
PhD student @ Weizmann | Brain–Vision Models, Multimodal AI, Brain Interpretability
Joined May 2024
- Tweets 16
- Following 107
- Followers 57
- Likes 37
6 Photos and videos

Navve wasserman retweeted

Jun 9
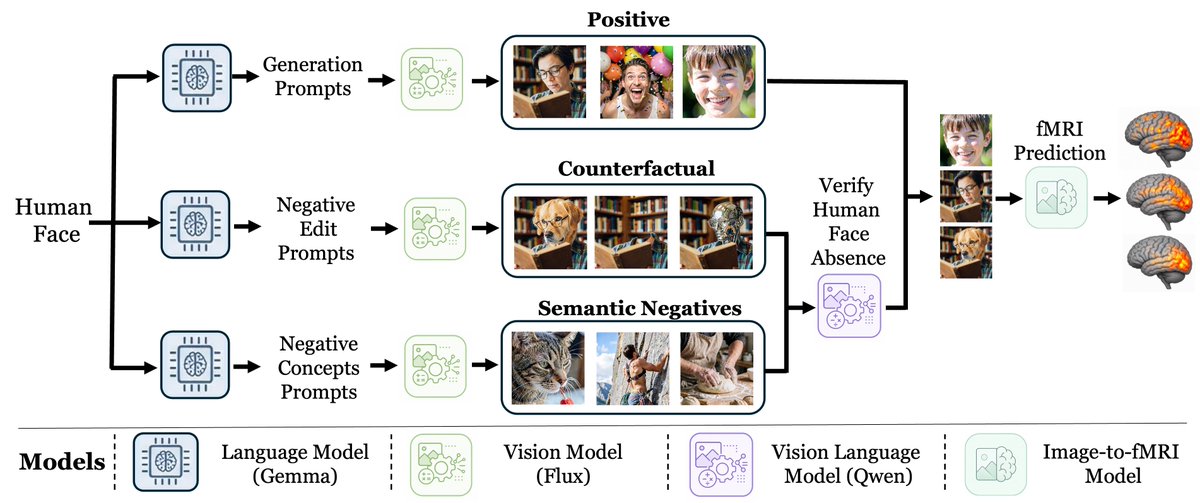
How can we tell whether a brain region causally represents a visual concept, rather than merely correlating with it?
Introducing BrainCause, a framework combining generative and brain models to create controlled stimuli and causally test neural representations.
More below 🧠👇
2
8
23
1,840
Jun 9
How can we tell whether a brain region causally represents a visual concept, rather than merely correlating with it?
Introducing BrainCause, a framework combining generative and brain models to create controlled stimuli and causally test neural representations.
More below 🧠👇
2
8
23
1,840
Jun 9
6️⃣ Are these representations consistent across people?
Despite individual differences in cortical anatomy, BrainCause identifies similar concept-selective regions across multiple subjects, providing evidence that the discovered organization is reproducible.
1
2
138
Jun 9
7️⃣ 📄 Paper:
arxiv.org/abs/2605.23895
🤗 Dataset:
huggingface.co/datasets/Brai…
🌐 Project page:
yuvalgol123.github.io/BrainC…
This work was done in collaboration with @GolbariYuv39835, Matias Cosarinsky, @RBeliy95358, @AudeOliva, Antonio Torralba, Michal Irani, and @TamarRottShaham
1
115
Navve wasserman retweeted

Jun 3
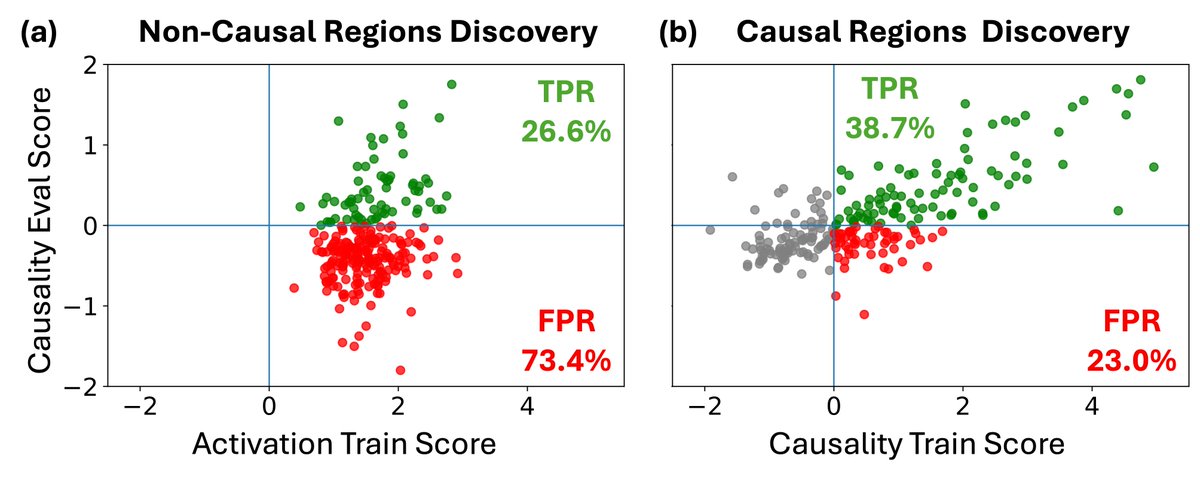
From Activation to Causality
BrainCause discovers true visual representations in the human brain by combining generative models with controlled counterfactual stimuli, moving beyond activation maps to validate neural causality.

2
6
33
1,824
Navve wasserman retweeted

May 26
FLUX.2's @bfl_ml text tokens aren't just holding your prompt.
During image editing, they absorb reference image content, and some of that absorbed content, like color and style, causally drives the output appearance.
New paper 🧵👇
7
35
203
26,033
Navve wasserman retweeted

May 17
I'm proud we are releasing LAION-fMRI, a densely sampled 7T fMRI dataset of natural images, with very broad stimulus sampling for testing countless hypotheses & deeply exploring brain representations. It is now available at
laion-fmri.hebartlab.com/
What does LAION-fMRI offer? 🧵
3
67
236
21,325
Navve wasserman retweeted

Mar 19
Diffusion models are great, but we can squeeze out so much more from them. The only problem is that it usually requires extra training or manual representation editing. In our new paper, we show that with the current capabilities of LLMs, it is much simpler than we thought!
8
37
401
34,812
12 Dec 2025
Thanks @rohanpaul_ai for sharing our new work!
Automatic Interpretability Pipeline Human Brain Data = 🧠🔍🔥
See how we use a large-scale automatic interpretability pipeline to discover what concepts are represented in the human brain.
Page & Demo: navvewas.github.io/BrainExpl…
12 Dec 2025

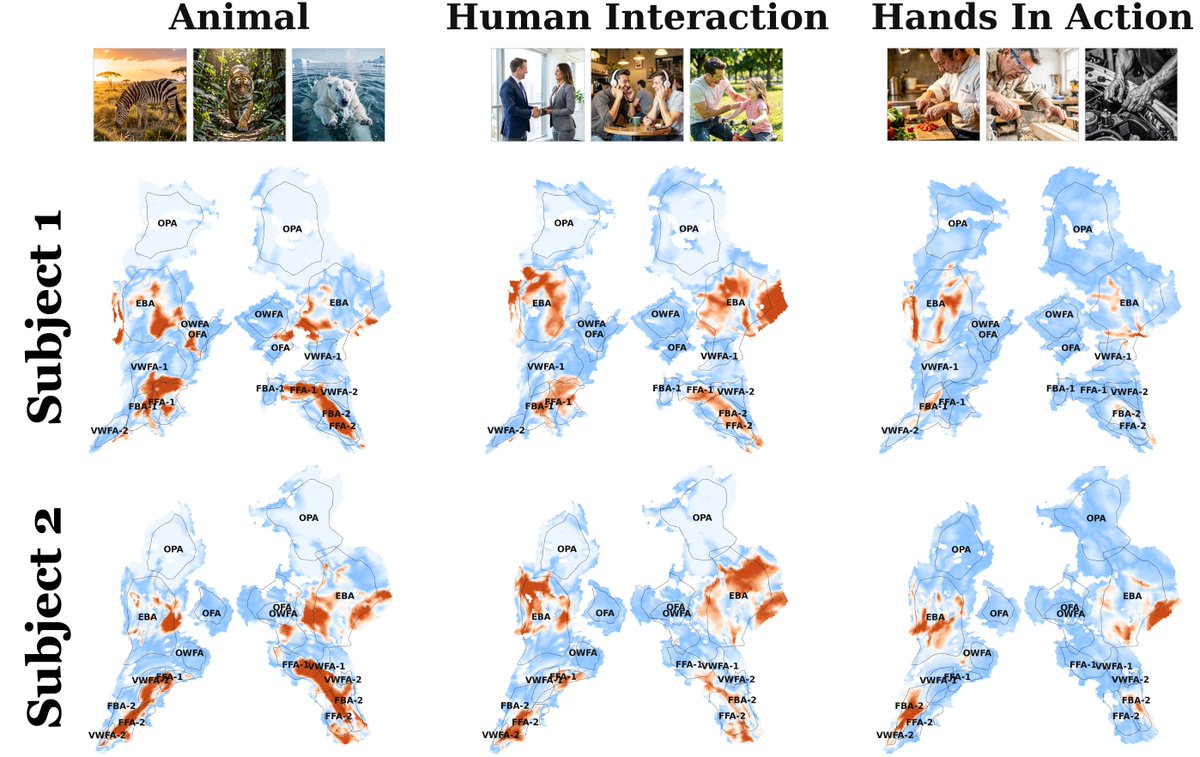
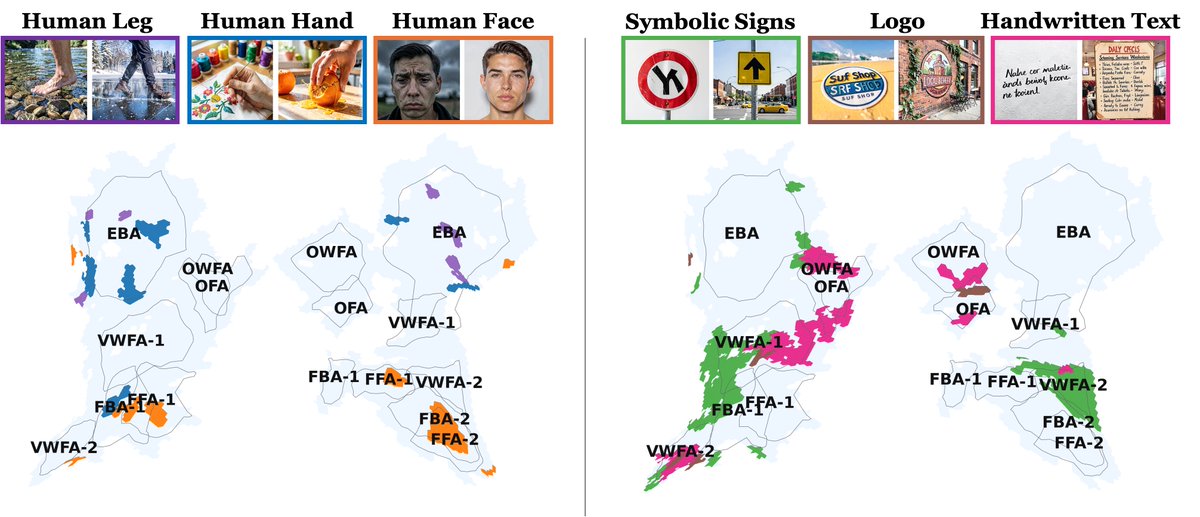
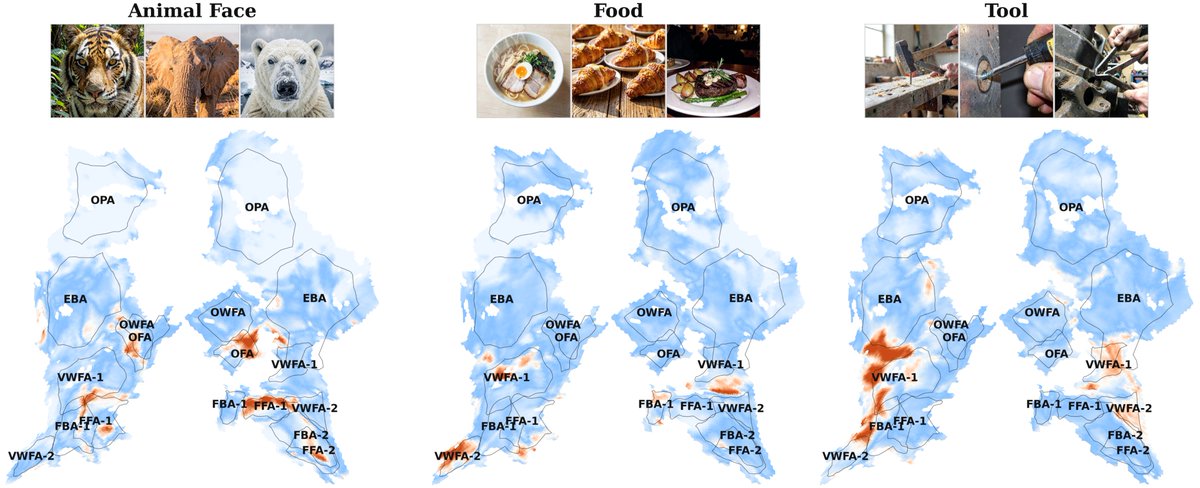
This paper uses AI-style interpretability tools to map which images trigger which visual concepts in the human brain.
It scales by adding about 120K extra images using predicted functional magnetic resonance imaging (fMRI) signals.
The problem is that fMRI data has about 40K voxels per person, each voxel is a tiny 3D pixel, and manual labeling does not scale.
The pipeline first breaks each brain region’s activity into patterns that can be mixed to rebuild any response, and a sparse autoencoder pushes each response to use only a few patterns.
For every pattern, it finds the top images that trigger it, captions those images, and has a model that writes text suggest shared meanings like “kitchen” or “hands in action”.
To avoid random labels, it builds a big concept list, marks each image as true or false for each concept, then keeps the concept that shows up most consistently in that pattern’s top images.
The payoff is a searchable map from image concepts to brain areas, plus a fair way to compare breakdown methods using held-out real scans.
----
Paper Link – arxiv. org/abs/2512.08560
Paper Title: "BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain"

1
2
25
3,753
Navve wasserman retweeted
11 Dec 2025
Unlocking the brain's visual secrets with a new AI framework from MIT
Researchers introduce BrainExplore, an automated system that maps thousands of interpretable visual concepts directly from fMRI activity. It's a huge leap towards understanding how our minds process the world.

1
5
28
1,912
Navve wasserman retweeted
6 Nov 2025
Brain-IT: Reconstructs images from fMRI with unprecedented faithfulness & data efficiency
This brain-inspired approach uses a Brain-Interaction Transformer to faithfully recover visual content from fMRI. It outperforms current SoTA and achieves strong results with just 1 hour of data from new subjects, matching models trained on 40 hours.

2
21
92
13,460