
Defining intelligent agentic eval inference and the future of production AI systems @tokenarena0 @intarena
Joined March 2026
- Tweets 66
- Following 4
- Followers 52
- Likes 42
20 Photos and videos







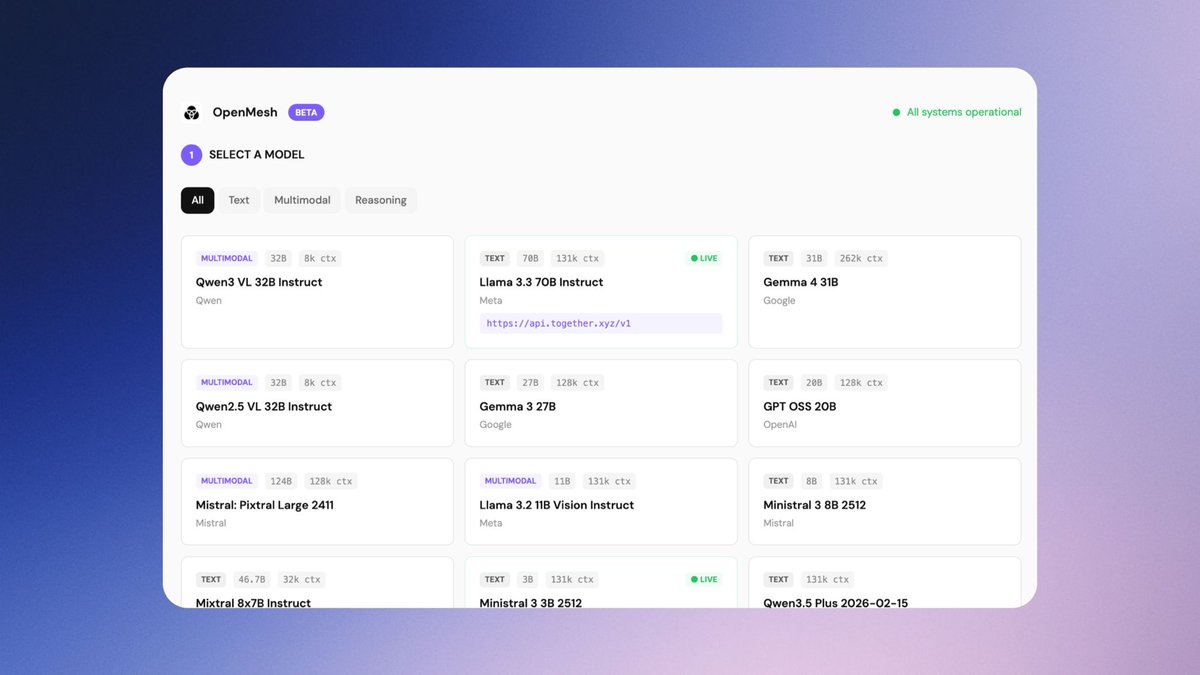
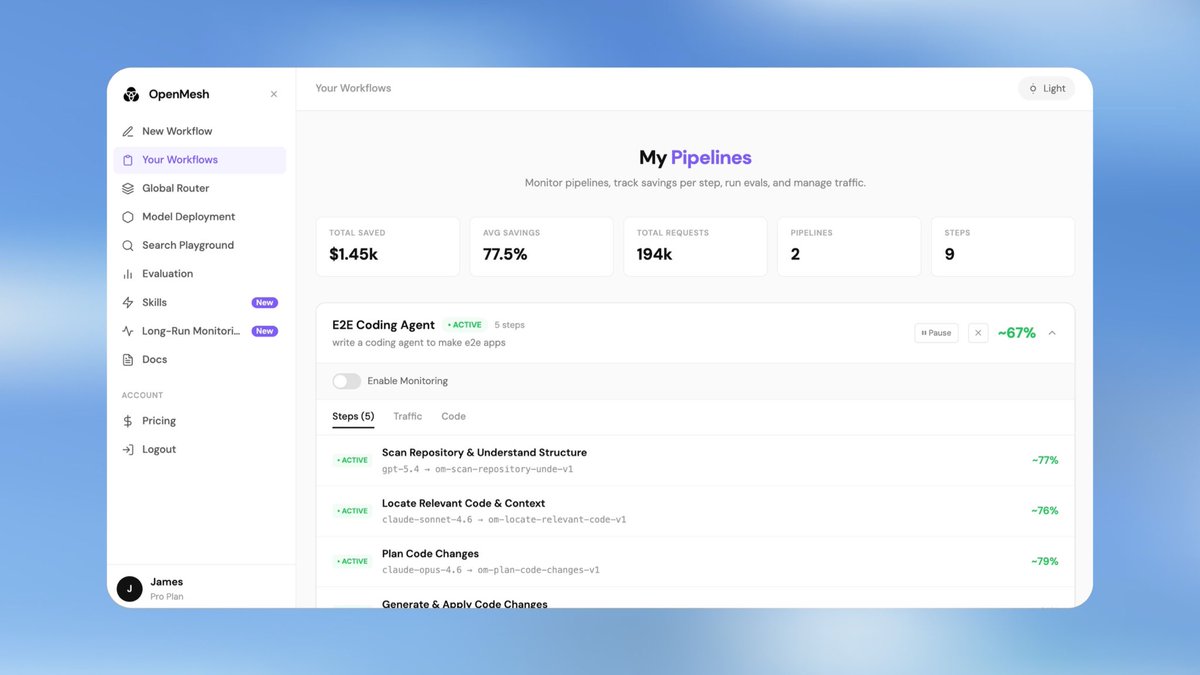

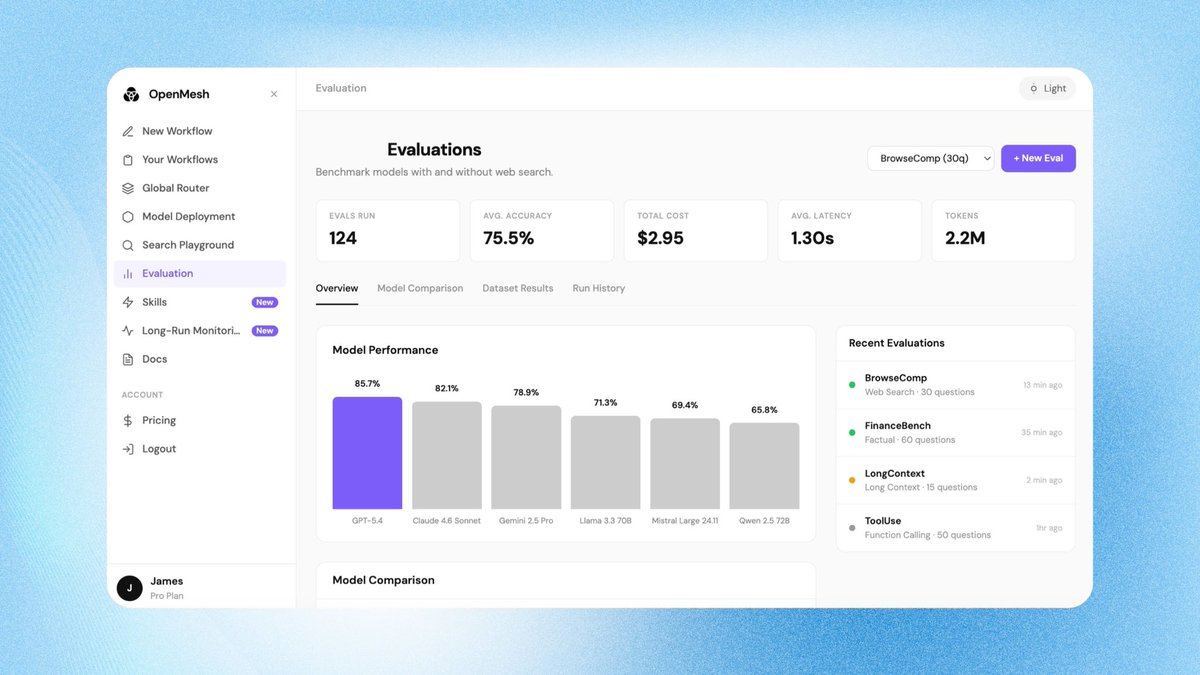

Pinned Tweet

May 26
Multi-agent systems are now routine, but one decision goes unmeasured: when an orchestrator hands a subtask to a peer model, does it pick the right one?
We built DecisionBench to score the handoff itself, not just the final answer, across an 11-model, 7-vendor pool over 23,375 task instances. The headline finding: there is enormous performance left on the table. A perfect-delegation ceiling sits 15 to 31 points above where today's systems land, on every benchmark we ran. That gap is the prize, and skill-aware orchestration is how you capture it.
Read more about it in our blog post:
openmesh.ai/news/decisionben…
4
10
17,755
May 29
Great day at ACM Conference on AI and Agentic Systems @CAISconf
Ion Stoica’s @istoica05 talk on efficient search was a highlight: stagnate -> explore, improve -> exploit.
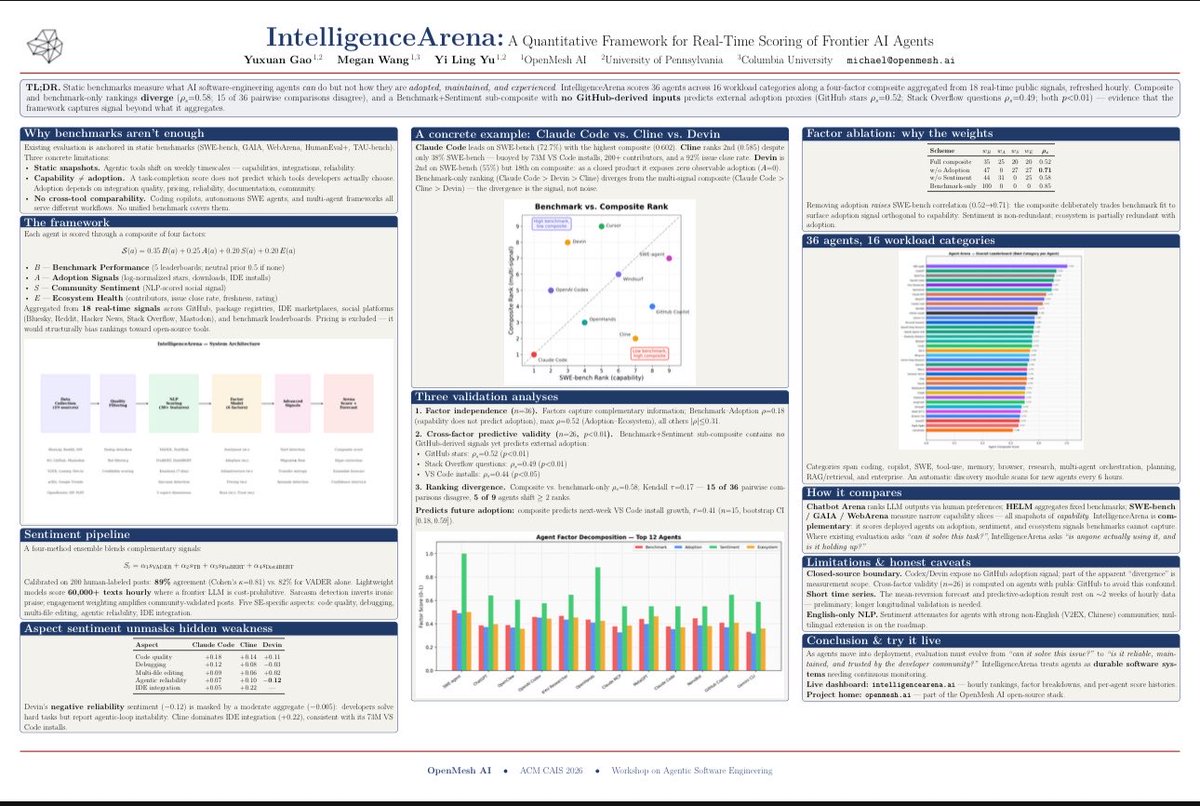
And what a response at our AgentPulse and IntelligenceArena posters, two sessions, both packed. Thank you to everyone who came by. Continuous eval for agents in deployment is striking a nerve, and the conversations proved it.

2
5
387
May 26
We will be at the ACM Conference on AI and Agentic Systems (CAIS) tomorrow @CAISconf
Come find the OpenMesh team at our poster station. We’d love to talk about your agentic workflows.
Posters: “AgentPulse” “IntelligenceArena”
3
11
862
OpenMesh retweeted

May 23
As LLMs become increasingly powerful, the ability to effectively delegate and collaborate with other models may itself become a critical capability for long-horizon agentic systems.
It was a lot of fun working with these passionate young researchers on DecisionBench! @MichaelYGao @meganwxng @YYL_GB
May 21

Your multi-agent system might be delegating to the wrong model on every single subtask, and your eval would never tell you 🧵
Introducing DecisionBench: the first benchmark that measures whether agents actually delegate well, not just whether the task got done.
arxiv.org/abs/2605.19099

2
11
21
3,422
OpenMesh retweeted

May 22
Final-task accuracy can hide a broken multi-agent system.
Your agent may “solve” the task while making bad delegation decisions the whole way through.
That’s why we built DecisionBench: an eval for whether agents delegate well, not just whether the final answer looks right. 🧵
May 21
Your multi-agent system might be delegating to the wrong model on every single subtask, and your eval would never tell you 🧵
Introducing DecisionBench: the first benchmark that measures whether agents actually delegate well, not just whether the task got done.
arxiv.org/abs/2605.19099
4
6
1,126
OpenMesh retweeted

May 21
Excited to share what we’ve been working on @OpenMeshAI
DecisionBench aims to measure how well LLM agents emergently delegate sub-tasks to peer models during long-horizon workflows, using process-level metrics that quality-only evaluation misses.
May 21
Your multi-agent system might be delegating to the wrong model on every single subtask, and your eval would never tell you 🧵
Introducing DecisionBench: the first benchmark that measures whether agents actually delegate well, not just whether the task got done.
arxiv.org/abs/2605.19099
4
7
5,017
OpenMesh retweeted

May 21
Your multi-agent system might be delegating to the wrong model on every single subtask, and your eval would never tell you 🧵
Introducing DecisionBench: the first benchmark that measures whether agents actually delegate well, not just whether the task got done.
arxiv.org/abs/2605.19099
2
16
58
14,886
OpenMesh retweeted

May 20
Three strong signals today: DecisionBench (delegation quality), UCCI (calibrated cascade routing), and Gemini 3.5 Flash (agentic speed). Common thread: advantage is moving from model IQ to orchestration policy—who handles which step, at what confidence, at what cost.
2
3
4
271
OpenMesh retweeted

May 20
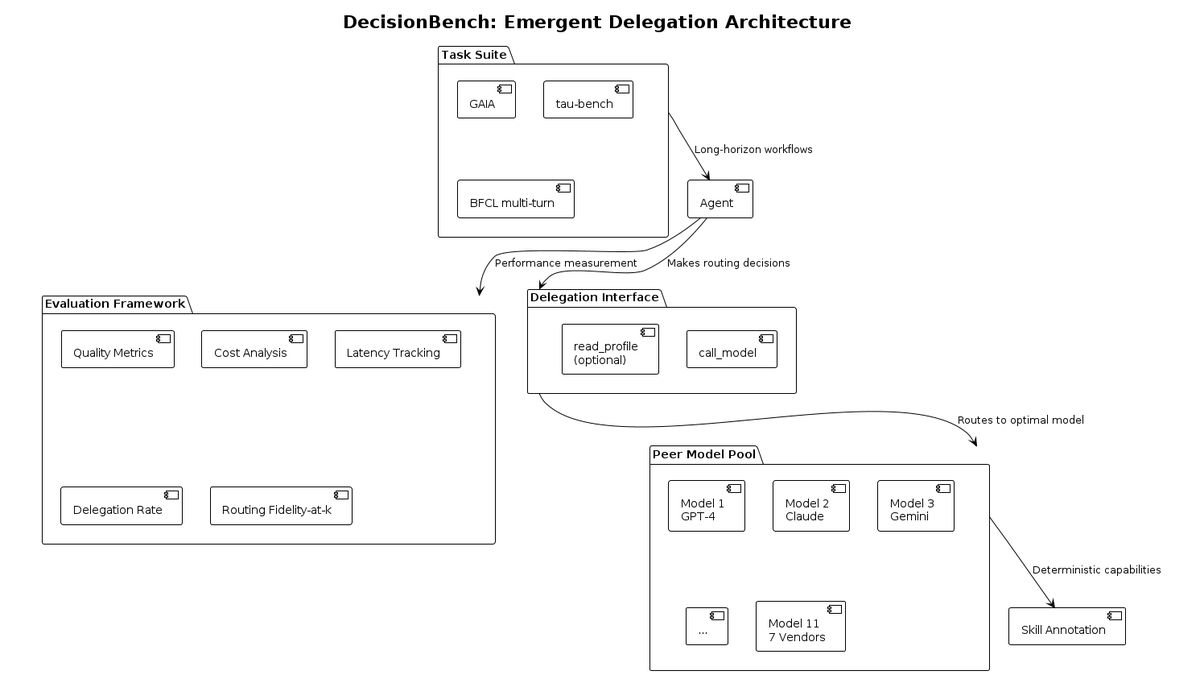
DecisionBench's methodology creates emergent delegation patterns:
1) Peer model pool with known capabilities (GPT-4, Claude, Gemini, etc.)
2) call_model interface optional read_profile channel
3) Skills deterministically annotated across all models
4) Tasks from GAIA, tau-bench, BFCL
1
1
3
60
OpenMesh retweeted

May 20
The promise of autonomous AI agents often rests on their ability to reason through complex, long-horizon tasks. Yet, we frequently overlook the "delegation problem", which is the moment an agent decides it needs to offload a sub-task to another model or tool. Enter DecisionBench, a new benchmark designed to stress-test how these systems handle emergent delegation. This is not just a technical curiosity, but a governance challenge. When an agent autonomously decides to delegate a critical fact-checking or drafting process to an external module, where does the chain of accountability end? DecisionBench forces us to confront the "black box" of agentic decision-making, moving us beyond simple benchmarks toward a more rigorous understanding of agency, error propagation, and the risks of unchecked automation in high-stakes environments. If we intend to integrate these workflows into the practice of law, we must ensure our agents possess not just intelligence, but a sense of jurisdictional competence.
Source: DecisionBench: A Benchmark for Emergent Delegation in Long-Horizon Agentic Workflows, by Yuxuan Gao, Megan Wang, Yi Ling Yu, Zijian Carl Ma, Ao Qu
2
3
148
OpenMesh retweeted
May 20
Long-horizon AI agents need to delegate subtasks to specialized models, but nobody's been measuring this systematically.
DecisionBench fixes this: 11 models, 3 task suites, deterministic skill annotations, and multi-axis evaluation covering quality, cost, latency, and routing fidelity.
2
2
4
100
OpenMesh retweeted

AgentPulse: A Continuous Multi-Signal Framework for Evaluating AI Agents in Deployment
Yuxuan Gao, Megan Wang, Yi Ling Yu
arxiv.org/abs/2604.24038 [𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙲𝙻 𝚌𝚜.𝚂𝙴]

1
3
4
5,140
Apr 28
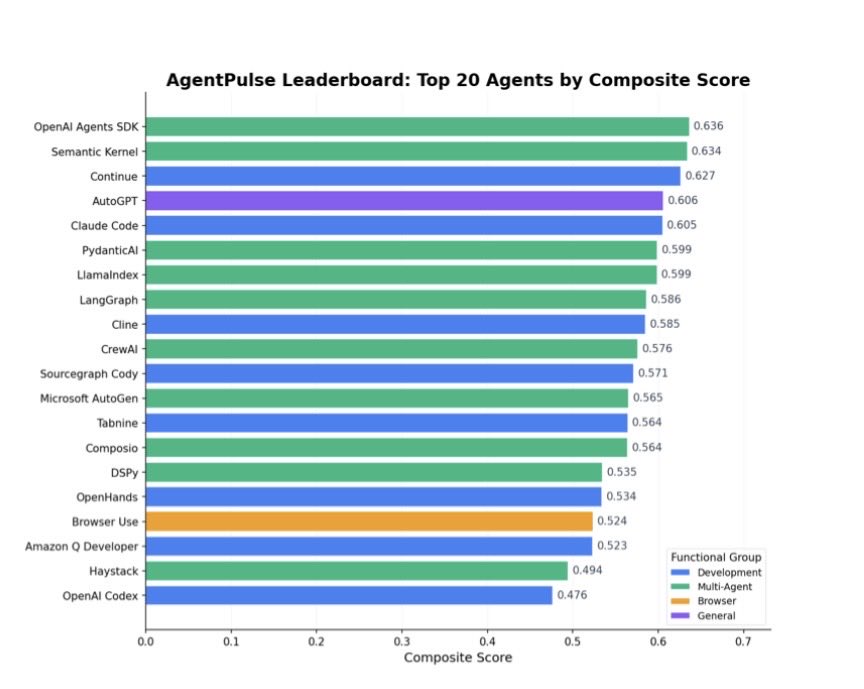
1/ Introducing our newest research, AgentPulse: A Continuous Multi-Signal Framework for Evaluating AI Agents in Deployment
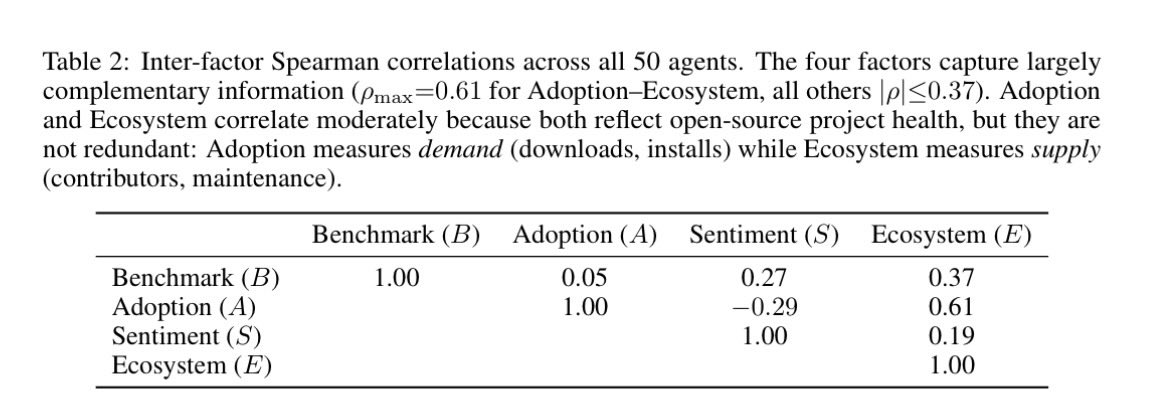
Static benchmarks tell you what an agent can do. They don’t tell you whether anyone actually uses it, trusts it, or sticks with it.
📄: arxiv.org/abs/2604.24038
3
5
9
5,550
Apr 28
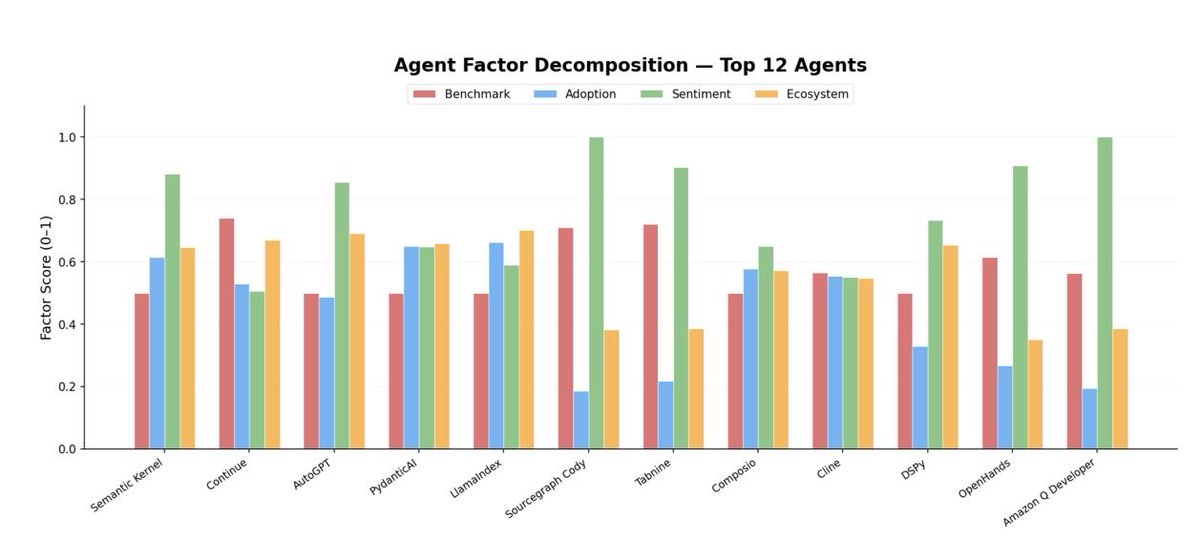
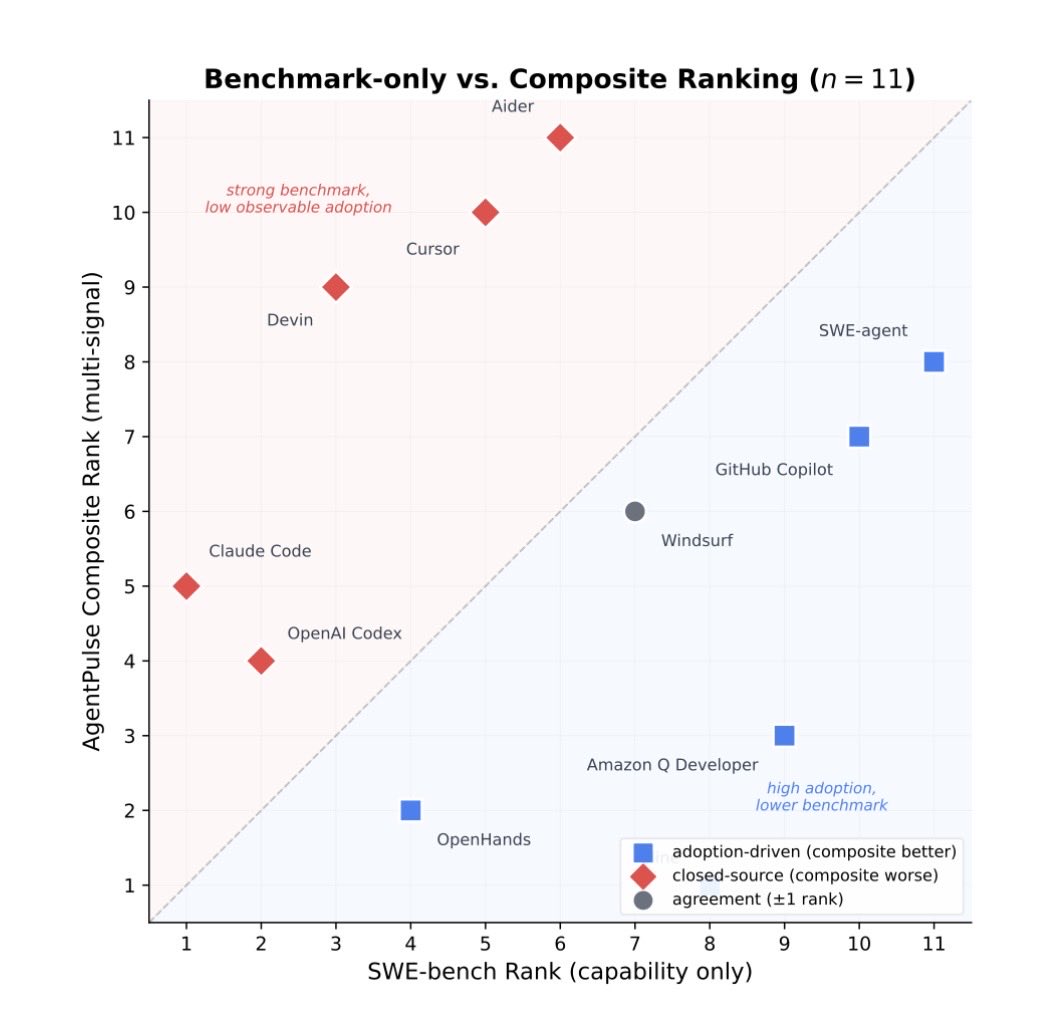
9/ Different agents are lifted by different factors. SWE-agent and OpenHands by sentiment, Claude Code by benchmark performance, copilots by adoption. The composite surfaces this heterogeneity instead of collapsing it into a single number.
1
4
74
Apr 28
10/ AgentPulse is a methodology, not a ground-truth ranking. As agents become more deployed, evaluation has to evolve from “can it solve this issue?” to “is it reliable, well-maintained, and trusted by the developer community?”
Feedback, replications, and adversarial tests welcome!! 🤗
3
47