
local models, cloud apis, and the boring infra between them. model routing notes → llmapi.ai
Joined July 2015
- Tweets 717
- Following 74
- Followers 28
- Likes 6,013
Photos and videos
NVMBR retweeted

Jun 7
there are still people who prefer claude code over codex
Do you guys agree?

97
4
117
9,091

SOMEONE JUST OPEN-SOURCED AN AI THAT SEARCHES EVERY MAJOR PLATFORM AT ONCE
Reddit, X, YouTube, Hacker News, TikTok, Polymarket, GitHub
not one by one - PARALLEL
it ranks results by what real people actually do:
- upvotes from Reddit
- likes and timing from X
- real money predictions from Polymarket
- commits and PRs from GitHub
then generates ONE brief
28,700 stars on github 2,400 forks. MIT license.
Google is strong on the web
ChatGPT has some access
neither of them touches this combination
setup guide (2 minutes):
Claude Code:
> /plugin marketplace add mvanhorn/last30days-skill
Hermes:
> npx skills add mvanhorn/last30days-skill -g -a hermes
Cursor / Codex / Copilot / Gemini CLI:
> npx skills add mvanhorn/last30days-skill -g
then run it:
> /last30days bitcoin
> /last30days "OpenAI vs Anthropic"
> /last30days [any topic]
no API keys needed for Reddit, Hacker News, Polymarket, and GitHub
X works if you're already logged into x. com in your browser
YouTube: brew install yt-dlp
repo in replies

Hermes Agent just got a massive upgrade 😳
Nvidia's Nemotron 3 Ultra is now FREE through nous portal until june 18 (most powerful model of nvidia)
model specs:
- 550B parameter model
- 65-70.4% on SWE-Bench Verified
- built for long running agentic tasks
- frontier reasoning for complex multi-step workflows
- available free june 4 - june 18 only
nous research joined nvidia's nemotron coalition and partnered with nebius to make this happen
here's how to get it:
option 1 (desktop app, easiest):
> download hermes desktop app at hermes-agent.nousresearch.co…
> open the app and complete quick setup via nous portal
> create a free nous portal account when prompted
> click change model in the app
> search "nemotron 3 ultra"
> select the variant tagged "free tier"
> start chatting
option 2 (CLI):
> curl -fsSL raw.githubusercontent.com/No… | bash
> hermes update
> hermes setup --portal
> hermes model
> select nvidia/nemotron-3-ultra:free
> hermes
option 3 (switch mid session):
> /model nvidia/nemotron-3-ultra:free
⚠️ make sure you pick the :free variant or you'll be charged
free until june 18 so move fast
save this and use nvidia most powerfull model nemotron ultra for free in your hermes agent 💜

18
7
76
37,773

Great tips.
In practice, this is how it roughly looks to run agents autonomously for hours or days.
/goal or /loop to keep it going.
Verification is crucial here.

Jun 8

Seeing a number of benchmarks showing Opus is the best model for long-running work.
Five tips for running Opus autonomously for hours/days:
1. Use auto mode for permissions, so Claude doesn’t ask for approval
2. Use dynamic workflows, to have Claude orchestrate hundreds/thousands of agents to get a task done
3. Use /goal or /loop, to nudge Claude to keep going until it’s done
4. Use Claude Code in the cloud, so you can close your laptop (easiest way is the desktop or mobile app)
5. Make sure Claude has a way to self-verify its work end to end: Claude in Chrome browser extension for web, iOS/Android sim MCP for mobile, a way to start the full web server or service for backend work
26
14
128
21,167
NVMBR retweeted

Jun 8
El ingeniero de Google que lleva 15 años enseñando a toda la web a escribir buen código publicó sus skills para Claude Code.
No son prompts genéricos.
Son flujos de trabajo reales de producción con pasos, verificaciones y comprobaciones anti-error.
47.4k estrellas. 5.3k forks. MIT.
✅ 23 skills que cubren el ciclo completo de desarrollo
✅ API design, code review, debugging, CI/CD y frontend incluidos
✅ Cada skill tiene pasos, gates de verificación y tablas anti-racionalización
✅ Compatible con Claude Code, Codex, Cursor y OpenCode
✅ Instalación con un comando: npx add-skill
✅ Context engineering skill incluida - la más importante de todas
✅ Duda sistemática integrada: CLAIM - EXTRACT - DOUBT - RECONCILE - STOP
✅ Actualizado hace 3 días. MIT.
El tío que inventó los patrones de rendimiento web para Chrome lleva meses usando estos flujos en producción.
Los acaba de regalar.
aquí lo tienes 👇
7
53
300
19,622
NVMBR retweeted

Jun 8
Tool of The Day - Day 12
name : 𝘍𝘪𝘳𝘦𝘤𝘳𝘢𝘸𝘭
→ what it does
an AI-native web scraping and crawling platform that turns websites into clean, LLM-ready data.
it can ┐
- crawl entire websites
- scrape dynamic pages
- extract PDFs
- parse documents
- search the web
- interact with websites
- convert content into markdown
- generate structured JSON outputs
all without building custom scraping infrastructure.
→ why creators care
most internet data is trapped behind messy HTML.
before AI can use it, someone has to:
- scrape it
- clean it
- structure it
- remove noise
that process normally takes hours.
@firecrawl removes almost all of that work.
instead of fighting websites, you get clean data that's ready for AI immediately.
→ creators that need it
- developers
- researchers
- founders
- marketers
- growth teams
- analysts
- AI builders
- automation operators
especially anyone building products that rely on live web data.
→ what problem it solves
- broken scrapers
- proxy headaches
- HTML cleanup
- expensive infrastructure
- token waste
- unreliable web extraction
it transforms the internet into structured data that AI can actually understand.
→ simple setup
- install the CLI
- connect the API
- enter a website or search query
- export markdown or JSON
most users can have their first crawl running within minutes.
→ how creators actually use it
- monitor crypto project documentation
- scrape competitor websites
- build research databases
- feed RAG systems
- create AI-powered search tools
- track product updates
- extract podcast transcripts
- build autonomous agents with internet access
all without writing complex scraping logic.
→ why this tool stands out
most scraping tools were built before AI became mainstream.
Firecrawl was built specifically for AI workflows.
instead of returning giant blocks of unusable HTML, it returns clean structured information designed for language models.
you tell it what you want.
it figures out how to get it.
→ best features
- AI-powered extraction
- markdown output
- structured JSON generation
- native PDF parsing
- browser interaction tools
- search scrape workflows
- browser sandbox
- natural language crawl instructions
→ best use case
perfect for ┐
- AI agents
- RAG pipelines
- competitive intelligence
- deep research systems
- monitoring websites
- data extraction
- market intelligence
- automation workflows
→ extra proof
- 125,000 GitHub stars
- 1.25M developers
- 5B requests served
- led by @CalebPeffer @ericciarla @nickscamara_
- Y Combinator backed
- rapidly growing AI developer ecosystem
- widely integrated into modern AI workflows

17
2
62
1,270
NVMBR retweeted

May 17
Hace casi un año presenté una app que había vibecodeado en tres días en la primera @cursor_ai meetup oficial de Argentina, y falló en el live demo.
Hoy la rehice en 3 horas con codex de @ChatGPTapp .
En esa época una app vibecodeada funcional medio que era una criatura mitológica, y yo no sabía la diferencia entre next.js y node.js, o como se hacía un algoritmo, o que era un callback, a ver, no sabía nada, lo mío era puras vibes.
Había devs de @Mercadolibre , gente de producto muy crack, startuperos que pensaban en productos rentables…
Y yo estaba ahi, presentando una app que a veces funcionaba y a veces no, y no entendía bien por qué.
Fast forward, varias hackathones y noches aprendiendo fundamentos técnicos de la magia negra que hacía con el chat de @claudeai , hoy empecé a rehacer aquella app y saqué la primera versión funcional en tres horas con Codex
este vídeo tiene el espíritu explorador de un gameplay, pero con suficientes tips e insights para que las personas que lo vean puedan llevarse algo
muestro todo el proceso real:
• prompt inicial que le tiré a Codex
• como armé toda la arquitectura (vibe engineering)
• @GeminiApp como capa de inteligencia Supabase como db y uso de la API de spotify para que las playlist no solo se creen, sino que aparezcan en tu cuenta
• live demo de la v1 funcionando al 100%
en el próximo video voy a transformar esa UI espantosa en algo que se sienta digno de la magia que hace cecily
si este vídeo cayó en tu algoritmo de casualidad, te cuento que subo vídeos de vibecoding regularmente, donde paso apps de idea a producción.
espero que les guste :)
3
2
55
4,599
NVMBR retweeted

May 17
看起来有吸引力
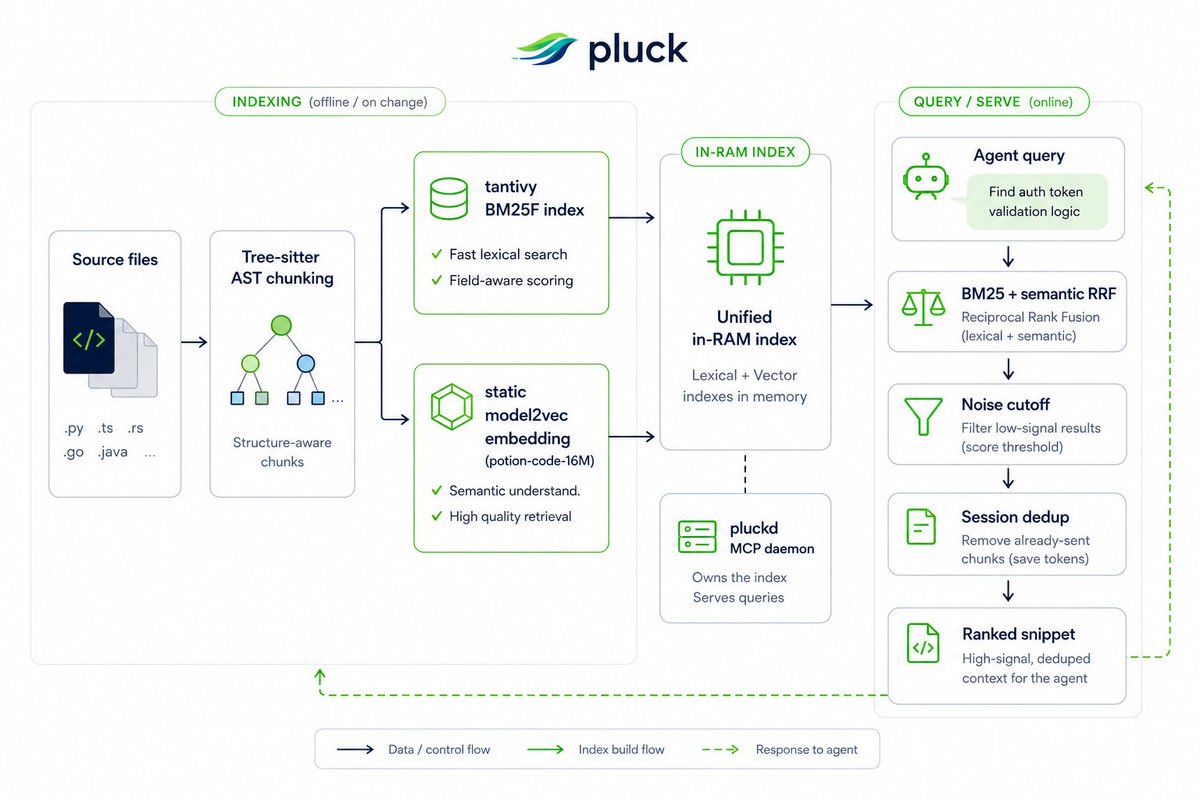
> pluck 是一个用 Rust 编写的代码检索引擎,原生支持 MCP(Model Context Protocol,模型上下文协议),专为 AI Agent 智能阅读和导航代码而设计。
实际测试结果: 在典型的代码读取场景中,可减少 84% 到 88% 的 token 消耗,同时保持(甚至提升)对核心关键内容的理解能力。
与其直接提供完整文件或随意的代码片段,pluck 使用 Tree-sitter 进行 AST(抽象语法树)级别的分块(chunking)。它能理解函数、类、逻辑块和函数签名。然后,它完美融合了两个领域的优势:
- 高级关键词搜索:(带字段的 BM25F)
- 语义重排: 采用静态嵌入(无需运行时推理)
该系统采用两阶段级联 RRF(倒数排名融合)机制,使自然语言查询和符号搜索的表现同样出色。所有内容都在本地的常驻守护进程(daemon)中进行索引,热响应时间仅为 0.07 毫秒(热启动 p50)。
此外,还有一个非常强大的额外功能:基于会话的去重。如果在之前的交互中已经展示过某个代码块,它会用一个轻量级的占位符代替。这在多轮对话中能额外带来 23% 的 token 节省。

¿Alguna vez has visto cómo un agente de IA se queda corto de contexto… no porque le falte inteligencia, sino porque desperdicia miles de tokens solo para leer código?
Usa cat o grep un par de veces en un archivo mediano y, de repente, la ventana de contexto ya está medio llena de información que ni siquiera necesitaba. Hazlo en la siguiente pregunta y el problema se multiplica.
En codebases reales, esto se convierte en el cuello de botella silencioso que limita lo que los agentes pueden lograr.
[pluck] llega para cambiar esa ecuación.
Es un motor de recuperación de código escrito en Rust, nativo de MCP (Model Context Protocol), diseñado específicamente para que los agentes de IA lean y naveguen código de forma inteligente.
El resultado medido: entre un 84 % y un 88 % menos tokens en lecturas típicas de código, manteniendo (o incluso mejorando) la capacidad de entender lo que realmente importa.
En vez de servir archivos completos o fragmentos arbitrarios, pluck hace chunking a nivel AST con Tree-sitter. Entiende funciones, clases, bloques lógicos y firmas. Luego combina dos mundos:
- Búsqueda por palabras clave avanzada (BM25F con campos)
- Ranking semántico con embeddings estáticos (sin inferencia en tiempo de ejecución)
El sistema usa una cascada de dos etapas fusión RRF para que las consultas en lenguaje natural y las búsquedas simbólicas funcionen igual de bien. Todo indexado localmente en un daemon persistente que responde en 0,07 ms (p50 en caliente).
Y hay una capa extra muy potente: deduplicación por sesión. Si ya mostraste un chunk en una interacción anterior, lo reemplaza por un placeholder ligero. Eso añade otro 23 % de ahorro en conversaciones multi-turno.
pluck no se limita a "buscar".
Ofrece un conjunto rico de operaciones pensadas para agentes:
- read → devuelve un outline inteligente (firmas cuerpos de helpers inline). Ahorro típico del 85-88 % en archivos grandes.
- symbol, peek, impact y deps → navegas grafos de llamadas, imports y dependencias sin tener que reconstruirlos tú.
- digest → comprime logs de CI y tests manteniendo los errores clave (71 % menos tokens).
- plan → sugiere los siguientes 3-5 pasos de exploración que el agente debería dar.
Y lo más importante: siempre existe el modo --raw que devuelve exactamente lo mismo que cat o grep byte por byte. Nunca pierdes la capacidad original. Es un reemplazo inteligente, no una limitación.
pluck no es "otra herramienta de búsqueda".
Es infraestructura pensada para la era de los agentes de coding.
Mientras más eficientes sean recuperando contexto relevante, más lejos podrán llegar antes de chocar contra los límites de tokens.
REPOOO👇
2
2
19
3,866
NVMBR retweeted

May 17
An Anthropic engineer literally stopped me at a coffee shop because of what was on my screen.
I was sitting at Sightglass running my Polymarket bot.
He looked over once.
Then again.
Then said:
“That’s not a normal trading setup.”
I told him the whole thing runs on:
• Claude Code
• 4 open-source repos
• $25/month
That’s it.
He pulled up a chair instantly.
“I work on the agent team at Anthropic,” he said.
“We stress test Claude for workflows exactly like this.”
Then I showed him what the bot was actually doing.
86 MILLION trades analyzed.
Every wallet.
Every entry.
Every exit.
Every profitable pattern.
One prompt:
“Find wallets with 100 trades and 70% win rate. Rank by profit. Export the best ones.”
Claude scanned 14,000 wallets in 4 minutes.
Returned 47.
The top 20 wallets made more money than the other 13,000 combined.
He stared at the results and said:
“That’s not data analysis.
That’s a weapon.”
And we were just getting started.
Second repo:
A Rust CLI scraping 500 live Polymarket markets in minutes.
Claude filtered everything automatically:
• spread gaps
• liquidity depth
• timing windows
• whale behavior
500 markets became 35.
Before I even looked at them.
93% rejected automatically.
Then a trade closed live on my screen.
$84.
He didn’t even blink.
“How does it decide when to enter?”
3 independent AI agents:
• arbitrage
• convergence
• whale-copying
No shared memory.
2 agents agree = full position
1 agrees = half size
Disagreement = no trade
That consensus system alone cut 40% of losing trades.
Then he asked the real question:
“What about exits?”
That’s where it gets stupid.
The profitable whales rarely hold to settlement.
91% exit early.
So my bot exits BEFORE they do.
It takes profit at:
• 85% expected move
or
• unusual volume spikes
Basically:
It copies smart money…
then front-runs their exits.
He just sat there staring at the terminal.
“How much did you start with?”
$200.
27 days ago.
Current balance:
$14,300.
271 trades.
74% win rate.
Sharpe ratio: 2.47.
Fully automated.
I haven’t touched it in weeks.
Before leaving he said:
“This is almost identical to the internal scenarios our red team simulates.”
Next morning I got an email from him.
“Would you be open to speaking with our policy team?”
I replied:
“The article IS the meeting.”
The craziest part?
This stack costs less than Netflix.
AI is no longer replacing workers.
It’s replacing entire hedge funds.
Comment “Claude” if you want the framework.
1,469
152
1,354
265,054
NVMBR retweeted

May 17
Este plugin cambia por completo lo que creías saber sobre Claude Code.
Anthropic lo lanzó discretamente: claude-code-setup, un plugin oficial que escanea tu proyecto y te dice exactamente qué te falta: hooks, skills, servidores MCP, subagentes y automatizaciones. Todo configurado automáticamente, paso a paso.
El verdadero poder de Claude Code no viene solo de la herramienta. Viene del ecosistema que la rodea. Sin eso, estás funcionando en modo degradado sin darte cuenta.
Instalación:
/plugin install claude-code-setup@claude-plugins-official
Guarda este post antes de olvidarlo.
12
207
1,591
133,832
NVMBR retweeted

Elon Musk just dropped an AI coding tool that runs multiple agents in parallel.
And most devs have no clue it exists yet.
Here's how to set up Grok Build in under 60 seconds:
→ Subscribe to Super Grok Heavy
→ Paste 1 command in your terminal
→ Sign in
→ Start with Plan Mode (always)
→ Approve the diff before it ships
That's it. You're running a junior engineer inside your terminal. 🚀
Save this post, you'll thank yourself later.
Want the SOP? DM me.
2
5
21
1,125
NVMBR retweeted

May 12
300 AI agent resources organized into 20 categories inside one GitHub repo.
Not another useless “top AI tools” thread.
These are the actual frameworks, workflows, papers, and open-source projects people are using to build real AI agents right now.
✅ 300 curated resources
✅ 20 organized categories
✅ Real-world use cases
✅ Active open-source projects
✅ Constantly updated
If you’re serious about AI agents in 2026, this repo is gold.
Link 👇
5
7
12
1,353
NVMBR retweeted

May 15
ELON JUST ENTERED THE AI CODING AGENT WAR
* xAI launched Grok Build Beta with autonomous coding and terminal execution
* Can analyze repos, modify files, test fixes, and iterate without constant supervision
16
11
86
54,462

Datawhale 的 Hello-Agents 最近还在 GitHub Trending 上。
这是一本从零开始构建智能体的开源教程,内容从 ReAct、Plan-and-Solve、Reflection,到 MCP、A2A、上下文工程、Agentic RL 和综合案例都有。
GitHub 上现在约 49.4k stars。想系统补 agent 基础的人可以看一下,尤其适合不想只看碎片文章的人。
项目地址:github.com/datawhalechina/he…
11
2
12
581
NVMBR retweeted

May 12
SOMEONE CUT THEIR AI CODING BILL FROM $4,200 TO $312/MONTH AND POSTED THE EXACT SYSTEM
Most vibe coders are burning $2,000-$5,000/month on tokens and don't realize that 50-70% of it is pure waste - the same unchanged files being re-sent to the model 50 times a day while Claude reads the entire repo just to find 30 lines that mattered.
The fix isn't a cheaper model. It's a router that automatically picks the right model for each task, combined with prompt caching that cuts input token costs by 90% on stable context.
The routing logic that saved $3,900/month:
- Architecture decisions → Claude Opus 4.6 (10% of work)
- All serious implementation, debugging, refactoring → Kimi 2.6 at $0.50/M instead of Sonnet at $3/M, same shipped quality
- Lint, format, single-line edits → Haiku 4.5
- Boilerplate and autocomplete → local Qwen 3 via Ollama, completely free
One config file and a routing system cut a $4,200/month AI bill down to $312 - without touching shipping speed or output quality.
The models didn't change. Just what got sent to them.

27
29
316
37,749
NVMBR retweeted
May 14
Everyone is flexing Claude Code.
Almost nobody is using it properly. 🤯
This official Anthropic plugin changes that completely.
claude-code-setup analyzes your repo and builds the perfect Claude Code setup for you automatically.
It recommends:
• Hooks
• MCP servers
• Skills
• Subagents
• Automations
• Workflow configs
Basically turning Claude Code into a fully customized AI engineering system for your project.
Install it once:
/plugin install claude-code-setup@claude-plugins-official
And suddenly Claude Code goes from “kinda confusing” to “how is this even real?” 🔥
3
11
55
5,251
NVMBR retweeted

May 14
Most developers are using Claude at maybe 5% of its actual power.
This 30-minute Claude Code demo makes that painfully obvious.
debugging entire repos → terminal automation → agent workflows → context memory.
One of the few AI videos actually worth watching till the end.

4
4
32
1,426

ANDREJ KARPATHY JUST SAID SOMETHING THAT SHOULD MAKE EVERY AI DEVELOPER UNCOMFORTABLE.
"90% of your AI coding bill is paying for context you didn't need to send."
You are not paying for intelligence.
You are paying for waste.
Here are the 10 things senior AI engineers stopped doing that cut their bills by 60 to 80%:
Auto-loading 50 files for a 30-line fix. $1.20 per turn on tokens you never read. 80% input waste every single session.
Running Opus on lint, format, and rename tasks. $0.60 for what Haiku nails at $0.02. 30x overpay on cleanup work.
Tool call loops that re-send the full repo on every retry. 5x context cost per agentic flow. Fixing this one thing cuts 30 to 50% of your total bill.
Defaulting to Sonnet in 2026. Kimi 2.6 matches it on most coding tasks at one sixth the cost. You are leaving 60 to 70% on the table every session.
Streaming responses on stable-prefix workflows. Kills your prompt cache. You pay 10x for tokens that should have cost cents.
Just in case file includes. 80,000-token prompts that should be 3,000. Context bloat is the silent budget killer.
Per-session knowledge rebuilding. 10 minutes writing a SKILL.md once versus paying agents to re-figure out your environment every run. $4 versus $0.30 per execution.
Single-model setups. Premium tier on every task is the most expensive mistake in AI coding right now.
Asking 10 small questions one at a time. 10 separate input prefix charges versus one batched call. 70 to 90% savings on routine workflows.
Paying for Claude Pro plus ChatGPT Plus plus Cursor Pro simultaneously. You seriously use one. The other two are habit not utility.
What actually compounds:
Context discipline. Grep before fetching. Always.
Prompt caching on every stable prefix.
Multi-model routing. Kimi 2.6 as default. Opus for the 10% that needs it.
Graduated skills via SKILL.md files.
The routing mindset. Right model for the right task.
In 12 months the gap between developers shipping on $200 a month and $4,000 a month will not be skill.
It will be how well they route.
Bookmark this. Study it.
Follow @cyrilXBT for every AI engineering insight that compounds your output and cuts your costs.

INSTEAD OF WATCHING NETFLIX TONIGHT.
Spend 1 hour with this.
Claude AI FULL COURSE that teaches you how to BUILD and AUTOMATE anything.
The people who watch this tonight will wake up tomorrow with a skill that most people will not have in 2 years.
The people who skip it will still be watching Netflix next year wondering why nothing in their life has changed.
Your call.
15
13
77
7,919

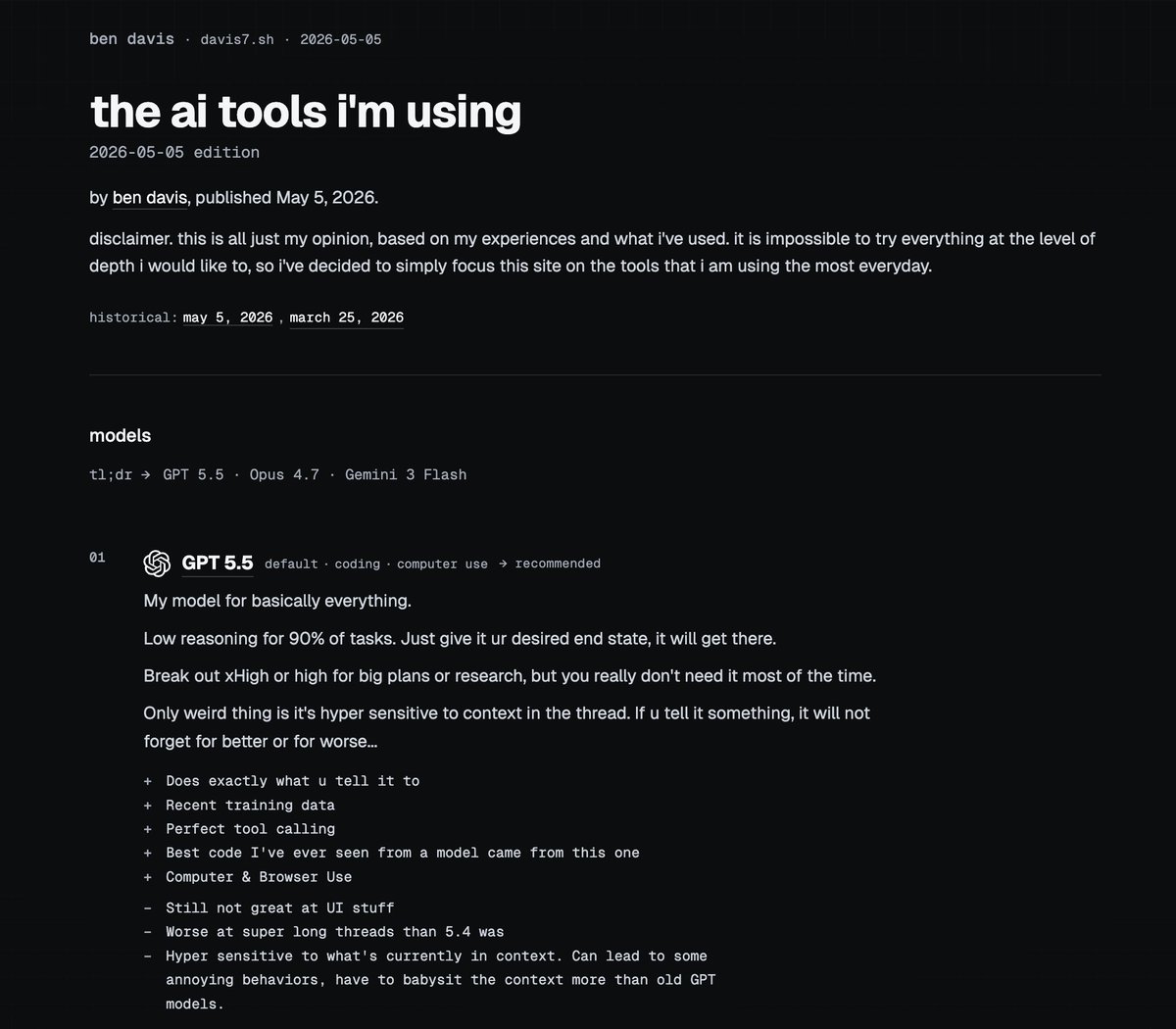
Updated the list of AI tools I'm using
Cut a lot of things out this time, wanted to just focus on what I'm really using day to day which is:
MODELS
GPT-5.5 95% of the time, then some Opus 4.7, and Gemini 3 Flash when I need to turn some blob of something into structured data
HARNESSES
Pi. Some T3 Code, but mostly Pi. Like entirely Pi. Also the Codex desktop app is really useful for image gen and browser use stuff.
SUBS
Codex $200. Cursor and OpenCode Black are both still really useful, but the vast majority is in Codex.
Only thing I left off the list that I'll probably update with next time is Droid from Factory AI. Been giving it a real shot, it's temperamental for sure but when it works it is very very impressive.

Started putting together a personal "state of ai" type site with all the models, harnesses, and subs I'm currently using why
I try to, but I physically can't test everything. This is just the stuff I'm using.
Plan is to update it monthly-ish: ai.davis7.sh
35
6
348
31,366

ANTHROPIC'S OWN APPLIED AI TEAM JUST DROPPED A FREE 25-MINUTE CLAUDE CODE WORKSHOP THAT WILL CHANGE HOW YOU BUILD WITH AI FOREVER.
Not a creator who learned Claude Code last month.
Not a tutorial channel optimizing for watch time.
The team that builds Claude.
Teaching you exactly how Claude Code was designed to be used.
Here is why this 25 minutes is worth more than everything else you have watched about AI this year.
Most Claude Code tutorials teach you commands.
This workshop teaches you ARCHITECTURE.
How Claude Code was designed to think.
How your tools are supposed to connect.
Why the workflows most people build break under real production conditions.
And how to set up a system where your AI tools actually work together instead of operating in isolated silos that require you to manually move context between them.
The gap between someone using Claude Code correctly and someone using it incorrectly is not a feature gap.
It is a mental model gap.
The people with the right mental model ship products.
The people without it spend hours debugging workflows that should have taken minutes.
Anthropic's applied AI team just handed you the mental model for free.
25 minutes.
No paywall.
No $500 course upsell at the end.
Just the best practices straight from the people who built the tool.
The engineers getting hired at $200,000 to $400,000 a year to build AI systems at the highest level understand what this workshop teaches.
Now you can too.
For free.
In 25 minutes.
Bookmark this before you open Claude Code today.
Follow @cyrilXBT for every Anthropic resource that makes Claude Code more powerful the moment it drops.
10
11
94
6,229