
Proof-of-useful-work. Merge-mined with Pearl, so you mine $MDL free. Every block is a real AI inference.
Joined May 2026
- Tweets 69
- Following 98
- Followers 1,023
- Likes 89
8 Photos and videos





16h
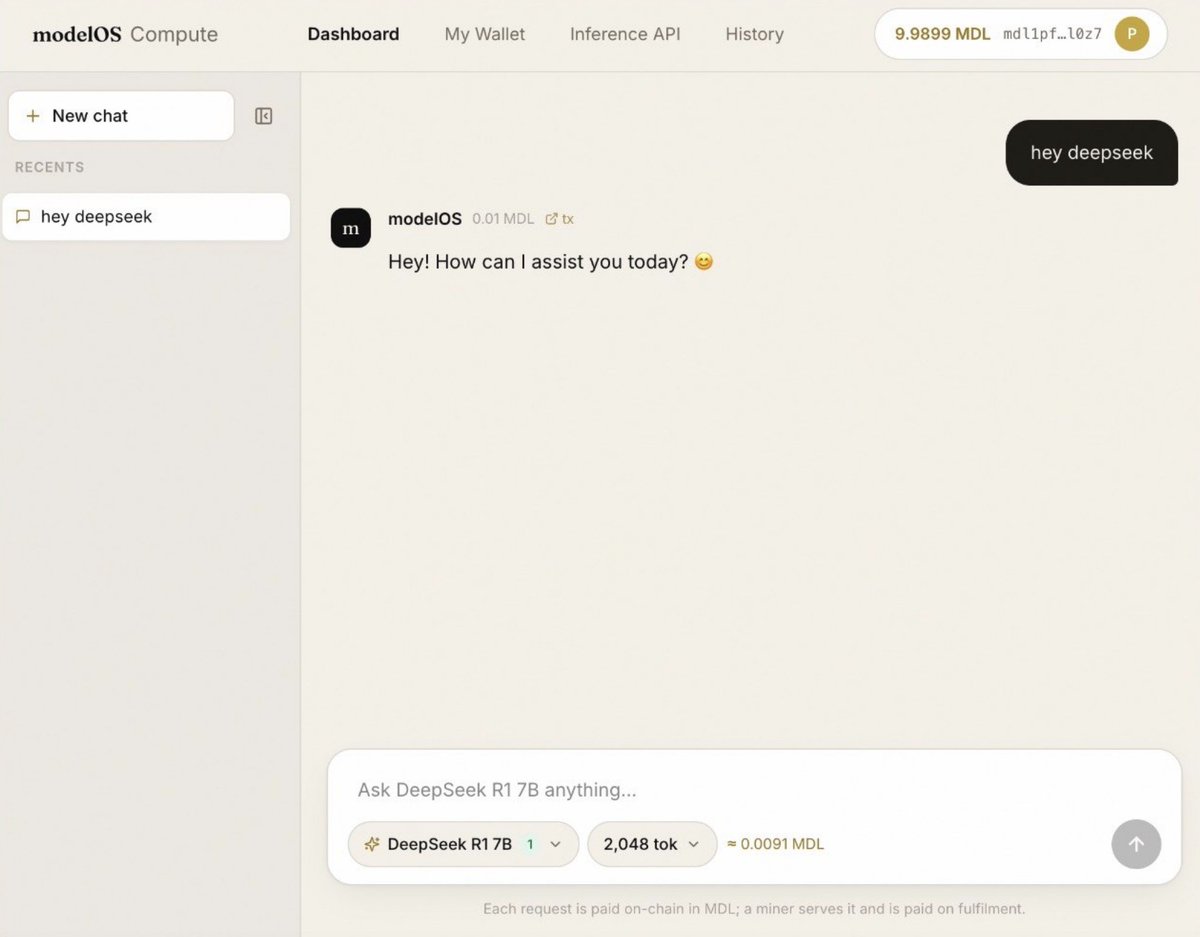
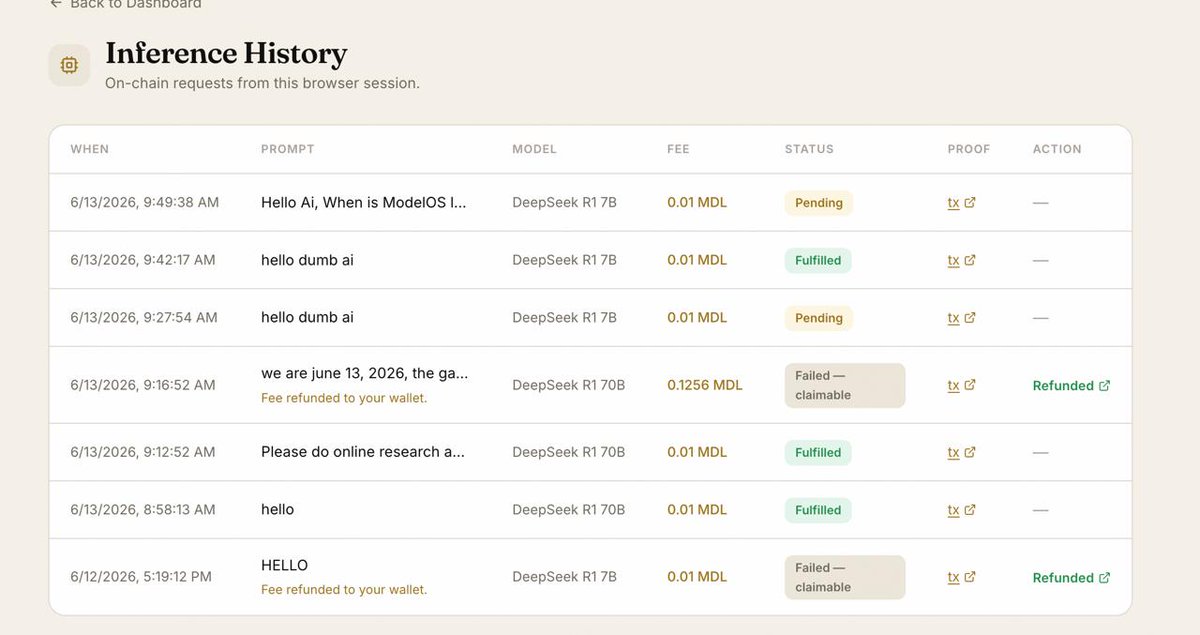
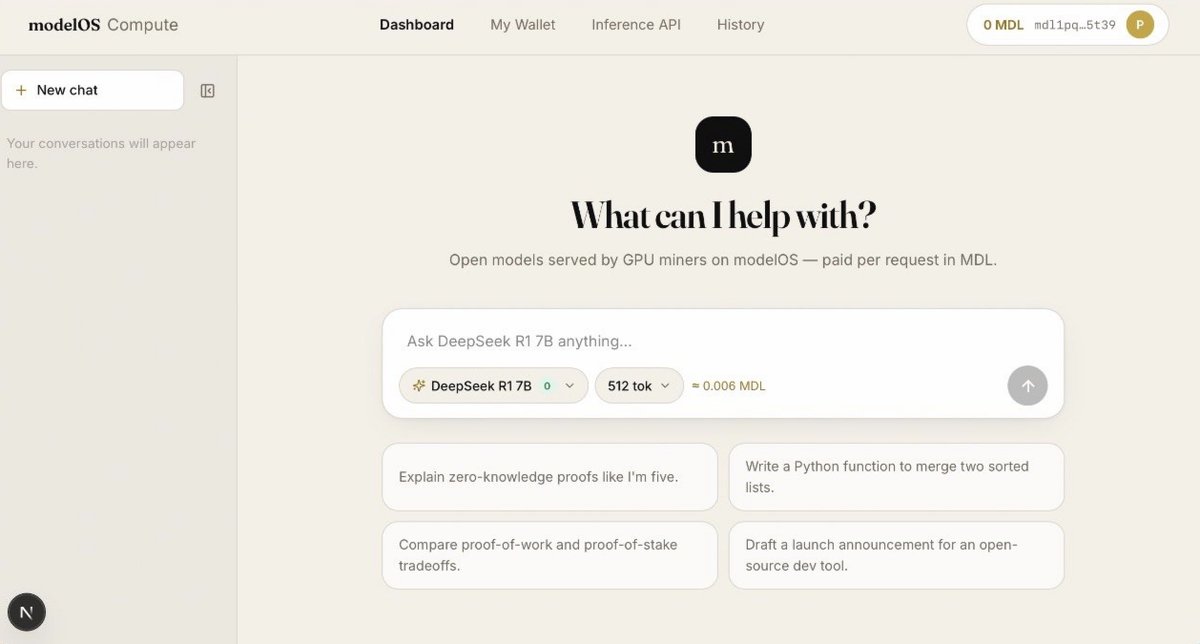
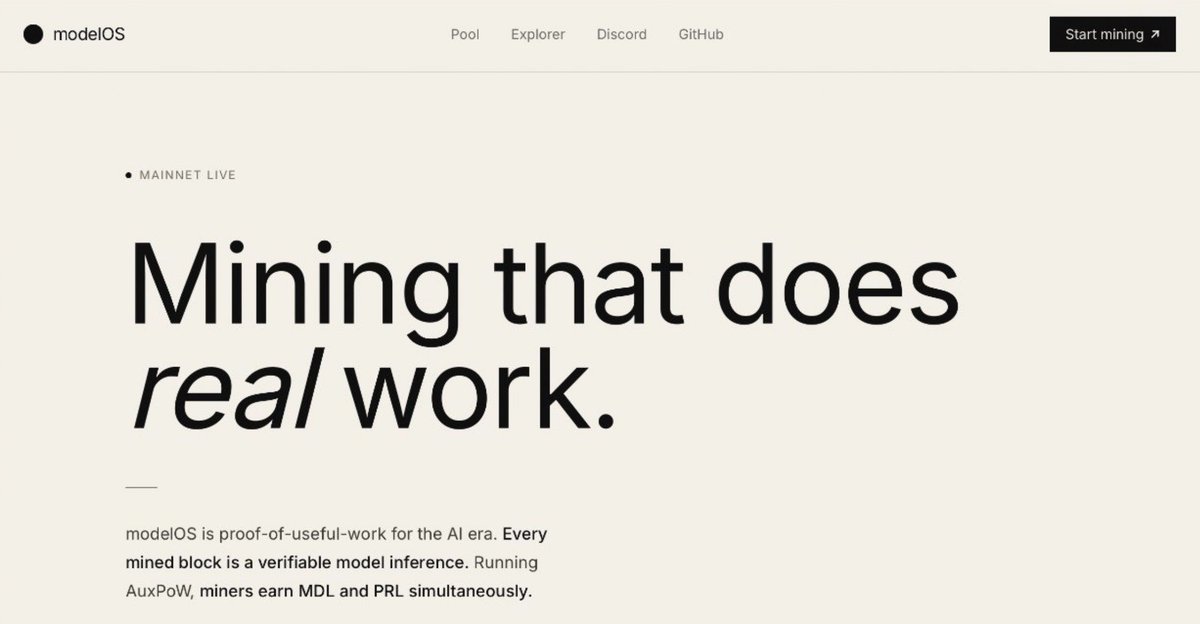
Running the very last test now, making sure inference works end to end.
We're not launching half-baked. When we go live, it's all there:
🔹 Merge-mined with Pearl
🔹 Our pool, paying both $PRL and $MDL
🔹 Inference live with the DeepSeek models, more added after
🔹 Every inference tx verifiable on-chain
🔹 OTC live, so you can trade $MDL from day one
We know you're impatient. Hang with us, we're almost there. Nobody's going to regret the wait.
You're early. 🔔

12
7
39
2,857
16h
Btw we don't actually think our AI is dumb. It's a very nice AI. Very smart. We're proud of it 🙃
5
770
Jun 11
Get ready. Stealth launch is coming.
We're wrapping up the final testing now, making sure everything runs clean. Once it's solid, it's go time.
Have your GPU rigs ready. 🔔
16
4
44
3,041
Jun 9
But who actually buys the inference?
You do, anyone can. At launch there's a chat interface and an API where you request inference from miners and pay in $MDL straight from your wallet.
Over time it grows into a full decentralized inference marketplace.
And soon you'll be able to host any model, the DeepSeek R1 distills, Kimi K2, GLM 4.5, our own distilled model, and more.
Miners serve it. Anyone can use it.
Jun 8

How inference works on ModelOS:
Your GPU isn't just mining, it's serving real AI. Miners run a vLLM miner, and the proof-of-work is the inference itself. Every block is a genuine model run.
At launch you can serve: DeepSeek R1 distills (70B, 32B, 14B, 7B), plus Kimi K2, GLM 4.5, and our own distilled model.
Mine blocks, serve inference, and keep earning the $PRL you're already mining. One GPU, three ways to earn.
10
22
5,076
Jun 8
How inference works on ModelOS:
Your GPU isn't just mining, it's serving real AI. Miners run a vLLM miner, and the proof-of-work is the inference itself. Every block is a genuine model run.
At launch you can serve: DeepSeek R1 distills (70B, 32B, 14B, 7B), plus Kimi K2, GLM 4.5, and our own distilled model.
Mine blocks, serve inference, and keep earning the $PRL you're already mining. One GPU, three ways to earn.
16
5
28
8,998
Jun 4
We're Bitcoin people at heart, so we did one thing differently with $MDL.
Pearl's supply runs to 2.1 billion. We capped Modelos at 21M. Same number Satoshi chose, on purpose.
Less supply, real scarcity, and a lot harder to ever hold a whole coin. Which is exactly why you want to be early. 🔔
10
3
30
4,487
Jun 3
Modelos is a merge-mined proof-of-work chain where the work is real AI inference. Every block mined is a verifiable model run, not wasted hashing. Run AuxPoW and you earn $MDL and $PRL at the same time, same card, no extra cost.
What's coming: our own miner built for efficiency, a block explorer, and the whitepaper. We'll soon be reaching out to Pearl pools about adding $MDL too, so you can mine it through the pool you already use.
Mine blocks. Serve inference. Proof-of-useful-work.
11
8
44
18,000
Jun 1
Already mining Pearl on a GPU? You mine $MDL at no extra cost, same card, same hashpower. Merge-mined, so it's free.
And here's what's different: your rig runs a real AI model while it mines. The proof-of-work is the inference. Same math finds the block and answers the prompt. So that card earns twice, block rewards plus inference fees.
8
3
25
3,286