
Senior Engineer @Qualcomm - Performance Engineering | Windows kernel | C/C | ARM64 | CPU & Memory Microarchitectures | SoC's
Joined June 2024
- Tweets 411
- Following 754
- Followers 3,210
- Likes 118,944
148 Photos and videos












Read “Windows Internals: Thread Management — Part 1“ by OS Dev on Medium:
This article discusses about ETHREAD, KTHREAD kernel objects & windows scheduler - how it schedules a thread.
medium.com/windows-os-intern…
3
24
160
14,177
One of the most interesting Windows NT kernel bugs is MS08-067 - tracked as CVE-2008-4250 - learn.microsoft.com/en-us/se…
The vulnerability was in the Server service ("srvsvc") and was triggered remotely through a crafted RPC request. An unchecked path parsing routine led to a stack buffer overflow, allowing attackers to execute code in kernel-related services without authentication.
It became the primary infection vector for the Conficker worm, proving that a single parsing bug could compromise millions of Windows machines worldwide.
2
14
385
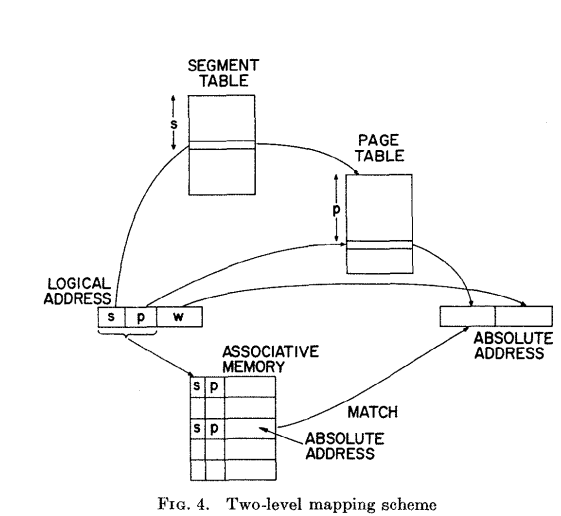
Daley & Dennis (1968) – Virtual Memory, Processes, and Sharing in MULTICS
Introduces segmentation and virtual memory concepts.
andrew.cmu.edu/course/15-440…
1
2
31
558
I’d like to sponsor this FPGA learning kit for a deserving student who genuinely wants to learn FPGA but can’t afford it. Just a small help from my side.
@VazeKshitij @Vicharak_In, could you help me find someone who would benefit from this opportunity?
Jun 12


3
1
22
1,446
Randell & Kuehner's Dynamic Storage Allocation Systems (1968) is one of the earliest papers that studies how operating systems allocate and reclaim memory at runtime.
Instead of proposing a new allocator, it surveys existing allocation techniques and classifies them based on their design and trade-offs. The paper discusses fixed-size and variable-size allocation schemes, relocation, protection, and different placement algorithms such as first fit and best fit.
A major focus is memory fragmentation, especially external fragmentation, and how it affects long-running systems. It highlights the limitations of contiguous allocation and provides a framework for evaluating dynamic storage management techniques that later influenced modern memory management designs.
*This motivated the innovation of Paging*

Randell & Kuehner (1968) – Dynamic Storage Allocation Systems
One of the classic surveys explaining contiguous allocation techniques and fragmentation problems.
researchgate.net/profile/Bri…
2
29
1,692
Randell & Kuehner (1968) – Dynamic Storage Allocation Systems
One of the classic surveys explaining contiguous allocation techniques and fragmentation problems.
researchgate.net/profile/Bri…
6
45
2,996
Windows NT kernel bug CVE-2022-21882 - sentinelone.com/vulnerabilit…
The vulnerability abuses a use-after-free in "win32k.sys". By carefully manipulating window objects and their lifetime, an attacker can make the kernel operate on a freed object that is now under attacker control. This primitive is then used to achieve arbitrary kernel read/write and finally swap the current process token with the SYSTEM token.
12
61
2,674
One of the most fascinating Windows kernel bugs is CVE-2023-21768 - sentinelone.com/blog/cve-202…
A simple integer overflow in the Common Log File System (CLFS) driver causes the kernel to allocate less memory than required but continue writing as if the buffer was large enough. The resulting out-of-bounds write corrupts adjacent kernel objects, giving attackers arbitrary kernel read/write and eventually SYSTEM privileges.
12
44
2,231
One of the most interesting Windows NT kernel bugs is CVE-2018-8611 - nccgroup.com/research/cve-20…
It's a series of 5 articles.
The exploit didn't need to overflow any buffer. Instead, it abuses a race condition in the Kernel Transaction Manager (KTM) to create a use-after-free. Once the attacker gets an arbitrary kernel read/write, it's game over, they simply replace their process token with the SYSTEM token and instantly become SYSTEM.

27
123
6,122
One unchecked integer multiplication can own the entire Windows kernel.
In CVE-2024-30088, an integer overflow caused the kernel to allocate a smaller buffer than required while continuing to process it as if it were large enough. The resulting out-of-bounds write let attackers corrupt kernel memory, build arbitrary read/write primitives, and ultimately replace their process token with the SYSTEM token.
github.com/tykawaii98/CVE-20…
15
73
4,427
CVE-2021-1732 is a great example of how a tiny logic bug can compromise the entire Windows kernel.
During "NtUserCreateWindowEx()", an attacker abuses a user-mode callback to confuse "win32k.sys" about a window's "cbWndExtra" and "pExtraBytes" fields. This type confusion turns "SetWindowLongPtr()" into an arbitrary kernel read/write primitive, allowing the attacker to overwrite the current process token with the SYSTEM token and gain full privileges.
safe.security/wp-content/upl…
16
114
8,116
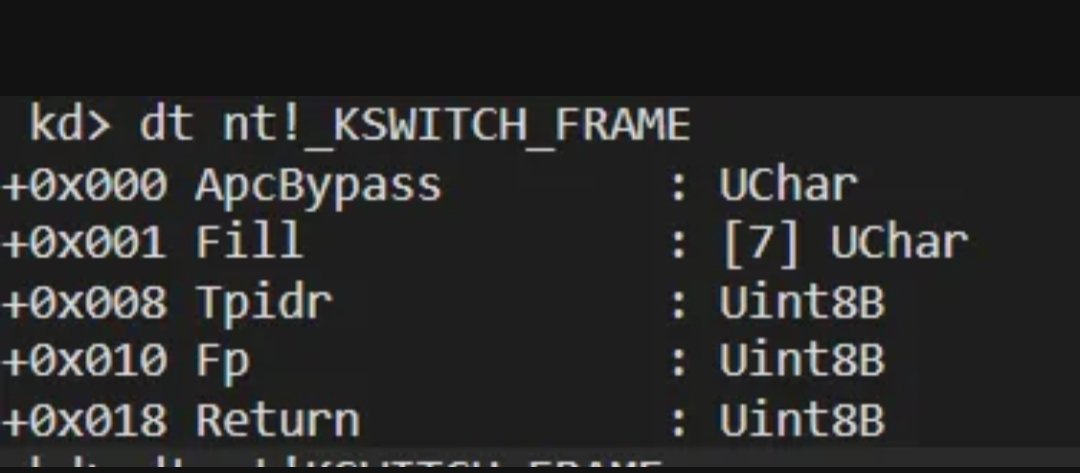
In windows kernel, when interrupts/syscalls or context switch happens, it stores the state of CPU registers inside Threads(KTHREAD) kernel stack. The below are those data structures.
KTRAP_FRAME = snapshot of the CPU at kernel entry (trap/interrupt/syscall).
KSWITCH_FRAME = snapshot of the thread state needed specifically for KiSwapContext to suspend and later resume that thread.
Read more about Thread management in Windows - medium.com/windows-os-intern…
12
130
5,210
This is best channel for windows Internals by @zodiacon
He's one of the authors of the iconic windows Internals books.
youtube.com/playlist?list=PL…
1
35
218
13,881
APC vs APC_LEVEL in Windows Kernel:
APCs (Asynchronous Procedure Calls) are callbacks queued to execute in the context of a specific thread.
- User APC: Runs in user mode when the thread enters an alertable wait.
- Kernel APC: Runs in kernel mode for operations like I/O completion and thread management.
- Special Kernel APC: Higher-priority kernel APC used for critical operations such as thread suspension or termination.
*APC_LEVEL* is not an APC. It's an IRQL (Interrupt Request Level) in the Windows kernel.
Used while processing kernel APCs.
Prevents normal kernel APC delivery during sensitive operations.
Represents the CPU's execution priority, not a queued callback.
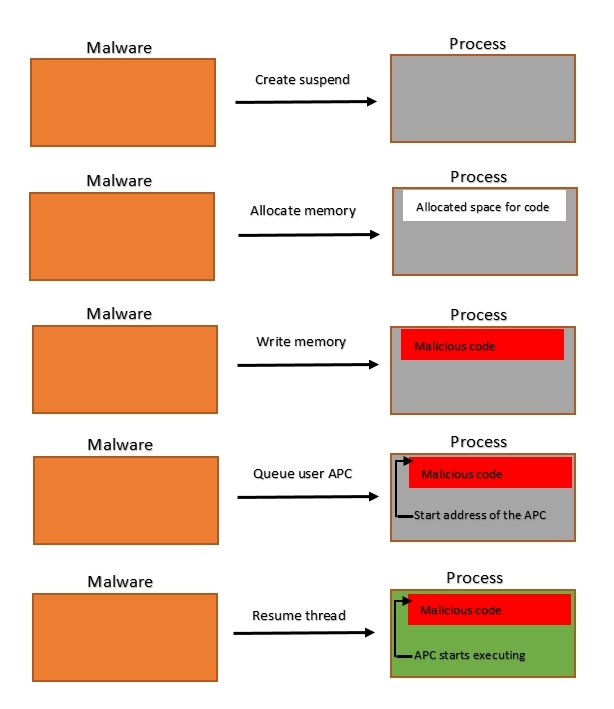
In windows, APCs(Asynchronous procedure calls) is a mechanism in which a function executes in the context of the specific thread. It's not an independent execution entity like a thread.
void CALLBACK MyCompletionRoutine(...)
{
printf("Read completed!\n");
}
ReadFileEx(..., MyCompletionRoutine); //Async I/O
// Later
SleepEx(INFINITE, TRUE); // Alertable wait
Here, the completion routine runs even before SleepEx returns.
Thread
|
|-- ReadFileEx()
|
|-- SleepEx(INFINITE, TRUE)
| (alertable wait)
|
|<-- I/O completes
|<-- Windows queues User APC
|
|-- MyCompletionRoutine() <-- APC executes
|
|-- SleepEx returns WAIT_IO_COMPLETION
|
|-- Continue execution
That's how the below sequence is possible if you have proper rights to open the process handle to suspend. Btw security software can easily catch this because you're suspending a process and allocating memory etc.
8
63
3,030
In windows, APCs(Asynchronous procedure calls) is a mechanism in which a function executes in the context of the specific thread. It's not an independent execution entity like a thread.
void CALLBACK MyCompletionRoutine(...)
{
printf("Read completed!\n");
}
ReadFileEx(..., MyCompletionRoutine); //Async I/O
// Later
SleepEx(INFINITE, TRUE); // Alertable wait
Here, the completion routine runs even before SleepEx returns.
Thread
|
|-- ReadFileEx()
|
|-- SleepEx(INFINITE, TRUE)
| (alertable wait)
|
|<-- I/O completes
|<-- Windows queues User APC
|
|-- MyCompletionRoutine() <-- APC executes
|
|-- SleepEx returns WAIT_IO_COMPLETION
|
|-- Continue execution
That's how the below sequence is possible if you have proper rights to open the process handle to suspend. Btw security software can easily catch this because you're suspending a process and allocating memory etc.
2
12
78
5,784
• improved branch prediction - to execute real applications like databases up to 30% better. How many BTBs(branch target buffers) does it have ?
• 196MB L3 cache, so fewer cache misses. Thus performance improvements.
" - not small loops " targeting Spec CPU benchmarks?
Jun 10

Graviton5 is now generally available. 192 cores, four-chiplet architecture, DDR5-8800, PCIe gen6, and 25% better performance than Graviton4 for general-purpose and agentic AI workloads: amazon.science/blog/graviton…
1
25
1,689
Essentially solving the memory problems with compute by predicting a block instead of just one token ?
Jun 10

Say hello to DiffusionGemma. 👋
@GoogleGemma’s new open model generates text in parallel, not one token at a time, helping deliver faster, more responsive AI on NVIDIA DGX Spark & RTX GPUs.
Get started: nvda.ws/3Sxeonb

3
348
Wow. This is interesting.
Mutex objects have shared variables which are atomically updated, and based on the updated value (i.e., lock = 1 means the lock is already acquired, while a successful atomic operation acquires it with acquired semantics). So, this bug happens because while the atomic update is still in progress and its result is not yet known, the core speculatively assumes the lock will be acquired and starts executing the critical section. It may speculatively read or compute the values inside the critical section, leaving microarchitectural side effects (like cache changes), even though the execution is later rolled back if the lock acquisition actually fails.
2
7
42
1,882
We know modern CPUs have aggressive Out-of-order executions and interrupt/exceptions can be handled precisely when Reorder buffers(ROBs) are used because we still commit in-order. Execute Out-of-order and store temporaries in ROBs and commit in-order.
But what about ARMs weak memory ordering? It doesn't have TSO(like x86 does). Memory operations can happen any order.
Even if commits are ordered,
what if memory itself is allowed
to appear out of order?
This paper answers :
Keep registers precise,
but define memory precision
according to the weak-memory model.
So the paper redefines the precision as "consistent with Arm semantics" rather than "consistent with sequential execution."
Precise exceptions in relaxed architectures
This answers, "Does that still make sense on modern OoO CPUs?" Which refers to "Exceptions occur between instructions"
dl.acm.org/doi/epdf/10.1145/…
1
7
49
3,691
In the windows kernel, at IRQLs you can use Spinlocks but not Mutexes.
The reason is Mutex structure holds ownership details meaning they only work with threads. At higher IRQLs >= DISPATCH_LEVEL, there's no concept of threads.
When we use KeWaitForSingleObject() on a thread, the scheduler switches this thread on sleep and runs another thread. The scheduler only handles threads not interrupts. That's why there should be no blocking at Higher IRQLs (Mutexes, accessing paged data etc)
Btw the Scheduler itself runs at DISPATCH_LEVEL. That's why thread level activity is only restricted to PASSIVE_LEVEL/APC_LEVEL
5
3
106
5,735