
Gambling industry entrepreneur, investor, advisor. GP at Acies Investments, Operating Advisor at Arctos Sports Partners, Partner Emeritus at Eilers & Krejcik.
Joined December 2011
- Tweets 27,845
- Following 375
- Followers 13,186
- Likes 7,864
947 Photos and videos

















During outgoing South Carolina Gov. Henry McMaster's nearly 10-year tenure, legal sports betting or gambling legislation has repeatedly died in the state legislature.
McMaster, who has reached his term limit and won’t be on the November ballot, staunchly opposes any form of legal gambling.
With the state primary set for Tuesday, gambling companies will be watching closely.
None of the 11 candidates have publicly said they favor legal sports betting — or any other kind of gambling — but at least a handful are not vehemently opposed, which would open a window for change.
2
1
1,294
Chris Grove retweeted

Today, @DraftKings unveiled Moonshot, a new live betting feature available on DraftKings Sportsbook for MLB games.
Moonshot allows customers to place a single, dynamic wager that builds in value as the action unfolds toward a target payout. Predefined values are assigned to every outcome, with the biggest moments accelerating progress toward a target payout.
More: draftkings.com/draftkings-ex…
5
8
42
228,472
Chris Grove retweeted

Jun 8
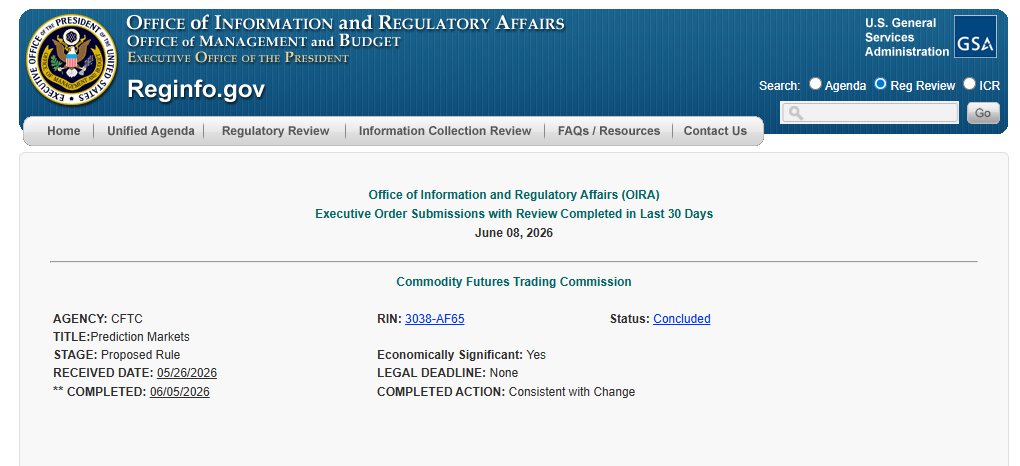
The CFTC's proposal to regulate prediction markets should be out soon.
The White House wrapped up its review of the measure on Friday, according to an update on OIRA's website.
9
27
94
35,969

Jun 8
In related news, water is expected to remain wet.
Jun 7

Tax revenue from legal online sports betting in North Carolina has far exceeded even the most optimistic expectations. Now state lawmakers, seeking additional revenue for other priorities, have reached an agreement to raise the rate that operators pay: wral.com/news/local/nc-lawma…
1
4
2,561
Chris Grove retweeted

Jun 8
Release: @Sportradar and @Kalshi today announced a multi-year global agreement to position Sportradar as an official data and solutions provider for Kalshi.
Sportradar will deliver sports content and services across MLB, NHL, MLS, the UFC, and other major sports properties.

6
8
56
21,469
Chris Grove retweeted

Jun 6
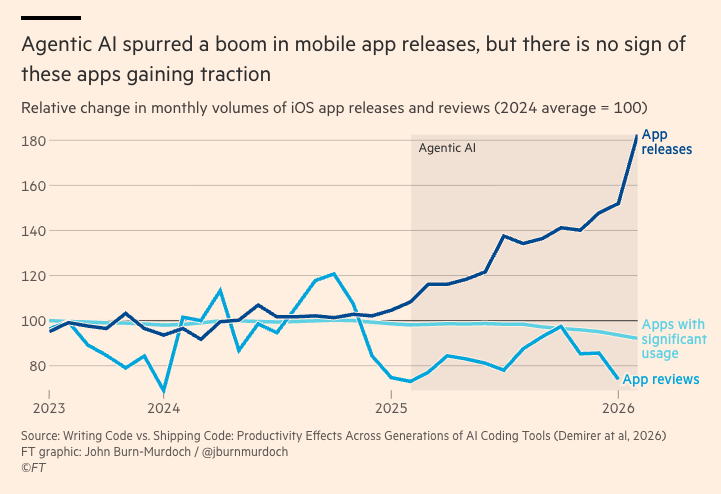
This FT chart visualizes the dramatic increase in apps published to the iOS App Store. I wrote about this a few weeks ago, when SensorTower published similar data. I don't find the increase particularly interesting, since that's exactly what one would expect with the proliferation of AI-enabled coding tools. What I do find noteworthy is:
- this is unique to the App Store; Google Play has seen no commensurate increase, since it tightened its automated submission review standards, also through AI: more output meets greater scrutiny, both empowered by AI.
- the surge in apps published to the App Store coincides with Apple launching a new ad placement in App Store Search.
As I note in the first episode of The Prosperous Society, AI-enabled output shifts the binding constraint for commercial success to distribution.
5
3
22
10,059
Chris Grove retweeted

Jun 5
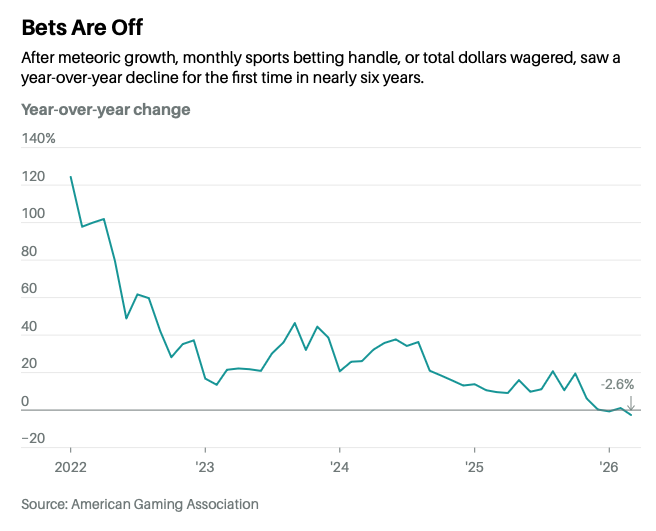
NEW: The 2026 World Cup is set to be the biggest betting event in history, but the business of sports betting faces an uncertain future.
Total U.S. sports wagers in Q1 fell 3.1% from a year earlier, according to the American Gaming Association (excluding the new market of Missouri).
That's on top of state lawmakers tightening the screws on the industry with responsible gambling measures and rising tax rates, plus a growing betting fatigue in America spurred by rapid sportsbook expansion and prediction markets opening new facets of life to betting.
My cover story for next week's print issue of Barron's is online now with insights from @JonathanDCohen1, @SteveRuddock, @Jordan17502511, @joeymaloney, @nigeleccles, and more.
1
6
12
17,990
Rush Street Interactive (RSI) submitted its application to the Commodity Futures Trading Commission (CFTC) to become a prediction market exchange, becoming the latest business involved in state-regulated gambling to take steps to launch a prediction-market product.
5
11
35
22,674
Jun 4
I absolutely cannot wait for the seven-part limited series on @netflix.
Jun 3

Polymarket believes archrival Kalshi could be spying on its NYC offices, employees: 'Too many coincidences' trib.al/VZJMuSy

1
1
69
19,905
Chris Grove retweeted
Jun 3
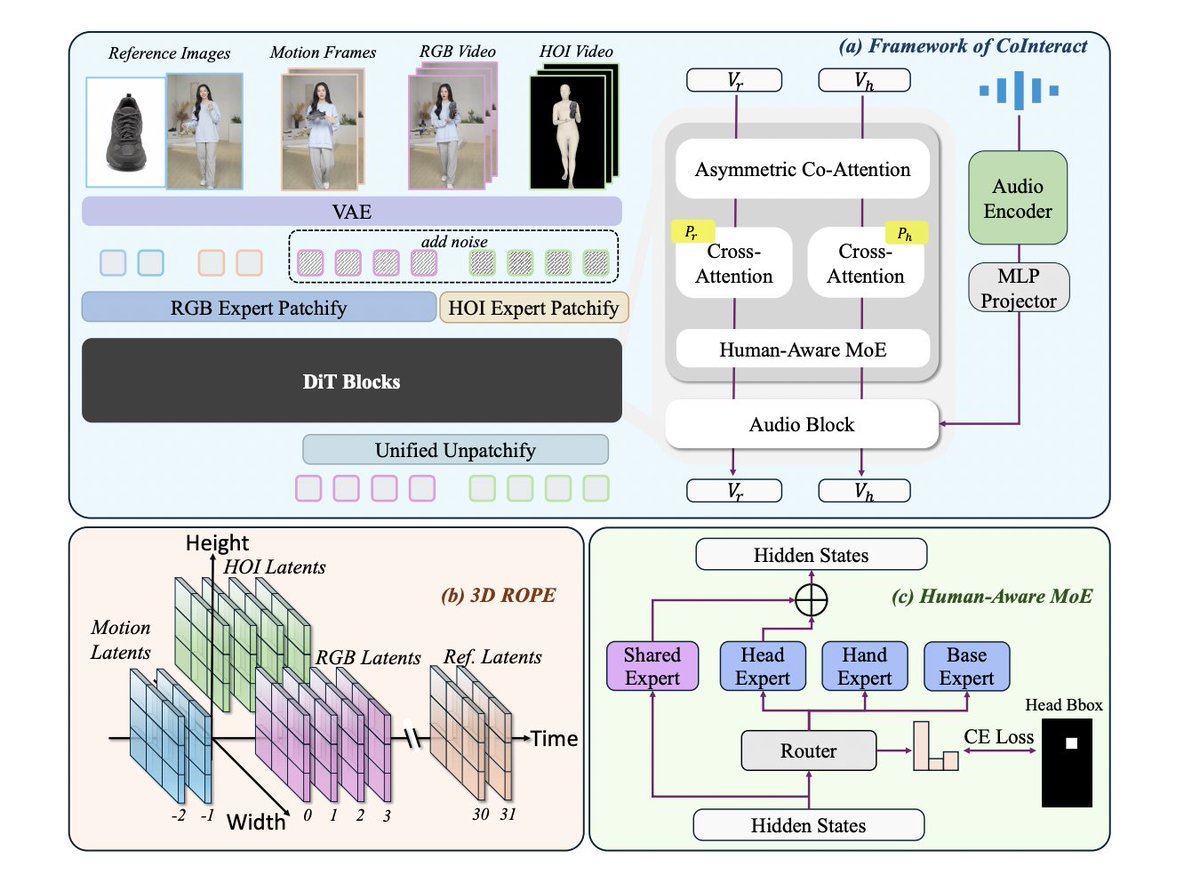
Many of the eCommerce product showcase videos you now see on Instagram and TikTok are AI-generated. It's generally fairly easy to tell because the hands may be mangled, the faces don't retain consistency throughout, and/or the person in the video interacts in odd ways with the product (hand passing through it, etc.). This is because diffusion transformers (DiT) are trained primarily on RGB representations, meaning they infer human-object boundaries from appearance alone.
A new paper from Alibaba introduces CoInteract, which trains a DiT on two parallel representations of the same scene: a standard RGB video stream and an auxiliary Human-Object Interaction (HOI) stream that strips away texture from the human representation while preserving body structure and interaction geometry. The two streams are trained jointly through a shared backbone with co-attention, allowing the model to learn physical interaction priors during training. The HOI stream is discarded at inference, so most of the quality gains come with almost no additional generation cost.
The framework also introduces face- and hand-specific experts in an MoE architecture that routes tokens via a "spatially supervised router." The training pipeline relies heavily on off-the-shelf tools for object segmentation, human mesh recovery, and hand/face detection to create human- and object-masked streams and to encode them both into a shared latent representation. The model was trained on 12k clips with "RGB–HOI representations, hand/face bounding boxes, and silhouette masks." CoInteract outperformed other SOTA models on nearly every benchmark.
Paper linked below.
2
2
10
2,772
Chris Grove retweeted

Jun 3
No idea who made this game, but it's extremely fun and addicting.
Thank me later.
82-0.com

687
519
6,454
3,500,554
Chris Grove retweeted

May 28
Introducing The Run by Called It.
We make a prediction market call. We back it. And we carry it — position by position — until we hit our target.
$250 to $1 Million
Every call is logged. Every result is public. Nothing gets deleted.
Editorial only. Not financial advice.
7
2
20
3,001
Kalshi has filed to offer contracts related to fantasy football for the first time, having self-certified contracts on players’ average draft position.
The contracts use Sleeper’s single-QB point-per-reception redraft leagues as the sole source agency to determine ADP. In February, Sleeper started offering Kalshi’s sports event contracts.
12
15
79
235,468
Jun 2
This is true from a category perspective, but any given competitor in the retail casino category can certainly be outcompeted by companies that better leverage technology.
Good news is that bar is fairly low in the retail casino industry due to its ~hermetic nature.
Jun 1

Barry Diller, whose company already owns a 26% share of casino giant, has said he sees it as a business that is less at risk of being disintermediated by technology. on.wsj.com/4nYtpdH
2
1
4
9,484
Chris Grove retweeted
Jun 1
On The Record is live today 11am EST.
@dannyburke5 will be joined by @AdamMKaufman and @CormacYanited to discuss the following prediction markets:
⚾️CI. Daily Call of Texas Rangers to Win
⚽️The World Cup Golden Boot Winner
👽Will Aliens be Confirmed to Exist?
Watch here on X or at twitch.tv/calleditmedia
3
4
2,757
Chris Grove retweeted
Jun 1
Starting today, licensed Massachusetts sports betting operators must send out notifications to customers if their sports betting activity is limited in any way.
Several operators have confirmed with @SBD notifications are going out.
sportsbettingdime.com/news/b…
4
13
10,046
Chris Grove retweeted

May 28
Gonna do an unsolicited plug here: If you are in gaming and enjoy just learning about the business, there really is no better conference than the @UNLVigi #GamblingConf. Regulators, academics, industry execs all find so much to take from this event.
1
4
5
1,089
If you’ve been anywhere near gambling Twitter the last few weeks, you’ve seen it: Kalish vs Kalshi.
DraftKings co-founder @mattkalish, freshly retired from the company, lighting up the timeline with one critique after another of Kalshi.
The Business of Betting podcast got Kalish on to find out what set him off — and why he continues to beat the drum.
3
3
15
3,845