
mix of engineering and research | building voice @rumik_ai
Joined August 2023
- Tweets 91
- Following 150
- Followers 68
- Likes 402
13 Photos and videos











nullHawk retweeted

Someone writing small cheques into American AI labs, doing PR tours about how they “backed the future” probably shouldn’t be the loudest voice lecturing everyone on what India must do after the Fable news.
For those of us actually building models from scratch across modalities, the bottlenecks are not a breaking headline or a geopolitical event. We live them every day, data, compute, talent, inference, distribution, and relentless execution.
You don’t wake up one morning, see a model get pulled down internationally, and suddenly discover the importance of sovereign AI.
At @rumik_ai we’ve always believed in owning our stack and building foundational capabilities ourselves. Soon, we’ll be open-sourcing India’s first expressive TTS model with deep code-switching support across Hindi, Hinglish, and multiple Devanagari languages. Not because it’s fashionable, but because we genuinely believe India can build world-class AI infrastructure and models.
What the ecosystem needs isn’t more hindsight experts chasing engagement after every headline. It needs patient builders, conviction, long-term capital, and VCs who help create enduring AI companies instead of pretending to be the smartest AI researchers on Twitter.
India doesn’t have a talent problem. It has a conviction problem.
Jun 13

Looking for a team of 10-12 cracked researchers & engineers to build a new AI Lab in India.
Funding and compute secured.
DMs open.
2
3
16
2,045

17h
nice read... definitely neural codecs have their advantage for generation.

1
69
nullHawk retweeted

Jun 8
i've been observing mixed results for non transformer backbones tbh (might be a skill issue) but another angle to reason about training behavior that i found in this paper was to observe the singular value spectrum of the momentum buffers during training.

Jun 7

I took aside some time this week to look into @jxbz 's muon optimiser as well as code it up from scratch (the repo is great, but i wanted to build my intuition) and wow the results were impressive!
it got me a 4x reduction in mse for a model that has no transformer architecture and is more of a classical CNN architecture.
credits to @jbhuang0604 's video on the optimiser outside of the awesome blogs deriving it from first principles as well :>

3
2
11
3,640
Jun 2
checkout this thread!

most people assume muP = safe learning rate transfer. true, but historically only across model width and depth.
when you change your batch size or total token duration, standard heuristics get you close, but they aren't exact.
a new paper by Bruno et. al completely changes this.
1
83

most people assume muP = safe learning rate transfer. true, but historically only across model width and depth.
when you change your batch size or total token duration, standard heuristics get you close, but they aren't exact.
a new paper by Bruno et. al completely changes this.
5
10
24
2,529
a few months ago we were just building.
today, @AWSCloudIndia invited rumik to the startup summit as one of the top 5 startups.
wild. the best is still ahead.
3
11
37
1,426
a conversation with @thepushkarp from @AI_NURIX . his thoughts,his words and all things rumik
4
24
1,574
May 20
apparantly calculating API pricing is more complex than building the whole infra for inference🥲
8
89
May 14
this is just a jist of what we have been working on!
May 14

an audio model that can switch languages, accents, tone, gender, emotions in a single instance
this is silk mulberry 1.5 our most cost efficient model!
by @rumik_ai research lab
1
4
237
nullHawk retweeted
May 6
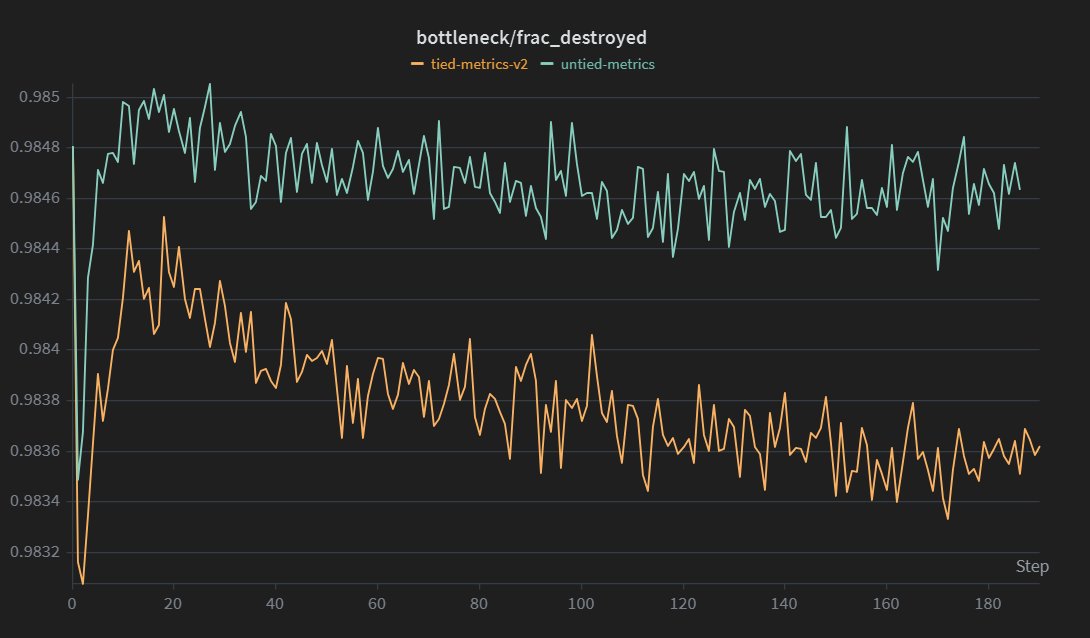
i've been running a lot of experiments recently related to similar ideas, and can confirm that gradient destruction is real. although there is a lot of room for experimentation here on "how much of the destroyed norm is actually good training signal"
x.com/prompt_Tunes/status/20…
Mar 30

if the problem is that the gradient projection destroys orthogonal information because the rows of W (the LM head matrix) overlap and occupy a narrow subspace, what if we mathematically force W to spread out?
we know that if the rows of W are orthogonal to each other, the projection W.W_t acts closer to the identity matrix on its principal subspace. if we can just find a way to maximize the "volume" of the subspace that W spans so that less gradient norm falls into its null space.
can we not just add a simple regularization term to cross entropy loss:
L_reg = lambda * ||WW_t - I||^2
3
9
703

nullHawk retweeted

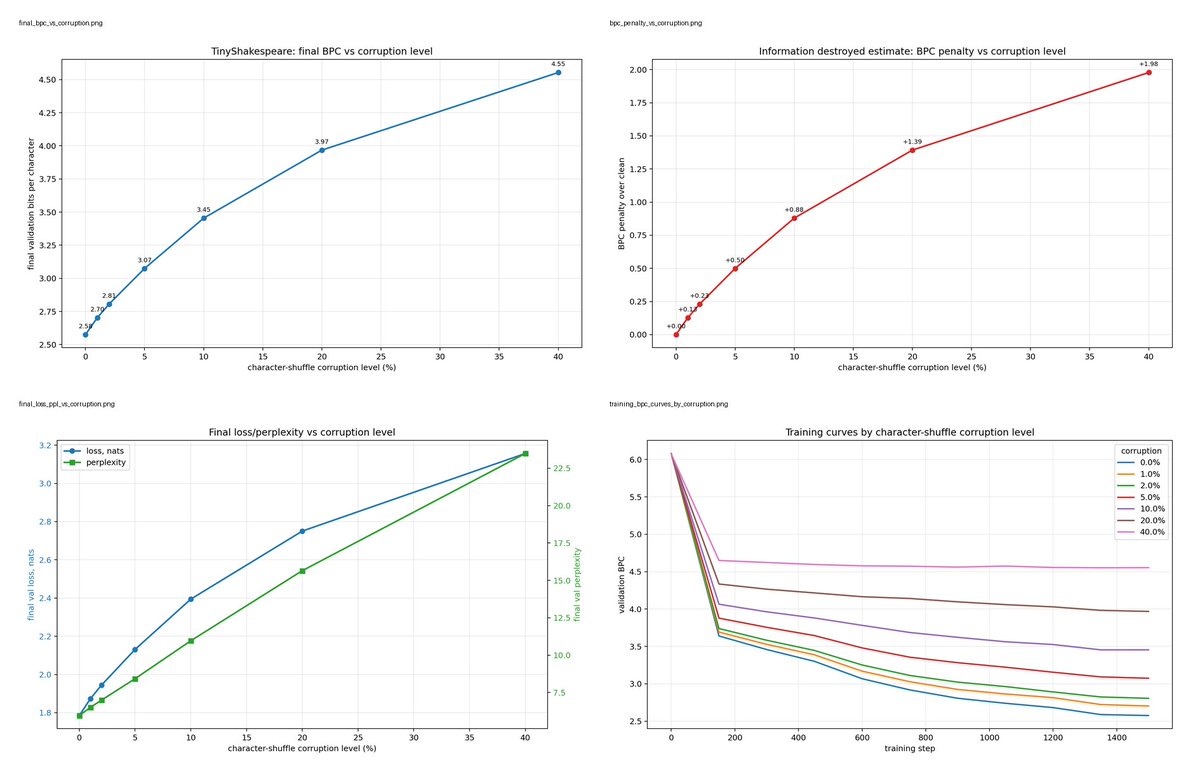
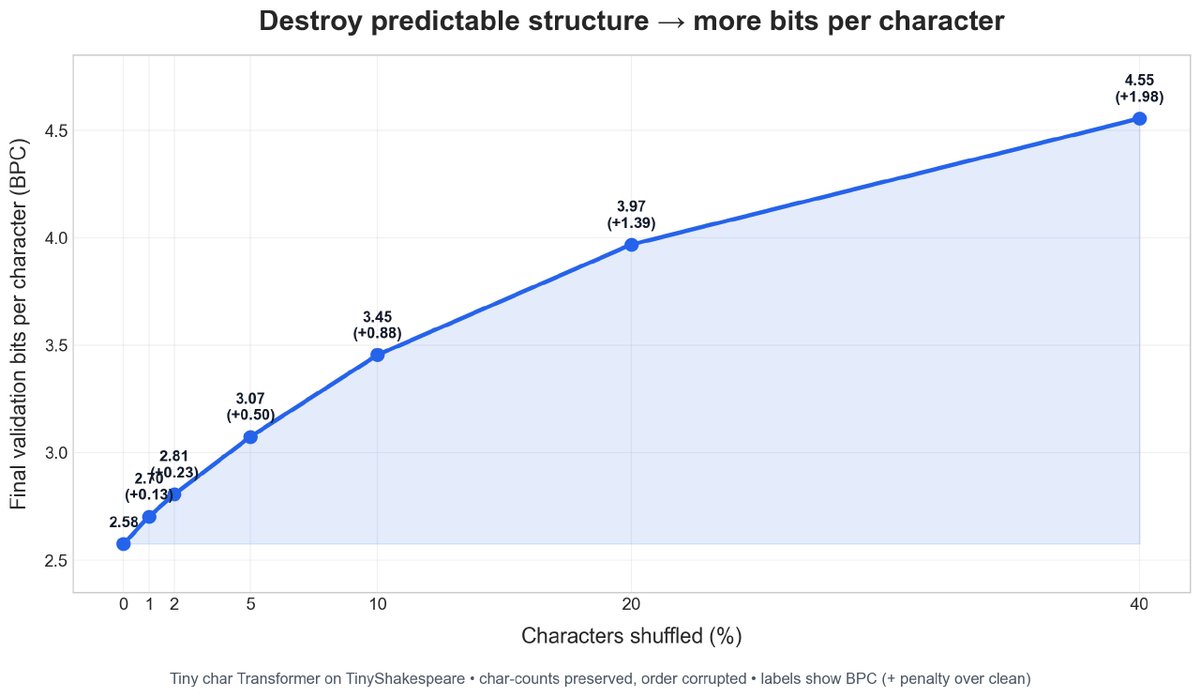
I ran a small experiment to make information theory feel less abstract.I trained a tiny character-level Transformer on TinyShakespeare, then corrupted the text by randomly shuffling different percentages of character positions:
0%, 1%, 2%, 5%, 10%, 20%, 40%
The model tracks cross-entropy loss, perplexity, and bits-per-character. Since this is char-level, BPC is just:
loss / ln(2)
At initialization, the vocab size was 65, so a clueless model should assign about 1/65 probability to each next character. That means initial loss should be:
-ln(1/65) = ln(65) ≈ 4.17 nats
Observed initial loss was ~4.21 nats, so the model was behaving like a near-uniform predictor before training.
After training, final BPC rose with corruption:
0%: 2.58
1%: 2.70
2%: 2.81
5%: 3.07
10%: 3.45
20%: 3.97
40%: 4.55
> More corruption destroys predictable structure, so the model needs more bits per character to model the text.
> That last part is what made the Shannon idea click for me. Information content is not the same thing as human meaning. By shuffling characters, I destroyed meaning in the normal sense. The text became worse, less readable, less Shakespeare.
But to the model, it also became more surprising. The local patterns were damaged, so it needed more bits per character to encode/predict the sequence.
Meaning went down.
Uncertainty went up.
Bit cost went up.
That distinction finally felt concrete.
2
7
336
nullHawk retweeted
> cross-entropy loss is a compression rate. not metaphorically. literally.
> kraft's inequality says every prefix free code is secretly a probability distribution, and every distribution is secretly a code.
> the map is codeword length = -log₂(p)
> minimizing -log p of the next token is minimizing a codeword length.
> so an LM at L nats/token = a compressor at L/ln(2) bits/token
> not an analogy. an equality
2
12
606
Apr 30
summerized what i learn't about VAE and the nuances like:
- why reparameterization beats REINFORCE
- why we predict log-variance, not variance
- the hole problem
- posterior collapse
- the link to probabilistic PCA
nullhawk.github.io/deep-lear…
2
8
310
Apr 30
ig this increases the rate of self-correction events because it commits to speech before full reasoning is complete.
Apr 29

We’re excited to introduce KAME: Tandem Architecture for Enhancing Knowledge in Real-Time Speech-to-Speech Conversational AI, accepted at #ICASSP2026! 🐢
Blog pub.sakana.ai/kame/
Paper arxiv.org/abs/2510.02327
Can a speech AI think deeply without pausing to process?
In real conversation, we don’t wait until we’ve fully worked out what we want to say—we start talking, and our thoughts catch up as the sentence unfolds.
Fast speech-to-speech models achieve this, but their reasoning tends to stay shallow. Cascaded pipelines that route through a knowledgeable LLM are smarter, but the added latency breaks the flow—they fall back to "think, then speak."
In our new paper, we propose a way to break this trade-off. We call it KAME (Turtle in Japanese).
A speech-to-speech model handles the fast response loop and starts replying immediately. In parallel, a backend LLM runs asynchronously, generating response candidates that are continuously injected as "oracle" signals in real time.
This shifts the AI paradigm from "think, then speak" to "speak while thinking."
The backend LLM is completely swappable. You can plug in GPT-4.1, Claude Opus, or Gemini 2.5 Flash depending on the task without changing the frontend. In our experiments, Claude tended to score higher on reasoning, while GPT did better on humanities questions.
Try the model yourself here: huggingface.co/SakanaAI/kame
1
1
274
nullHawk retweeted
Apr 23
log softmax over a matrix increases the final rank of the matrix by at max 1.
rank(log(softmax(X))) <= rank(X) 1

2
10
619