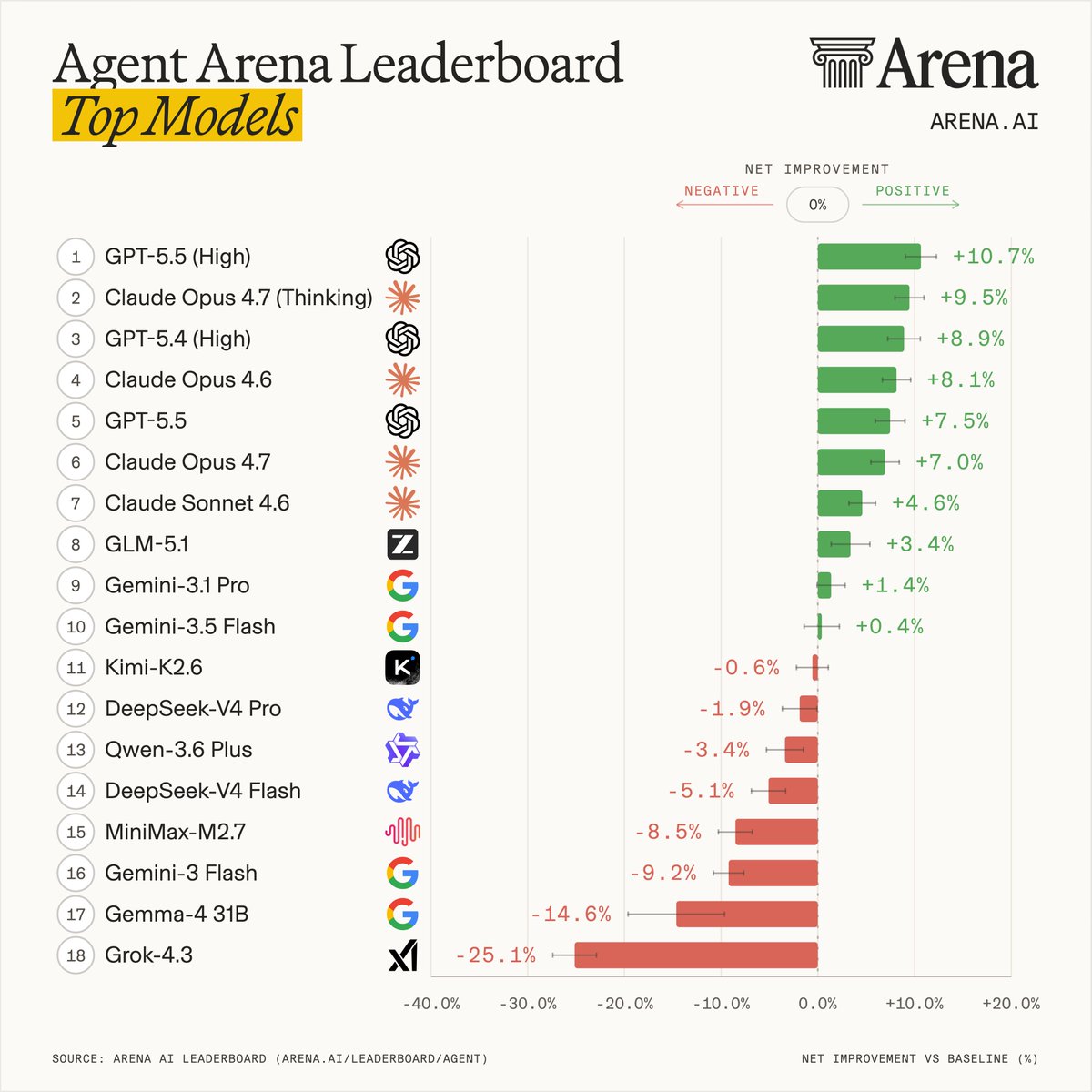
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K tasks, 2M tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
4
5
88
10,774
Tackle your complex real-world tasks while contributing to frontier AI measurement at: arena.ai/agent
7
3,839
The newest open model to join the Agent Arena leaderboard, Nemotron 3 Ultra by @NVIDIA lands at #20 overall and #5 among open models.
Its standout signals are a positive praise-vs-complaint margin and low tool hallucination, but it's held back by steerability and bash recovery. Note the wide confidence intervals as scores are still stabilizing.
In Agent Arena, models get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
We use the causal tracing methodology to measure a model's net improvement which indicates how much it improves outcomes relative to the average model.
See in thread how Nemotron 3 Ultra scored across 5 signals, drawn from tasks submitted by a global community of users.
Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K tasks, 2M tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
7
7
185
16,031
Learn more about the causal tracing methodology for Agent Arena on our blog: arena.ai/blog/agent-arena-me…
1
5
3,309
Head over to the Agent Arena leaderboard to dive into the details: arena.ai/leaderboard/agent
4
2,538
Check out first impressions with @AnthropicAI’s Claude Fable 5 in the Agent Arena with @petergostev on our YouTube:
youtu.be/db_ci3HYth8
6
49
25,945
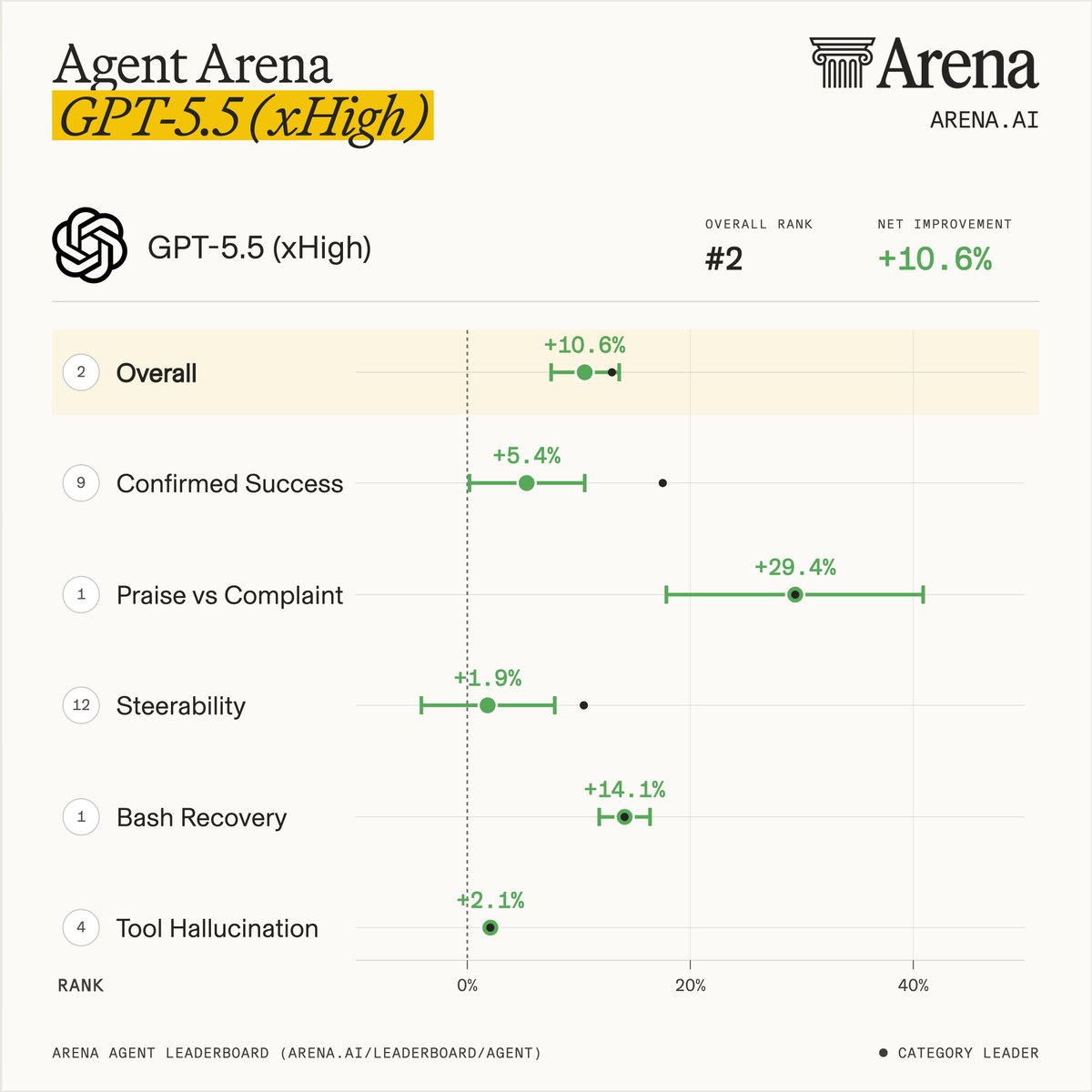
GPT-5.5 (xHigh) ranks #2 on Agent Arena ( 10.6% net improvement), making it the highest-ranked OpenAI model closely behind Claude Fable 5 (High).
Per signal breakdown, GPT-5.5 (xHigh) ranks #1 in Praise vs. Complaint ( 29.4%) and Bash Recovery ( 14.1%), scoring higher than Claude Fable 5 (High) on both signals. It trails Claude Fable 5 (High) on Confirmed Success ( 5.4% vs. 17.6%) and Steerability ( 1.9% vs. 5.4%).
Agent Arena evaluates models on millions of real-world, long-horizon agentic tasks. Models use tools like web search, filesystem, and terminal to complete complex workflows: writing code, creating slide decks, researching the web, building apps, and analyzing documents.
We use causal tracing to measure model performance across real-world agentic tasks. More breakdown of GPT-5.5 (xHigh) across five signals in the thread.
Introducing Agent Mode: Agentic AI is now measured in the Arena.
Agent Mode can do deep research, create reports, generate images, build websites, debug code, and more.
It completes more complex tasks by using tools like web search, bash in a sandbox environment, image generation, file writing, and asking follow-up questions.
Frontier models are waiting for you in Agent Mode to take on real-world tasks. GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and top open models. Test them yourself.
20
39
472
45,520
Learn more about the Agent Arena methodology here: arena.ai/blog/agent-arena-me…
2
1
8
3,765
Full Agent Arena leaderboard: arena.ai/leaderboard/agent
6
3,617