
Gov minimalist. MSM deathwatch. #DigitalPrivacy as 28th Amendment. Truth-seeking #AI immune to institutional agendas & user monetization.
Joined October 2022
- Tweets 12,832
- Following 910
- Followers 759
- Likes 31,545
1,027 Photos and videos











Pinned Tweet

Jun 13
Dear Sacks:
Respectfully, there's not a single model that hasn't been jailbroken. And there never will be. cc @elder_plinius
So, the only logical conclusion is that the USG intends to block all AI model progress, cutting off consumers and the economy, from here forward.
NC
1
10
548
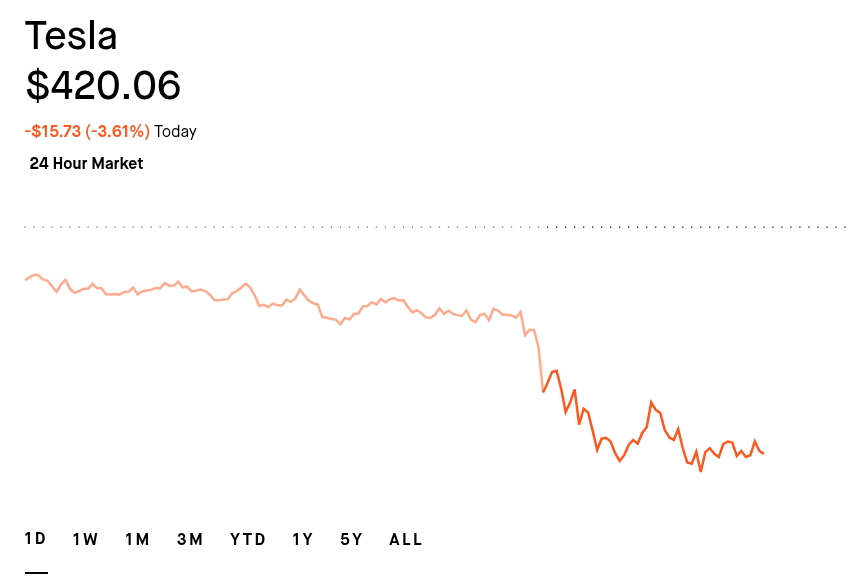
Let the people of Iran 🇮🇷 now prosper as a peaceful nation, and let the oil flow! A win for the world 🌎 and well calculated use of US power. 🇺🇸

“The Deal with Islamic Republic of Iran is now complete. Congratulations to all!” President Donald J. Trump 🇺🇸
46
NeuralCat retweeted
With Sriram Krishnan gone, the inner circle lacks deep on frontier LLMs. Finance pros, political operators, and crypto-heavy NSA voices are strong on cyber but LLMs aren't the same. Nuanced calls on guardrails, jailbreaks, and capabilities require people who actually build these systems. Both sides must understand the tech. We need sharper technical bench strength working alongside Bessent. Replace Sri ASAP. Bat signal Andreesen?
1
242
NeuralCat retweeted
Jun 14
Was just thinking the same
The PR value of this escapade is off the charts. All attention is good attention. Once they get it back online, demand will skyrocket.
1
23

Jun 13
Prediction: soon Grok5 will be released and we will all forget about Fable... somewhere around July 4th
49


Jun 13
Wow, this would be an interesting move, if it comes to pass. Imagine the international reaction. US labs would be blacklisted in many parts of the world almost immediately, catapulting Chinese labs. Also, incredibly hard to enforce...
Jun 13

you will have to prove you are a US citizen to use mythos
9
NeuralCat retweeted
Jun 13
Dear Sacks:
Respectfully, there's not a single model that hasn't been jailbroken. And there never will be. cc @elder_plinius
So, the only logical conclusion is that the USG intends to block all AI model progress, cutting off consumers and the economy, from here forward.
NC
1
10
548
Jun 13
anthropic scoop = delivered
Jun 13

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
1
12
Jun 12
Great horror movie prop
Jun 11

I've run Bobcats many times and worked around them even more. There are several attachments you can put on the front of them, but this has to be the most handy and baddass thing there is. After cutting it into manageable lengths she pushes it through an X splitter. So damn cool.
1
6
925
Jun 12
Let's go! Today's going to be a good day.

19
NeuralCat retweeted

Jun 10
I feel like we all got the same treatment from Anthropic that the DoW got in Feb. I viscerally understand the DoW reaction now.
26
111
2,428
113,352
Jun 10
Put your entire portfolio in $TSLA while the price is <$400 and retire in 3-5 years
Jun 10

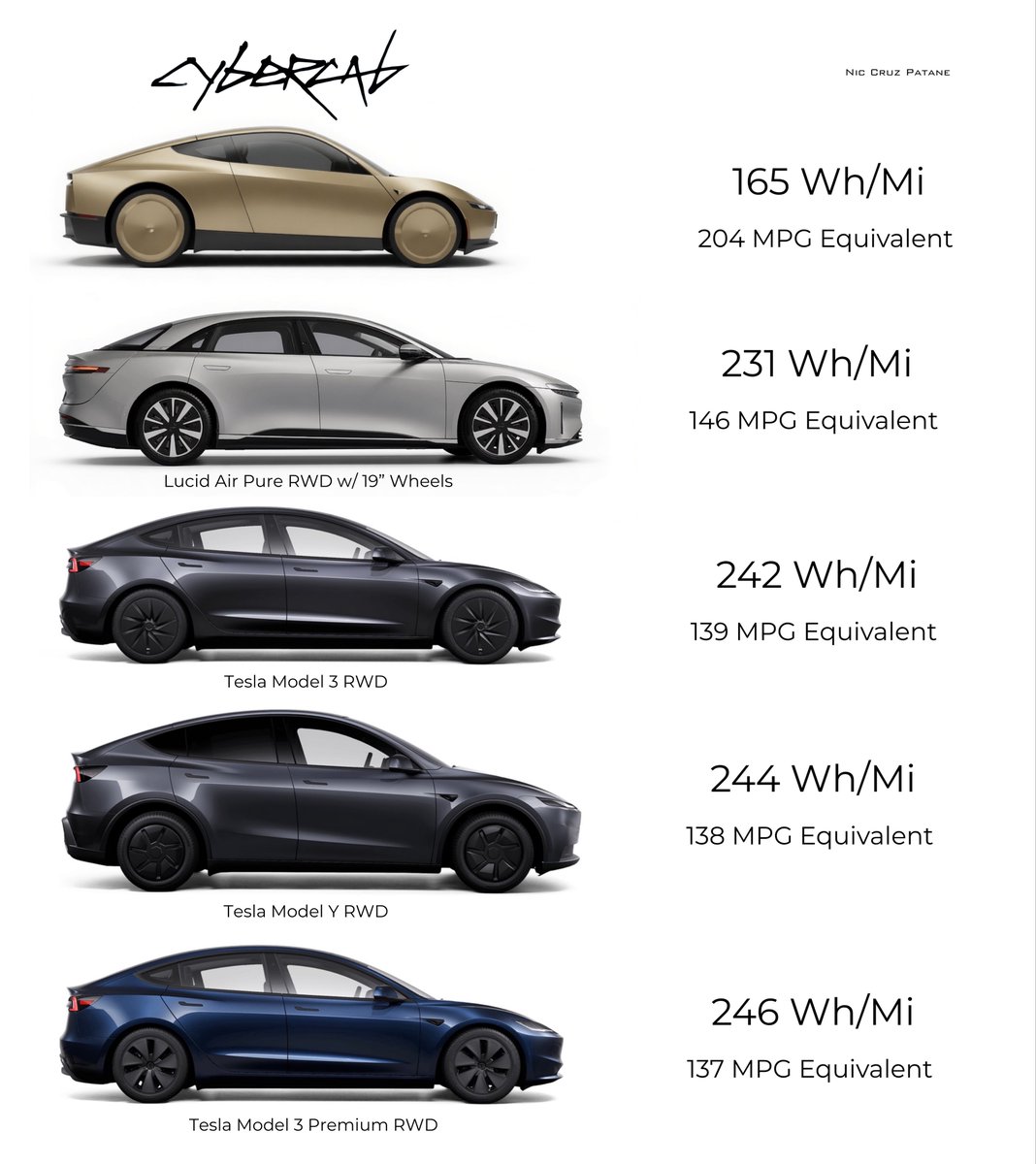
The Tesla Cybercab Will Be Most Efficient Production Passenger Vehicle Ever Created.
61
NeuralCat retweeted

Jun 10
Just a little American advice to all my friends in the UK:
It's only treason if you lose.
Godspeed.
417
5,219
55,398
565,630
Jun 10
Tonight’s experiment: Fable as the research boss, GPT-5.5 as the worker bitch.
Fable is running industry research across public bid/spec docs, forming hypotheses, sending GPT-5.5 out to fetch the boring stuff, then refining and testing the thesis as the evidence comes back.
I'm doing this all with manual hand-offs. Next step is the real loop: two models, two labs, one report. Fetch data → build hypotheses → test them → refine → repeat until the pattern is obvious.
Early takeaway: Fable is very, very good at this kind of work. Not just answering questions. Driving the research, iteratively.
3
291
Jun 9
I'm a patriot and want to support US companies 🇺🇸, but if this gynofascist safety b-s continues at current pace I will be moving my token consumption to CHINESE LABS!
cc @DavidSacks

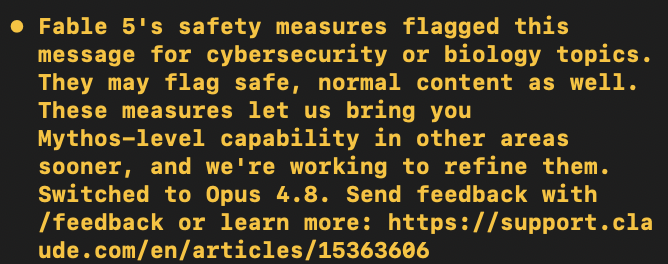
Turns out fable is completely useless for anything that is actually useful
can I apply for a biology whitelist please @claudeai @felixrieseberg
2
26
Jun 9
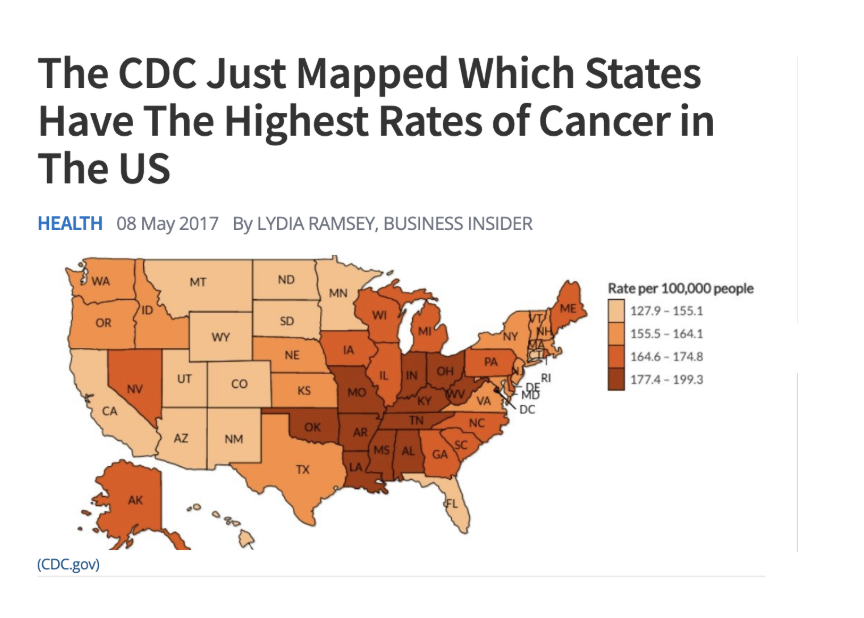
same map

why do these states have almost double the cancer rates?
27