
Joined May 2007
- Tweets 3,383
- Following 776
- Followers 402
- Likes 2,920
116 Photos and videos









Osamu MATSUMOTO retweeted

Jun 2
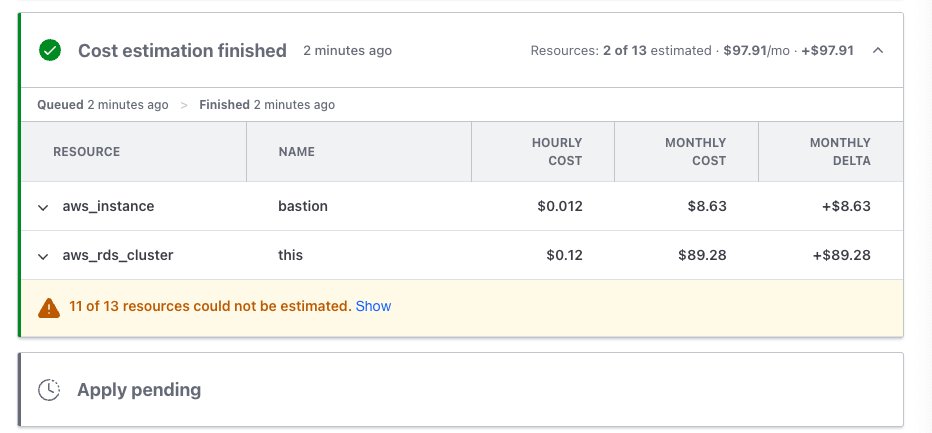
地方建設業が、1年で給与を平均20%、最大50%引き上げられた理由(ボーナスも過去最高を更新)
DXで生産性爆上げ
→ 人を増やさずに、対応できる仕事量が増える
→ 受注が増える(昨年比1.6倍)
→ 利益が増える(昨年比3倍)
→ 従業員に還元できる(給与は平均20%増、最大50%増、ボーナスも過去最高)
→ 雇用条件が良くなる
→ 人が集まり、採用が加速する(初の新卒採用にも成功)
→ 生まれた余剰キャパで新規事業も受注できる(親会社の顧客基盤ともつながり、シナジーが生まれる)
→ さらに積極的にDXへ投資
→ 正の循環が回り始める
この一連の取り組みを通じて、DXで本当に重要なのは、「どんなツールを使うか」ではなく、「どの業務に、どのテクノロジーを適合させるか」そして、「人とITを組み合わせて、どのようなオペレーションを最設計し、実行できるまで粘り強く推進するか」だということに気付きました。
この視点に立つと、必要なプロダクトも、最適なオペレーションも、人の配置も見えてきます。
だからこそ私たちは、単なるITツールベンダーではなく、DXで実際に成果を出す「建設業 × IT業」の会社を目指します。

10
34
2,810

May 28
May 28

みなさんぜひ、このページのFAQを読んでみてください!それから「履歴」「状態」は解像度が粗いので、当然ながら、それらのワードを含んだ一般則は作れません。
scrapbox.io/kawasima/�%…
79
May 26
これまでサービスを分割して独立して成長させていたところも、AIによる開発速度の変化によって1サービス複数モジュールとして成長させたほう良くなるパターンがある。おなじ製品価値のためのコードは、近くに配置し、シンプルに結合されてたほうが圧倒的に変更が早く間違わない。
2
50
May 24
すごい。壊れた複数の同一車種の外装パーツを1つ1つ分解して3DスキャンしてCAD化、CNC加工でプレス金型をつくってAE86などクラシックな名車のボディパーツを量産してる。こういうことを大規模できる事業者、日本には居なそう。
youtube.com/watch?v=cBBZrjwq…
1
85
May 21
言語化されててすばらしい。

いずれも言いたいことは、CADの設計データは見た目だけでは完結しないので、「AIで全自動化できる」と見るにはまだいくつも壁があるということ。
AIは絵を描けるのに、CADの線は引けない
zenn.dev/0xliclog/articles/f…
AIは3Dモデルを作れるのに、CAD設計データは作れない
zenn.dev/0xliclog/articles/f…
1
157
May 12
そう思います!セコイアキャピタルの基調講演で、顧客を包み込む体験の1つとして、AIと顧客との間に入って、アフォーダンスのギャップを埋めるアプリケーションが必要と言ってましたね。
youtu.be/LRo33rnv6rQ?si=C2Y1…
May 12

生成AI を前提にした既存サービスの新しい UI とか UX がどうなるか、なんかだいたいみんな間違えてるんじゃないかって思ってもどかしい
AI にお願いすればなんでもやってくれる体験みたいなのをみんなすぐ考えるんだけど、人間、いきなり自由度の高いツール与えられても案外何していいかわからない
1
340
May 11
テナント別にサイロ化するとmigrationが問題になりそ。
テナント別にローリングでMigrationする仕組みとか、アプリ側でLazyにmigrationかけるとか、そういうデータのケア部分の作り込みが必要になるんじゃないかな。
zenn.dev/emuni/articles/6eef…
1
118
May 10
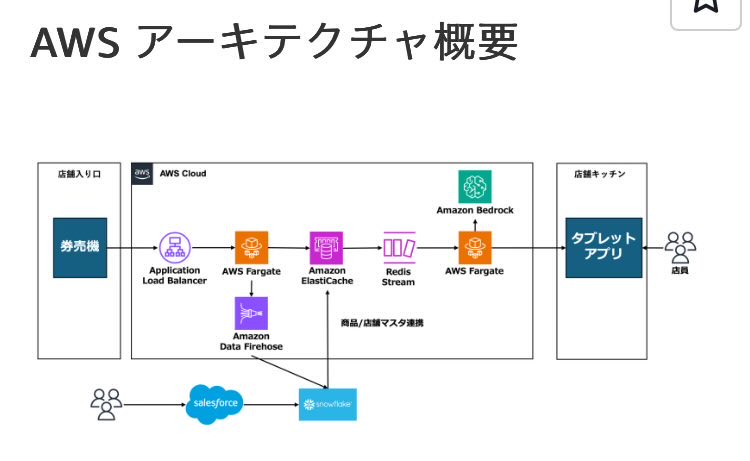
なんでこんな複雑にしちゃうんだろ?
ElastiCache Cluster Multi-AZは非同期レプリケーションだから障害時に注文情報のロスの可能性あり。その時はsnowflakeのデータと突合させるの?Redisを操作して、漏れているもの発見して入れ直すとか面倒そう。
普通にDBのMutiAZで同期が無難だし運用楽じゃない?

1
196
Osamu MATSUMOTO retweeted

52
409
143,320
Feb 24
最近claude codeがたまに接続エラーしまくることがある。途中でサーバ側からTCP RSTが飛んでくるんだよね。MTUいじったりしたくないが、家のNW構成との相性が悪い。類似Issueが結構ある。MAP-Eによって実効payloadが小さい可能性を疑いIPv6出るようにしたら安定はしてる。
github.com/anthropics/claude…
3
335
Osamu MATSUMOTO retweeted

Feb 21
28
946
5,095
4,345,897
Osamu MATSUMOTO retweeted

Feb 19
そう思っていた時期が俺にもありました...あと何年か経てば、LLMの一部としてセマンティックストレージ(GDMのTitansみたいなやつ)が実用化され、そこにテラバイトのデータを入れてrecall 100%で呼び出せて、かつ今思いついた新単語や製品IDみたいにセマンティクスがないデータも扱える世界がくる...のかも。
しかし現実にはロングコンテキストをフルに使うと重くて遅くて高い上に、Lost-in-the-middleのせいで長さに比例してreasoningの賢さがぐんと低下する。だからSkillsのように、セマンティック索引をエンジニアがこまめにメンテしてコンテキストを最小化するとLLMがぐんと賢く動く。まるでCPUと同じような局所性が重要で、これがコンテキストエンジニアリングが単なるバズワードではない理由。
だから当面はベクトル検索等のセマンティックストレージをLLMの外部に持つ必要がある。では、RAG界隈でベクトル検索がきちんと使えているかというと、全然そんなことはない。そもそもベクトル検索のイノベーションはここ10年くらいかけてじわじわと浸透してきたもので、LLMのイノベーションとはあまり関係がない。今のコンシューマ向けWebサービスのほとんどはベクトル検索と推薦モデルを中心に作られてる。Google等big techの主要サービス、Insta、X、Facebook、Spotify、TikTok、Uber、Amazon、Netflix...これらの今どきのITビジネスの収益を生み出している大黒柱だ。このポストを見ている全員、毎日数10のベクトル検索や推薦モデルを知らずに利用していることに気づいているだろうか?
でもこれらの本物のITとRAG界隈の最大の違いは、多くのRAG事例のような単純な類似検索(cos類似度の距離の近さ)のためにベクトル検索を使っているベンダーはほとんどない点。Xのタイムライン、YouTubeのおすすめ動画、Spotifyのプレイリスト、TikTokでスワイプ後に見せる動画リスト等々...を生成する推薦システム(recsys)を作るためにベクトル検索を使うのが、LLMとは関係なく過去10年のコンシューマ向けサービスで起きている最大のイノベーション。いかにして賢い推薦をするディープラーニングモデル(LLMではない)=推薦モデルを作れるかという部分で各社はしのぎを削っている。
LLMは推薦の能力は優れているけど、まだコストと遅延が桁違いに大きすぎて、こうした数億人相手の用途には使えない。現時点では世の中のコンシューマービジネスを回しているのはLLMでは全然ないことに気づいて欲しい。そして現在、XやYouTube、Amazon (COSMO) 等の先進的なプロジェクトで、LLM蒸留(LLMに大量の学習データを生成させて小規模なディープラーニングモデルを学習する手法)を使った生成的推薦(generative recommendation)が実用化されはじめている。さらにYouTubeのセマンティックIDやGoogleのDSI等の新しい研究が始まっている。詳しくはこれ参照→ x.com/kazunori_279/status/20…
一方で、ここ2〜3年の間にネット上で続けられてきたRAG界隈の議論は、こういうレベルに全然達していないまま下火になりつつある。依然としてベクトル検索=単純なcos類似度による類似検索という前提の議論が主流で、上記のようなアカデミックな推薦モデルやLLM蒸留の話をタイムラインで見かけることは、英語でも日本語でもとても少ない。でも、国内外のコンシューマー大手のデータサイエンティストの人とミーティングしたりすると、やはり彼らは現実的なLLM蒸留を実用化してたり検討している(当然Xにはそういう話はあまり流れない。ビジネスの稼ぎ頭の話だから)。
というわけで、RAG=ベクトル検索では全くないし、ベクトル検索を使わずとも優れたRAGはいくらでも作れるけど、ここ10年でIR/recsys界隈で起きてきたベクトル検索のイノベーションが背景にあるからこそ、LLMとベクトル検索の組み合わせがとても面白いということを知ってほしい。まずは単純な類似検索をやめてみよう(定期)。

ぶっちゃけ、RAGをやる9割の人が間違っていると思う。そもそも、なぜベクトル検索をする必要があったのかを考えて欲しい。
背景はコンテキストウィンドウに入りきらない大量の独自ドキュメントを、安価にLLMの検索対象にしたいから。
RAG(ベクトル検索)が流行った当時は、今みたいにエージェントもなければ、ディープリサーチみたいなツールもないし、コンテキストウィンドウも主要モデルは小さかったから、ベクトル検索せざるを得なかった。
つまり、別に精度が高いからRAG(ベクトル検索)をしている訳じゃない。
むしろ、ベクトル検索をし続ける限り、コサイン類似度に近いチャンクを拾ってくるという宿命から逃れられなくなる。運用コストもバカ高い。
何より、せっかくLLMの精度がとてつもないスピードで向上して、MCPもあればSkillsも出てきたのに、ベクトル検索に依存するフローは、これらの恩恵を受けられず、あまりに勿体なさすぎる。
Claude Sonnet 4.6 が安価に100万トークンのコンテキストウィンドウを持つようになったことで、大量のSonnetサブエージェントに普通に検索をさせた方が遥かによくなる。
全てサブエージェントによる大量検索が最適解だとは思わないが、基本的にはこの未来は確定路線だと思う。
10年後を見据えたコンテキストエンジニアリングが必要で、その中にベクトルDBが本当に入っているのか、想像してみた方がいい。
7
141
913
131,977
Feb 17
まさに同意見でした。チャレンジャー側にいる。

2
255
Feb 12
どのスコープの話なのか経験のない人には伝わらない。部分のことが全部だと伝わっちゃう例をみる。
DDDが必要な業務ソフトウェア、DDDが不要なシステムソフトウェア。データ=~ SoRをもつSaaSと、データを持つがSoRではないSaaS。これらを横断して開発を経験してる人が少ないからなのかなぁ。
1
134
Feb 12
私がやってたのはSREとかできる前の世界だが、大型計算機センターの運用チームには当番シフトがくまれてたし、10年前のSNSの会社でも運用チームがNW・Appそれぞれいて待機当番の手当をもらってたよ。インフラがクラウドになる前だが、当番制度は世の中の普通だったと思う。壊れる頻度が違うからね。
Feb 12

日系でSREやプラットフォームエンジニアをやっているチームで、ちゃんとオンコール制度が回っているところがあれば、ぜひ話を聞いてみたい
オンコールって、本来はサービスを24時間守るための仕組み。誰かが常に責任を持って見るからこそ、プロダクトに本気で向き合える。グローバルサービスだとわりと当たり前にある文化だけど、日系だとまだ少数派な印象
これまで聞いた範囲だと、制度として明確に回している(有償化など)のはPayPayとメルカリくらい
前職はオンコールなしでサービス回ってたけどいつも同じ人が対応してしまいますよね
255

Claude Codeのみで開発されたCコンパイラーCCCのベンチマーク
GCCが10秒かかるベンチマークがCCCだと2時間6分もかかる。
harshanu.space/en/tech/ccc-v…
3
130
674
124,442
Jan 30
他にも、人、物、リソース、様々なマッチングのSaaSとかはAIが労働力だとしても、Supply/Demandのデータを突き合わせる場として残るなと思ってる。

2
199
Osamu MATSUMOTO retweeted

Jan 29
mysqlのコミット止まってるデマの時系列
最初はコミット数減少しているという話や開発がオープンではないという批判で、これはMariaDBの元CEOの記事で、この時点では誤情報ではなかったのだが
1/11 optimizedbyotto.com/post/rea…
その後devclassというサイトが3ヶ月コミット無しというタイトルで記事化する
1
67
120
35,873
Jan 26
10年以上の前の昔話ですが、memcachedといえばmixi大規模障害。私がmixiに入社して1ヶ月後の夏。
qiita.com/bonnu/items/1afaf6…

なんとなく最近memcachedだったので2026年のmemcachedの現在地を確認しとこうかと思って書きました、多分自分の認識も古いと思うしいろんな意見あると思うので、意見くださいませー😅
2026年、memcachedが輝く場所 blog.akuwano.net/2026/01/26/… @kuwa_twより
1
1
9
1,288
Jan 22
1月頭からCES出展でラスベガス行ってきました。
Jan 22

\🚀CES 2026出展レポート公開/
世界最大級のテック展示会CES
現地で見えた技術トレンドだけでなく、日本企業・スタートアップが世界で戦うために必要な視点をまとめました。
noteでぜひご覧ください✨
CESは未来の“当たり前”を測る場所だった【CES 2026出展レポート】
@Tsubaki_quando
@SynQRemote
#CES2026 #CES #スタートアップ #AI #DX #クアンド #出展レポート #ラスベガス
note.quando.jp/n/n5adecd194c…
3
7
429