
Joined February 2020
- Tweets 1,039
- Following 1,402
- Followers 394
- Likes 3,962
176 Photos and videos












Vision retweeted

Jun 13
Chinese teams that already distilled Fable 5.
33
87
2,688
193,619

Jun 10
How long until everyone realises DeepSeek v4 Flash is the only model you need?
1
19
Jun 1
Build Model-Agnostic Architecture

Vibe-coding 102
Personal AI infrastructure and tooling, how I do everything I do.
Enjoy (:
1
18
Vision retweeted

Human in the loop 🤖
Made in @ComfyUI with a laundry list of tools: @ltx_model 2.3 @thesystms FLW LoRA, @Alibaba_Wan 2.2 I2V T2V, Florence2, @Meta Sapiens2, @OpenAI GPT Image 2.0, @suno , @AdobeAE
55
134
1,828
135,820

Behind the MiMo API Price Reduction:
The deepest price cut, up to 99%, is for Input (Cache Hit). The core reason is our inference framework now supports hierarchical KV cache optimization for SWA. Production inference engine tests show this optimization increases cached token capacity by 5x, equivalent to an 80% reduction in caching costs. Combined with Cache Read Overlap among multiple Full Attention modules in the Hybrid model, actual costs are further reduced.
Prices for Input (Cache Miss) and Output are also reduced by 60%-80%. This mainly benefits from the extreme 1:7 Full:SWA sparsity ratio brought by the model architecture (the prefill compute of the 70-layer MiMo-V2.5-Pro roughly equals a 10-layer GQA model). This kept our original inference costs well below the industry average, naturally leaving a 2x-3x profit margin in pricing. This price adjustment simply reflects our decision to pass these structural cost efficiencies directly to developers.
Operating at these newly reduced API prices, our production inference engine is running at near full capacity, and we can still essentially break even. We previously advised LLM companies not to "blindly cut prices" precisely because very few model architectures and inference optimizations can keep API costs from running at a loss. If more architectures that save compute and KV cache emerge, along with better inference Infra to drive down API costs, this will form an excellent virtuous cycle in the industry.
More crucially, affordable, high-performance model APIs will drive real, sustained, and at-scale inference demand. This upstream demand pulls forward the development of the entire AI infrastructure chain—including chips, servers, optical transceivers, PCBs, liquid cooling, power, energy storage, and data centers—serving as a strategic fulcrum for a systemic revaluation of AI hardware. In the long run, this injects more affordable and accessible compute into both training and inference pipelines, accelerating the parallel evolution of global AGI across multiple regions and technical routes.
For more technical details, we will release a detailed Blog post later.
155
186
1,742
187,872
Vision retweeted

May 27
Open Source Must Win
- The Pope

May 26

Today, among the goods that are universally intended for everyone, we must also include new forms of property, such as patents, algorithms, digital platforms, technological infrastructure and data. In a context where the wealth of nations depends increasingly on knowledge and technology, when these goods remain concentrated in the hands of a few, without adequate forms of sharing and access, a new imbalance is created that contradicts the universal destination of goods. In turn, it widens the gap between the included and the excluded, between those who can participate in the digital revolution and those who remain on the margins. #MagnificaHumanitas
62
231
1,714
90,417
May 25
How I talk to Hermes Agent

21



559
596
5,539
3,967,078
May 12
Your context is your moat, don’t lease it.

i hear it often. what's the point of local AI when cloud models are so far ahead. and yes, frontier closed-source models are ahead. that's true. before you assume i'm trying to convince you otherwise, hold the question one minute.
if you handle client financials, do you want that data sitting in anthropic's next training set. if you have a private case open and need a second brain to think through it, are you comfortable hitting openai api with the details. if you're working on something new that could matter, do you want that thinking captured upstream before you ship it.
some tasks stay between me and my machine. not everything has to be cloud-driven.
i don't write what i think you might like. i write what's already happening at the frontier of this age of acceleration. and there is no way i'm comfortable reasoning on top of my private data with frontier corporate models. i don't want my data to be the next training dataset.
what i want is to mine frontier intelligence instead of being mined.
that can happen if you orchestrate well, organize the work so frontier models solve the actual problem without knowing the core context. a 27b dense on a single 3090 is intelligence enough to play orchestrator, hold your context, route the public-facing problem out, integrate what comes back.
nothing unveils until you actually try running this. words on screen don't load weights into vram.
flip the lens. start running local ai. you will find things, for the first time, where every word stays between you and your machine. that is what independent thinking actually feels like.
your context is your moat. don't lease it.
35
May 12
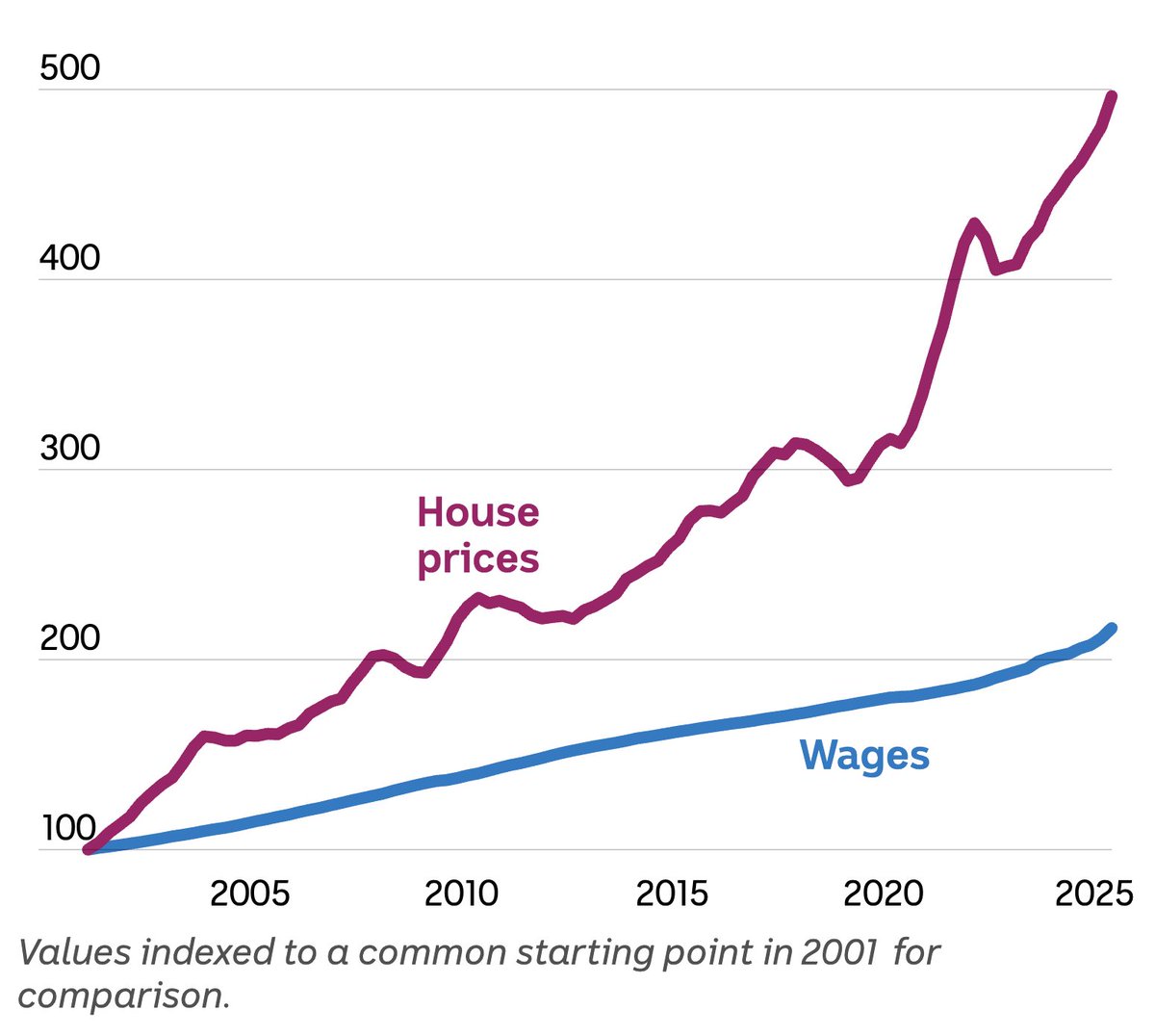
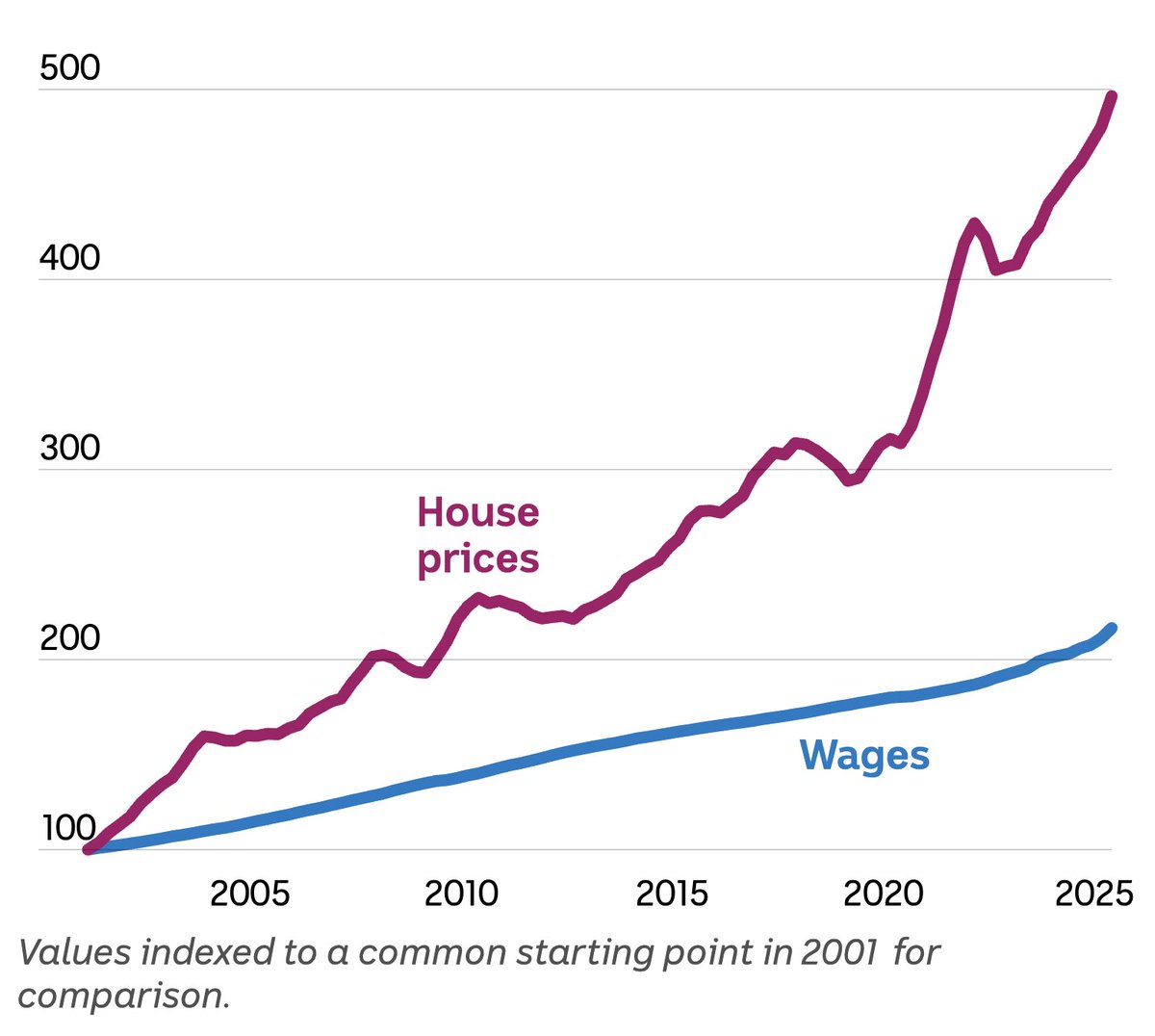
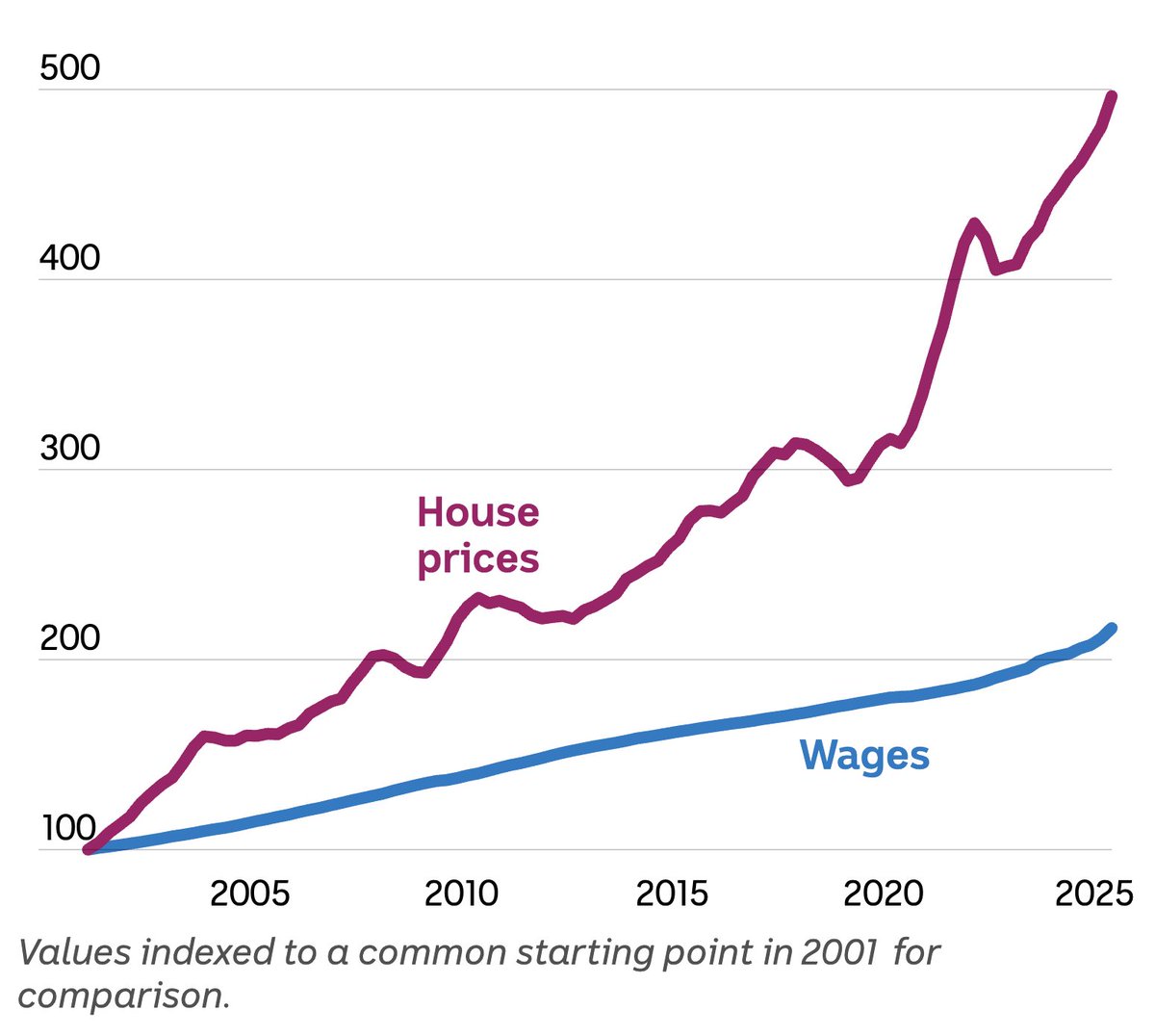
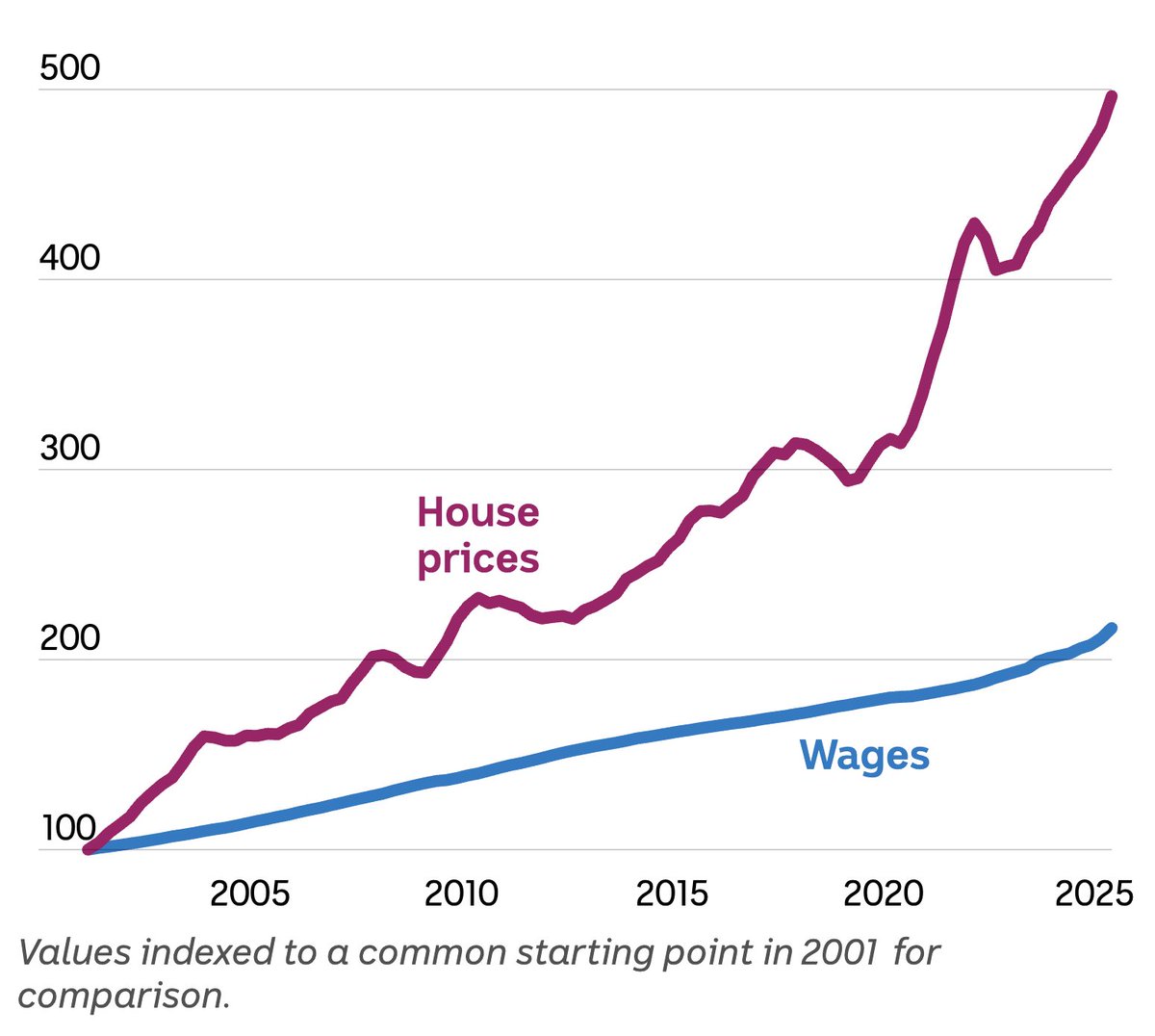
If you look at this chart and think it's a good thing, you're sub-70 IQ.
#AusPol #HousingCrisis #NegativeGearing #Budget2026
3
147
May 12
Aussies when they can no longer spend $47 at Bunnings on paint & handles and magically add $200k to the property value
1
22
Vision retweeted

May 12
I’ve always believed the No.1 application of AI should be to improve human health.
That work started with AlphaFold, and now at @IsomorphicLabs with the mission to reimagine drug discovery and one day solve all disease!
We are turbocharging that goal with $2.1B in new funding.
731
2,645
21,267
3,152,914
May 11
LOCK IN NOW
Hermes Agent
May 11

Qwen 3.6 Plus by @Alibaba_Qwen is now FREE for a limited time on Nous Portal!
Nous Portal is one easy subscription that gives you access to 300 models, exclusive discounts, and bundles your tokens and paid tools together for hassle-free setup and simple billing.
1
30
May 7
Love to see it 🐨🇦🇺
May 7

Excited (and jet lagged) to officially be launching @ElevenLabs Australia 🇦🇺 & New Zealand 🇳🇿
750k users across the region with lots of enterprises already using our tech, including enterprises that range from Australia Post to @Xero, @EmploymentHero or Greenstone Financial Services.
Let's go ANZ!!

9
Apr 26
Build Model Agnostic Architecture
Apr 26

I'm on Claude Max 20x. Unlimited frontier access.
I'm planning with Qwen 27B and Gemma 9B instead.
One evening to set up.
Code reviews. Refactors. Doc summaries. All local.
Most people think local models are for engineers.
They're not.
Frontier for everything isn't smart.
It's leasing from people who can change the terms.
If your AI only works from one lab, that's not a workflow.
It's a full-on dependency.
10
Apr 25
Last name checks out
Apr 24

Everyone is slowly coming to this realization, and I assure you, no one is running multitudes of agents overnight. No one that is doing anything of substance at least.
There _are_ people pretending to be scientists, or fully caught up in their drug infused AI overdose, that think their slop machines are changing the world. They're not tho, and they're just wasting a bunch of money and compute to create a lot of LoC that will just get thrown away.
The state of the art is still "can we even one shot a production quality patch that we wont regret later", and its rarer than you'd expect based on discourse.
14