
Half engineer, half philosopher.| research @rumik_ai | Ex-MLE intern @videoversehq and @vedantu_learn
Joined February 2021
- Tweets 240
- Following 407
- Followers 106
- Likes 759
26 Photos and videos











pulsatingGenius retweeted

Someone writing small cheques into American AI labs, doing PR tours about how they “backed the future” probably shouldn’t be the loudest voice lecturing everyone on what India must do after the Fable news.
For those of us actually building models from scratch across modalities, the bottlenecks are not a breaking headline or a geopolitical event. We live them every day, data, compute, talent, inference, distribution, and relentless execution.
You don’t wake up one morning, see a model get pulled down internationally, and suddenly discover the importance of sovereign AI.
At @rumik_ai we’ve always believed in owning our stack and building foundational capabilities ourselves. Soon, we’ll be open-sourcing India’s first expressive TTS model with deep code-switching support across Hindi, Hinglish, and multiple Devanagari languages. Not because it’s fashionable, but because we genuinely believe India can build world-class AI infrastructure and models.
What the ecosystem needs isn’t more hindsight experts chasing engagement after every headline. It needs patient builders, conviction, long-term capital, and VCs who help create enduring AI companies instead of pretending to be the smartest AI researchers on Twitter.
India doesn’t have a talent problem. It has a conviction problem.
Jun 13

Looking for a team of 10-12 cracked researchers & engineers to build a new AI Lab in India.
Funding and compute secured.
DMs open.
2
5
22
3,353
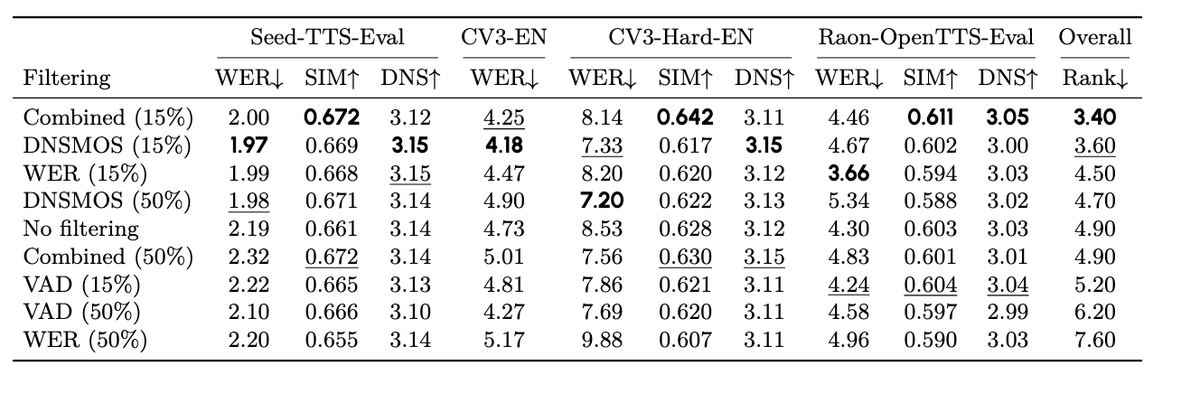
Genuine question : your combined filter weights DNSMOS, WER and SR or VAD ranks equally. But Table 3 shows the SR/VAD signal is your weakest filter (5.20 avg rank vs 3.40 for combined) and filtering harder on it makes things worse (VAD-50% = 6.20).
Why give equal weight to SR?
Isn't Silero VAD unreliable on exactly the wild YouTube-type audio that's most of your pool?
May 27

Raon-OpenTTS paper is finally out! We fully open-sourced 615K hours of TTS data and a 1B model competitive with Qwen3-TTS-1B and Voxtral-TTS-4B. Like DCLM and DataComp, our work closed the gap towards SOTA closed-data models in TTS, which will help push the TTS community forward!

1
1
16
2,015
wrote a short blog on a pattern i keep seeing again and again. heres why i think it happens

8
539

most people assume muP = safe learning rate transfer. true, but historically only across model width and depth.
when you change your batch size or total token duration, standard heuristics get you close, but they aren't exact.
a new paper by Bruno et. al completely changes this.
6
10
25
2,559
Once you know the definition of expectation and linearity of expectation and Jensen’s inequality a lot of probability theory starts unfolding from just those tools.
5
276
> Diffusion models don’t use Gaussian noise because “noise is Gaussian”.
> They use Gaussian noise because Gaussians have ridiculously nice mathematical properties.
Sum of Gaussians → Gaussian
Affine transform of Gaussian → Gaussian
KL between Gaussians → closed form
> Without these properties many diffusion derivations become much uglier.
Starting to realize that half of modern ML is just exploiting convenient math.
1
6
225


May 12
A probability distribution describes a state of knowledge, not a state of the world.
A coin flip is deterministic. Given the angular velocity, air resistance, surface elasticity, and initial orientation, the outcome is fixed.
We say P(heads) = 0.5 because we don't have those variables. Probability lives in us, not in the coin.
This sharpens Shannon's theorem. "You can't compress below the entropy of the data" isn't a claim about irreducible randomness in the world. It's a claim about irreducibility given the variables you've chosen to condition on. Different context, different floor. Add variables, floor drops. In the limit of full physical context, the floor is zero.
A language model isn't fighting some fundamental noise. It's working against a floor defined by its own context window. Longer context, richer modalities, world knowledge each lowers the floor by exposing more of the variables that made the next token "uncertain" in the first place.
Entropy isn't a property of the world. It's a property of the question you're asking.
2
9
330
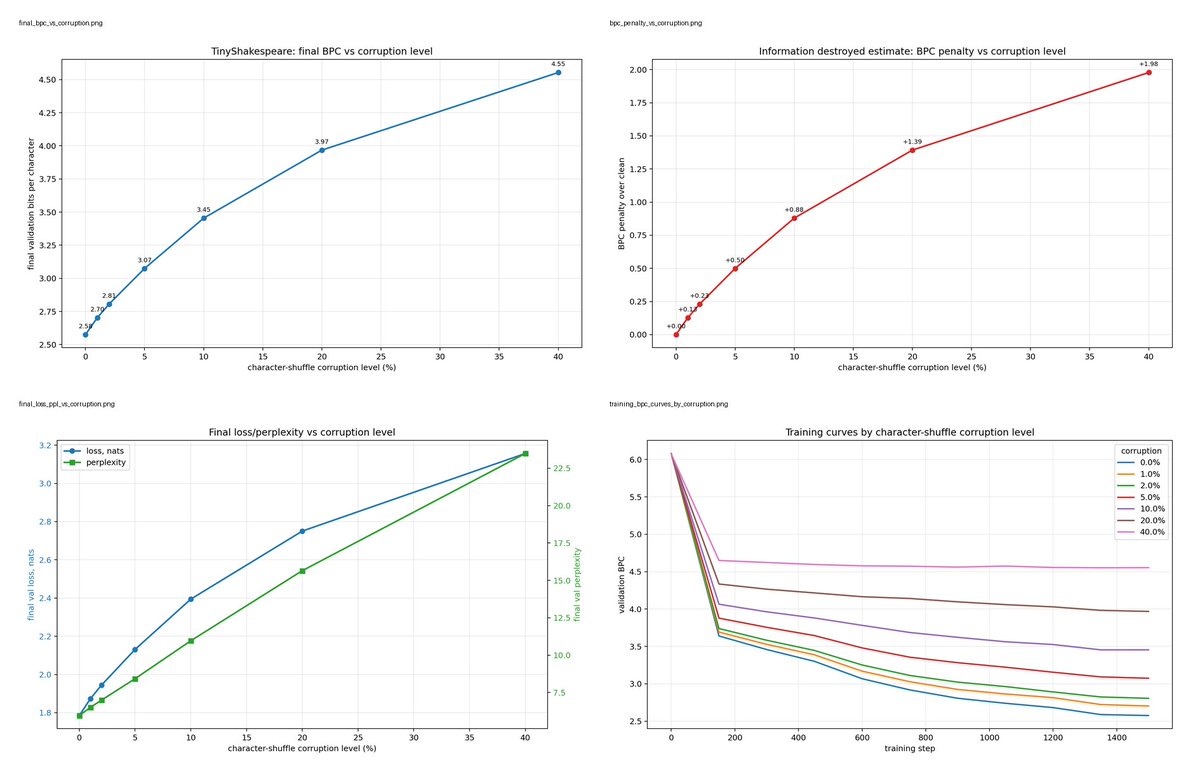
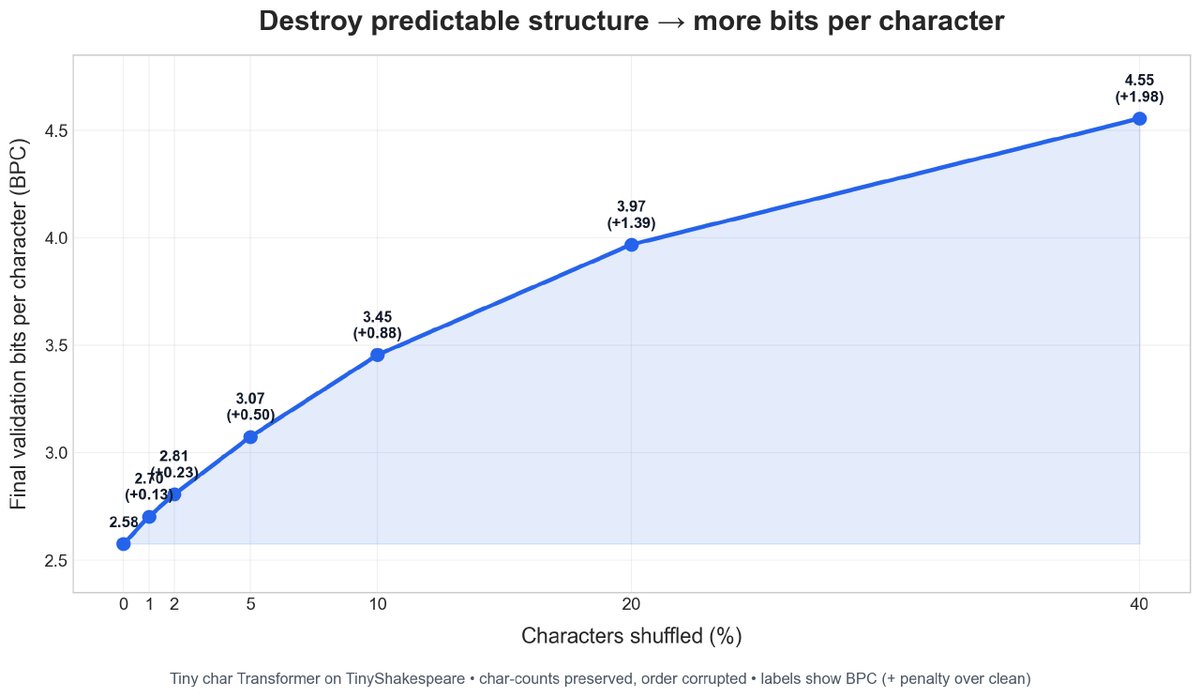
I ran a small experiment to make information theory feel less abstract.I trained a tiny character-level Transformer on TinyShakespeare, then corrupted the text by randomly shuffling different percentages of character positions:
0%, 1%, 2%, 5%, 10%, 20%, 40%
The model tracks cross-entropy loss, perplexity, and bits-per-character. Since this is char-level, BPC is just:
loss / ln(2)
At initialization, the vocab size was 65, so a clueless model should assign about 1/65 probability to each next character. That means initial loss should be:
-ln(1/65) = ln(65) ≈ 4.17 nats
Observed initial loss was ~4.21 nats, so the model was behaving like a near-uniform predictor before training.
After training, final BPC rose with corruption:
0%: 2.58
1%: 2.70
2%: 2.81
5%: 3.07
10%: 3.45
20%: 3.97
40%: 4.55
> More corruption destroys predictable structure, so the model needs more bits per character to model the text.
> That last part is what made the Shannon idea click for me. Information content is not the same thing as human meaning. By shuffling characters, I destroyed meaning in the normal sense. The text became worse, less readable, less Shakespeare.
But to the model, it also became more surprising. The local patterns were damaged, so it needed more bits per character to encode/predict the sequence.
Meaning went down.
Uncertainty went up.
Bit cost went up.
That distinction finally felt concrete.
2
7
338
> cross-entropy loss is a compression rate. not metaphorically. literally.
> kraft's inequality says every prefix free code is secretly a probability distribution, and every distribution is secretly a code.
> the map is codeword length = -log₂(p)
> minimizing -log p of the next token is minimizing a codeword length.
> so an LM at L nats/token = a compressor at L/ln(2) bits/token
> not an analogy. an equality
2
12
607
I implemented this @karpathy LLM-wiki idea with OpenClaw, and the conclusion is: OpenClaw fits this pattern really well if you treat the agent as the wiki maintainer, not just a chatbot.
The basic mapping is:
- raw sources= papers / links / notes / PDFs
- wiki = the maintained markdown knowledge base
- OpenClaw agent= the thing that reads sources, updates pages, cross-links concepts, answers from the wiki, and keeps it healthy over time
So chat becomes the control surface, but the wiki becomes the memory. (1/12)
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1
1
11
1,075
After that, I designed the heartbeat / cron style maintenance loop. The morning maintenance logic should be:
- read the global wiki registry
- for each registered wiki:read local AGENTS.md
- inspect queue if present
- process pending ingest items
- update logs/history
- run that wiki’s own verification step
(10/n)
1
3
142
The last practical decision was about the chat surface itself. Even though a lot of people use OpenClaw through Telegram, I think Discord is better for this workflow.
Why:
- one channel/thread per wiki
- cleaner context separation
- easier for OpenClaw to keep per-wiki context straight
- easier for me to treat each wiki like its own maintained workspace
- overall much more ordered when multiple wikis are evolving in parallel
(n/n)
4
138