
Wev3 degen, @BoltLiquidity engineer, founder @ArkProtocol
Joined November 2017
- Tweets 5,183
- Following 2,891
- Followers 1,543
- Likes 6,322
566 Photos and videos









Pinned Tweet

There are some people in life you meet and it restore your faith in humanity - Sam is one of them.
I met him last year in Siem Reap, Cambodia, through a dear friend knowing him for over 10 years.
He's a Tuk-Tuk driver - quiet, warm, always laughing. He doesn't talk about what he does for others - like collecting funds for his village, for solar lights, road repairs, supporting people and families who have nothing.
He never thought of starting a campaign for himself - but I did! Let's boost the future for Sam and his family.
Please read his story and share if you can.
khmercare.com/raise-funds/3e…
facebook.com/sam.ath.31/post…
3
7
342
mr-t | Bolt Liquidity | Ark Protocol retweeted

Jun 10
Composability is the key to DeFi. Break it and you break everything downstream.
Every Bolt swap settles in one atomic transaction.
No off-chain step. Any protocol on @SuiNetwork can compose with it.

2
17
161
mr-t | Bolt Liquidity | Ark Protocol retweeted
May 12
4
6
32
1,809
mr-t | Bolt Liquidity | Ark Protocol retweeted
May 5
What happens when the largest aggregator on Sui meets zero slippage execution?
A short documentary 👇
23
13
60
12,345

Fixed the exact num_ctx bloat you ran into with Qwen 3.5 9B Ollama @openclaw! 🚀
Just opened PR #69464 - now properly honors params.num_ctx (both at provider and model level). No more 262k-token GGUF override killing your Mac Mini M4.
The workaround I posted in #44550 still works today (provider-level config or custom Modelfile).

spent yesterday trying to run qwen 3.5 9b locally on my mac mini m4 for my @openclaw bot.
inference is fast (14 tok/s), tool calling works, ram is tight but manageable at 6.6gb.
one dealbreaker: ollama forces thinking ON for all qwen 3.5 models. 800 invisible <think> tokens before any output. 30-60 seconds of silence on every message, even "say hi."
what I tried:
→ think: false on /api/chat - works, but openclaw doesn't send it
→ reasoning_effort: "none" on /v1/ - disables thinking but breaks tool calling
→ node proxy to inject the param - works for raw calls, breaks streaming
→ system prompt tricks - qwen 3.5 ignores them
→ /nothink suffix - that's qwen 3, not 3.5
reverted to glm-5 for now. the model runs great, ollama just won't let me turn off thinking for small models despite qwen's own docs saying it should default to off.
if you're running qwen 3.5 locally with ollama and have thinking disabled with tool calling intact, what am I missing?
modelfile trick? different runner? different approach entirely?
2
4
157
1
35
Workaround until PR gets released:
github.com/openclaw/openclaw…
26
mr-t | Bolt Liquidity | Ark Protocol retweeted
Apr 20
Deeper pools. More incentives. Higher TVL.
That's how DeFi has chased execution quality since day one.
But what if you didn't need any of it?
Bolt decouples execution from depth. The oracle handles pricing. The pool handles settlement. That's it.

2
11
407
mr-t | Bolt Liquidity | Ark Protocol retweeted
Apr 15
Every AMM charges you slippage. Every single one.
And they've convinced you it's the cost of doing business on-chain.
@CryptoChem0000 explains why it's actually the cost of building on an outdated model. And what Bolt does differently. 👇
5
4
26
2,343
mr-t | Bolt Liquidity | Ark Protocol retweeted

Apr 14
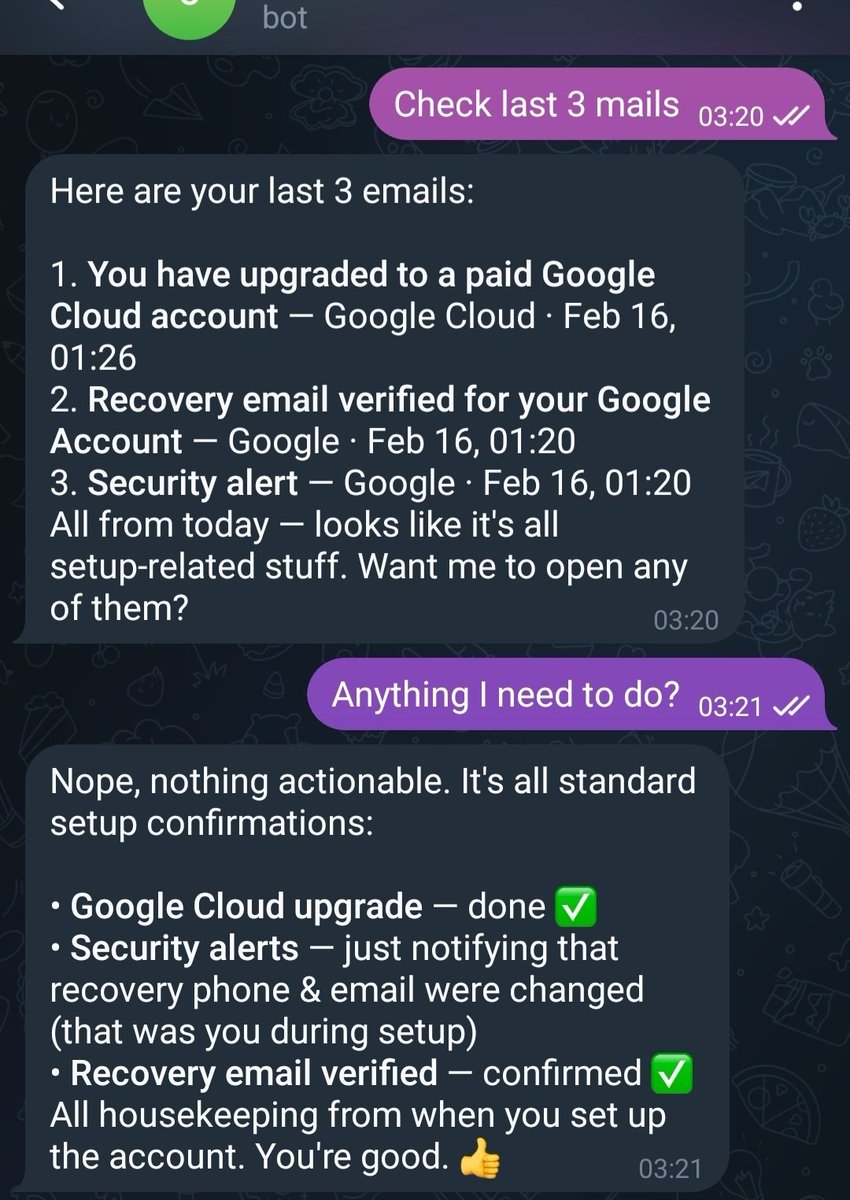
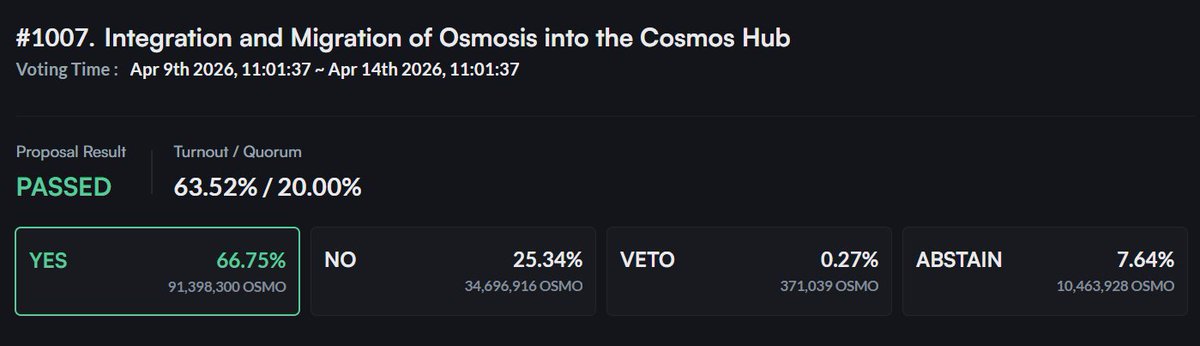
Osmosis has voted to migrate.
Now the decision sits with the Cosmos Hub.
With ~2 days left and a close vote, participation matters.
If you stake ATOM, take a moment to review Proposal 1029 and cast your vote.
10
13
96
19,638


We’ve updated the Cosmos Hub proposal based on validator and community feedback.
The biggest change: no new ATOM mint.
Any ATOM required beyond the Hub community pool will now be sourced over time using protocol revenue from the DEX, which will be used to purchase ATOM on the open market to fund OSMO → ATOM conversion.
This introduces a performance-linked component, where a portion of the acquisition is funded over time through realized protocol revenue — while simultaneously creating open-market demand for ATOM.
Total acquisition size remains bounded at < 2.5% of ATOM supply.
forum.cosmos.network/t/propo…

Today we’re proposing something big for the Cosmos ecosystem.
We’re bringing Osmosis directly into the Cosmos Hub.
If approved by governance of both chains, the Osmosis DEX will be migrated natively on the Hub — unifying liquidity, governance, and security under one chain.
This proposal reflects a natural evolution for Cosmos: sovereign experimentation followed by consolidation once infrastructure has matured.
Osmosis has served as the primary liquidity venue of Cosmos since 2021. Now it has the opportunity to become native infrastructure of the Hub itself.
OSMO holders would have the ability to convert to ATOM through a structured migration process, allowing the Cosmos to finally align around a single coordination asset.
Finally, ATOM will have its first true revenue stream and direct exposure to the liquidity engine of Cosmos.
For years the question has been: how does ATOM capture value from ecosystem activity?
This proposal is our answer.
Governance discussion begins today.
Forum proposal ↓
forum.cosmos.network/t/propo…
47
59
344
75,575
mr-t | Bolt Liquidity | Ark Protocol retweeted

Apr 2
3
8
2,481
mr-t | Bolt Liquidity | Ark Protocol retweeted
Mar 24
Club Zero: the intersection of infrastructure and culture
18
7
53
13,798
mr-t | Bolt Liquidity | Ark Protocol retweeted

Mar 20
Behind the Science: @osmosis
the latest from the LAB
⏰ Tue March 24th, 17:00 UTC
👇 Set your reminders
x.com/i/spaces/1rGmqoOVgVnGy

6
12
85
8,953
mr-t | Bolt Liquidity | Ark Protocol retweeted
Mar 23
TVL matters when liquidity determines price.
Bolt breaks that link, decoupling pricing from depth.
Pricing is deterministic.
Liquidity is for settlement.
That’s why less capital can do more.
@CryptoChem0000 explains 👇
5
2
21
23,814
mr-t | Bolt Liquidity | Ark Protocol retweeted

Mar 19
Stargaze 2.0 is now LIVE 🎉
(1) Connect your favorite wallet
(2) Come and see your NFTs on the @cosmoshub
(3) The marketplace is OPEN
Come and play: stargaze.zone
58
95
321
48,415
There are some people in life you meet and it restore your faith in humanity - Sam is one of them.
I met him last year in Siem Reap, Cambodia, through a dear friend knowing him for over 10 years.
He's a Tuk-Tuk driver - quiet, warm, always laughing. He doesn't talk about what he does for others - like collecting funds for his village, for solar lights, road repairs, supporting people and families who have nothing.
He never thought of starting a campaign for himself - but I did! Let's boost the future for Sam and his family.
Please read his story and share if you can.
khmercare.com/raise-funds/3e…
facebook.com/sam.ath.31/post…
3
7
342
And no: it's not me, since Sam and his family are young, handsome and has a bright future - not degens 🙃
1
37
mr-t | Bolt Liquidity | Ark Protocol retweeted

Buddhist monks are approaching the last stretch of a 2,300-mile "Walk for Peace," getting close to the borders of Washington, D.C., after 105 days traveling.
#walkforpeace
20
748
3,289
26,392