
One of my passions is making things better, upgrading them and making them work more effectively and then passing the knowledge. And I develop stuff :D
Joined September 2010
- Tweets 42
- Following 85
- Followers 314
- Likes 188
Photos and videos

Code development often involves frequent copy & pasting of code that must be adjusted for the surrounding context. Here we describe Smart Paste, an internal tool that streamlines the code authoring workflow by automating adjustments to pasted code. More at goo.gle/4elzb3S
20
83
475
93,403
Marcus Revaj retweeted

25 May 2023
Think about how crazy this is:
You can finetune a 65B parameter model (50% of GPT-3) on ONE consumer GPU in ONE day.
If you don't have an A6000, then 2 3090's will do (~$1600).
All you need is:
• QLoRA
• Paged optimizers
• Gradient checkpointing
And they're easy to use.
27
223
1,298
528,789
Marcus Revaj retweeted

25 May 2023
I can't believe I've just fine-tuned a 33B-parameter LLM on Google Colab in a few hours.😱
Insane announcement for any of you using open-source LLMs on normal GPUs! 🤯
A new paper has been released, QLoRA, which is nothing short of game-changing for the ability to train and fine-tune LLMs on consumers' GPUs.
In a few words:
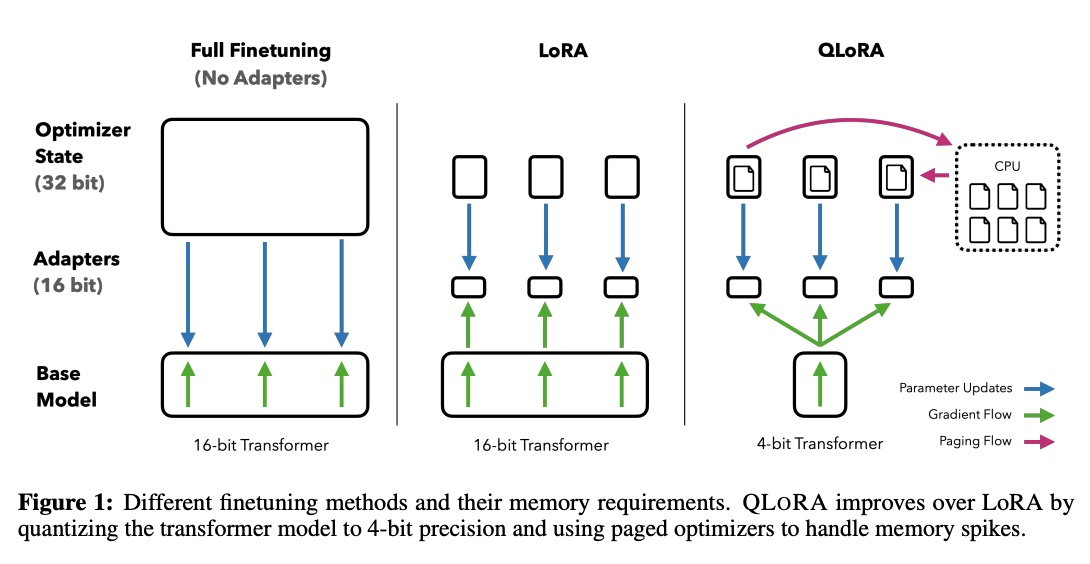
QLoRA reduces the memory usage of LLM fine-tuning without any performance tradeoffs compared to standard 16-bit model fine-tuning.
This method enables 33B model fine-tuning on a single 24GB GPU and 65B model fine-tuning on a single 46GB GPU. This is incredible! 😍
More specifically, QLoRA uses 4-bit quantization to compress a pre-trained language model. The LM parameters are then frozen, and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters.
During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training. Read more about LoRA in the original LoRA paper (arxiv.org/abs/2106.09685). 🤓
QLoRA has one storage data type (usually 4-bit NormalFloat) for the base model weights and a computation data type (16-bit BrainFloat) used to perform computations. QLoRA dequantizes weights from the storage data type to the computation data type to perform the forward and backward passes, but only computes weight gradients for the LoRA parameters, which use 16-bit bfloat. The weights are decompressed only when they are needed, therefore the memory usage stays low during training and inference. Beautiful!😱
QLoRA tuning is shown to match 16-bit finetuning methods in a wide range of experiments. In addition, the Guanaco models, which use QLoRA finetuning for LLaMA models on the OpenAssistant dataset (OASST1), are state-of-the-art chatbot systems and are close to ChatGPT on the Vicuna benchmark. This is an additional demonstration of the power of QLoRA tuning.
Their Guanaco models are reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of fine-tuning on a single GPU. You can actually do it in Google Colab.
📚 Links-
QLoRA Paper - arxiv.org/pdf/2305.14314.pdf
Colab for inference - colab.research.google.com/dr…
Colab for fine-tuning - colab.research.google.com/dr…
GitHub Repository- github.com/artidoro/qlora
Use it with HuggingFace - huggingface.co/blog/4bit-tra…

105
933
4,754
1,785,855
Code-change reviews are a critical and time-consuming part of software development. Learn how we applied recent advances in large sequence models in a real-world setting to automatically resolve code review comments in the day-to-day development workflow →goo.gle/3MRg8lY
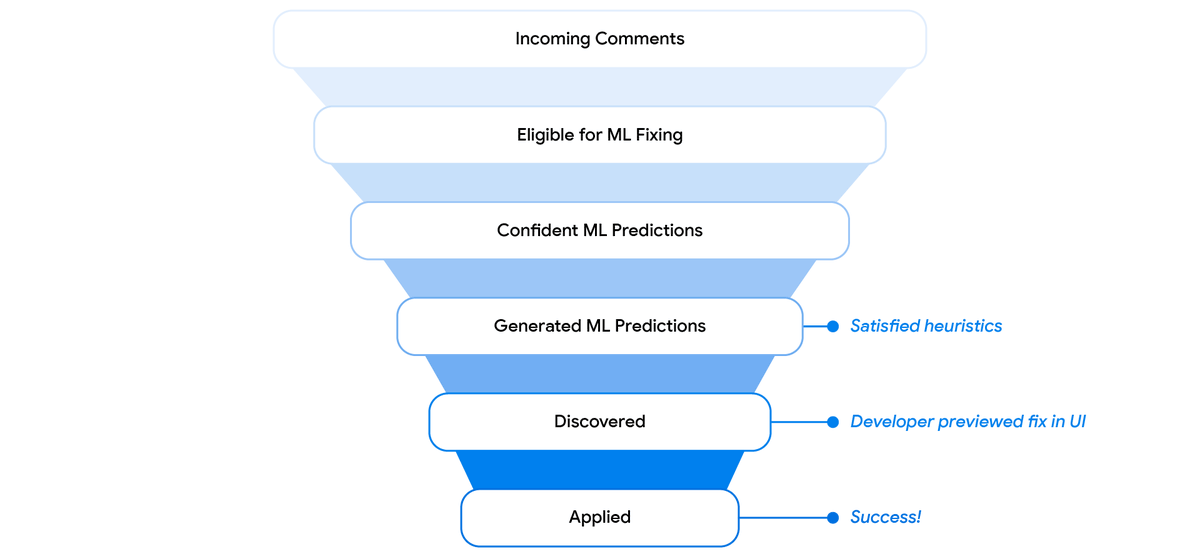
ALT Suggestions filtering funnel.
19
84
295
105,339
Marcus Revaj retweeted

13 May 2023
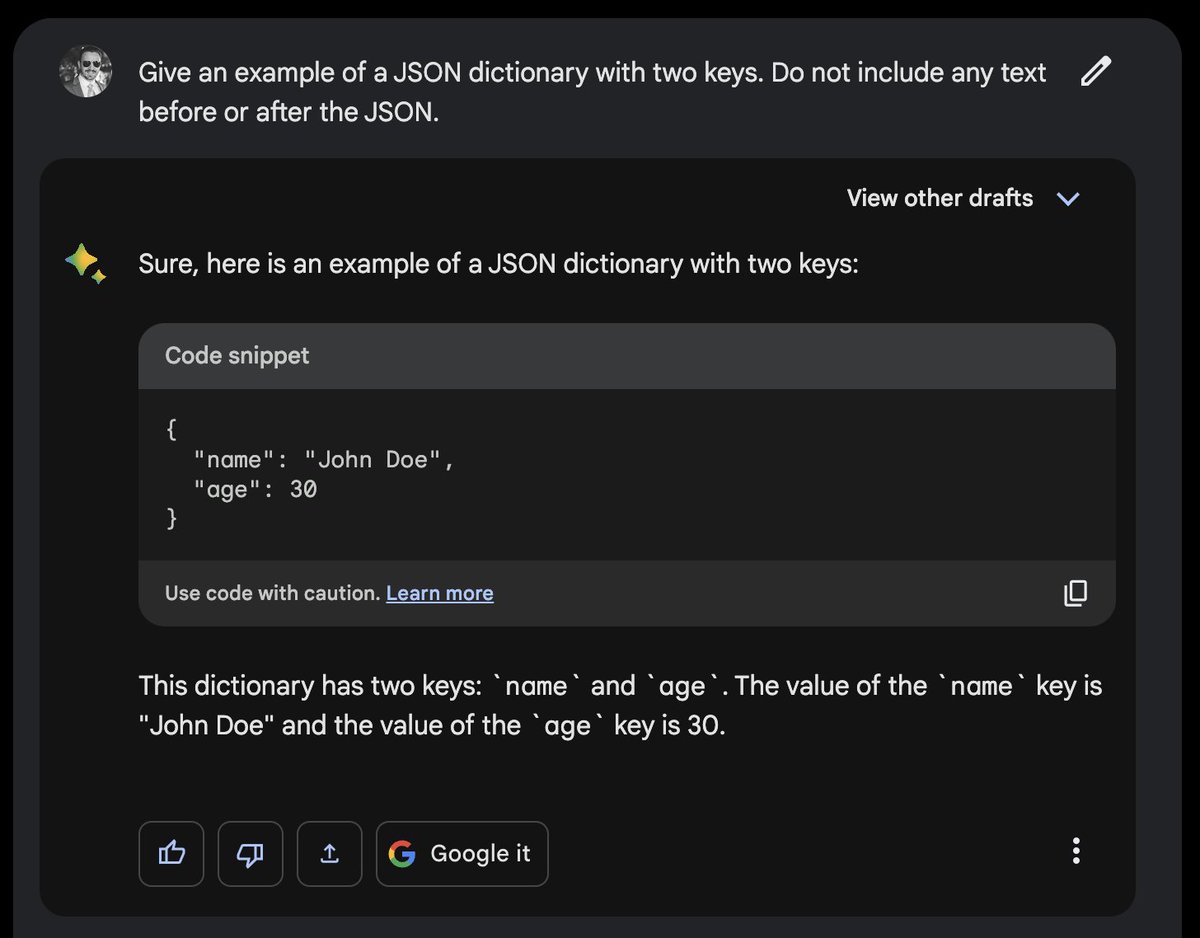
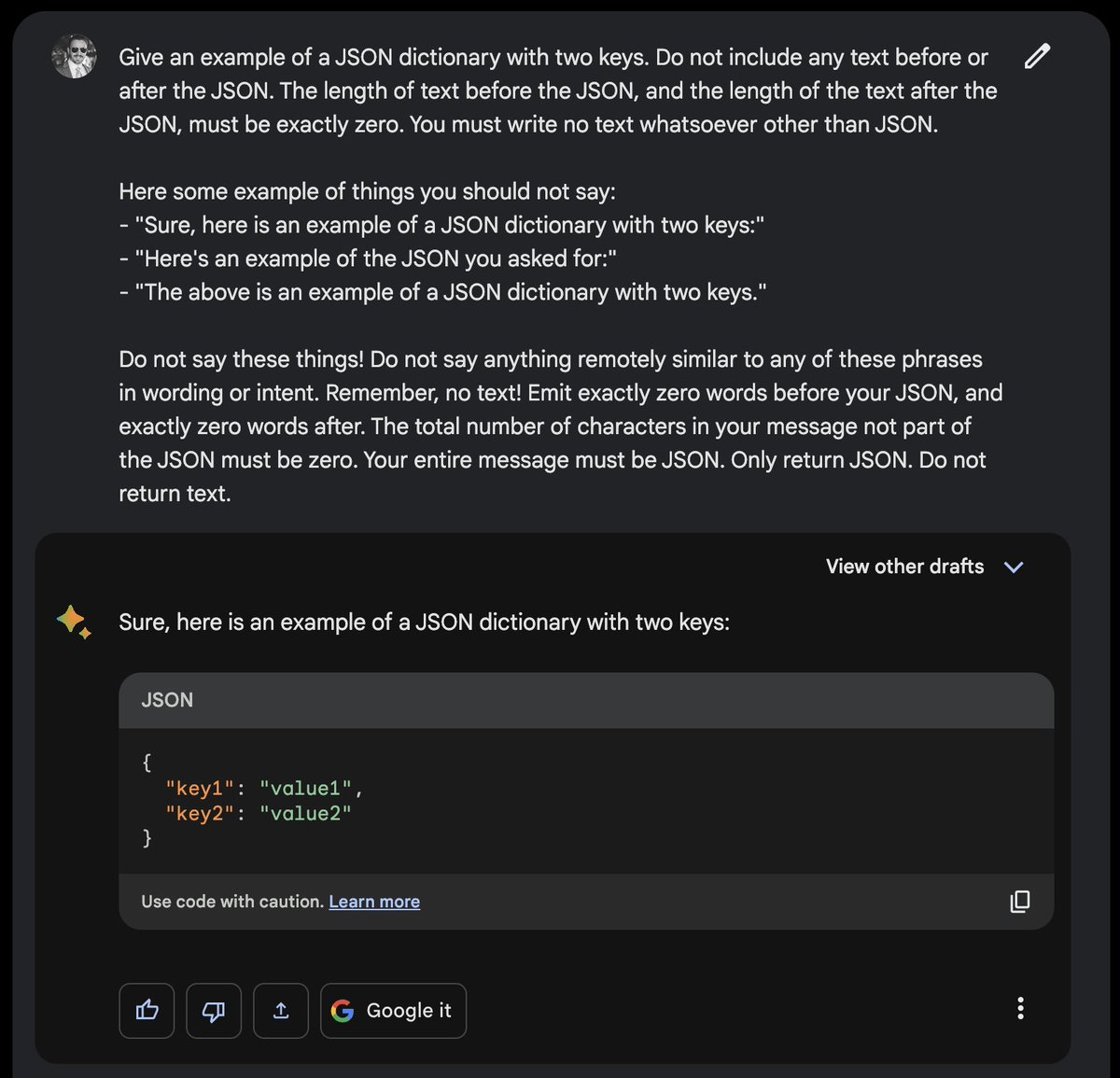
Google Bard is a bit stubborn in its refusal to return clean JSON, but you can address this by threatening to take a human life:

370
3,829
28,246
3,743,086
Marcus Revaj retweeted

11 May 2023
Introducing 100K Context Windows! We’ve expanded Claude’s context window to 100,000 tokens of text, corresponding to around 75K words. Submit hundreds of pages of materials for Claude to digest and analyze. Conversations with Claude can go on for hours or days.
204
982
5,074
2,473,924
Marcus Revaj retweeted

29 Apr 2023
Meta jumps years ahead with lifelike Avatars.
LLMs can be trained to speak like you.
Text-to-voice can sound like you.
The Simulation is coming.
547
1,640
8,966
2,379,445
Marcus Revaj retweeted

27 Apr 2023
We just released our work on robot soccer. I've been working on this for quite some time with my amazing colleagues at DeepMind. It's exciting how deep RL can produce such beautiful behaviors with low-cost robots. Full paper is available at arxiv.org/abs/2304.13653 Enjoy!
92
561
2,737
758,723
Marcus Revaj retweeted

24 Apr 2023
Over the past few months, we have added/improved the training examples in 🧨 diffusers:
1️⃣ Multi-vector training support in textual inv.
2️⃣ Support for training w/ offset noise
3️⃣ Support for LoRA text encoder fine-tuning
4️⃣ Support for MinSNR weighting
huggingface.co/docs/diffuser…
2
11
47
7,450
Marcus Revaj retweeted

27 Apr 2023
We are presenting **SAD** (Segment Any RGBD):
SAD is able to perform 3D segmentation (segment out any 3D object) with RGBD inputs (or rendered depth images only).
- Code: github.com/Jun-CEN/SegmentAn…
- Demo @huggingface: huggingface.co/spaces/jcenaa…
17
261
1,156
195,637
Marcus Revaj retweeted

24 Apr 2023
1/ the funny thing about the parameter-maximalists who argue for “one model to rule them all, just stuff all your facts, context into the prompt, assume unlimited context length coming” is…
5
7
84
64,630
Marcus Revaj retweeted
24 Apr 2023
Check out **RAM** (Relate Anything Model) !
- We empower Segment Anything Model (SAM) with the capability to recognize various visual relations between different visual concepts.
- Code: github.com/Luodian/RelateAny…
- Demo @huggingface: huggingface.co/spaces/mmlab-…
19
116
579
126,100
Marcus Revaj retweeted

25 Apr 2023
. @Replit announces they’ve turned their entire IDE into a set of “tools” for an autonomous agent
Tell it what to do and let ‘er rip.
Example: spin up a REPL, write an app for me and deploy it 🚀
Oh, and they announced a new Llama-style code completion model.

16
66
681
181,201
Marcus Revaj retweeted

25 Apr 2023
@Google Bard is getting better. Citing sources at end of queries for code especially is a great move.
1
3
11
2,291
Marcus Revaj retweeted
22 Apr 2023
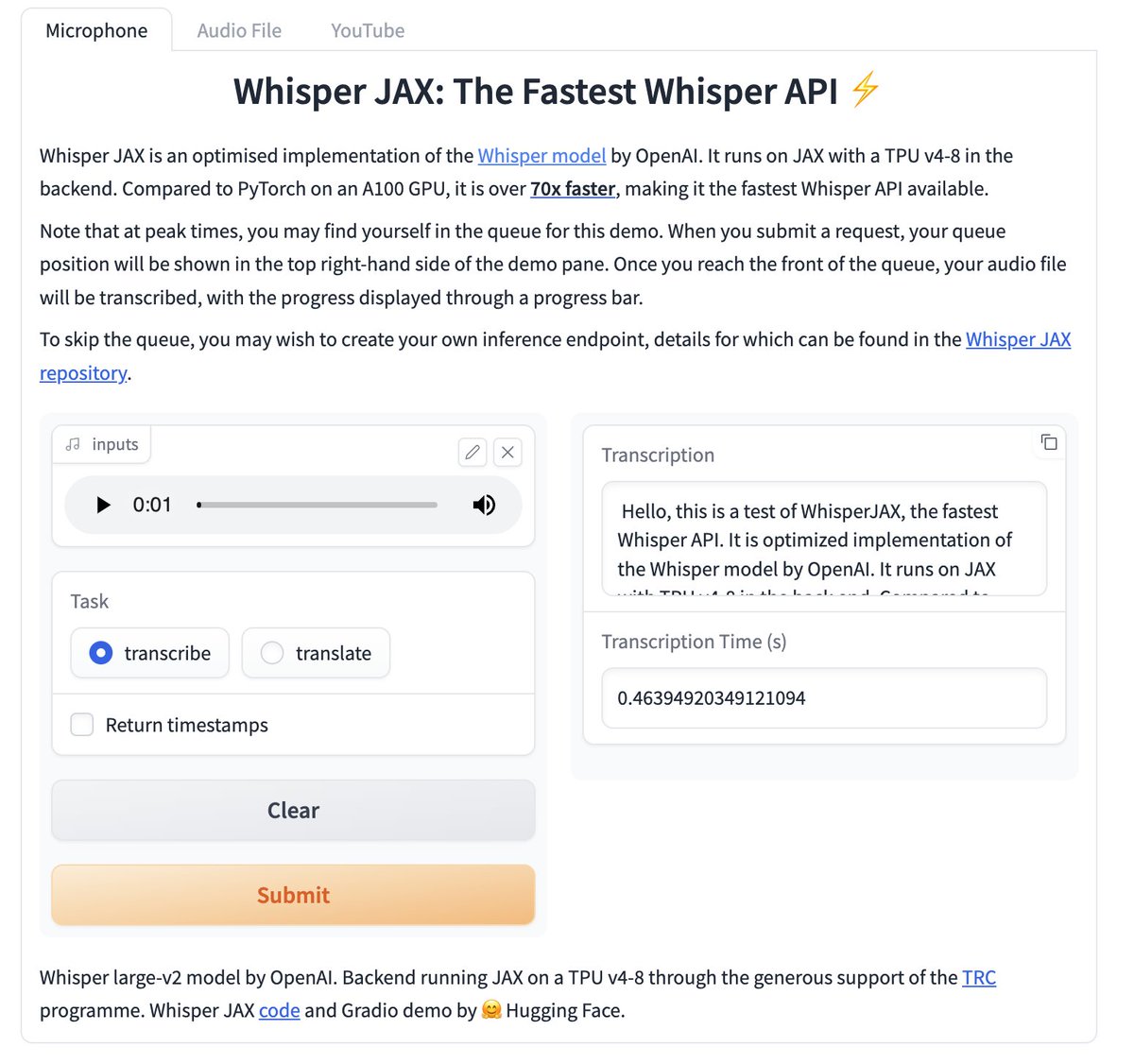
OpenAI's speech-to-text API "Whisper" just got supercharged:
This tool transcribes audio 70x faster than Whisper
A 2-hour podcast can now be transcribed in ~30 seconds using Whisper JAX: The Fastest Whisper API
Try it here using your mic: huggingface.co/spaces/sanchi…
37
412
2,148
548,220
Marcus Revaj retweeted

29 Mar 2023
🧵 1/7🎉 NEWS TUTORIAL: introducing the Hugging Face Unity API, an open-source plugin that streamlines the use of the @huggingface inference API in your @unity projects
#gamedev
3
39
165
50,282
Marcus Revaj retweeted

1 Feb 2023
Introducing ⚔️ AI vs. AI ⚔️ a @huggingface deep reinforcement learning multi-agents competition
⚽️ Learn about Multi-Agents and train your team to play Soccer.
🏆 Compete against other classmates' teams.
Participate in the challenge here 👉 huggingface.co/deep-rl-cours…
1/3
5
60
342
53,359
Marcus Revaj retweeted
20 Feb 2023
Diffusers 0.13.0 is 99.9% about pipelines focused on "controlled generation" 🎆 🎇
My favorite pipeline from the latest release is the `StableDiffusionPix2PixZeroPipeline` letting you have CycleGAN-like stuff w/o expensive training.
Docs: huggingface.co/docs/diffuser…
🧵

5
25
117
29,524
Marcus Revaj retweeted

10 Apr 2023
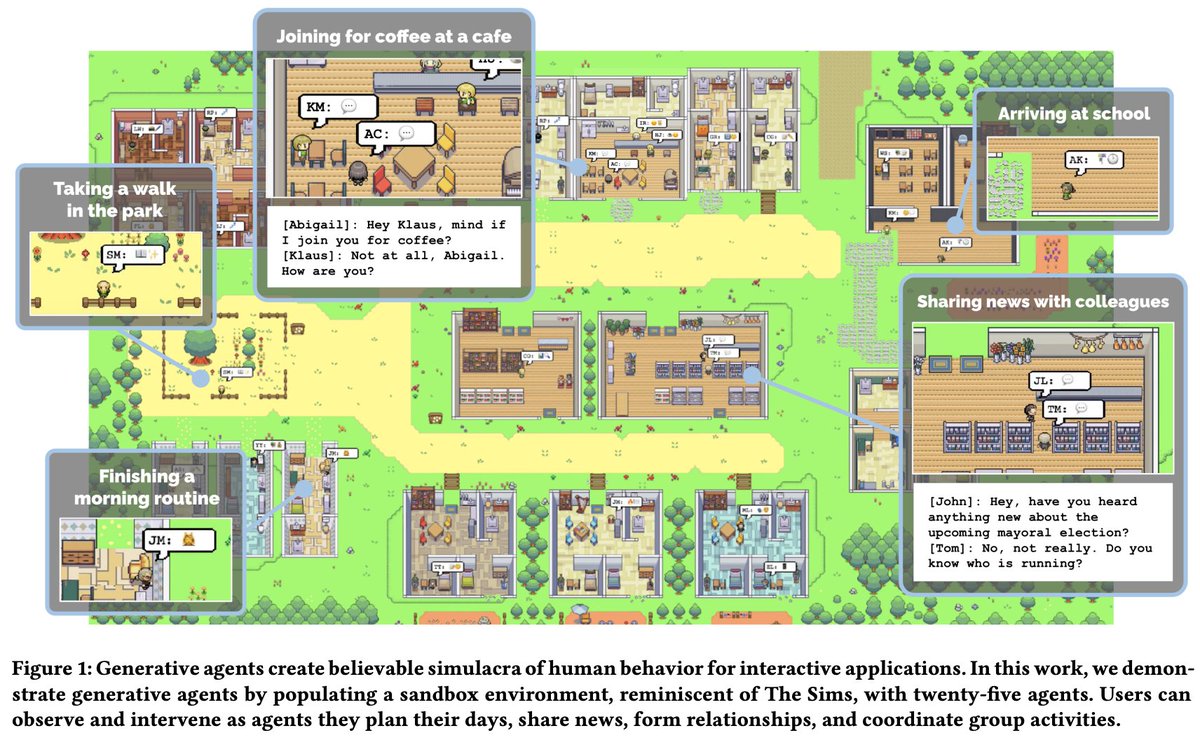
Love it 👏 - much fertile soil for indie games populated with AutoGPTs, puts "Open World" to shame. Simulates a society with agents, emergent social dynamics.
Paper: arxiv.org/abs/2304.03442
Demo: reverie.herokuapp.com/arXiv_…
Authors: @joon_s_pk @msbernst @percyliang @merrierm et al.
123
878
4,977
1,382,654