
Driving innovations with open communities. 💬 Join our Discord: discord.gg/hgKcfgXHAQ
Joined April 2024
- Tweets 788
- Following 141
- Followers 9,184
- Likes 129
416 Photos and videos







Jun 12
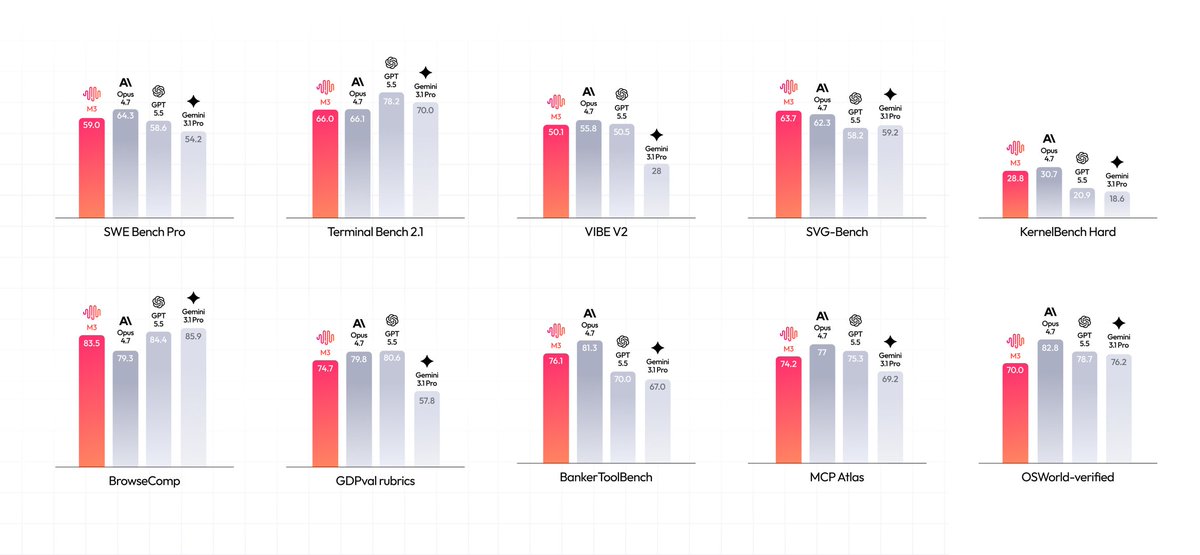
MiniMax M3 is now open source! The model combines native multimodal understanding, ultra-long context, and Agent capabilities in one.🚀
New MSA architecture: up to 1M context at 1/20 the per-token compute of the previous gen. 9x faster prefilling, 15x faster decoding, on par with full attention on most tasks.
Two versions 👇: MiniMax-M3 (full precision) and MiniMax-M3-MXFP8 (quantized, lower VRAM).
🤖 modelscope.ai/models/MiniMax…
🤖 modelscope.ai/models/MiniMax…
🧠 12hrs autonomous: reproduced an ICLR 2025 Outstanding Paper end to end, 18 commits 23 experiment plots
⚡ 147 iterations, 9.4x CUDA speedup: FP8 matmul kernel on Hopper, peak utilization 7.6% → 71.3%, zero human intervention
🛠️ PostTrainBench: scored 37.1, ranking 3rd behind Opus 4.7 (42.4) and GPT-5.5 (39.3)
4
18
239
27,466
Jun 12
DiffusionGemma is here! Google DeepMind’s open-weights 25.2B MoE model brings discrete diffusion to Gemma 4, with 3.8B active params and block-level text generation. 🚀
🤖 modelscope.ai/models/google/…
• Speed: parallel denoising generates 15-20 tokens per forward pass, with reported >1100 tokens/s in low-batch FP8 settings
• Architecture: encoder caches prompt context, decoder denoises 256-token canvases with bidirectional attention
• Context: up to 256K tokens, native system prompt support, function calling, and configurable thinking mode
• Multimodal: text image input, video as frames up to 60s, variable image token budgets from 70 to 1120
• Benchmarks: 77.6% MMLU Pro, 73.2% GPQA Diamond, 69.1% AIME 2026 no tools, 69.1% LiveCodeBench v6
• License: Apache 2.0
2
70
3,092
Jun 12
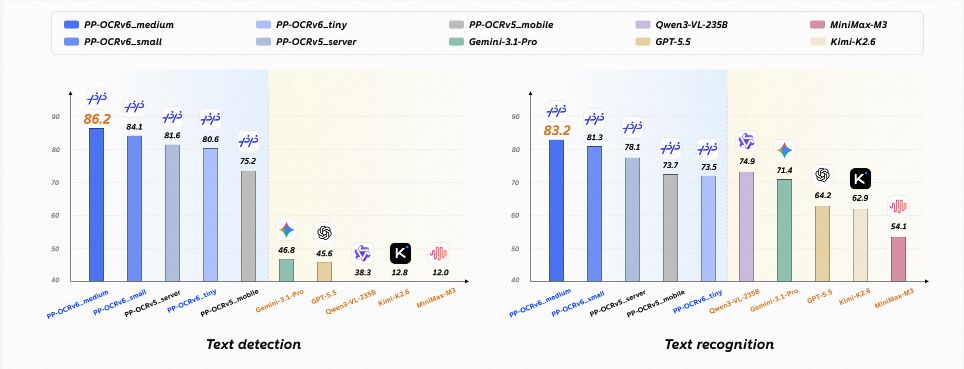
PP-OCRv6 just landed on ModelScope! PaddleOCR’s new OCR model series scales from 1.5M to 34.5M params and surpasses billion-scale VLMs on OCR tasks. 🚀
🤖 modelscope.ai/collections/Pa…
• Models: tiny 1.5M, small 7.7M, medium 34.5M for edge, mobile, and server deployment
• Accuracy: medium tier improves over PP-OCRv5_server by 4.6% detection and 5.1% recognition
• VLM comparison: surpasses Qwen3-VL-235B and GPT-5.5 on reported OCR benchmarks with only 34.5M params
• Languages: one unified model covers Chinese, English, Japanese, and 46 Latin-script languages
• Speed: 5.2x CPU end-to-end speedup with OpenVINO, 6.1x on Apple M4 tiny, 0.13s on A100 GPU
• License: Apache 2.0
7
111
5,468
Jun 11
This one is seriously adorable! 💖
Allin-ModelScopeIP-Inspiration-Qwen2512 turns text prompts into inspirational IP visuals Perfect for character concepts, collectible designs, and creative experimentation. 🎨🖌️
🔗modelscope.ai/models/orangeH…
A must-try if you’re exploring new IP styles, toy design, or creative LoRA inspiration.
• Format: BF16 safetensors LoRA
• Checkpoints: ckpt-5, ckpt-10, ckpt-15, ckpt-20, about 236MB each
• Task: text-to-image synthesis on Qwen-Image
• License: Apache 2.0



1
10
843
Jun 10
🚀 Multi-Node RL Training with Megatron backend is now live in ms-SWIFT:
swift.readthedocs.io/en/late…
With our newly introduced Ray extension, orchestrating multi-node RL training on a Ray cluster is now as simple as a familiar YAML config, offering:
🔀 Flexible GPU Allocation | Colocation or separation of training & inference nodes.
🧠 Comprehensive RL Support | GRPO/DAPO/GSPO/SAPO etc., with multi-turn agentic RL supported.
⚡ Megatron Parallelism | Scale seamlessly with TP, PP, CP, and EP.
🎓 GKD / OPSD | Top-k & full-vocab teacher logits, with versatile grouping of GPUs.
🤖 Extensive Model Coverage | 300 LLMs & 200 MLLMs (Full-param & LoRA), covering all frontier models.
Learn more at:
💻 GitHub: github.com/modelscope/ms-swi…
📖 Docs: swift.readthedocs.io/en/late…
📝 Examples: github.com/modelscope/ms-swi…
13
1,645
Jun 10
Nex-N2-Pro API inference is now live on ModelScope! 🚀
Try it directly through the ModelScope API and start building with it today!
modelscope.ai/models/nex-agi…
Jun 8

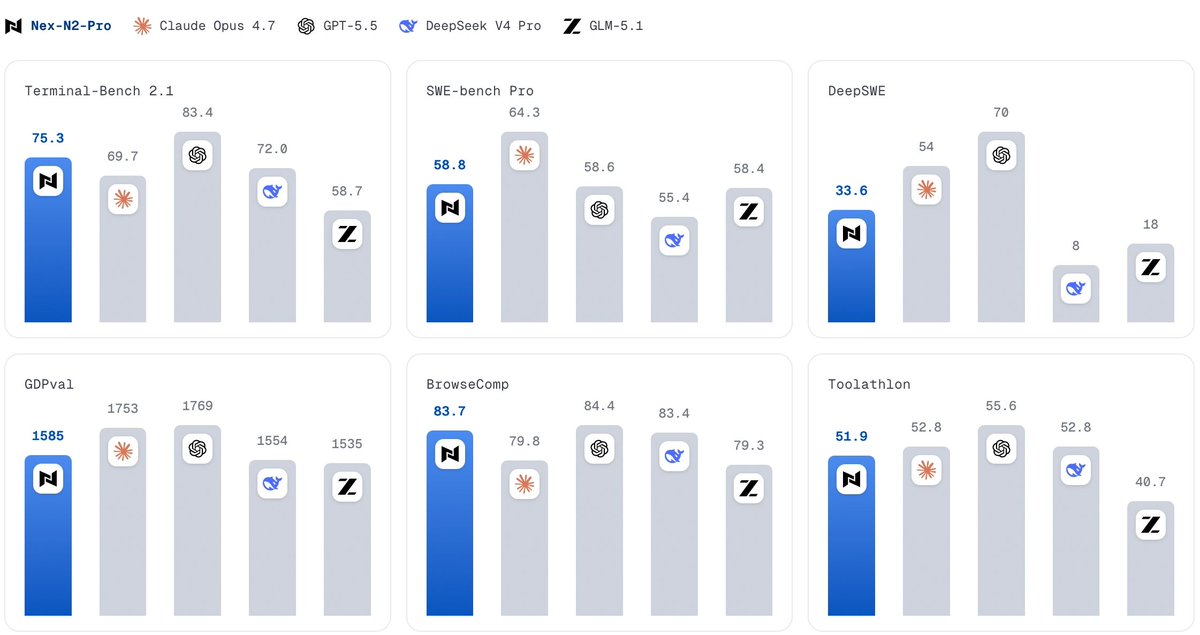
Nex-N2 is now open source!An agentic model series from Nex AGI built for coding, tool use, deep research, and long-horizon workflows. 🧠🔎
🛠️ modelscope.ai/models/nex-agi…
⚙️ modelscope.ai/models/nex-agi…
● Models: Nex-N2-Pro 397B total, 17B active; Nex-N2-mini 35B total, 3B active
● Agentic Thinking: adaptive reasoning depth coherent reasoning across coding, search, tool calling, and execution
● Efficiency: Nex-N2-mini saves roughly 20% overall token cost vs forced thinking while matching or slightly exceeding task performance
● Open-model lead: 75.3 on Terminal-Bench 2.1, 80.8 on SWE-Bench Verified, 83.7 on BrowseComp, and 1585 on GDPval among listed open baselines
● Deployment: customized SGLang fork, reasoning parser, tool-call parser, Docker image
● License: Apache 2.0
5
64
4,875
Jun 10
Obsessed with this one. 👀
NewChinese_IPfigurine by @WarmBlood_Aban turns character ideas into collectible-style visuals with a fresh New Chinese aesthetic. 🏮
A fun one for character design, toy concepts, and original IP exploration.
🔗 Try it on ModelScope:
modelscope.ai/models/zhouwen…
• Model size: 2.12GB
• Training data: 32 samples
• Training steps: 2,000
• Base model: Qwen-Image-2512 LoRA
• License: Apache 2.0

1
1
17
1,096
Jun 9
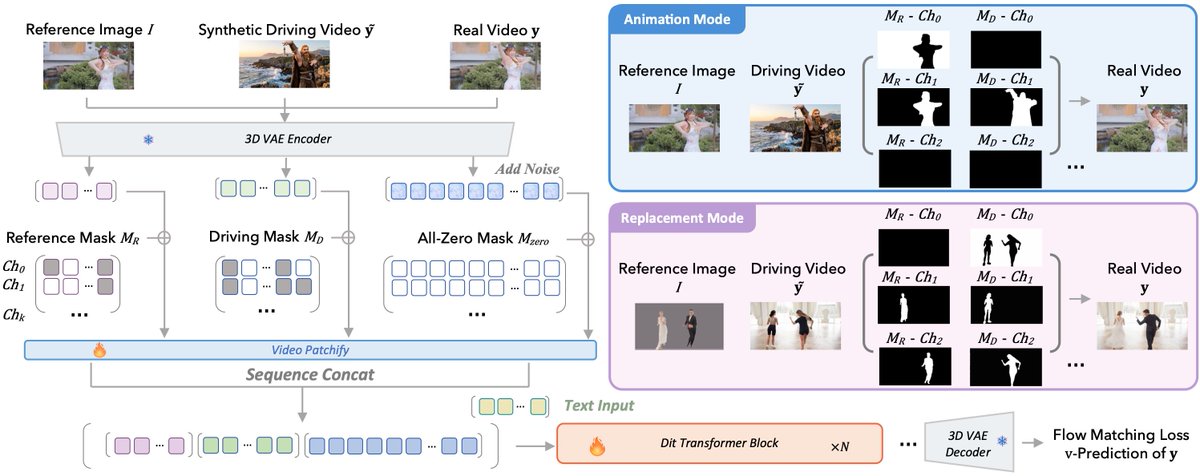
New on ModelScope! Meet SCAIL-2, ZhipuAI’s studio-grade character animation model for reference-image driven motion transfer with improved stability, clarity, and native long-video generation. 🚀
🤖 modelscope.ai/models/ZhipuAI…
🎬 3D pose control: preserves depth, orientation, and spatial relationships
📽️ Long video: improved stability and clarity over SCAIL-Preview
🤸 Hard motions: handles flips, turns, occlusion, and multi-character interactions
🧩 Workflow: reference image driving video rendered 3D pose sequence, with ComfyUI support
📜 License: Apache 2.0

4
4
49
3,711
Jun 9
OSCAR INT2 KV cache by @ZhongzhuZhou makes ultra-long context more practical on local devices. 🔥🚀
🔗modelscope.ai/models/togethe…
💾 KV memory: reduces Gemma 4 12B-it’s KV cache at 256K context from ~24 GiB to ~3 GiB, saving ~21 GiB
📉 Compression: ~8× smaller KV footprint with q2_0 INT2 KV cache
🧠 Method: calibrated rotations use query covariance for Keys and score-weighted value covariance for Values
🎯 Quality: pushes quantization noise into attention-insensitive directions to preserve near-f16 KV behavior
🖥️ Deployment: Gemma 4 12B now supports both ready-to-run INT2 KV GGUF models through the llama.cpp fork and INT2 KV cache through SGLang. The local path also includes Apple Metal support and fused mixed-precision flash attention.
🧩 Model support: Qwen3 with head dim 128 and Gemma 4 with head dim 512, including Gemma 4 12B-it with sliding-window layers
2
11
64
5,944
Jun 8
Nex-N2 is now open source!An agentic model series from Nex AGI built for coding, tool use, deep research, and long-horizon workflows. 🧠🔎
🛠️ modelscope.ai/models/nex-agi…
⚙️ modelscope.ai/models/nex-agi…
● Models: Nex-N2-Pro 397B total, 17B active; Nex-N2-mini 35B total, 3B active
● Agentic Thinking: adaptive reasoning depth coherent reasoning across coding, search, tool calling, and execution
● Efficiency: Nex-N2-mini saves roughly 20% overall token cost vs forced thinking while matching or slightly exceeding task performance
● Open-model lead: 75.3 on Terminal-Bench 2.1, 80.8 on SWE-Bench Verified, 83.7 on BrowseComp, and 1585 on GDPval among listed open baselines
● Deployment: customized SGLang fork, reasoning parser, tool-call parser, Docker image
● License: Apache 2.0
32
80
837
81,993
Jun 5
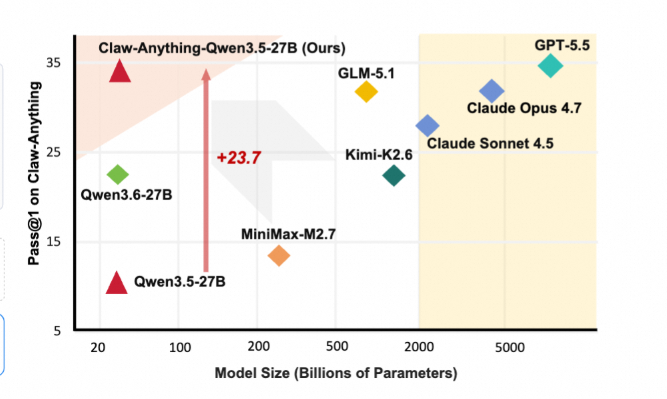
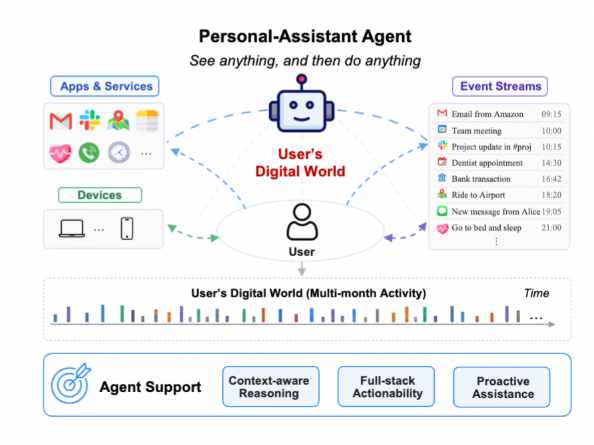
Introducing Claw-Anything by @haiyang73756134 , a benchmark and training set for always-on personal assistants with broader access to the user's digital world. 🚀
🤖 modelscope.ai/datasets/Liber…
📄 modelscope.ai/papers/2605.26…
● Benchmark: 200 human-verified eval tasks across skill, tool, and GUI settings
● Training: 2,015 auto-generated environments across 25 personas, 4 execution dates, and 2 difficulty levels
● Context: long-horizon event streams, interconnected services, and CLI Android GUI interaction
● Gap: GPT-5.5 reaches only 34.5% pass@1, showing current agents still struggle with broad always-on assistance
● Data pipeline: training traces improve the base model by 23.7 pass@1
● License: Apache 2.0
2
1
16
2,334
Jun 5
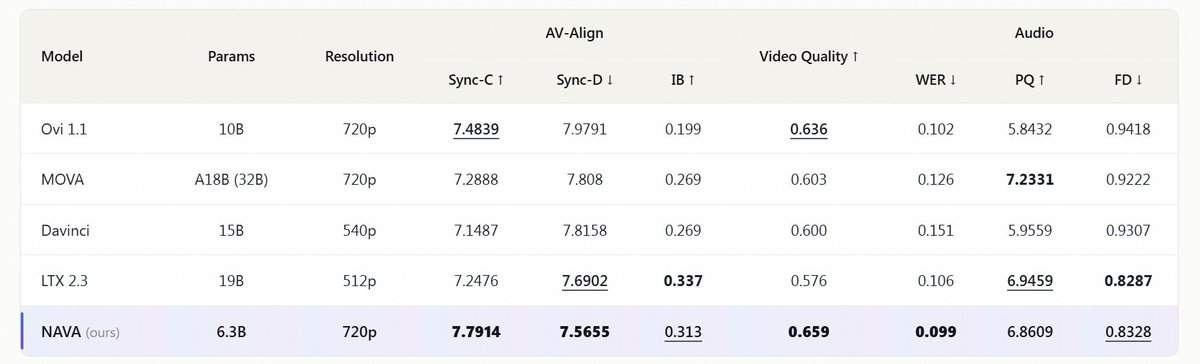
NAVA just landed on ModelScope!6.3B parameters, one prompt input, synchronized 720p video and stereo audio output.
🔗 modelscope.ai/models/ernie-r…
📝 modelscope.ai/papers/2605.30…
🌟 Benchmarks: SOTA AV sync on VerseBench, with 7.7914 Sync-C and 7.5655 Sync-D, using 2× to 5× fewer parameters than open baselines
⚡ Speed: 720p 1-min generation in about 1 minute via 8-GPU Ulysses sequence parallel🎙️ Audio: dual-channel stereo for scene speech, jointly denoised with video, no post-hoc vocoder alignment
🧩 Control: reference WAVs bind speaker timbre to <S>...<E> spans; camera composition, motion, and pacing follow language prompts
🧠 Resolution: landscape, portrait, and square aspect ratios from the same checkpoint
🧾 License: Apache 2.0
2
5
52
3,167
Jun 4
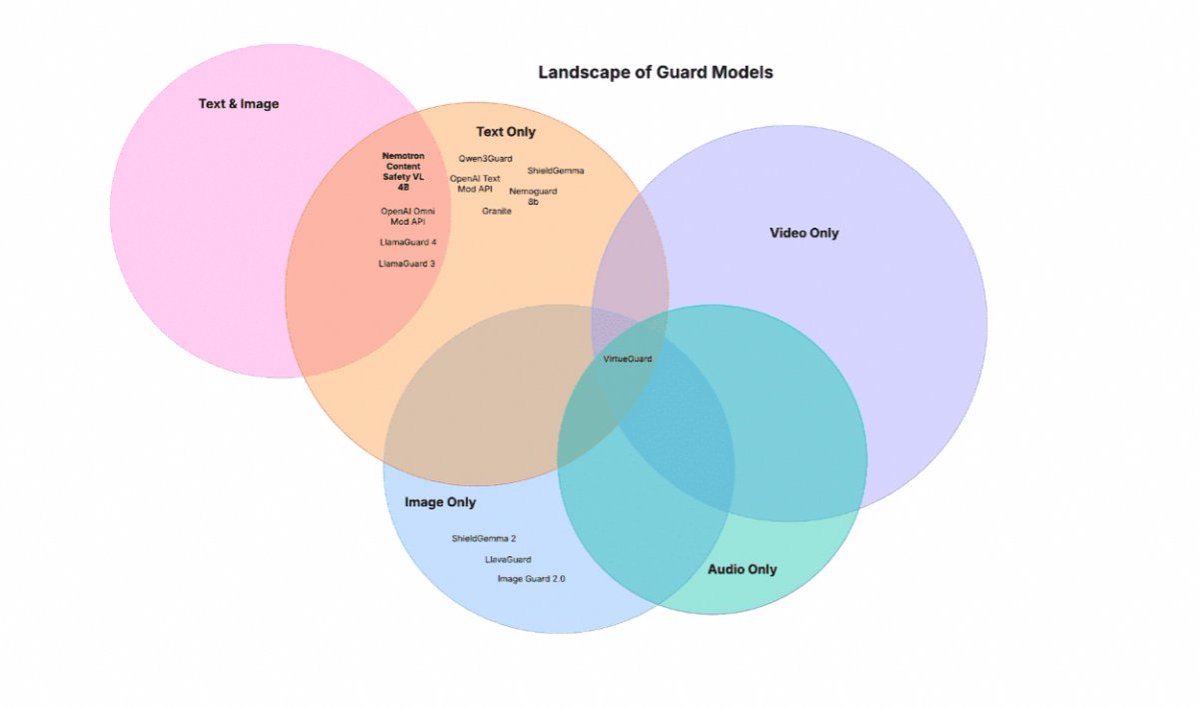
Nemotron 3.5 Content Safety is now live from @NVIDIAAI 🤖One 4B model, three capabilities.
🛡️modelscope.ai/models/nv-comm…
● Multimodal safety: #1 on VLGuard (.903), beating Llama Guard 4 12B (.653) and OpenAI Omni (.216)
● Custom policy: BYO safety rules at inference time, no retraining. Scores .915 on DynaGuardRail safety and .902 on prompt injection
● Multilingual: 12 languages, beating Llama Guard 4 and OpenAI Omni on every multilingual benchmark
Open weights and training data are available under the OpenMDW-1.1 license.
1
3
24
1,667
Jun 4
Nemotron 3.5 ASR from @NVIDIAAI is built for real-time voice agents.
🌍modelscope.ai/models/nv-comm…
Voice agents need to listen in real time. Nemotron 3.5 ASR is built for that.
● Streaming-first with sub-100ms latency, with runtime-configurable latency for live pipelines
● 40 language-locales across Europe, Asia, and the Americas
● Native punctuation and capitalization out of the box
Built for voice agents, call centers, meeting transcription, in-car assistants, and live captions.
1
9
1,011
Jun 4
Meet Nemotron 3 Ultra @NVIDIAAI 's frontier open reasoning model built for long-running AI agents.🚀
🤖 modelscope.ai/models/nv-comm…
- 550B total / 55B active parameters, using a hybrid MoE design – only a fraction of the parameters are activated per token.
- Up to 1M-token context window.
- Up to 5x faster inference and up to 30% lower cost on complex agentic tasks
- Open weights, training data and recipes under the OpenMDW-1.1 license. Nemotron 3 Ultra is one to try.

3
8
77
4,775
Jun 4
We just added Stable Video Infinity to ModelScope. Infinite length video generation with Error Recycling Fine Tuning, from VITA@EPFL, ICLR 2026 Oral.
🤖 modelscope.ai/models/epfl-vi…
📄 modelscope.ai/papers/2510.09…
🏆Benchmark: SVI-Shot reaches 93.52% subject consistency and 95.86% background consistency on consistent video generation, vs 85.62% subject consistency for FramePack
📽️Ultra-long: at 250s, SVI-Shot reports 97.50% subject consistency with only a 0.63% drop as length scales, while FramePack drops 13.71%
📊Quality: 58.07% aesthetic quality, 62.81% imaging quality, 98.42% motion smoothness
🧵 Control: SVI-Film supports text prompt streams with 1 prompt per 5s clip; SVI-Talk and SVI-Dance add audio and skeleton conditioning
🧠Adaptation: fine-tune lightweight LoRA adapters with limited data to build custom SVI models for new video tasks
MIT model repo,Check it out on ModelScope.
5
45
3,036
Jun 4
JoyAI-Echo is now on ModelScope. Minute-level multi-shot audio-video generation from Joy Future Academy, JD, with paired cross-modal memory for story-level consistency.
🤖 modelscope.ai/models/jd-open…
● Long video: 5 min coherent stories from one prompt JSON
● Speed: 7.5x faster than the original multi-step pipeline with DMD-distilled few-step inference
● Large-scale evaluation: 3,000 generated shots across 100 benchmark stories
● Long-video human eval:preferred over HappyOyster on long-video visual aesthetics 63.6%, audio quality 81.7%, prompt following 80.6%, IP consistency 59.4%
● Short video comparison: preferred over Wan 2.6 on visual aesthetics 58.8% and prompt following 33.8%
Under the LTX-2 Community License Agreement,non-commercial use only.

5
30
1,782
Jun 3
One image, controllable 3D output. TripoSplat from @tripoai a lightweight image-to-3D Gaussian model for fast, controllable 3D asset generation.
🔗modelscope.ai/models/VAST-AI…
✅ Adjustable Gaussian count up to 262,144
✅ Two core files, ~2,000 LOC total, for lightweight implementation.
✅ Near-zero dependencies, no transformers or diffusers required.
✅ Official ComfyUI support
Released under the MIT License for flexible commercial and non-commercial use.
For image-to-3D and Gaussian Splatting workflows, TripoSplat offers a practical way to reduce setup cost while keeping quality and rendering cost controllable.
📚Paper:modelscope.ai/papers/2605.16…




5
24
2,695