
21 Photos and videos














Pinned Tweet

Feb 11
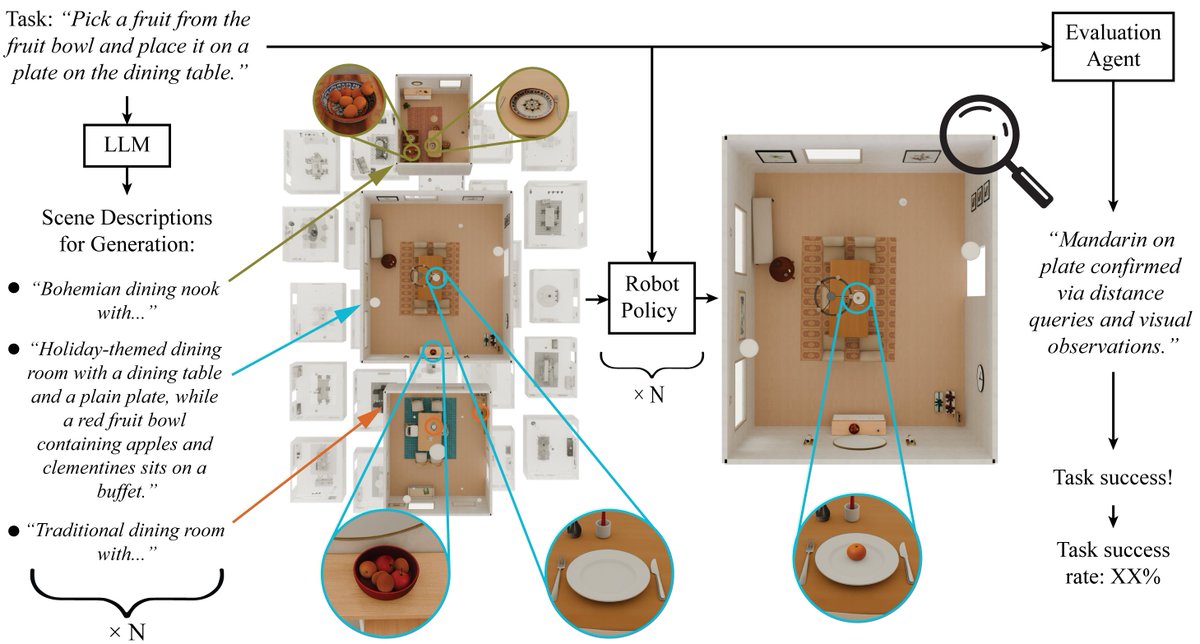
Meet SceneSmith: An agentic system that generates entire simulation-ready environments from a single text prompt.
VLM agents collaborate to build scenes with dozens of objects per room, articulated furniture, and full physics properties.
We believe environment generation is no longer the bottleneck for scalable robot training and evaluation in simulation.
Website: scenesmith.github.io/
👇🧵(1/8)
18
81
569
74,377
SceneSmith is now an ICML 2026 Spotlight (top 2.2%) and will be presented in Korea this summer!
Meet SceneSmith: an agentic system that generates simulation-ready indoor environments from a single text prompt.
New in the camera-ready: zero-shot rollouts of an externally trained robot policy inside generated SceneSmith scenes.
👇 (1/3)
6
18
161
11,579
The camera-ready adds a new page on qualitative robot simulation demonstrations, plus additional baseline-control experiments, and a detailed limitations/failure analysis.
Project: scenesmith.github.io/
Paper (updated): arxiv.org/abs/2602.09153
Code: github.com/nepfaff/scenesmit…
Joint work with @cohnthomas43, @ZakharovSergeyN, @RickCory21, @RussTedrake
(3/3)
1
1
6
646
And one more of our teleop demos (head and external camera view) in the generated scenes. The project site has more zero-shot videos, more teleop videos, and videos of a mobile iiwa policy being evaluated in our scenes.
323
Nicholas Pfaff retweeted

Apr 29
Releasing RecGen: a collaboration between @ToyotaResearch, @toyota_europe, and @UvA_Amsterdam tackling a core 3D vision challenge: reconstructing complete multi-object scenes (parts, poses, textures, even occluded geometry) from just 1 to a few RGB-D views.
Trained purely on synthetic data, RecGen achieves SOTA on real-world robotics and 6D pose benchmarks, handling occlusions, symmetry, and complex interactions.
A step toward scalable, high-fidelity digital twins for robotics, and better evaluation and training of generalist policies.
reconstruction-by-generation…
2
35
220
26,907
Nicholas Pfaff retweeted

Apr 23
Also, if you’re wondering how we generated all these cool videos from the Drake sim, check out @NicholasEPfaff’s repo github.com/nepfaff/drake-ble… as a starting point 👀
Apr 23

A few interesting rollouts from the Foundry-QwenVLA-2.5B multi-task model on seen tasks in sim – a 🧵. I really like behaviors that involve non-prehensile manipulation, like the little nudges in StoreCerealBoxUnderShelf.
6
29
2,767
Nicholas Pfaff retweeted

Apr 22
Releasing VLA Foundry: an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. End-to-end control from language pretraining to action-expert fine-tuning — no more stitching together incompatible repos.
10
76
491
74,701
Nicholas Pfaff retweeted

Mar 4
🧵1/
🤔New paper: Do LLMs Benefit from Their Own Words?
In multi-turn chats, models are typically given their own past responses as context.
But do their own words always help… or can they sometimes be a distraction?

6
34
172
18,428
Nicholas Pfaff retweeted

Feb 12
This is awesome work! Curious—any plans to integrate SceneSmith-like agentic scene generation into MolmoSpaces?
It feels like a natural combo: MolmoSpaces benchmark SceneSmith prompt-to-sim scenes = infinite evaluation distribution.
scenesmith.github.io/
1
1
4
1,049

Nicholas Pfaff retweeted

Feb 12
Agentic Generation of Simulation-Ready Indoor Scenes and Robot Test Environments.
📍 Paper AND Code:
Instead of hand-building scenes in simulation, you write one prompt.
SceneSmith builds the world for you.
> Room layout.
> Furniture.
> Wall and ceiling objects.
> Small movable items.
Each stage is handled by a team of VLM agents: one proposes, one critiques, one coordinates. The result is not just pretty scenes, but physics-ready environments.
Every object:
•Metric scale
•Collision geometry
•Estimated mass, inertia, friction
•<2% object collisions
•96% stable under gravity
And it exports directly to MJX, USD, SDFormat.
If you train or evaluate robot policies, environment creation is usually the bottleneck. SceneSmith turns it into an on-demand layer. You can generate dozens of diverse scenes per task and automatically evaluate policies across them, with 99.7% agreement to human labels.
That means:
•More robust policies
•Faster benchmarking
•No hand-written success predicates
205 participants preferred SceneSmith scenes 92% of the time for realism and 91% for prompt faithfulness.
Environment generation is no longer the slow part of robot research.
If you work on sim2real, policy scaling, or automated evaluation, this is worth bookmarking and sharing with your team.
📍GitHub: scenesmith.github.io/
Paper: arxiv.org/abs/2602.09153
Code: github.com/nepfaff/scenesmit…
—-
Weekly robotics and AI insights.
Subscribe free: 22astronauts.com
5
1
44
3,888
Nicholas Pfaff retweeted

Feb 11
I've been saying for years that the biggest challenge for simulation in robotics is not actually the physics engine (although you do have to get that right). The real challenge is capturing the *diversity* of the real world. There was no doubt that generative AI had the potential to change that, but it's still amazing to see it take shape.
Watching Nick's incredibly fast progress has convinced me that content generation might not actually be a bottleneck anymore. This is a beautiful combination of hardened tools for e.g. low-level mesh processing with the latest tools for generative asset creation, wrapped in a powerful agentic workflow. Please do give it a try and share your feedback.
Feb 11

Meet SceneSmith: An agentic system that generates entire simulation-ready environments from a single text prompt.
VLM agents collaborate to build scenes with dozens of objects per room, articulated furniture, and full physics properties.
We believe environment generation is no longer the bottleneck for scalable robot training and evaluation in simulation.
Website: scenesmith.github.io/
👇🧵(1/8)
12
33
325
38,091
Nicholas Pfaff retweeted

Feb 11
Amazing, I used to think about such projects during grad school but the technical complexity is super high for such a plug and play level simulator. Seems like an amazing piece of work. Will try for sure later this week.
Feb 11
SceneSmith exports to any major robotics simulator (MJX, USD, SDFormat). Here is a Rainbow RBY1 being teleoperated in our scenes.
Opening cabinets, grasping mugs, navigating rooms. Third-person view (left) robot head camera (right).
🧵(7/8)
1
7
905

We can now generate realistic and physically interactable scenes with just a text prompt!
I'm super excited to see how this tool will shape the future of sim-based development and evaluation
Feb 11
Meet SceneSmith: An agentic system that generates entire simulation-ready environments from a single text prompt.
VLM agents collaborate to build scenes with dozens of objects per room, articulated furniture, and full physics properties.
We believe environment generation is no longer the bottleneck for scalable robot training and evaluation in simulation.
Website: scenesmith.github.io/
👇🧵(1/8)
2
7
570
Nicholas Pfaff retweeted
Feb 11
Super excited to share our latest work on 3D scene generation! SceneSmith turns natural language prompts into richly furnished, simulation-ready indoor environments—enabling robot training and evaluation at scale.
Huge kudos to @NicholasEPfaff and team for the tremendous effort!
Feb 11
Meet SceneSmith: An agentic system that generates entire simulation-ready environments from a single text prompt.
VLM agents collaborate to build scenes with dozens of objects per room, articulated furniture, and full physics properties.
We believe environment generation is no longer the bottleneck for scalable robot training and evaluation in simulation.
Website: scenesmith.github.io/
👇🧵(1/8)
2
4
1,004
Nicholas Pfaff retweeted

Feb 11
We all know that being able to generate a new world at the touch of a button is nice. But the fact that you can just directly simulate these scenes and everything works is a huge boon for robotics. I can personally vouch for the quality and realism of the resulting simulations.
Feb 11
Meet SceneSmith: An agentic system that generates entire simulation-ready environments from a single text prompt.
VLM agents collaborate to build scenes with dozens of objects per room, articulated furniture, and full physics properties.
We believe environment generation is no longer the bottleneck for scalable robot training and evaluation in simulation.
Website: scenesmith.github.io/
👇🧵(1/8)
3
24
3,898
Feb 11
Meet SceneSmith: An agentic system that generates entire simulation-ready environments from a single text prompt.
VLM agents collaborate to build scenes with dozens of objects per room, articulated furniture, and full physics properties.
We believe environment generation is no longer the bottleneck for scalable robot training and evaluation in simulation.
Website: scenesmith.github.io/
👇🧵(1/8)
18
81
569
74,377
Feb 11
SceneSmith exports to any major robotics simulator (MJX, USD, SDFormat). Here is a Rainbow RBY1 being teleoperated in our scenes.
Opening cabinets, grasping mugs, navigating rooms. Third-person view (left) robot head camera (right).
🧵(7/8)
1
17
1,954
Feb 11
This is an amazing collaboration with @cohnthomas43, @ZakharovSergeyN, @RickCory21, @RussTedrake
📄 arxiv.org/abs/2602.09153
💻 scenesmith.github.io/
🔧 github.com/nepfaff/scenesmit…
Explore our interactive 3D scenes on our website or download them from Hugging Face!
🧵(8/8)
2
2
30
1,679