
Building Vectorless Long-Context AI Infra
Joined June 2023
- Tweets 1,722
- Following 292
- Followers 1,585
- Likes 1,089
51 Photos and videos











Pinned Tweet

May 4
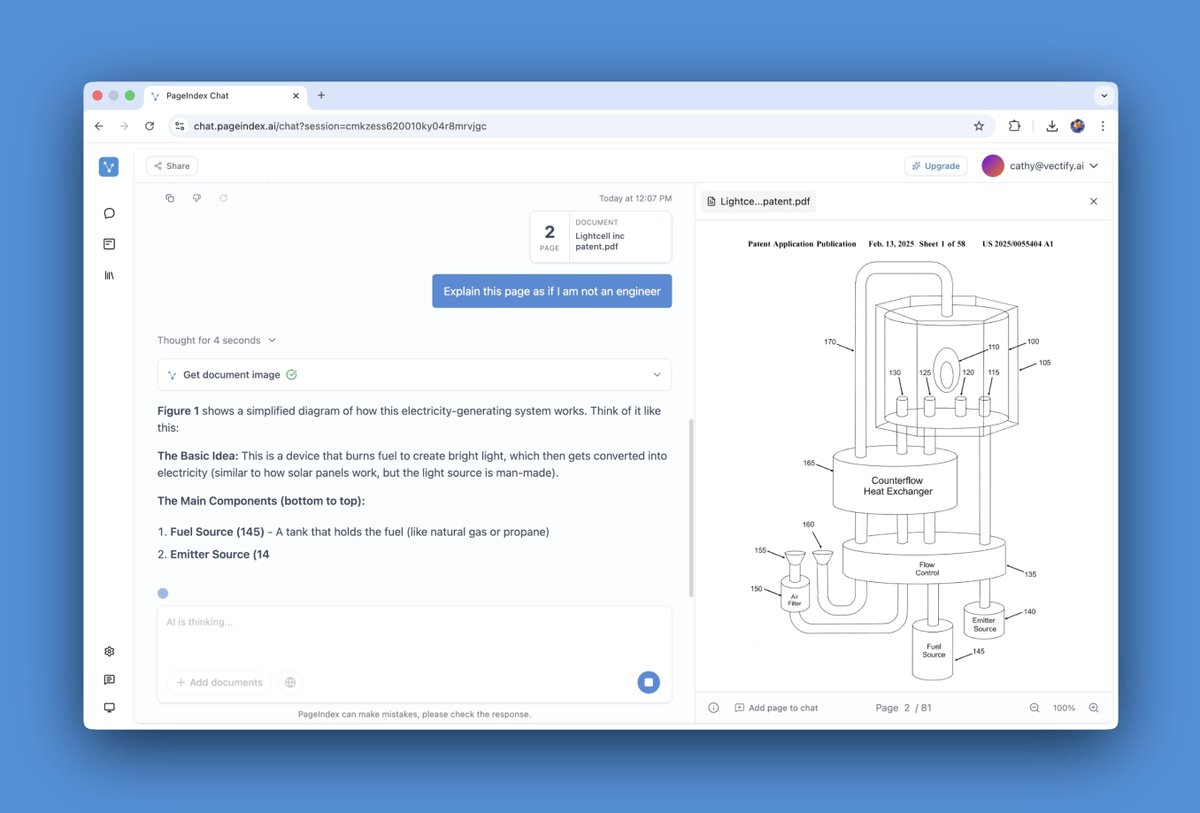
PageIndex now scales to millions of documents.
Introducing the PageIndex File System: a file-level tree layer that lets the PageIndex tree search engine reason over an entire enterprise corpus, not just a single document.
Available today in PageIndex Enterprise. Cloud rolling out later this month.
5
4
23
2,380
PageIndex retweeted

PageIndex seems to be able to become an industry standard index method in the AI era, which is similar position as B-tree earned in the RDBMS era.
Standing on the shoulders of giants is the right way to build something new.
1
1
6
451
Jun 5
📢 New feature in PageIndex Chat: Team Spaces
👥 Create a shared workspace where your team can sync documents, chat with the same knowledge base, and manage access in one place.
#PageIndex #NewFeature #RAG
1
1
6
289
May 28
Linear context doesn't scale. Hierarchical context does.
Dynamic workflows are proving this for agents; while PageIndex is proving it for retrieval.
The future isn't infinite context. It's agentic, adaptive context trees.
May 28

New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
1
4
409
May 28
“Better embeddings don’t fix the wrong kind of memory.”
Structure carries meaning. Chunk a document for vector search and you can lose the section that actually holds the answer.
PageIndex builds a tree index and reasons over it instead — no embeddings, no chunking, no vector DB.
Thanks @natebjones for featuring us.
1
1
3
249
May 28
Full video: youtube.com/watch?v=lqiwQiDg…
Learn more about PageIndex: github.com/VectifyAI/PageInd…
3
275
May 21
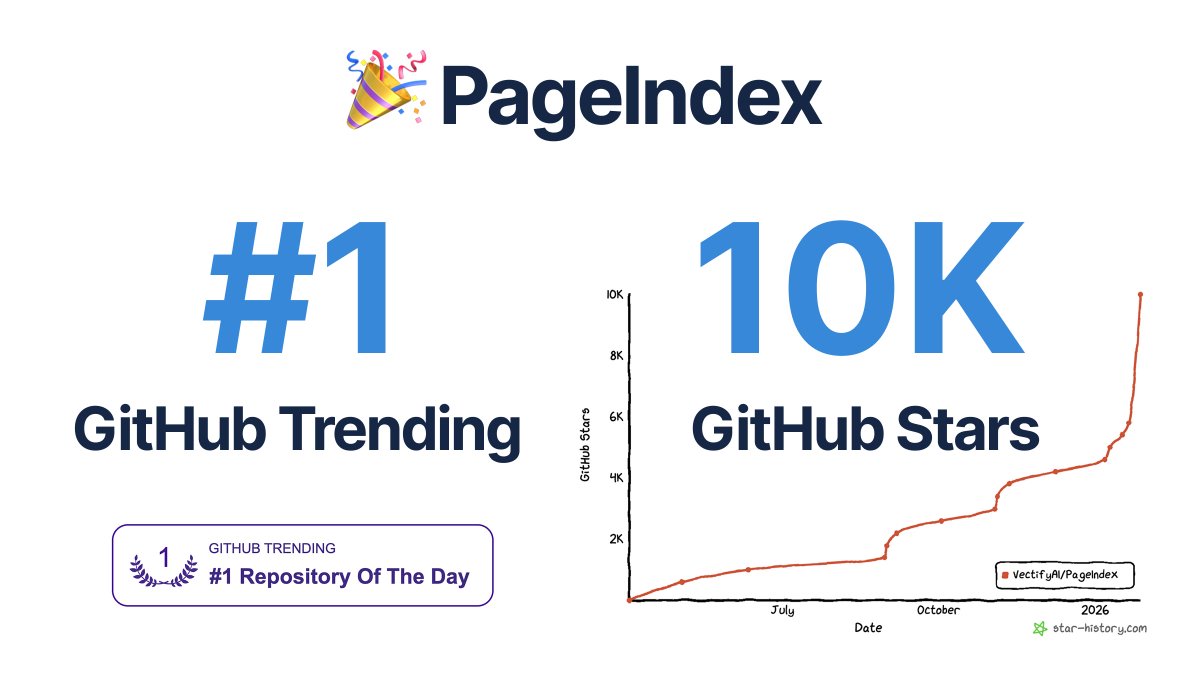
PageIndex crossed 30K stars on GitHub ⭐, now at 31.9K and still climbing fast.
With our recently launched PageIndex File System, we are building the long-context AI knowledge infra for vectorless, reasoning-based retrieval at scale.
Thanks to everyone who starred, tried, shared feedback, and built with PageIndex. More to come.
1
1
9
485
May 4
PageIndex now scales to millions of documents.
Introducing the PageIndex File System: a file-level tree layer that lets the PageIndex tree search engine reason over an entire enterprise corpus, not just a single document.
Available today in PageIndex Enterprise. Cloud rolling out later this month.
5
4
23
2,380
May 4
Contact us to get early access: ii2abc2jejf.typeform.com/to/…
Learn more at pageindex.ai/blog/pageindex-…
1
2
772
Apr 29
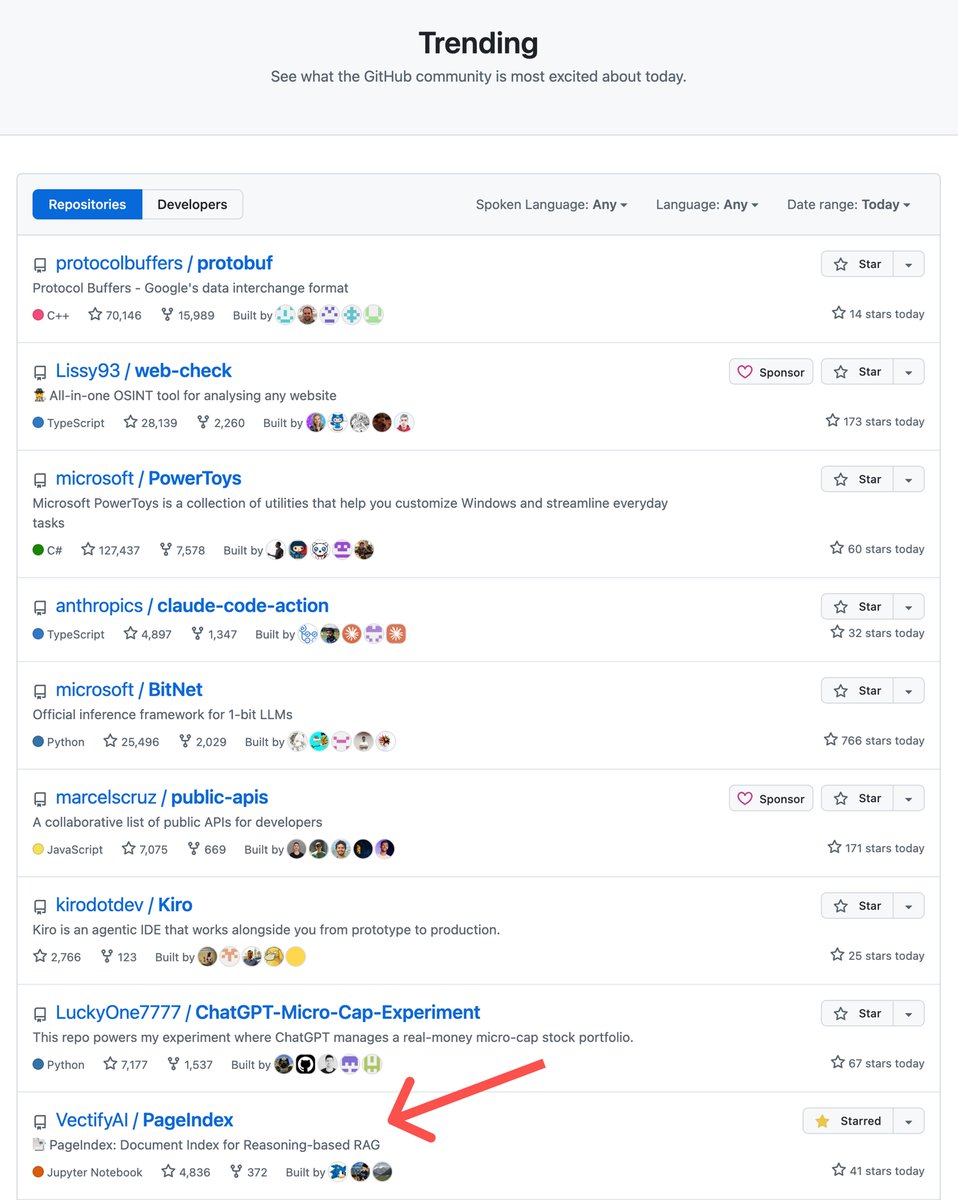
🚀 PageIndex ranked among the fastest-growing on the Open Source Growth Index (#14 in GitHub Star Growth, #38 Overall) by @supabase × @commitvc (Scaling Tier, Q1 2026).
Huge thanks to our incredible community for pushing forward the future of vectorless RAG with us.
26K GitHub stars and counting. More open-source modules coming soon. Stay tuned.
osscar.dev/org/vectifyai
Vectify AI — OSSCAR Q1 2026
Vectify AI on OSSCAR Q1 2026 with a composite score of 3.000.
osscar.dev 2
3
8
1,082
PageIndex retweeted

Apr 28
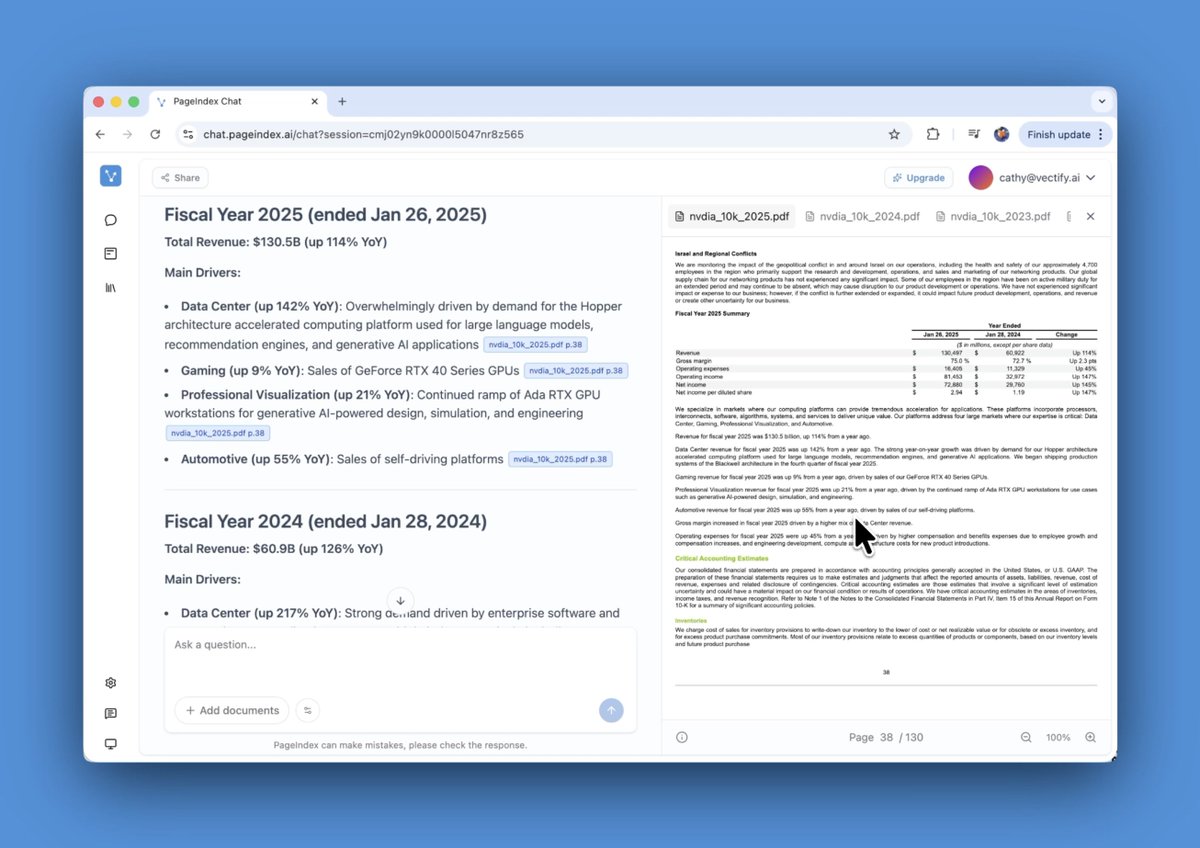
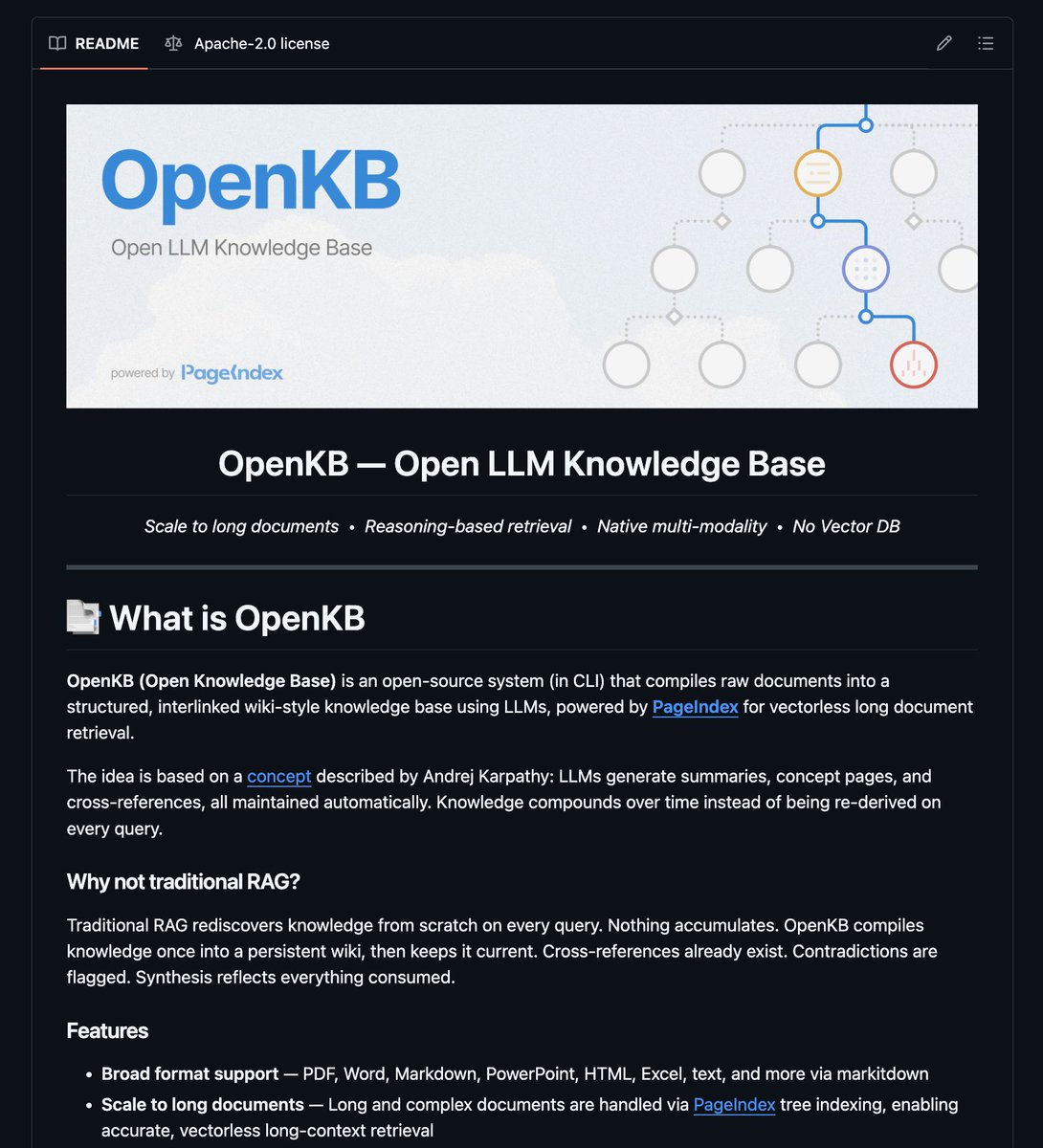
You can now search a 500-page PDF without chunking or embedding anything.
Andrej Karpathy floated an idea recently.
What if your knowledge base worked like a wiki instead of a vector database?
OpenKB is the open-source CLI built on that exact concept.
It compiles raw documents into a structured, interlinked wiki using LLMs.
Knowledge accumulates instead of being rebuilt every query.
Traditional RAG rediscovers context from scratch each time. The system flips this.
Long PDFs get parsed by PageIndex, a vectorless tree index that lets the model reason over document structure.
What you get out of it:
> Auto-generated summaries and concept pages
> Cross-references between documents
> Contradiction and gap detection
> Watch mode for live updates
> Obsidian-compatible markdown output
Format support covers PDF, Word, PowerPoint, Excel, HTML, and images.
Figures and tables are retrieved natively.
A single new file can update 15 wiki pages automatically.
Your knowledge base finally remembers what it already learned.
20
88
554
32,718
Apr 24
Congrats to the @deepseek_ai team on releasing DeepSeek V4 🚀
Curious what’s new compared to V3.2? Check out a simple explanation here with page references: chat.pageindex.ai/share/chat…
1
1
4
535
PageIndex retweeted

Apr 18
Vectorless LLM knowledge base with reasoning
github.com/VectifyAI/OpenKB
3
82
542
31,011
Apr 16
We solved the biggest problem with @karpathy’s LLM Wiki.
He pointed out the hard part: long PDFs and books don’t work well unless you process them carefully in stages.
That’s exactly what OpenKB fixes.
With PageIndex, OpenKB scales to long PDFs by turning them into a hierarchical tree for better wiki generation.
4
6
29
1,817
Apr 15
Many ideas behind PageIndex are from Mackay’s great book!
Apr 15

10 years ago today, we lost Sir David MacKay FRS. Physicist. Mathematician. Polymath. Gone at 48. I was working on my PhD at Cambridge, and attended some of his last lectures and symposium. He was a reason that attracted me to Cambridge over MIT in 2014.
His textbook, Information Theory, Inference, and Learning Algorithms, was the first ML book I ever read — recommended to me by none other than Geoff Hinton.
He used that same information theory to build Dasher — a text entry system where users steer through a continuous stream of letters flowing toward them, with a probabilistic language model making likely next letters larger and easier to reach, so that any tiny movement — a finger, a gaze — becomes efficient writing. It was the first ML application that truly blew my mind, and sent me deep into a rabbit hole: arithmetic coding, PAQ8 compression, nonparametric models. A journey I partly owe to his PhD student Christian Steinruecken, who also happened to share my love of Japan.
As Chief Scientific Advisor to the UK's Department of Energy & Climate Change, he brought a physicist's clarity to policy. In Sustainable Energy – Without the Hot Air, he ran the numbers on our entire energy diet — and made me confront an uncomfortable truth. One of the biggest single factors? Beef — roughly 1,000 days of cow-time per steak. Hard to argue with the data. Hard to act on it when you were born and raised in Japan. I'm still working on that one, David.
At his final symposium in Cambridge — just a few weeks before his passing — the room told the full story. Geoff Hinton and his Caltech PhD advisor John Hopfield — both Nobel Prize winners in Physics 2024 — gave tributes. Environment policy advisers spoke. Dasher users sent video messages of thanks from around the world — people who found their voice because of him. It was extraordinary to witness, in one room, just how many minds and lives a single person had touched.
The story of how Hinton first noticed him: at a conference workshop poster session, among everyone who stopped by, it was the young MacKay who asked the sharpest, most penetrating question. Hinton remembered it. That's how it begins.
I've always liked physicists who cross into ML — they bring a groundedness, a refusal to hide behind formalism without meaning. David MacKay and Max Welling are the role models I point to. Not just for the mathematics they built, but for how they carried it: with humility, curiosity, and a stubborn insistence on reaching beyond academia.
He seemed to know his time was limited, and gave everything anyway. His legacy stays.



1
2
564
Apr 15
We are proud that PageIndex’s 25k stars are entirely organic, coming from people with vision.


1
415
PageIndex retweeted

Apr 14
Context as structured data in @MystMarkdown is where ideas like LLM-wiki (@karpathy) and vectorless reason-first search (@PageIndexAI) converge. Evidentron lives in the scholarly publishing domain, but the same principles can significantly benefit agentic knowledge bases.
Apr 14

I will be presenting this work at the upcoming National Academy of Science, Engineering and Medicine Roundtable Action Collaboratives meeting at @hhmi_science
Below is the entire demo by @agahkarakuzu, feedback welcome! n/n
2
3
7
820
PageIndex retweeted

Apr 13
Reading "Rules of the Mind" by John R. Anderson — his ACT theory splits long-term memory into:
1. Declarative memory — factual, retrievable knowledge
2. Procedural memory — skill-based knowledge
Striking how closely this maps to today’s LLM systems.
chat.pageindex.ai/share/chat…
1
9
517