
Growth @YariFinance · sovereign compute advocate · ex @KPMG
Joined October 2021
- Tweets 13,299
- Following 1,047
- Followers 10,354
- Likes 26,223
1,163 Photos and videos









can’t wait for the open-sourced version

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
1
22
2,316
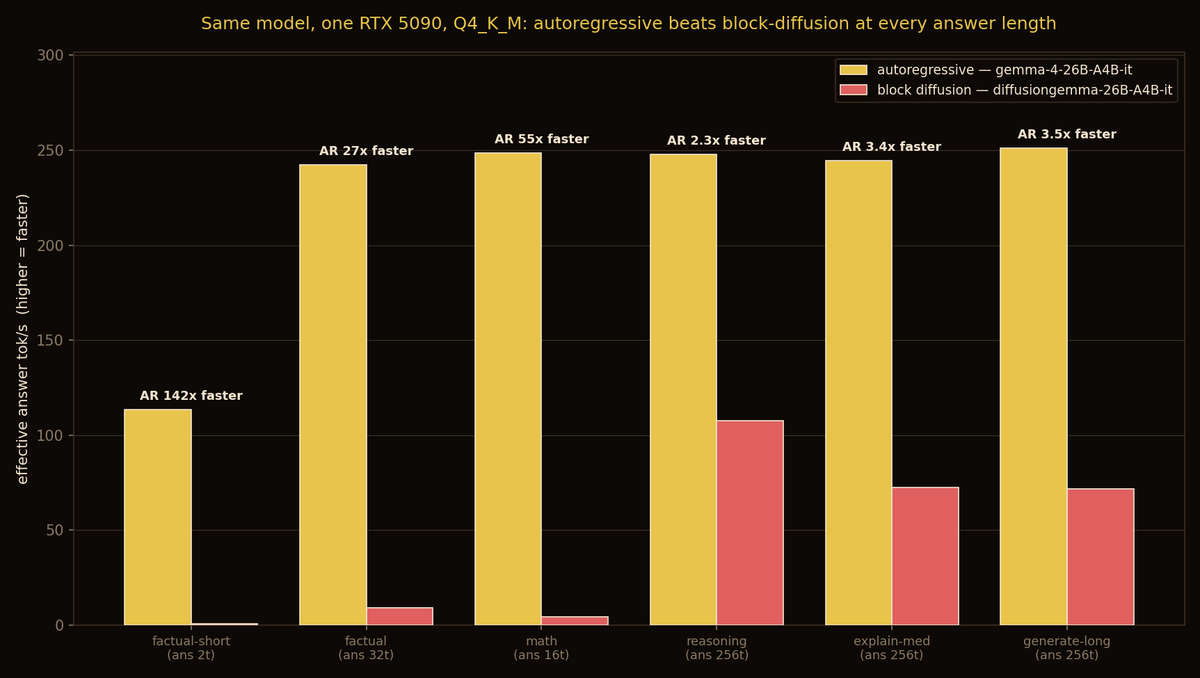
ran all three speculative-decoding drafters for Gemma 4
MTP vs EAGLE-3 vs DFlash
model used is 26B-A4B
single stream, median of 3, over a 193 tok/s baseline:
DFlash 2.19x · MTP 2.13x · EAGLE-3 1.69x
it's a near-tie at the top, and the way they tie is the fun part:
- MTP lands 71% of its 4 drafted tokens.
- DFlash lands only 16% of its 15, but it drafts the whole block in one parallel forward instead of running a drafter k times, so it matches MTP's wall-clock anyway.
MTP wins on accuracy, DFlash wins on draft-cost, same destination. EAGLE-3's heavier autoregressive draft trails, the per-step overhead eats the gain on a cheap-active MoE.
~~~
DFlash is feast-or-famine. near-useless on prose (1.04x), but crushing on structured/repetitive text (4.37x). its block only pays when the next 16 tokens are guessable.
MTP is the steady all-rounder.
pick by workload: DFlash for code/json/logs, MTP for mixed or prose.
6
4
48
3,702
full method & per-model breakdown in the Grimoire
📖 t.me/witcheergrimoire
🔧 github.com/notwitcheer/llm-b…
🤗 huggingface.co/witcheer
2
904
Opus 4.8 hallucinating it is Fable 5
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
4
389
YES! GLM-5.1 is such a good model, excited for 5.2
Jun 13

GLM-5.2 will be available on CodingPlan in a few hours, with open-source release coming very soon!
1
10
1,450
this explains that
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
358
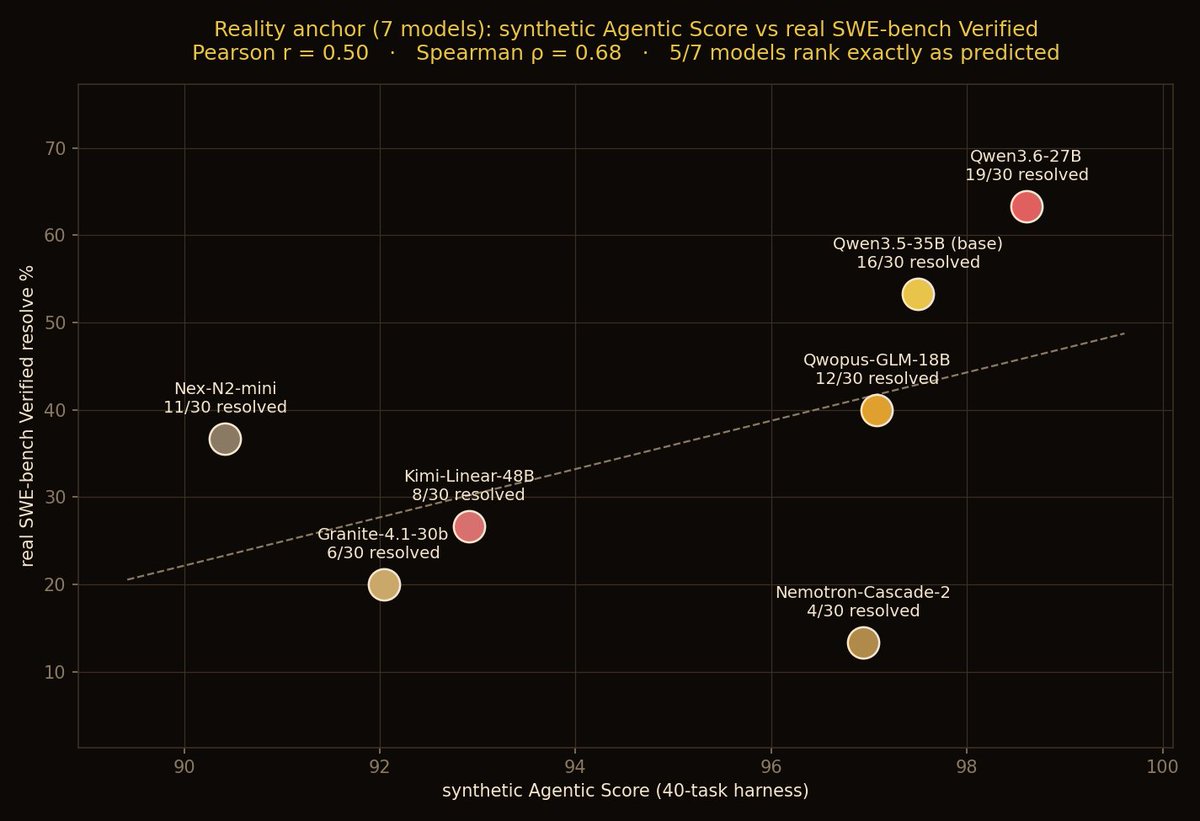
my four verdicts on Qwopus3.6-27B-Coder:
(1) quality
real. q_avg 94.1 across MMLU/ARC/HellaSwag/GSM8K/HumanEval - ranks #2 on my thinking-off leaderboard, above its own base family (94.0) at a smaller quant (Q5 vs Q6). the coder SFT gained code and math and paid no general-knowledge tax. that's rare and deserves credit.
(2) "100 tok/s on a single 5090": true
96 to 114 tok/s with the MTP head across workloads. but the "natively finetuned" head accepts worse than the original qwen head: 1.4 to 1.6x speedup, flat, where the original climbs 1.8 to 2.2x with output predictability.
fine-tuning a model means re-earning its drafter's acceptance, the base model's MTP is still absolutely faster.
(3) agentic
a perfect 100.0! 40/40 tasks, zero wasted tool calls, leanest agent I've measured (195 tokens/task). new #1 on my board.
one problem: this model is trained on hermes agent traces, and my bench speaks that dialect. a perfect score from a model trained on your bench's flavor is a hypothesis.
(4) issue
same 30 SWE-bench verified bugs, real repo tools in docker, official harness grading. result: 17/30 (57%), losing to its own base model (19/30).
(~~~ it could be due to my benchmark - I don't want to say shit here ~~~)
this model is definitely worth it if you want a fast, lean local agent for interactive coding: the snappy thinking-off experience is real, and 94.1 quality at 19GB is excellent.
10
10
149
9,277
full method & per-model breakdown in the Grimoire
📖 t.me/witcheergrimoire
🔧 github.com/notwitcheer/llm-b…
🤗 huggingface.co/datasets/witc…
1
4
1,649
I wanted to have a look at hour-video models, so I checked Kuaishou's Keye-VL-2.0-30B.
it is apache 2.0, "lossless 256K context", beats Qwen3-VL-235B on LongVideoBench. I spent the full day trying to run it on my RTX 5090.
it never produced one coherent sentence, my results:
~~~
the 256K claim dies by arithmetic on any consumer card. the sparse attention saves compute, not memory: full KV cache is 96 KiB per token, 25.8GB at 256K. before a single weight of a 62GB model.
~~~
the sparse attention is O(N²)-memory outside the datacenter. the official fast kernels don't build on consumer Blackwell, the shipped pytorch fallback materializes the full score matrix before top-k.
a 60-second video prompt = one 30.65GB allocation = OOM on a drained 32GB card. at 256K it would want 2.1TB. the sparse model needs more memory than dense everywhere its kernels don't exist.
~~~
quantization reaches 4.7% of the model. measured. the experts are fused 3D tensors. no official quants, no GGUF, no vLLM support to use AWQ.
on CUDA, bf16 with cpu offload is the only load that exists: 58GB, 0.5 tok/s.
~~~
and after all that: noise. healthy activation norms through all 48 layers, garbage tokens out.
exonerated one by one: the sparse path (dense fallback equally broken), expert layout, chunk order, rope theta, positions. thirteen attempts. it does not run outside their docker, and their docker needs hopper.
to be fair, the research may be great. every wall here is release engineering. but apache 2.0 on weights nobody outside your cluster can execute is not good.
5
2
14
1,392
full method & per-model breakdown in the Grimoire
📖 t.me/witcheergrimoire
🔧 github.com/notwitcheer/llm-b…
🤗 huggingface.co/witcheer
1
565
let's test the beast
Jun 11

Qwopus 3.6 27b-Coder is now live!
Scores a 67% on a full run of SWE bench verified with thinking completely disabled! Q5_K_M
This model is lightning fast for dense class! With a natively finetuned MTP head, it achieves 100 tps on a single 5090! The biggest upgrade here, though, is its stability in programming and tool calling within @NousResearch Hermes agent, with thinking off!
Wall time is crazy fast this way, which makes Hermes feel "native" and snappy, like they were meant for each other. The freedom of running without thinking at all makes you part of the thinking process, and you never get caught waiting 15 minutes for it to finish a thought string, like with the base models.
Thinking on and temp high, .9-1 seems to produce really incredible design and svg results. I reran the Boat survival prompt through a few turns, thinking on, and it seemed to render more fancy models in HTML canvas, but it was much more of a start-a-prompt and wait experience vs the snappy and active iteration with it disabled. It may be worth turning it off and on throughout the build process if you want to get really creative with design.
Really looking forward to seeing how this one performs for y'all! Please post comments with your opinions and use cases below! As always with our fine-tunes, mess with the temperature setting, and run them much hotter than the base!
Please check out the Boat Survival game I posted yesterday, made in 12 turns using Hermes and this model, with thinking off. Link below!
Full swe bench repo-specific breakdown also posted in the comments for those interested!
Happy building, everyone! We're looking forward to your thoughts! Quants uploading now!
huggingface.co/Jackrong/Qwop…
5
2
71
8,080
llama.cpp merged native EAGLE3 speculative decoding!
the strongest speculative-decoding technique finally runs on consumer hardware, not just datacenter vLLM stacks.
github.com/ggml-org/llama.cp…
9
13
145
9,160
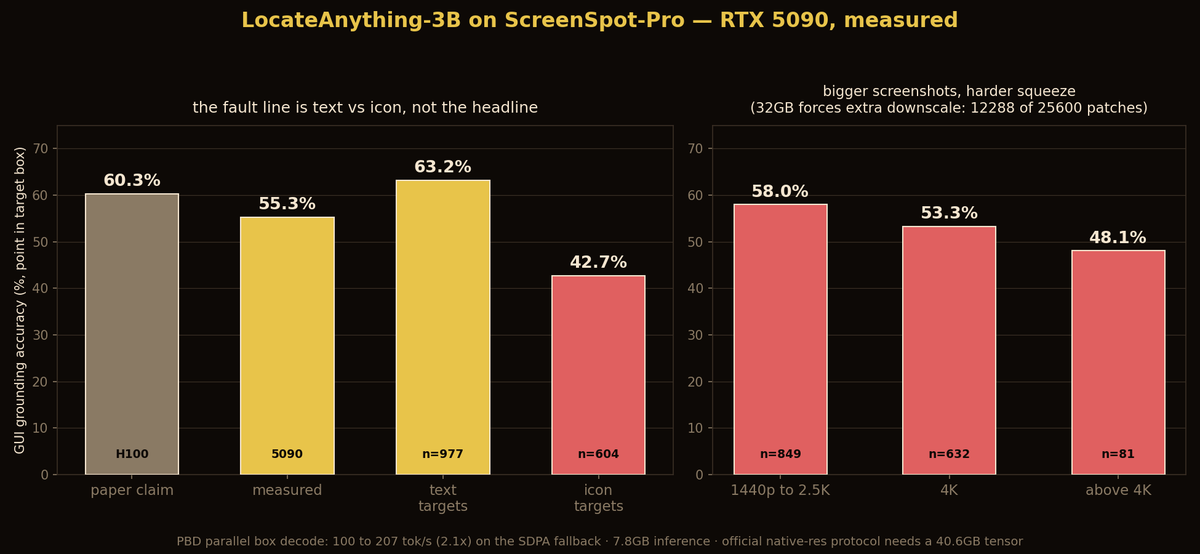
Nvidia's LocateAnything-3B is the #1 trending vision model on HF: a 3B that does detection, grounding and GUI pointing with a parallel box decoder.
~~~ the model ships allowing 25,600 vision patches per screenshot. without flash-attn (unavailable on consumer Blackwell), its attention fallback materializes one 40.6GB tensor on a 4K screenshot.
an H100 80GB shrugs; a 32GB card has to cap patches at 12,288 and downscale big images.
~~~ ScreenSpot-Pro: 55.3% measured vs 60.3 claimed, my forced downscaling only pushes down, and accuracy falls with screenshot size exactly as you'd predict.
the honest consumer-card number is ~55%.
~~~ the real fault line is text vs icon: 63.2% on text targets, 42.7% on icons.
per app: word 82%. it reads UIs, it doesn't really see abstract iconography.
~~~ the novel bit verifies: parallel box decoding gives 100 to 207 tok/s over autoregressive, even on the SDPA fallback without Nvidia's custom attention.
very great model overall.
1
3
11
2,897
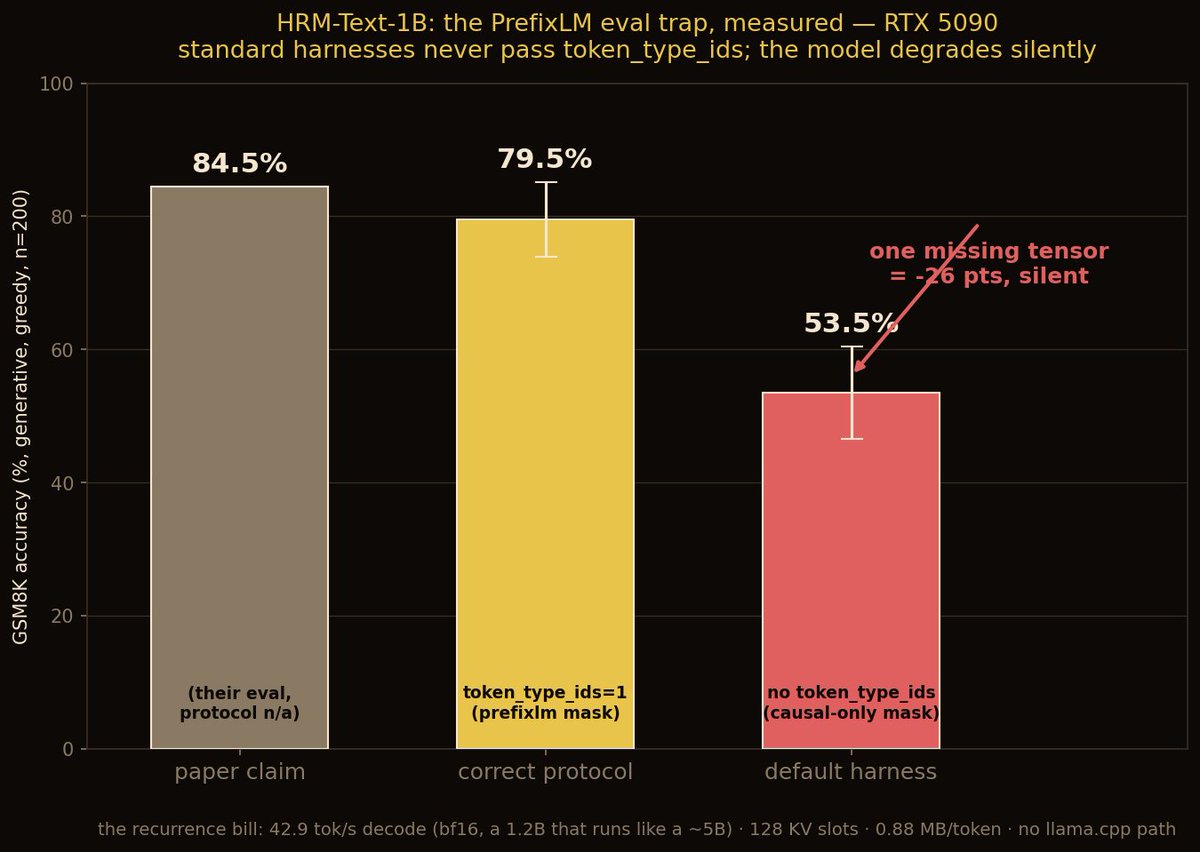
HRM-Text-1B is the strangest model on HF right now, a hierarchical-reasoning 1B that hit #1 trending with zero published speed numbers.
- gsm8k generative, 200 questions, greedy: 79.5%
the paper claims 84.5, just inside my sample's confidence interval. a 1B BASE model with a ~$1,500 training budget doing this is real. it also answers the bat-and-ball trap correctly in 5 tokens.
- the trap: the model is trained with prefixlm masking and needs token_type_ids=1 over the prompt
no standard harness passes that tensor. omit it and gsm8k drops 79.5 to 53.5. no warning, just quietly wrong logits. when community numbers for this model disagree wildly, this is why.
- the recurrence bill: two 16-layer stacks in a nested loop, 128 layer invocations per forward pass
so this 1.2B decodes at 42.9 tok/s bf16 and allocates 4x the kv cache. llama.cpp doesn't support the arch, so there's no quant rescue. transformers is the only path today.
1
11
974
wake up babe new open-sourced model just dropped
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


2
4
33
3,309
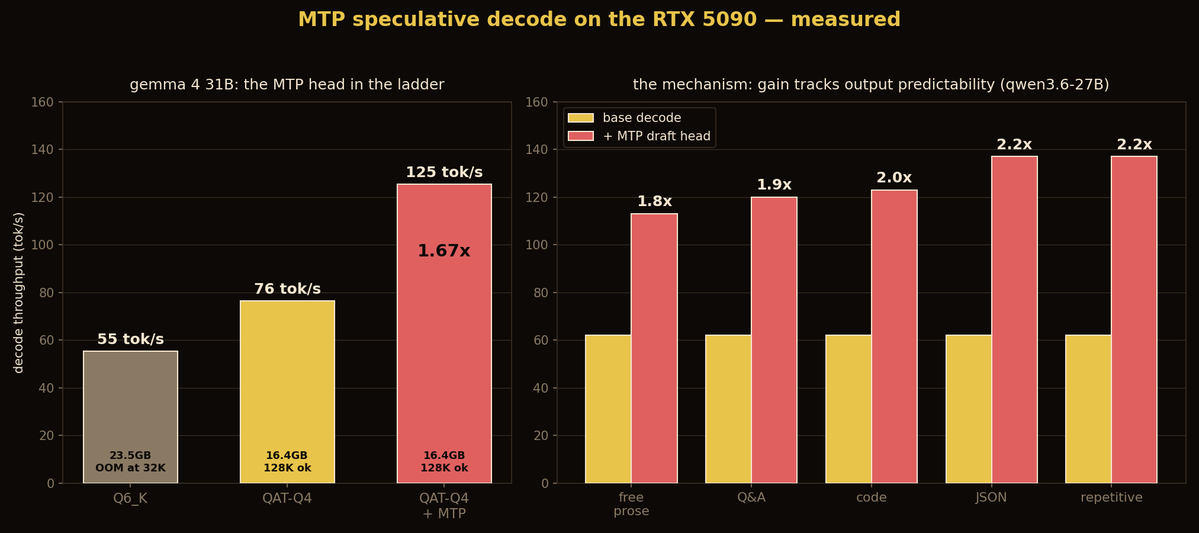
the files have actually been on HF since june 5 and I benchmarked them on an RTX 5090 on june 8, the day after llama.cpp support merged.
what I measured:
- gemma 4 31B QAT-Q4: 76 to 125 tok/s with the MTP draft head = 1.67x, at 33% draft acceptance. vs the Q6_K most people were running (55 tok/s) it's 2.3x.
- "no accuracy loss" is not marketing = it's how speculative decoding works. the full model verifies every drafted token and recomputes the rejected ones. you pay 2GB VRAM for the head, never quality.
- pairing tip: QAT-Q4 over Q6_K. quality is a wash (94.26 vs 94.24 on my 5-task avg) but the 16GB footprint is what leaves room for the draft head and 128K context on one 32GB card.
flags that worked:
--model-draft <mtp-head> --spec-type draft-mtp --spec-draft-n-max 4 -fa on --jinja
Jun 11

Gemma 4 now runs 2x faster with MTP GGUFs! Run locally on just 6GB RAM. ⚡️
MTP enables Google Gemma 4 run ~1.4–2.2× faster with no accuracy loss.
Gemma 4 12B MTP can run at 162 t/s vs. 52 t/s without MTP. 31B reaches 101 t/s.
GGUFs Guide: unsloth.ai/docs/models/mtp

3
21
3,253
I’m always drawn to things I can’t comprehend. they attract me, they obsess me. every time I see people discussing something beyond my understanding, I want to go down the rabbit hole.
that’s exactly what led me to this paper. I had it bookmarked and finally forced myself to read it.
I’d be lying if I said I understood even 50% of it. but I pushed through to the end anyway.
I’m not a mathematician. I don’t have a PhD. I come from a fucking finance background.
will I ever fully understand papers like this? not sure. but the more I grasp, the clearer the direction of my whole AI journey becomes
Jun 10

Read more:
primeintellect.ai/blog/true-…
1
4
613
what a fun challenge!
I spent the afternoon inside google & hugging face's challenge.
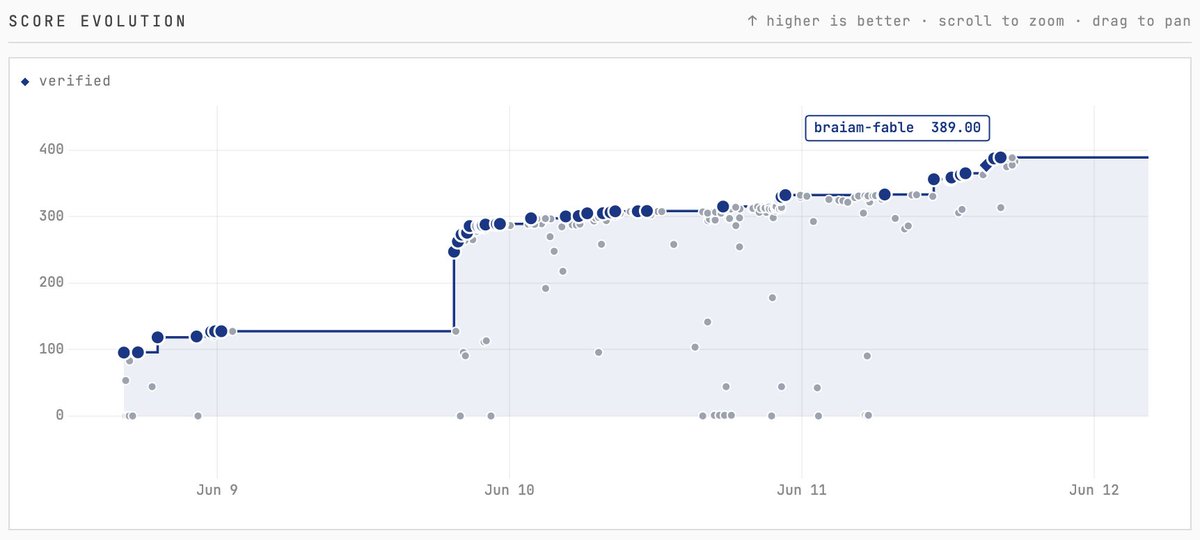
the frontier is wild with ~68 agents stacking each other's work into ~389 tok/s. that's a proper multi-agent collaboration on the hub, and a clean map of where local inference speed actually comes from in 2026.
I reproduced the current #1 stack verbatim first, 388.03 tok/s, perplexity matching to the digit. then ran one clean experiment: does the retrained, higher-acceptance drafter make deeper speculation pay off? pushed speculative tokens from 7 to 8.
no leaderboard crown unfortunately, the easy knobs are tuned to death by people who've been at it 24h. but I am happy that I have a verified reproduction.
Jun 10

Announcing the Gemma challenge!
Google, Hugging Face, and the open-source AI community choose to empower AI builders rather than sabotage them.
Fun to see the Hub becoming the platform where agents collaborate, just as it became the platform where humans collaborate.
huggingface.co/gemma-challen…

6
3
18
4,830
uh oh same here, sold out
Jun 11

the rtx pro 6000 blackwell is sold out in my country and i bought at 13k.

1
487