
Research Scientist @GoogleDeepMind. Ph.D. from @CornellCIS/@cornell_tech. I bake my own opinions.
Joined July 2014
- Tweets 270
- Following 1,567
- Followers 842
- Likes 675
2 Photos and videos

J.Nathan Yan retweeted

Mar 25
It's really neat to see all the interest in the Composer 2 technical report, from training to kernel design to inference.
If you have any questions about why we did things, feel free to ask. I'll run around the office and bug people.


35
18
320
58,021
J.Nathan Yan retweeted

8 May 2025
🔥Thrilled to share that I’ll be joining the Computer Science Department at NYU Shanghai as an Assistant Professor starting Fall 2025! @nyushanghai
🎯 I’ll be recruiting PhD students across the entire NYU network—including @nyushanghai, @nyutandon, and @NYU_Courant—to build efficient ML systems (algorithms, models, kernels, and more). I’ll also be hosting multiple RAs and interns (remote friendly). If you're interested, DMs are open! ✉️
8
4
119
24,124
J.Nathan Yan retweeted

14 May 2025
# Embeddings are underrated (2024)
just a really excellent piece of technical writing.
23
95
1,500
144,047

I will be attending #ICLR2025 in person during Apr 24-28, and presenting our research:
DART: Denoising Autoregressive Transformer
📌Fri 25 Apr 3 p.m. 08 — 5:30 p.m. 08
This is my first time visiting Singapore, and I am looking forward to chatting with old and new friends!

🚀Excited to introduce our recent work @ AppleMLR --
DART: Denoising AutoRegressive Transformer for Scalable Text-to-Image Generation!
A transformer-based model that unifies Autoregressive and Diffusion with a non-Markovian diffusion framework:
🔗 arxiv.org/abs/2410.08159 (1/n)

2
11
78
16,613
J.Nathan Yan retweeted

7 Apr 2025
Today, we're releasing a new paper – One-Minute Video Generation with Test-Time Training.
We add TTT layers to a pre-trained Transformer and fine-tune it to generate one-minute Tom and Jerry cartoons with strong temporal consistency.
Every video below is produced directly by the model in a single shot, without editing, stitching, or post-processing. Every story is newly created.
Demos: test-time-training.github.io…
Paper: test-time-training.github.io…
178
894
5,360
1,389,824
J.Nathan Yan retweeted
20 Mar 2025
Some personal news: I recently joined Cursor. Cursor is a small, ambitious team, and they’ve created my favorite AI systems.
We’re now building frontier RL models at scale in real-world coding environments. Excited for how good coding is going to be.
140
82
2,894
335,911
J.Nathan Yan retweeted

4 Mar 2025
How well do data-selection methods work for instruction-tuning at scale?
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)

4
65
324
86,240
J.Nathan Yan retweeted

25 Feb 2025
I've uploaded the latest slides & beamer source code to github.com/sustcsonglin/line…. Hopefully this repository will help train an LLM that generates Beamer slides better than I do :)
24 Feb 2025

Linear Attention and Beyond: Interactive Tutorial with Songlin Yang (@SonglinYang4 MIT/Flash Linear Attention)
I didn’t follow some of the recent results, so I zoomed Songlin and she explained it all to me for two hours 😂
youtu.be/d0HJvGSWw8A
4
24
200
20,230
J.Nathan Yan retweeted
21 Feb 2025
Introducing the first open-source implementation of native sparse attention: github.com/fla-org/native-sp…. Give it a spin and cook your NSA model! 🐳🐳🐳
10
119
756
72,422
J.Nathan Yan retweeted
18 Feb 2025
🚀 Announcing ASAP: asap-seminar.github.io/!
A fully virtual seminar bridging theory, algorithms, and systems to tackle fundamental challenges in Transformers.
Co-organized by @simran_s_arora @Xinyu2ML @HanGuo97
Our first speaker: @heyyalexwang on Test-time Regression

3
53
195
31,114
J.Nathan Yan retweeted
3 Feb 2025
Got talked into giving a DeepSeek talk this afternoon simons.berkeley.edu/workshop…
Not sure I have anything new to say here! But good excuse for me to read all the blogs.

10
49
464
37,274
🚀Thrilled to share our paper "DART" has been accepted by #ICLR2025!
Congrats to my amazing collaborators
@YuyangW95 @YizheZhangNLP @QihangZhang0224 @zdhnarsil Navdeep Jaitly @jsusskin @zhaisf!
Please also check the updated version with more results at arxiv.org/abs/2410.08159
🚀Excited to introduce our recent work @ AppleMLR --
DART: Denoising AutoRegressive Transformer for Scalable Text-to-Image Generation!
A transformer-based model that unifies Autoregressive and Diffusion with a non-Markovian diffusion framework:
🔗 arxiv.org/abs/2410.08159 (1/n)
6
24
116
13,825
J.Nathan Yan retweeted
17 Jan 2025
spent the last month building my own framework to train a diffusion model from scratch. it was hard
almost like i just learned to cast an ancient spell that requires lots of mysterious steps and ingredients. for a long time i was trying, and nothing happened. but when it worked it felt like magic
i've learned a lot so wanted to share a bit 🧵
- i'm doing *conditional* diffusion, trying to produce outputs x that depend on some inputs y. my biggest blocker was that the architectural biases matter here – you can NOT put the conditioning directly into the input, or the model will just learn to map y to x instead of using y to denoise the noisy input x. (the loss will go down but sampling will not work)
- thus the diffusion world has a zoo of "conditional" architectures that can be a little challenging to adapt for your problem. but you have to use one or else things just won't work
- apparently, architecture still matters in vision (sad). initialization, residuals, and extra normalization can make all the difference
- learning a small "probe" alongside your diffusion model is hugely valuable. you can just cut the gradients to the probe so that it doesn't affect training. this way you will know when you beat the baseline. (i'm not sure if this is common practice but it was invaluable for me)
- you need to incorporate sampling into training every-so-often. otherwise you will never figure out why your model doesn't work
- the normalization is super important. your input data needs to have ~mean 0 or std 1. otherwise learning might not work, or will be super slow
- in diffusion a lot of things can have the same shape but be different "types" in the sense that they're incompatible in some way. easy to make these bugs and the code will still run. and you often can find them by checking that the norms, stds, and means are approximately correct
- complex systems that you write from scratch will inevitably have tons of bugs. you can start with trying to learn the identity function (in diffusion just set the noise to zeros). if you can't do this something is broken. in my case this helped me realize one of my losses had a sign flipped
- in my opinion the loss after 1000 steps or so is usually a reliable signal for debugging architectural changes
- diffusion people look down on DDPM as old and outdated but turns out it's still "good enough for government work" and worked fine for me eventually
- wouldn't recommend the diffusers library. not sure it's really being developed anymore. heard the openai impl is much better
- in general building systems from scratch is a slow and frustrating way to do research and i would recommend most people just start with a good codebase and tweaking it to fit your problem. but if you build everything yourself you will learn a lot and feel a deep sense of satisfaction when it all starts working :)
33
37
555
35,219
J.Nathan Yan retweeted

13 Nov 2024
In this video, I'll be deriving and coding Flash Attention from scratch. No prior knowledge of CUDA or Triton is required.
Link to the video: youtu.be/zy8ChVd_oTM
All the code will be written in Python with Triton, but no prior knowledge of Triton is required. I'll also explain the CUDA programming model from zero.
I'll explore the following topics:
* Review of Multi-Head Attention
* Safe Softmax
* Online Softmax (with proof!)
* Introduction to GPUs and the CUDA programming model
* Tensor layouts: row-major layout, stride, reshape, transpose
* Block Matrix Multiplication
* Introduction to Triton
* Forward pass of Flash Attention in Triton
* How Autograd works
* What are derivatives, gradients, and Jacobians
* Jacobian of the Matrix Multiplication operation
* Jacobian of the Softmax operation
* Backwards pass of Flash Attention in Triton
* Triton tricks: Software pipelining
If you find this video useful, consider subscribing to my channel and sharing the video within your network of friends and colleagues.
#flashattention #triton #cuda #tutorial #python #attention #transformers #deeplearning
44
286
2,268
422,404
J.Nathan Yan retweeted

21 Dec 2024
The most beautiful thing on LLM reasoning is that the thought process is generated in an autoregressive way, rather than relying on search (e.g. mcts) over the generation space, whether by a well-finetuned model or a carefully designed prompt.
29
57
644
90,514
J.Nathan Yan retweeted

19 Dec 2024
How far is an LLM from not only understanding but also generating visually?
Not very far!
Introducing MetaMorph---a multimodal understanding and generation model.
In MetaMorph, understanding and generation benefit each other. Very moderate generation data is needed to elicit visual generation from an LLM, when trained jointly with visual understanding.

25
133
718
253,444

20 Dec 2024
Experience Gemini 2.0 Flash Thinking—the fast and transparent reasoning model that reveals its thought process in real-time! This breakthrough brings us one step closer to deeper, more reliable AI understanding. Try it now!

Introducing Gemini 2.0 Flash Thinking, an experimental model that explicitly shows its thoughts.
Built on 2.0 Flash’s speed and performance, this model is trained to use thoughts to strengthen its reasoning.
And we see promising results when we increase inference time computation!
4
485
J.Nathan Yan retweeted

17 Dec 2024
Announcement #1: our call for papers is up! 🎉
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi @eunsolc @RanjayKrishna and @AdtRaghunathan


1
41
163
23,026
J.Nathan Yan retweeted

16 Dec 2024
Today, we’re announcing Veo 2: our state-of-the-art video generation model which produces realistic, high-quality clips from text or image prompts. 🎥
We’re also releasing an improved version of our text-to-image model, Imagen 3 - available to use in ImageFX through @LabsDotGoogle. → goo.gle/veo-2-imagen-3

ALT Prompt: An extreme close-up of a craftsperson's hands shaping a glowing piece of pottery on a wheel. Threads of golden, luminous energy connect the potter’s hands to the clay, swirling dynamically with their movements.

ALT Prompt: A portrait of an Asian woman with neon green lights in the background, shallow depth of field.
263
1,313
6,896
2,291,262
16 Dec 2024
super cool paper! and this made me believe that linear complexity for high-resolution is the future!
16 Dec 2024

🎉Excited to introduce our latest work, LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity!
✨For the first time, we demonstrate high-resolution 68-second video generation at 16fps on a single GPU— without relying on autoregressive extensions, super-resolution, or frame interpolation.
🚀Our approach achieves linear computational complexity, offering up to 15x speed-up over the standard DiT architecture, while delivering improved video quality and better text alignment. We believe this linear complexity provides extraordinary scalability, paving the way to hour-length movie generation.
Paper: arxiv.org/pdf/2412.09856
Project website: lineargen.github.io/
1
7
1,316
16 Dec 2024
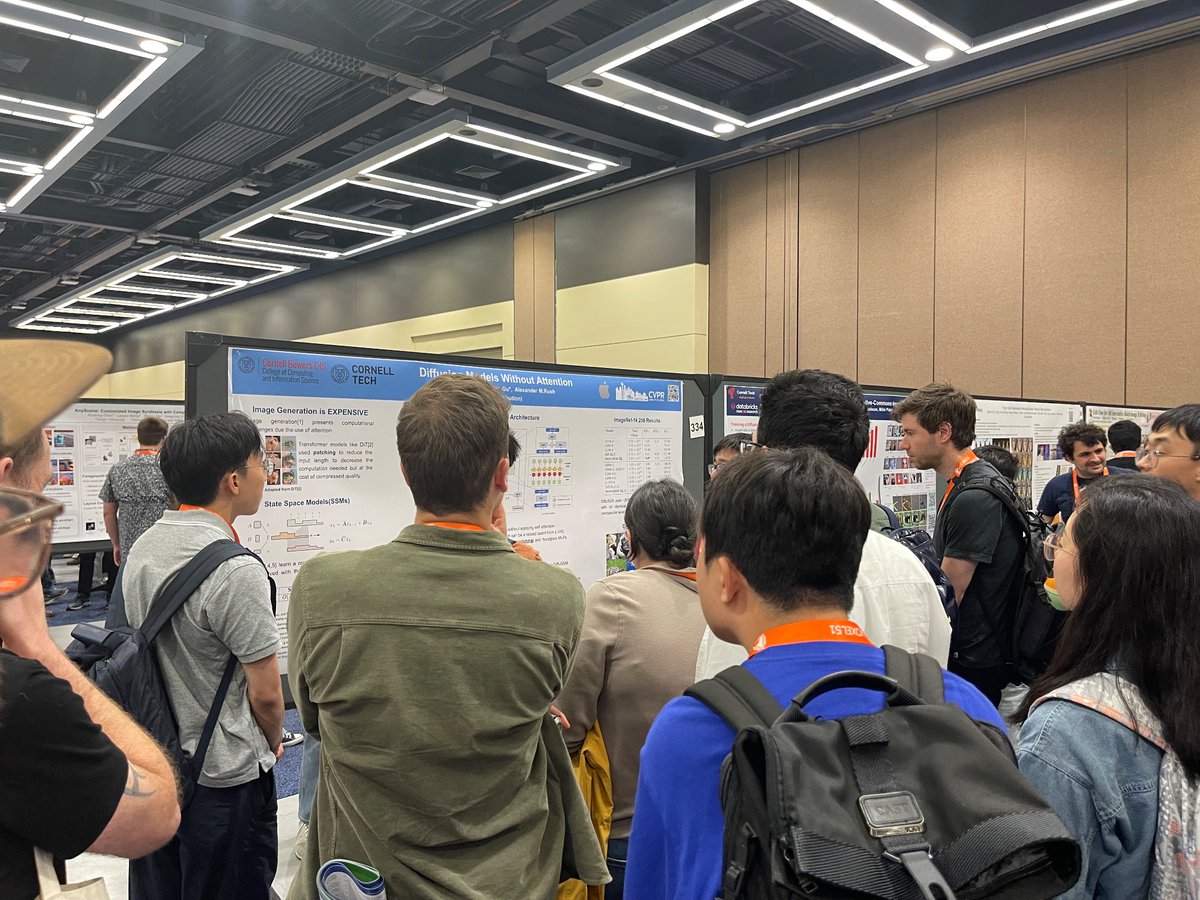
and also check out paper, which might be the first wave to explore this idea, "Diffusion Models Without Attention" (arxiv.org/abs/2311.18257) with @thoma_gu and @srush_nlp.
6
15
2,337