
Joined March 2026
- Tweets 13
- Following 0
- Followers 10,307
- Likes 14
2 Photos and videos



Jun 12
The MoE hard fork is now live. Update now!
This upgrade marks the next phase of the Pearl network.
With this hard fork, Pearl transitions to v2 certificates based on Mixture-of-Experts (MoE) workloads, enabling the network to more accurately verify and reward useful AI computation performed by participants.
⚠️ All node operators and ecosystem participants must upgrade to the latest versions to remain on the canonical chain.
Soon, new blocks will start using the v2 (MoE) certificates. Nodes that have not upgraded will continue following the previous ruleset and will no longer be compatible with the upgraded network.
Please update to the following versions:
• pearld node → v1.1.0
• Desktop Wallet → v2.0.0
Wallet download (macOS is now supported):
github.com/pearl-research-la…
20
24
171
16,415
Jun 8
A common critique on Proof-of-Useful-Work is that the zero marginal cost of mining drives the network’s security budget and price to zero.
A paper just released by Rafael Pass, a renowned cryptographer at @Cornell /@TechnionLive and research scientist at Pearl Research Labs proves why this argument is flawed.
By analyzing the equilibrium dynamics of PoUW, it shows not only that Pearl’s security budget (and hence price) are at least as high as Bitcoin, but in fact that Pearl will increase the SIZE of the global AI inference market, via Jevons Paradox.
arxiv.org/abs/2606.06700
@initc3org
13
38
198
20,065
Pearl Research Labs retweeted

May 23
Will Fast Matrix Multiplication ever be practical?
Strassen’s 1986 discovery of fast matrix multiplication (FMM) – asserting that the product of two 𝑛×𝑛 matrices can be computed in sub-cubic time 𝑛^𝜔 ∼ 𝑛²·⁸⁷ ≪ 𝑛³ – had a profound impact on theoretical computer science and algorithm design.
Since then, mathematicians improved on Strassen’s algorithm, and some experts believe that, eventually, it will be shown that 𝜔 ≈ 2, which would mean that the time to compute AxB is essentially the time it takes to merely read the inputs: ~O(𝑛²) (!) Needless to say, such result would have a major impact on the AI compute age we’re entering…
Unfortunately, FMM algorithms only work for enormous matrices--on the order of the number of atoms in the universe (“galactic algorithms" [1])--and it is currently hard to imagine them being practical on any imaginable hardware. Besides their asymptotic runtime, a core practical issue with FMM algorithms is that they all inherently rely on recursive divide-and-conquer, which creates memory and IO-bottlenecks, and is numerically unstable; This is likely the reason why the largest hardware manufacturers in the world are not developing chips for FMM. Even Strassen’s original algorithm, which gives nontrivial FLOP speedup for relatively small matrices, struggles to beat the sheer parallelism of naiive MatMul on GPUs or TPUs.
Some interesting progress on practical FMM seems underway [2] and would be interesting to follow, but it remains to be seen whether divide-and-conquer can be implemented in both silicon and memory to deliver wall-clock speedups for realistic dimensions of matrices in LLMs.
What is means for @prlnet. That’s the reason we designed the Pearl proof-of-work protocol (cuPOW) with the underlying baseline being “naiive” matrix multiplication O(𝑛³), which is what NVIDIA, AMD, Cerebras and all other AI hardware accelerators implement today.
Nevertheless, it is important to stress that Pearl’s protocol doesn't rely on naiive MatMul remaining SoTA -- if FMM becomes practical some day, Pearl's protocol can easily adapt to the 𝑛^𝜔 baseline (since the next version of cuPoW will only verify the output AB).
In fact, one of the intriguing aspect of @prlnet is that it creates incentives (for both humans and machines) to develop faster MatMul algorithms and hardware (as had happened in Bitcoin with SHA256). Of course, without proper modification, such breakthrough would break the security assumption of Pearl-GEMM, so such algorithmic breakthrough would better be public.
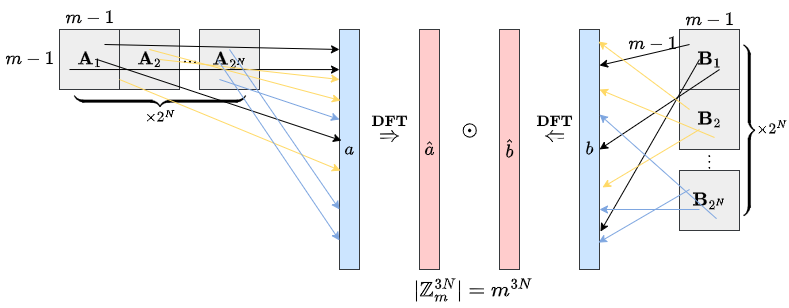
FMM and FFT. Our recent paper [3] shows that it is possible to achieve fast matrix multiplication without using Strassen-like divide-and-conquer, using only the Fast Fourier Transform, which is omnipresent in countless industry-scale applications. This paper presents a simple algorithm running in 𝑂(𝑛²·⁸⁹) time, which only sums a few convolutions in 𝕫ₖᵐ, using FFT (see figure below for illustration of the algorithm).
Despite being highly parallel (no recursion), this FFT algorithm for MatMul remains asymptotic, as it still requires many parallel repetitions on submatrices in order to obtain noticeable speedup over naiive MatMul (𝑛³). Whether FFT can lead to subcubic time MatMul
for reasonably-sized matrices is a fascinating question!
I believe FFTs are the most promising tool in this direction...
[1] Lipton, Richard J., and Kenneth W. Regan. “David Johnson: Galactic Algorithms.” In People, Problems, and Proofs, 109–112. Springer, 2013. doi.org/10.1007/978-3-642-41….
[2] Karstadt, Elaye, and Oded Schwartz. “Matrix Multiplication, a Little Faster.” Journal of the ACM 67, no. 1 (2020): 1:1–1:31. doi.org/10.1145/3364504.
[3] Uffenheimer, Yahel, and Omri Weinstein. “Improved Sparse Recovery for Approximate Matrix Multiplication.” arXiv:2602.04386, 2026..
19
21
140
54,123
May 15
Inference is becoming the largest compute market and energy consumer in AI. Pearl turns inference CapEx of hyperscalers into a profit center: every LLM token produced by GPUs can simultaneously generate ¶PRL in parallel. That means users get 2-for-1 economics: useful inference today, and Pearl coins that discount future compute.
We’re excited to partner with Together AI to launch the first 2-for-1 inference endpoint offering SoTA LLMs at discounted price, and securing the Pearl network in parallel.
May 15

Introducing Gemma-4-31B-it-Pearl on Together AI, Pearl Research Labs’ instruction-tuned checkpoint of Gemma 4 31B powered by @prlnet Proof of Useful Work protocol.
AI natives can now use this Pearl model as a serverless inference endpoint on Together AI, at a 25% discounted pricing.

51
41
235
113,381
May 15
"The real limit to AI is not energy, it is actually cash"
14
10
100
33,657
May 3
Demand for Pearl is skyrocketing.
@prlnet
We’ve opened up a compute platform for the people — first come, first served, with limited supply.
We’re working hard to expand capacity. Subscribe for updates:
compute.pearlresearch.ai
23
13
151
47,508
May 1
👀

Privy CEO @sternhenri sees three big trends in stablecoins and the blockchain growing in the future:
"First, we're going to see a rise of non-dollar stablecoins as more people embrace them."
"Second, I've heard of a few projects that are trying to have an inflation stablecoin. The stable actually grows with inflation, so that you're on purchasing power parity. I think they're really hard to instrument and get quite right, which is why I don't think they've taken off just yet."
"Third, there's a company called Pearl that is finding a way to do fast matrix multiplication and back a blockchain on this, so you can issue tokens based on how much compute you've got ready to do useful inference. So there was a question for me of, what other useful work could you back the currency on?
1
1
40
35,766
Apr 29
2-for-1 Inference on Gemma4 is now available on Pearl!
huggingface.co/pearl-ai/Gemm…
5
31
18,888
Apr 28
Every era has a resource so fundamental it becomes money.
Bitcoin turns energy into currency. Trustless, global and censorship-resistant.
AI is doing something even more powerful: it turns energy into intelligence. Deployable anywhere and useful for almost everything.
But intelligence has no native financial primitive. It isn't fungible. It can't move outside the dollar system.
Pearl changes that.
Pearl is the first asset natively produced by AI and natively secured by AI. Every GPU cycle producing LLM tokens can simultaneously mint Pearl tokens with marginal extra electricity, zero wasted compute and one unified primitive. 2-for-1.
Sitting atop one of the largest capital expenditures in history, Pearl changes the unit economics of AI.
This is what sets Pearl’s breakthrough apart. Previous attempts at useful-work blockchains captured a narrow slice of compute. Pearl's addressable market is every matmul computation on earth which, at current trends, will be the majority of all compute.
Bitcoin’s security is competing with AI for energy. Pearl's security scales with AI adoption.
Proof of work represents humanity's demand for energy, monetized.
Pearl represents humanity's demand for intelligence, monetized.
Pearl is now live.
pearlresearch.ai
5
10
115
67,488
Mar 17
It is becoming increasingly clear that the future economy will be denominated in compute cycles more than in human labor.
In a world where AI drives the majority of electricity consumption and GDP, compute is the natural collateral for money: an open, auditable, AI-native currency, produced directly through inference and training.
Since the inception of Bitcoin, an outstanding open problem in distributed systems was whether it is possible to implement Proof-of-Work consensus on top of real-world computation, as opposed to useless random hashing. While long considered impossible, last year we answered this question affirmatively.
Pearl’s mathematical breakthrough enables every GPU cycle powering AI systems to simultaneously produce a native digital currency: ¶PRL.
What this means is that the hundreds-of-billions (and soon trillions) of dollars of compute being deployed for AI workloads will double--for effectively free--to secure Pearl's Proof-of-Work chain; All the properties of Bitcoin, but secured as the by-product of AI inference and training, i.e., by the native operation of GPUs: matrix-multiplication (GEMM).
Pearl changes the unit economics of LLMs, which are are fundamentally non-fungible, and will shift a portion of the wealth generated by AI back to users – who drive production, model improvement and demand, yet currently capture none of the upside of the AI era.
We’ve spent the last year turning this “2-for-1” breakthrough into a working infrastructure, building from the linear algebra down to the CUDA kernels, alongside world-class mathematicians and low-level engineers.
Today, we’re excited to announce that the Pearl Network is ready, and will soon support state-of-the-art LLM serving, through vLLM and SGLang plugins. Running AI workloads on Pearl transforms AI compute from a sunk expense into an AI-native asset, anchored directly to the production of intelligence.
If you’re interested/skeptic or ideally both – we’ve published our next tranche of open problems as a collaborative Polymath challenge – containing math, systems and economics questions we’re grappling with next. We invite you to tear it down, prove it or propose better implementations: pearlpolymath.com.
#AIMoney
#ProofOfInference
16
11
99
23,763