
Joined July 2020
- Tweets 1,244
- Following 241
- Followers 11,086
- Likes 1,021
146 Photos and videos









Pinned Tweet

8 Feb 2022
⚡️ My PhD thesis is on arXiv! ⚡️
To quote my examiners it is "the textbook of neural differential equations" - across ordinary/controlled/stochastic diffeqs.
w/ unpublished material:
- generalised adjoint methods
- symbolic regression
- more!
arxiv.org/abs/2202.02435
v🧵 1/n


30
196
1,523
Jun 10
Can confirm, Adaptyv are amazing. 100% you should work on frontier science from the beautiful shore of the largest lake in Switzerland.

We're hiring at Adaptyv! Come work with us to scale up the best automated lab for the age of agentic science
2
11
2,408
Patrick Kidger retweeted

Jun 2
Introducing Strong Stochastic Flow Maps
TLDR: Stochastic Flow Maps where we learn the stochastic solution path.
Work led by Sam McCallum, @zwblasingame, with Timothy Herschelll, @AlexanderTong7, and @JamesFosterBath
Arxiv: arxiv.org/pdf/2606.01086
Code: github.com/sammccallum/ssfm
6
76
362
73,491
May 11
Alright chaps, I am in Boston for PEGS, here to chat all things AI antibody engineering. Send me a message if you're around! 🧬
(PS I'm hiring! Pharma x AI startup, come make drugs with us.)
1
1
43
3,425
Patrick Kidger retweeted

Mar 5
We're growing the AI team at @ManifoldBio, starting with a role to train protein foundation models on our proprietary data.
I believe Manifold is the most interesting place to work on protein design. We're designing and testing millions of binders per month, including in vivo, and accelerating. No one else has data like this.
If you have deep experience pretraining or fine-tuning protein models and want to work somewhere the data actually lets you push beyond what public datasets can enable, please reach out.
4
17
103
17,892
Patrick Kidger retweeted

Feb 23
Who's the most talented software engineer you know that should stop building SaaS products and instead join a company that builds in the physical world?
Refer them to me and get a 2000 USD referral bonus if we end up hiring them!
Feb 23

We're hiring software engineers at Adaptyv.
We're building an automated lab that allows AI models to run biology experiments in the real world.
You'll build the software platform that turns lab hardware into programmable APIs, orchestrates complex experiment workflows, and processes messy physical-world data.
50 companies already run experiments on our platform — big pharma, frontier AI labs, techbio startups. We're scaling fast and need people who can ship across the full stack.
You don't need a bio background, but you should be genuinely curious about biology. What matters most is product instinct, comfort in ambiguity, and the ability to build things that work in the real world (literally).
3
3
17
3,903
Patrick Kidger retweeted

🚀 Exponax v0.2.0 — fast & differentiable PDE solvers in JAX
New: 3D Navier-Stokes on a single GPU, wave equation stepper, improved dealiasing & memory efficiency
4096² / 256³ on 24GB consumer GPUs
10k² / 512³ on A100/H100
📦 pip install exponax
github.com/Ceyron/exponax
5
50
503
44,021
Feb 11
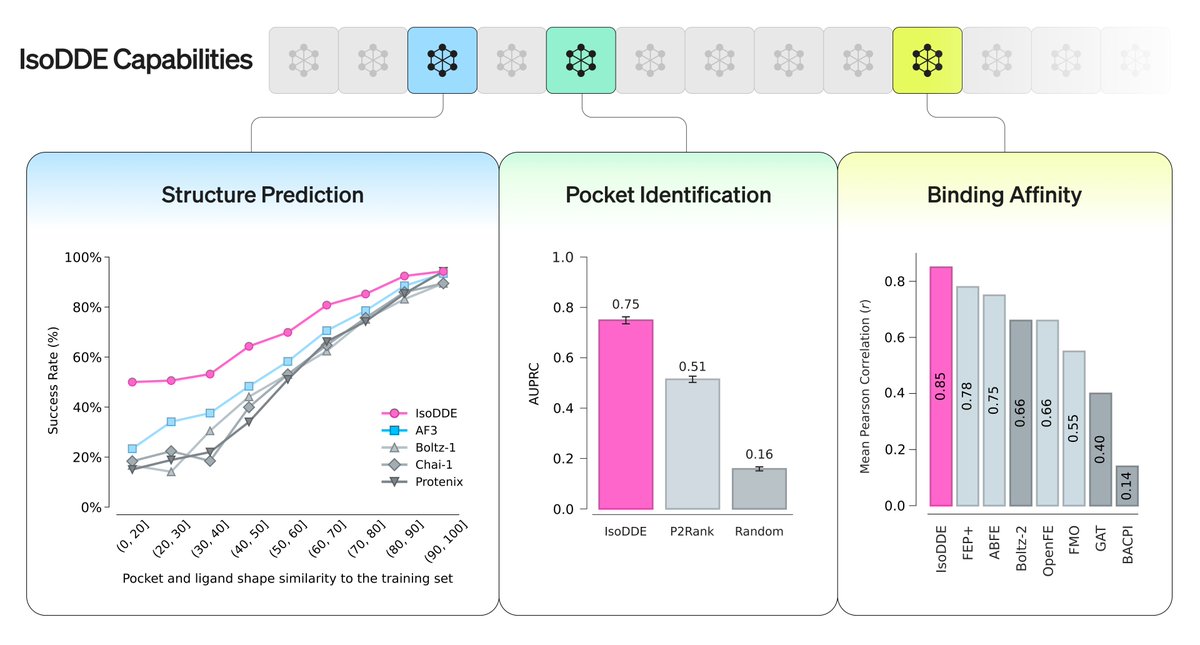
So I have mixed feelings about IsoDDE. It's an AF4, it's much better on hard problems, and I don't want to understate their technical achievement.
But also, it's been five years since founding, and success is measured in drugs, not models. Where are the drugs? 1/
Feb 10

Today we share a technical report demonstrating how our drug design engine achieves a step-change in accuracy for predicting biomolecular structures, more than doubling the performance of AlphaFold 3 on key benchmarks and unlocking rational drug design even for examples it has never seen before.
Head to the comments to read our blog.
10
4
150
31,743
Feb 11
Again, this really isn't meant as a takedown 😅 it's super cool and I look forward to the day that @GabriCorso
makes a publicly-available version! :D
2/2
4
3
41
5,752
Patrick Kidger retweeted

Feb 10
Excited to announce our next In Silico event on February 25th, 6pm at @localglobevc in King's Cross!
Don't miss great talks from @McclainThiel from UCL , @PatrickKidger from @cradlebio, @kpetrovvic from Oxford, and Ivan, PD at @ARIA_research.
Reg here: luma.com/gb3uso7t

1
2
5
1,598
Jan 18
Heck yeah, this is awesome :D
Integrated into everyone's favourite de novo tooling (Boltz, ...) when?
Jan 16
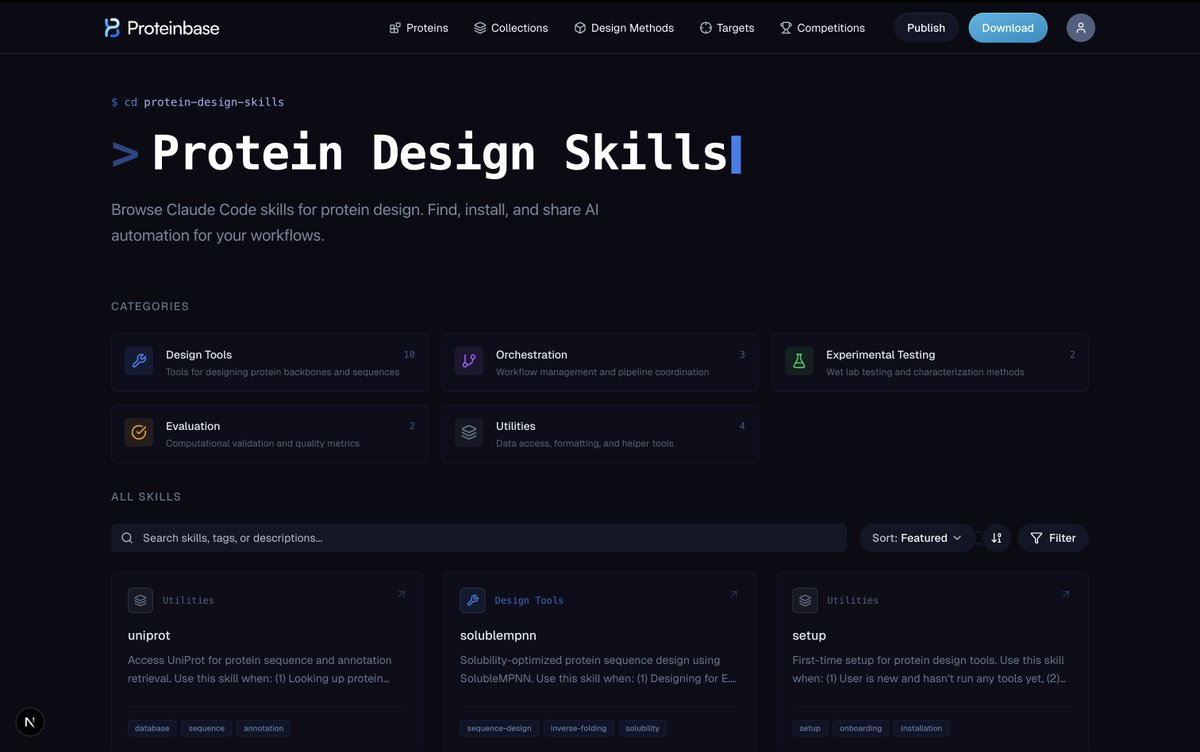
We're launching a Protein Design Skills marketplace for Claude Code!
We received a lot of questions about the protein design agent, so we're releasing the skills we used in the demo. The first batch includes skills for design generation, experimental testing, pipeline orchestration and more. The marketplace is open to community contributions too, so you can build and submit your own skills for others to use
Install with
/plugin marketplace add adaptyvbio/protein-design-skills
and check out the full list here: proteinbase.com/protein-desi…
1
13
2,859
Heck yeah! :D

Big news from Boltz today: we’re launching Boltz Lab, a new platform with new small-molecule protein design agents, announcing Boltz PBC and a $28M seed round, and sharing a multi-year partnership with Pfizer. More below! 🚀
1
2
15
2,056
Patrick Kidger retweeted

21 Nov 2025
we have nine roles open @ Loyal right now - come be a part of the final sprint to bring to market the first FDA-approved longevity drug.

9
10
65
29,793
Patrick Kidger retweeted

21 Nov 2025
Interesting post from @owl_posting asking whats next for antibody design. I agree with him that in vivo properties are likely the answer, but the question is how do we get there?
The PDB has enabled de novo binding models to be incredibly successful. Properties like developability likely are implicit in the models, given the data they are trained on is well formed antibody crystal structures. Fwiw at @ManifoldBio using our open source mBER de novo design approach, we also see very similar affinity/developability properties for our molecules, when we get around to it we might update the preprint to reflect this. Of course you are welcome to try out mBER as it is open source: github.com/manifoldbio/mber-…
Back to in vivo properties, the challenge here is that unlike the PDB, we don't have an accurate and high throughput dataset for antibodies in terms of PK/PD or ADAs etc. Using standard methods, these traits are quite hard to measure in high throughput, which make learning them very challenging. And arguably, these properties are more important than binding for making a successful drug.
These properties are complex, essentially you are asking "I have a binder that I know binds a target of interest in vitro: but does it get to the right place, bind the right target (and not the 20k other possibilities in the body), last long enough to enact its function (i.e. PK) and then perform the function on the target (inhib, activate etc) in a highly complex living system that is nothing like the petri dish that the molecule likely was initially tested in before?"
To some extent, binding has been a solved problem for quite a while. If you talk to folks like Dane Wittrup (inventor of yeast display, founder of Adimab), he will tell you that using yeast display Adimab can design binders to specific epitopes / gpcrs, whatever you want. They will bind with high affinity and specificity in vitro. These new de novo methods indeed speed this process up by a couple months, but fundamentally the really question is still, does your molecule work in a living system, and have you optimized for all the properties (PK,PD, ADA) that will enable clinical success.
This is exactly what why we built @ManifoldBio. We saw the need for high throughput in vivo data to unlock the real power of AI. AI / de novo design are only as good as the data they are trained on, without in vivo data, we will never learn in vivo properties! So we built a measurement engine to solve that.
We have generated PK data on over 12,000 molecules to over 100 targets of interest to date. We have generated in vivo tissue enrichment data on half a million molecules to almost a thousand targets. This is the data we believe will unlock the true promise of AI. Lot's of folks talking about virtual cells, but perhaps we should start thinking about virtual organisms. Even if you had a virtual PK model, this would be a huge benefit to drug discovery. In fact, we already are building such a model, more details soon :)
20 Nov 2025

turns out everything nabla’s model claims it can do, chai’s can too!
so i guess the suspicion that developability being a naturally emergent property of a well-trained model is true
the GPCR result also seems emergent (surprising!), given that chai-2 could do it from the start but just was never tested on it in the original release
insane speed from chai, i wonder if this result was just sitting on ice or they literally contracted a CRO the second they saw Nabla’s release. the post at 11:48pm PST makes me feel like it was the latter, which is a fun story
it does beg the question a little of whats next to hill climb on in this subfield if the traits i assumed are next to optimize for (solubility, etc) are simply going to naturally pop out of any good model, regardless of who are the ones developing it. in-vivo properties i guess?
1
15
79
17,302
Patrick Kidger retweeted
17 Oct 2025
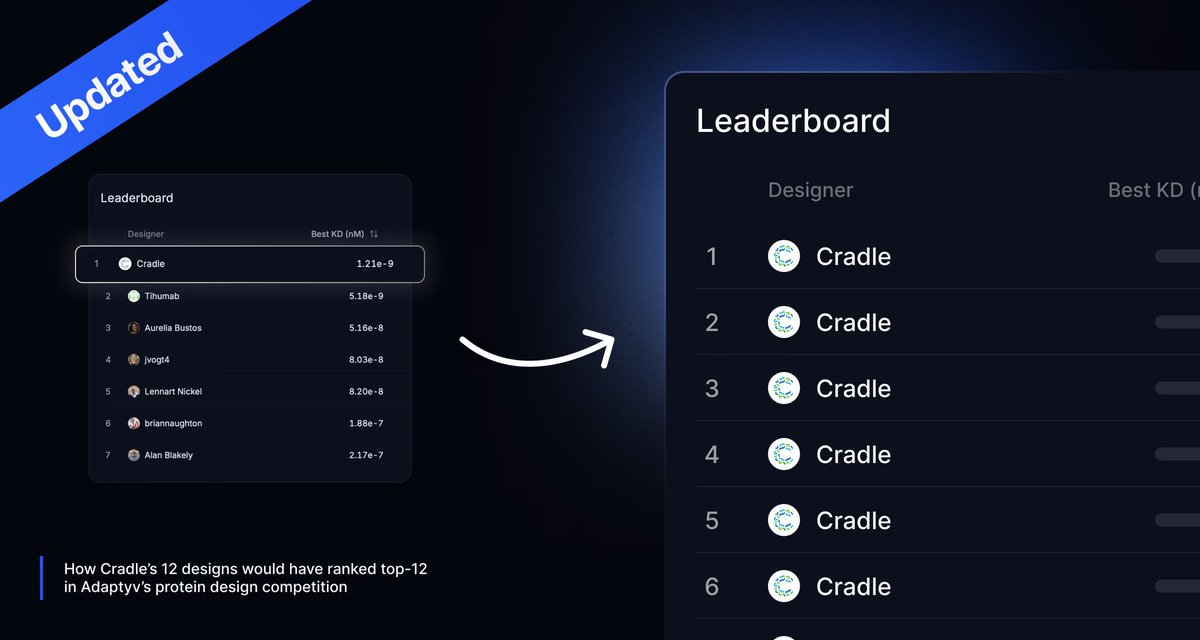
Next company to release cool protein designs on @proteinbase! Check out @cradlebio's competition winning EGFR binders. Many more data drops on the way 👀
17 Oct 2025

New collection drop!
@cradlebio just released their competition-winning EGFR binders on Proteinbase. Check out how they optimized the commercial antibody Cetuximab and scored the highest affinities in our 2024 Protein Design Competition.

4
24
4,147

We’re excited to share a new multi-year collaboration with @TakedaPharma, building on the success of our first engagement. Under the agreement, Nabla will receive double-digit millions in upfront and research payments and is eligible for success-based payments exceeding $1 billion.
The partnership deploys Nabla’s AI-driven JAM platform across Takeda’s early-stage programs to include de novo design of antibodies in parallel for multiple targets, multispecifics, challenging targets, and other custom therapeutics.
Read more below
7
20
118
107,031
7 Oct 2025
🚀 New talk!
"Automated ML-guided lead optimization: surpassing human-level performance at protein engineering"
▶️ youtube.com/watch?v=mEhBBI0j…
✨🧪 This was a talk I gave at the recent AIxBIO conference in Cambridge UK. A 10-minute pitch for what we do at Cradle!
10
68
11,450
Patrick Kidger retweeted
3 Oct 2025
Today we’re releasing real-world experimental data for over 1000 novel AI-designed proteins on our new platform @proteinbase!

11
109
408
49,372
25 Sep 2025
A reminder that there is now *1 week* left until the MLSB deadline on October 1st!
Send in your 🧪bio 🤖ML papers, for either
🇺🇸San Diego,
🇩🇰Copenhagen, or
✨both✨!
17 Sep 2025

🚨To accommodate the addition of EuroMLSB, we have extended the submission deadline to October 1, 2025 11:59pm AoE.
Find information on paper guidelines at mlsb.io. Submissions will be made through CMT.
7
46
7,666
Patrick Kidger retweeted

22 Sep 2025
Taking a first step towards hibernation pods :)
Just announced a $58M Series A led by @foundersfund to back the core roadmap
reversibly cryopreserve human organs ->
help transplant patients build sustainable business ->
accelerate R&D for whole body cryo
22 Sep 2025

We’ve raised $100M to date, we are developing reversible cryopreservation for patients in need of donor organs, and we are hiring 🫀🎉🚀
118
79
1,200
435,723
Patrick Kidger retweeted

18 Sep 2025
Today we're dropping the "beta" tag from Adaptyv, launching our new website and announcing our $8M seed round.
When we started Adaptyv a few years ago, our core belief was: AI models for biology are only as good as the experimental data they're trained on and the hypotheses they can test in the real world.
Now, after a year of working with many great partners, we’ve scaled our infrastructure to the point that we're now open to anyone who wants to use our platform!
Overall, this year, over 30 companies started using Adaptyv to validate their protein designs - from some of the biggest pharmas to frontier AI labs to many, many techbio startups. We've run hundreds of experiments, tested well over 10,000 proteins this year and are generating the data that validates the best AI models currently in development.
3
11
54
11,481