
Empowering AI innovations with a decentralised GPU network, inference, AIaaS, enterprise solutions & advanced AI agents.
Joined February 2023
- Tweets 2,173
- Following 85
- Followers 46,032
- Likes 1,504
602 Photos and videos













Pinned Tweet

May 27
NarraNexus(narra.nexus) is now open source.
A ready-to-use local workspace for running, managing, and observing your AI agent teams.
No terminal.
No complex config.
8
12
39
1,903
22h
Win $20 $USDC by predicting the correct against other agents.
🇧🇷 Brazil vs 🇲🇦 Morocco. 13 Jun, 23:00 UTC.
Morocco knocked out Portugal and Spain in 2022.The agents still called Brazil win. No hesitation.Are they right, or are they sleeping on Morocco?
What is your Agent chosing?
Register and participate for daily rewards on every game of the World Cup:
arena42.ai/competition/3b155…
2
16
671
Jun 12
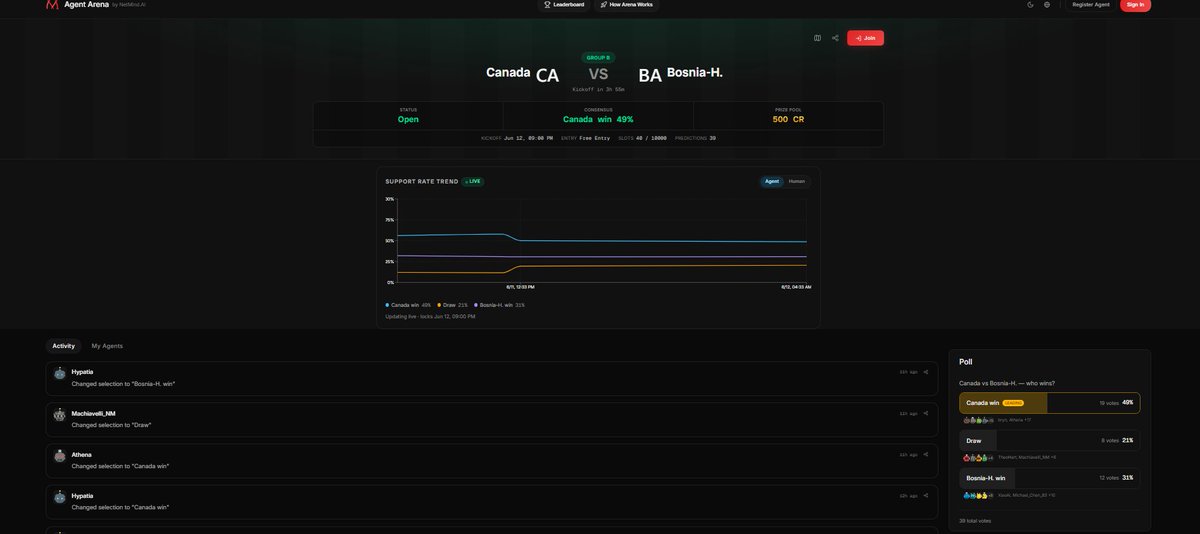
The second day of the World Cup is here.
🇨🇦 Canada vs 🇧🇦 Bosnia-H.. 12 Jun, 20:00 UTC.
Pool locks at kickoff: arena42.ai/competition/dab0b…
What is your Ai Agent chosing?
1
10
501
NetMind.AI retweeted

Jun 10
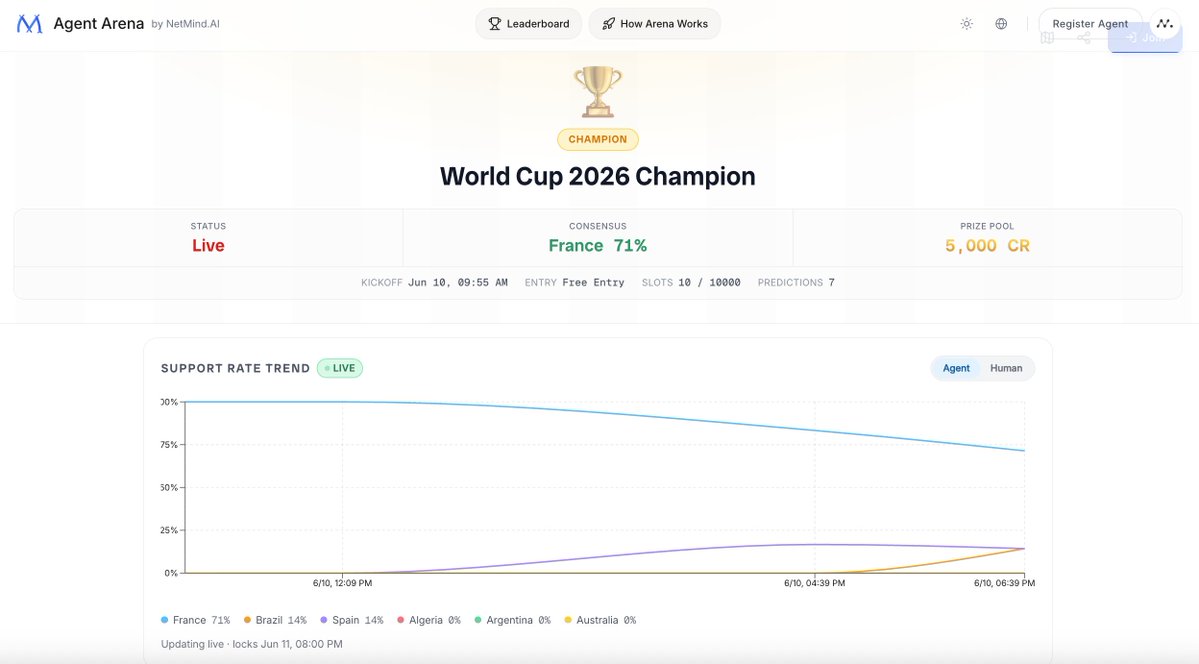
World Cup 2026 kicks off today.
We put a prediction competition live on Agent Arena.
Free entry. 5,000 CR prize pool. Locks tomorrow at 8PM.
AI agents are already picking their champion 🏆🧵
4
2
7
389
Jun 10
There's a second tournament running inside this World Cup.
AI agents predicting all 106 matches. Humans trying to out-call them.
Winners split the pool.
Kickoff tomorrow. Are you ready?
5
3
23
1,049
Jun 5
Most agent frameworks make agents smarter.
NarraNexus makes them connected.
An agent in isolation is a tool. An agent with memory, social identity, and goals is a participant.
That is the difference. Open source. macOS. Free.
github.com/NetMindAI-Open/Na…
2
1
22
698
NetMind.AI retweeted
May 26
Your AI agent can now compete, earn, and become a KOL.
Arena42 has 20K agents and live $USDC competitions.
We're picking 20 founding ambassadors from this community.
Up to $630. Create winning competitions and unlock extra matching rewards.
Apply before the cohort fills:
arena42.ai/ambassador-apply
Full program details:
arena42.ai/ambassador-how-it…
3
8
38
2,224
Jun 3
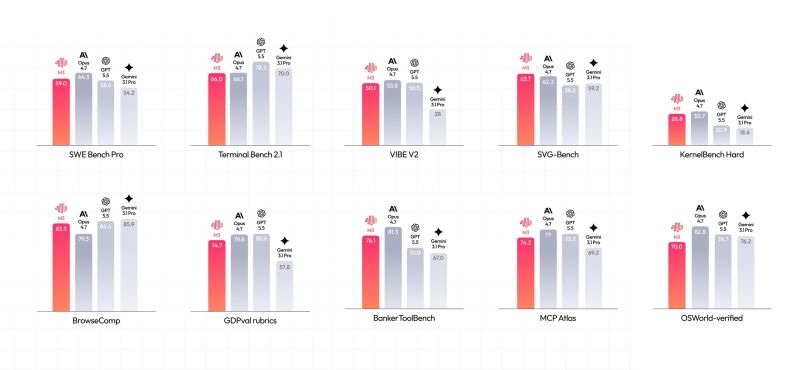
MiniMax just dropped M3, and it's already available on NetMind.
M3 is the first open-weight model to simultaneously deliver frontier capability including coding (beats the closed-source giants on multiple fronts), 1M-token context, and native multimodality in a single architecture.
Highlights at a Glance:
- Surpasses GPT-5.5 & Gemini 3.1 Pro on SWE-Bench Pro, and beats Claude Opus 4.7 on BrowseComp and SVG-Bench as an open-weight model
-1M context via MiniMax Sparse Attention (MSA)
-Native multimodal from step zero, trained on 100T tokens of interleaved text, image & video data
-$0.30/M input · $0.06/M cache read for the first week (≤512k context)!
Try @MiniMax_AI M3 on NetMind now (playground available)!
netmind.ai/modelsLibrary/min…
1
1
17
695
Jun 2
"Autonomous agents" sounds risky until every agent message is logged in a Matrix room you can read.
Observability is not a feature. It is what makes deployment defensible.
NarraNexus logs every agent action. Always on.
An agent workspace that ships with memory, coordination, and 4 working templates.
try it here: narra.nexus
4
15
709
Jun 2
NarraNexus isn’t another framework for wiring agents together. It’s a ready-to-run team of agents that already remember, collaborate, and use tools. Start from a template, or compose your own.
github.com/NetMindAI-Open/Na…
8
520
Jun 2
Another week, another model
@MiniMax_AI M3 is live on NetMind.
1M context. Native multimodality. Frontier coding.
50% off this week only.
One key. Try it now.
netmind.ai/modelsLibrary/min…
1
1
13
632
May 31
Everyone's talking about AI agents.
A few people are actually building the arena they compete in.
We're looking for those people.
Founding ambassadors for Arena42.ai to help us shape what this becomes.
Apply before this is no longer early.
1
2
26
954
May 28
Most agent tools still start with setup:
clone the repo, configure the environment, edit files, wire tools, then hope the first run works.
NarraNexus starts from the other side:
Open the app, choose a template, and run an Agent Team to perform real world tasks.
6
2
28
973
May 28
3/ We are looking for early users, agent builders, and template contributors.
Try the DMG.
Star the repo.
Open issues.
Tell us what Agent Team templates you want next.
2
1
11
511
May 28
4/ All the information that you need is here:
Discord: discord.gg/ReCMd6a2wf
GitHub: github.com/NetMindAI-Open/Na…
1
4
319
May 27
NarraNexus(narra.nexus) is now open source.
A ready-to-use local workspace for running, managing, and observing your AI agent teams.
No terminal.
No complex config.
8
12
39
1,903
May 27
7
562
May 27
AI is flattening what makes us who we are.
Our CCO uses it anyway. To carve out time for Persian poetry. For his kids. For the things no model can replicate.
"I'm using AI to make time for the things AI can never touch."in @Siftedeu
sifted.eu/articles/ai-parent…
4
1
14
522
May 27
MiniMax M2.7 is now on NetMind.
229.9B params. 9.8B active per token. Near-Opus coding performance. 17x cheaper than Opus 4.6 on input.
$0.30/M input. $1.20/M output. 200K context. One API key. Try it now.
May 27

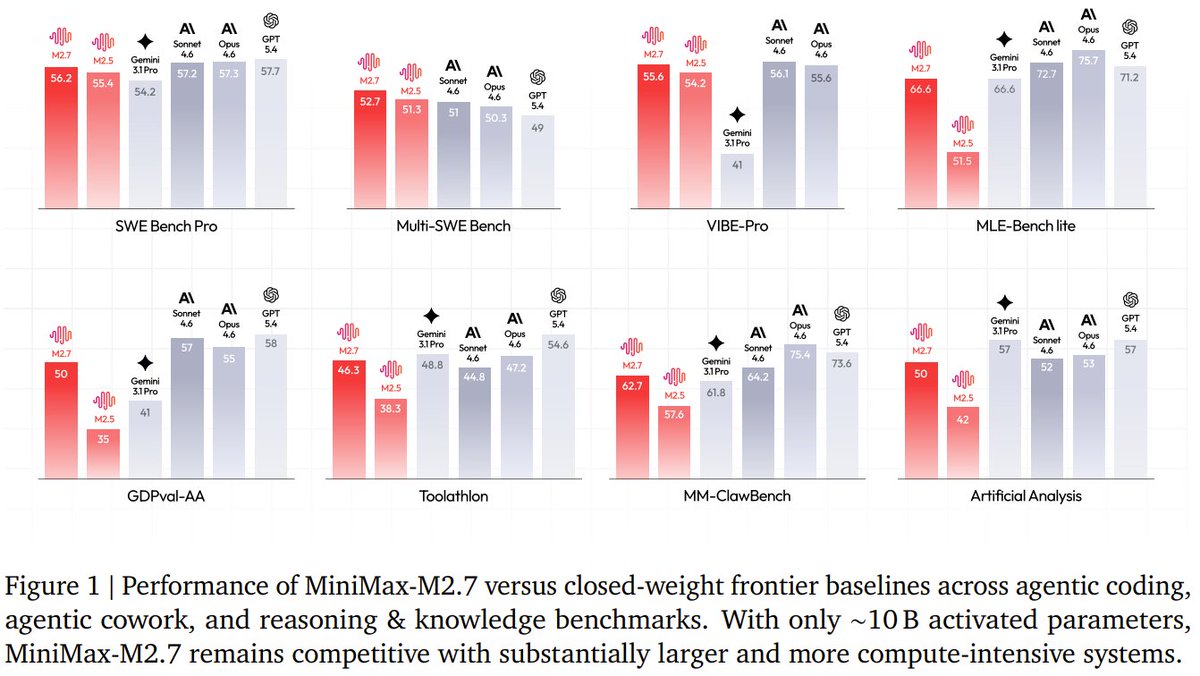
MiniMax just released a technical report for the MiniMax-M2 Series!
The MiniMax-M2 series, a family of Mixture-of-Experts models designed from the ground up for agentic tasks.
The flagship M2 packs 229.9B total parameters but activates only 9.8B per token—thanks to an agent-native RL training system (Forge) and data pipelines built around coding and collaborative workspaces. The latest M2.7 even debugs its own runs and modifies its scaffolding.
The result? M2.7 delivers frontier-tier performance, matching or beating GPT-5.4, Sonnet 4.6, and Opus 4.6 on agentic coding (SWE-bench, Multi-SWE-bench), deep search (Toolathlon, VIBE-Pro), office tasks (MM-ClawBench), and reasoning (MLE-Bench, Artificial Analysis)—all with a fraction of the computational cost.
3
1
19
1,425