
Assistant Professor @UniUtrecht nartrith.atomistic.net DFT/MachineLearning & Energy Materials Enthusiast youtu.be/mJTcHTgrvDY Visiting Researcher @MSFTResearch
Joined January 2019
- Tweets 822
- Following 612
- Followers 1,105
- Likes 3,029
65 Photos and videos
















Pinned Tweet

1 May 2021
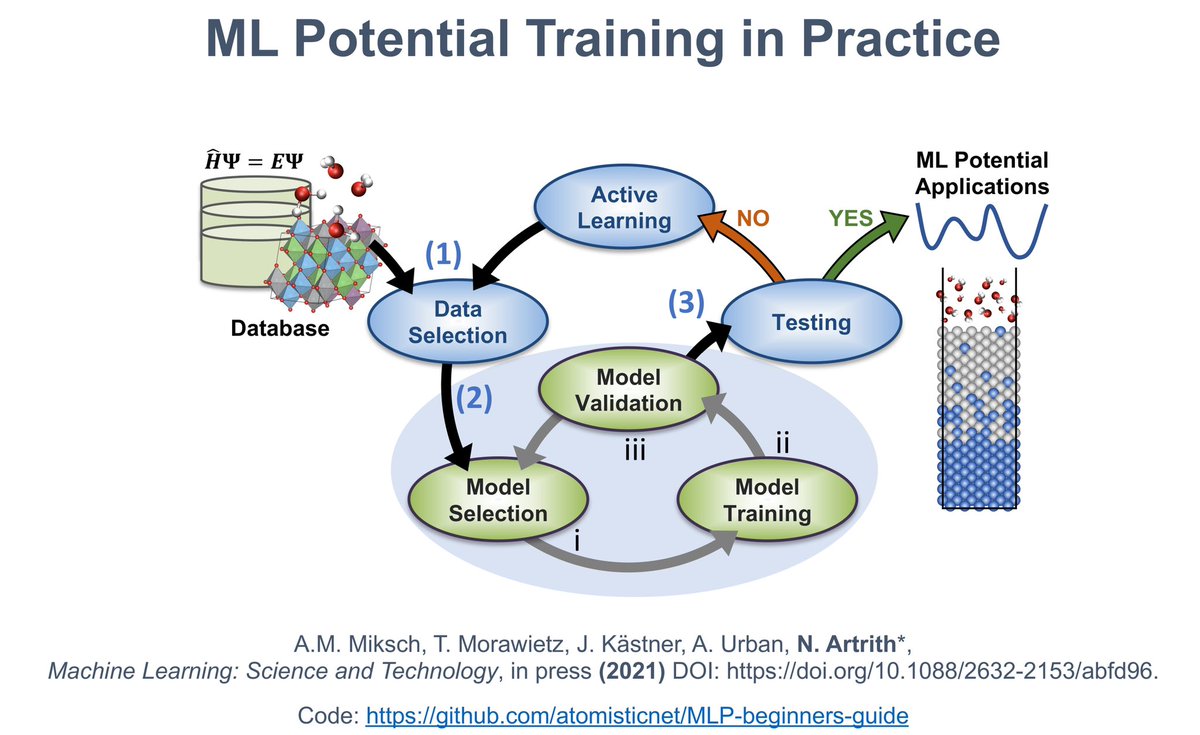
Happy to share our recipes 👩🍳👨🍳 for developing #MachineLearning potentials with @AENET_Network. Just accepted in @MLSTjournal @IOPPublishing ➡️ doi.org/10.1088/2632-2153/ab… Many thanks to April Miksch @GroupKaestner @Uni_Stuttgart @TobiasMorawietz @AlexUrban42 🍀💻🍀
4
25
110
Nong Artrith retweeted

29 Dec 2024
Refining catalyst–adsorbate interatomic potentials with transfer learning in ænet-PyTorch
From optimizing catalyst interfaces to extending molecular dynamics (MD) simulations, linking broad chemical knowledge to specific adsorbate systems often poses challenges in materials research. While large-scale data repositories can help, constructing accurate machine learning potentials (MLPs) for adsorbate-catalyst complexes still requires significant computational resources, especially if only a small custom data set is available.
A recent paper by An Niza El Aisnada and coauthors proposes a transfer learning strategy to build stable MLPs under tight data constraints, particularly for catalyst–adsorbate systems. Leveraging the Open Catalyst 2020 (OC20) database—a substantial collection of diverse catalyst configurations—they pretrain MLPs on carefully selected OC20 subsets. By transferring the pretrained models to a smaller target data set (only a few hundred ab initio references), they achieve robust energy and force predictions. Notably, these transfer-learned MLPs remain stable for hundreds of picoseconds of MD simulation on Cu–Au/water cluster systems, whereas models trained only on limited local data fail much sooner.
They explore two main approaches for selecting relevant subsets from OC20: (1) random sampling to mirror the original database broadly, and (2) filtering by chemical environment (for example, focusing on Cu–Au). The pretrained MLPs, once transferred, exhibit significant improvements in force prediction and MD stability—even though raw RMSE metrics in smaller data sets do not always reflect such gains.
A key component of their workflow is the “ænet-PyTorch” framework. Originally, the Atomic Energy Network (ænet) was a C/Fortran toolkit for ANN-based MLP construction. In this updated PyTorch extension, parallelization and GPU acceleration are harnessed for efficient training, allowing the incorporation of both reference energies and forces. Through transfer learning, a user can import a pretrained model (from large data sets), then fine-tune it on domain-specific references to achieve both accuracy and scalability.
Beyond a simple methods comparison, the authors emphasize pragmatic insights—such as the importance of CV-limited data curation, the synergy of domain-focused subset selection (e.g., focusing on Cu–Au to boost transfer success), and the pitfalls of relying on single scalar metrics like RMSE. They illustrate how data set sizes and neural network hyperparameters (for balancing energy vs. forces) drive generalizability in practice.
Paper: pubs.acs.org/doi/full/10.102…

11
43
3,734
Nong Artrith retweeted

20 Oct 2024
One of the largest materials datasets and SOTA ML potentials are open-sourced by FAIR Chemistry.
Immensely proud to be part of the team that delivers open science and catalyzes community involvement and advances in this field.
x.com/OpenCatalyst/status/18…
18 Oct 2024

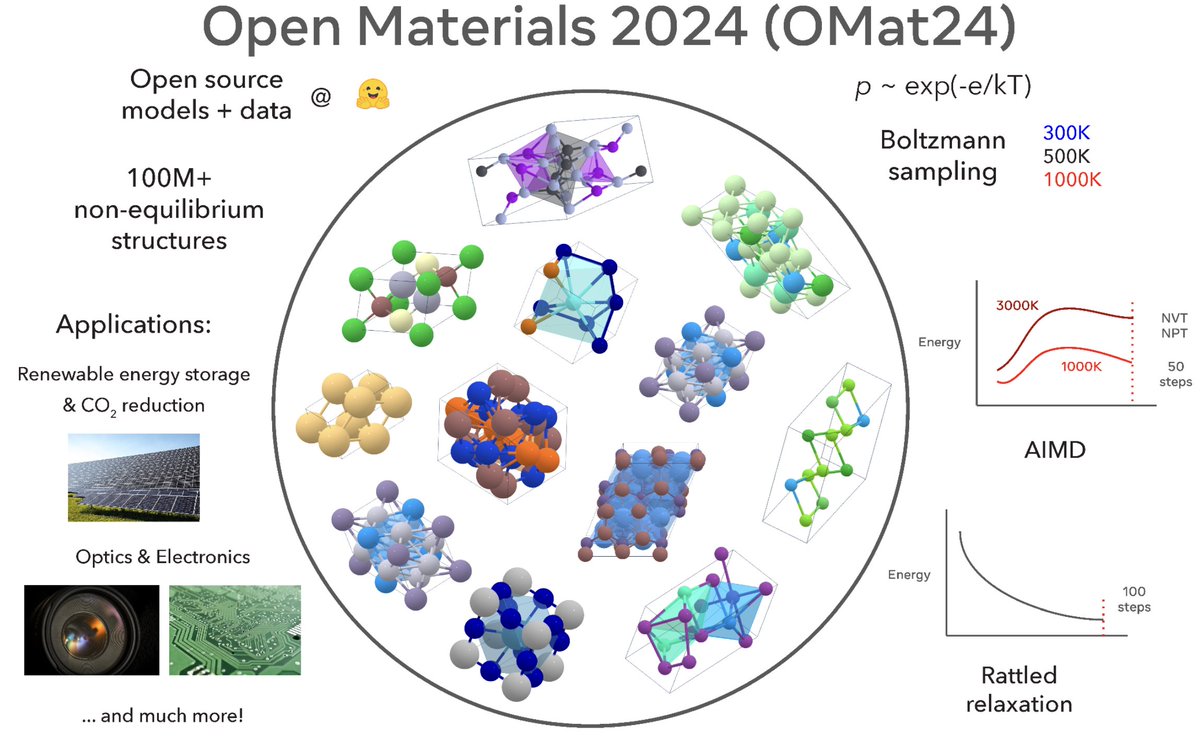
Introducing Meta’s Open Materials 2024 (OMat24) Dataset and Models! All under permissive open licenses for commercial and non-commercial use!
Paper: arxiv.org/abs/2410.12771
Dataset: huggingface.co/datasets/fair…
Models: huggingface.co/fairchem/OMAT…
🧵1/x
3
28
2,107
Nong Artrith retweeted

8 Oct 2024
BREAKING NEWS
The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”

979
13,038
32,135
12,691,300
Nong Artrith retweeted

4 Sep 2024
Very interesting roundtable on "How to best combine AI and physical modelling to accelerate discoveries with societal impact?" moderated by @nicola_marzari, with Laura Toni, @adrian_roitberg & @MicheleCeriotti at the #CECAM55 conference!

1
5
35
2,695
Nong Artrith retweeted

8 Jul 2024
Taking a picture of @HannaTuerk discussing the photo rules of the @cecamEvents workshop on #machinelearning for electronic structure in Berlin. So meta.

1
19
2,141
Nong Artrith retweeted

21 Mar 2024
We got started! Excited to have a great line up of speakers and a large audience in the X Theatre Hall today @tudelft. #materialsscience #MachineLearning




8 Feb 2024

These speakers 👆🧵 will talk about #MachineLearning & Molecular Discovery in the X Theatre Hall @tudelft on 21 March.
Join them exploring the future of scientific discovery, facilitated by #ML and #quantummechanics.
📢 Keynote: Prof. Max Welling
🌐 4tu.nl/htm/joint-materials-s…
12/



3
8
1,190
Nong Artrith retweeted

18 Mar 2024
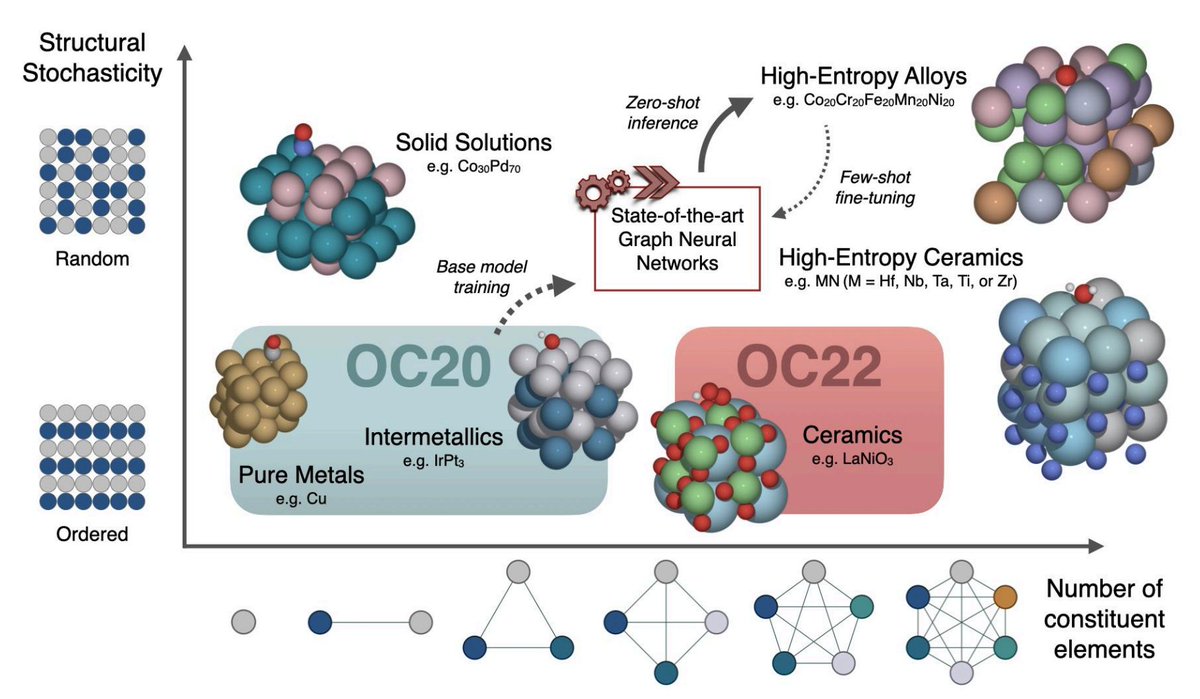
Paper shared on arXiv showing catalyst AI/ML models trained on datasets like @OpenCatalyst can generalize to solid solutions like high entropy alloys (HEA)! This is exciting because the design space of HEAs (with >5 components) is combinatorially large.
arxiv.org/abs/2403.09811
4
38
169
15,819
Nong Artrith retweeted

14 Mar 2024
Glad to share our recent work on modeling the cation-disorder in halide superionic conductors. 🔋
An interesting study integrating cluster expansion Monte Carlo & machine learning interatomic potential molecular dynamics. 👇
14 Mar 2024

The effect of cation-disorder on lithium transport in halide superionic conductors arxiv.org/abs/2403.08237
3
8
2,094
Nong Artrith retweeted

13 Mar 2024
Bye, Viennese Schnitzel; hello, California rolls! I've just moved to @UCB_Chemistry. I'm looking forward to new challenges and collaborations. And I thank the tremendous support and lovely colleagues from @ISTAustria over the past few years.
23
5
190
17,928
Nong Artrith retweeted

10 Mar 2024
SUNER-C Consortium Meeting at @UniUtrecht (1)
Last week we've organized the SUNER-C 4th Consortium Meeting. On Thursday the event took place in the Speelklok Museum in the city centre; on Friday we were in the David de Wiedbuilding, where there was a.o. a lab tour.
@sunergy_eu




2
9
1,165
Nong Artrith retweeted

18 Oct 2023
We proudly present our 524 page book on equivariant convolutional networks.
Coauthored by Patrick Forré, @erikverlinde and @wellingmax.
maurice-weiler.gitlab.io/#cn…
[1/N]

27
239
1,118
161,214
Nong Artrith retweeted

2 Mar 2024
This looks amazing: capturing carbon from seawater and generating hydrogen as a byproduct. Given the rate the climate is changing I am sometimes wondering why we are not pouring billions into these projects and put ITER / LHC on the backburner for a while. newatlas.com/energy/equatic-…
6
11
95
14,413
13 Feb 2024
👩🔬🧑🔬⚛️ Just wrapped up our 1st #eChems lecture @UUBeta. Prof. M Koper explores electrocatalytic reaction rates. Stay tuned for the upcoming online version 🎓🧪@sUUstainability Organizer @NArtrith @wardvanderstam @Peter2Ngene @ArnaudThevenon @DeptChemUU shorturl.at/fuz34



1
17
1,293
Nong Artrith retweeted

2 Feb 2024
David Reichman, JCP Associate Editor and Professor of Chemistry at Columbia University, wishes JCP a Happy 90th Birthday 🎈 - a journal he has looked to and respected since he was an undergraduate. @ChemColumbia
11
34
3,405
2 Feb 2024
⚡️🔋☀️Attending the 2nd Edition of the NWO NERA (NL) Symposium, '#EnergyTransition - Collaborating towards a Sustainable Future' I think our ML/AI models could also be useful 😊#NWONERA Come see our poster & look forward to opportunities to work together ☀️@NArtrith @Peter2Ngene


1
11
745
Nong Artrith retweeted

31 Jan 2024
Alex Urban @ChemeCU has received the @NSF Early Career Award, one of the highest honors for junior faculty.
Urban is being recognized for his research in building materials for clean energy applications, and will use the NSF funding to address critical challenges that arise from climate change. Read more:
engineering.columbia.edu/new…
@DataSciColumbia @CEEC_CU

2
9
5,546

1st pymatgen release of the year v2024.1.26 now on PyPI! Big thanks to @alexganose for a significant (backwards compatible!) refactor of the VASP input sets (to enable merging atomate2 input sets into pmg). Also in this release: over a dozen bug fixes, ... github.com/materialsproject/…
2
2
32
2,352
Nong Artrith retweeted
22 Jan 2024
Join us and learn more about ML for Simulating Complex #EnergyMaterials with Non-Crystalline Structures from Dr. Nong Artrith during the @4TU_HTM Workshop on the role of #machinelearning in Molecular Discovery @tudelft, 21 March '24.
Full programme:
🌐4tu.nl/htm/joint-materials-s…
4/

1
4
12
810
Nong Artrith retweeted

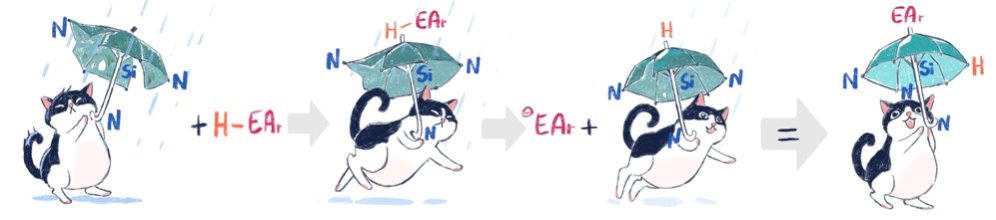
Happy to share the work of @Pam_Benzan, just accepted in @angew_chem, on the addition of O–H, S–H, and N–H bonds to an anionic #silicon center!
Work done at @UUBeta @UU_ISCC @DeptChemUU, funded by @MSCActions.
onlinelibrary.wiley.com/doi/…
2
8
59
5,558
Nong Artrith retweeted
9 Jan 2024
Congrats to Dr. Shuang Yang for an Excellent PhD Defense
Shuang has studied a.o. the effect of post-transition metals (Bi, Pb & Sn) on the properties of Cu for electrochemical CO2 reduction.
Well done & wishing you all the best for the future, Shuang!
@UniUtrecht @mcecresearch




1
3
32
2,745