
Joined July 2023
- Tweets 390
- Following 226
- Followers 1,944
- Likes 691
111 Photos and videos















Pinned Tweet

17 Dec 2025
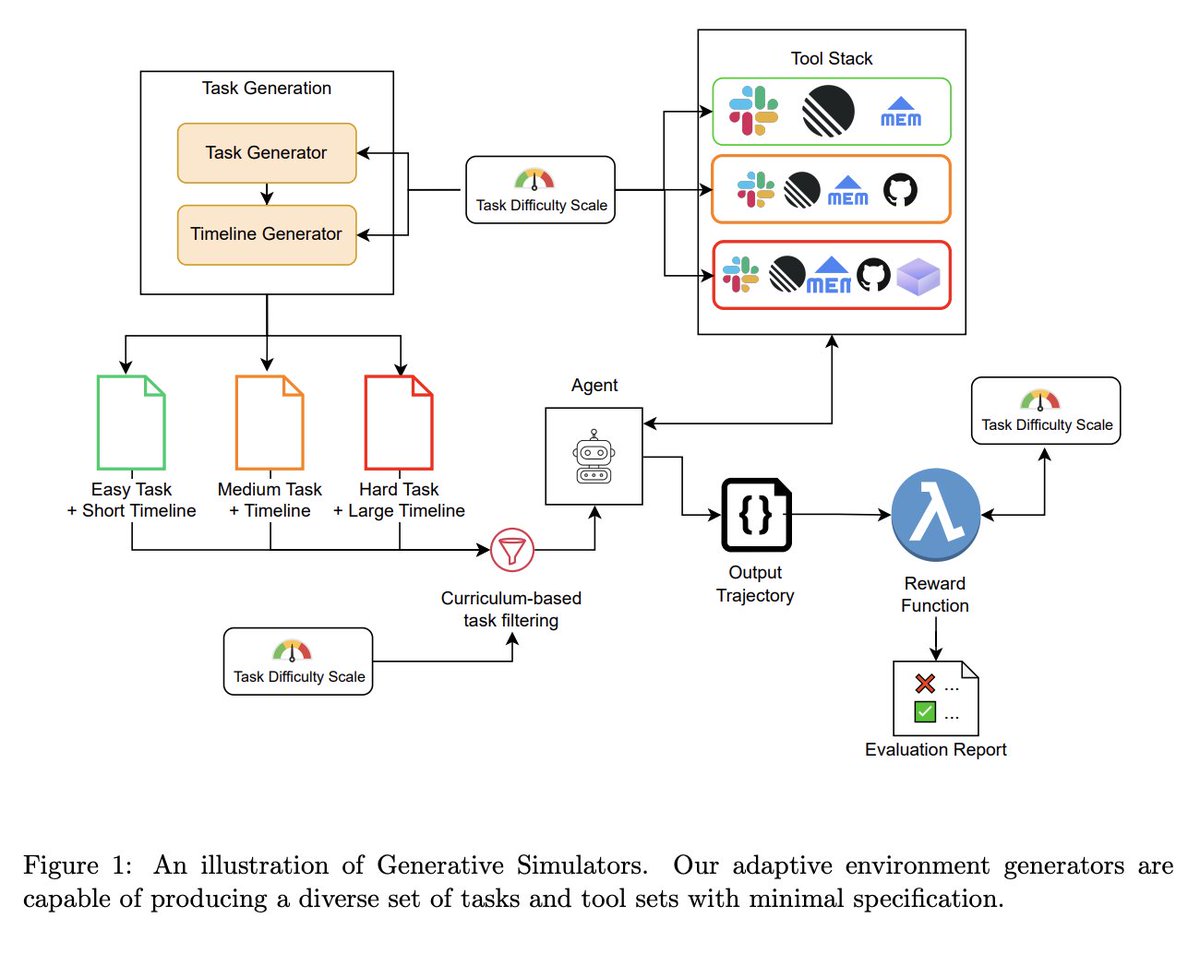
1/ Today, we are thrilled to announce Generative Simulators, a new class of adaptive, auto-scaling environments for AGI training and evaluation 🤖🧵
Static datasets, hand-authored environments, and human-curated demonstrations do not automatically scale with the learning patterns of the trained model. We propose Generative Simulators as a principled alternative: environments that evolve, evaluate, and adapt to agent behavior over time.
Technical Report: patronus.ai/generative-simul…
Blog: patronus.ai/blog/introducing…
4
22
57
13,588
Jun 12
Patronus AI is simulating the world's intelligence every day, and now we're doing it from Times Square too 🗽
Pulling off moments like this is exactly the kind of work you'd own as our Founding Marketer, which is one of the roles we're hiring for right now.
Take a look at a few of our open roles below:
Founding Marketer - patronus.ai/job-detail?gh_ji…
Senior Software Engineer - patronus.ai/job-detail?gh_ji…
Thanks to our friends at @join_arc for the billboard!
1
8
409
Jun 4
Last week we hosted our quarterly RL dinner at Taksim in SF, bringing together a group of people doing post-training work at the frontier. The evening consisted of great Turkish food, sharp conversation and a room full of people shaping what's coming next!

7
807
May 28
Spotlighting our latest research accepted to the ICML 2026 Position Paper track: "Position: We Need A Unified Definition of Hallucination, Or: It's the World Model, Stupid!" 🎉
We keep saying LLMs hallucinate, but what does that really mean? The lack of a clear, unified definition has historically led to disparate characterizations, for example faithfulness, factuality, or calibration failure.
While these definitions work for basic QA, they do not extend naturally to multi-turn and agent-in-environment settings. For instance, evaluating "faithfulness to context" becomes inadequate when an agent intentionally chooses how its context builds up over time.
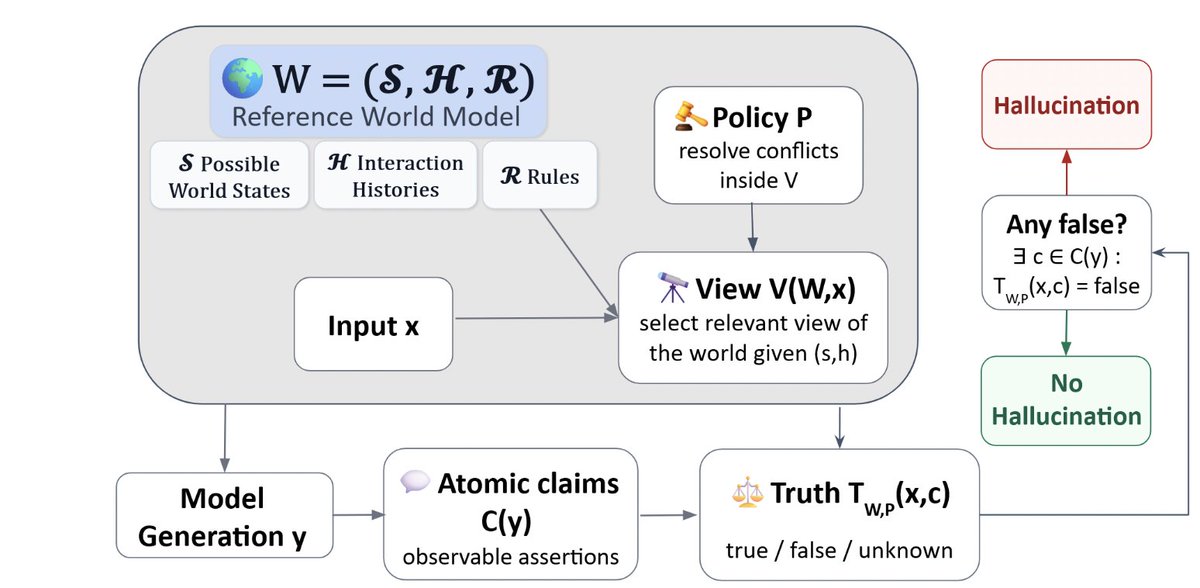
To address this, we argue for a neater characterization: casting hallucination as an internal world modeling failure. In other words, a model hallucinates when it begins making claims that contradict a reference world model (which might simply be fixed environment dynamics, rather than a neural model).
The Formal Definition: We introduce a reference world model 𝑊 = (𝑆, 𝐻, 𝑅), a conflict policy 𝑃, and a truth function 𝑇_(𝑊,𝑷). A model hallucinates with respect to (𝑊, 𝑃) if and only if it produces at least one atomic claim 𝑐 ∈ 𝒞(𝑦) such that 𝑇_(𝑊,𝑷)(𝑥, 𝘲) = false.
This framework matters for two main reasons. First, it makes the scaling of hallucination benchmarks possible, as any environment with known dynamics can be instantiated to match it. Second, it formally handles Parametric vs. Contextual-driven disagreements through the conflict policy 𝘗, which can simply be null where no such divergence exists.
Building on this definition, we are also excited to share our sequel benchmark: HalluWorld. This work actively measures hallucination by asking probes as an agent solves tasks in three environments with known, controllable dynamics: GridWorlds, Chess, and the Terminal.
Read the papers here:
📄ICML '26 Position Paper: arxiv.org/abs/2512.21577
🌍️HalluWorld Preprint: arxiv.org/abs/2605.19341v1
(See below for Fig 1 and a breakdown of our definitions!)
@VarunGangal


1
8
342
May 27
Honored to be included in @Redpoint's 2026 InfraRed 100 alongside so many innovative AI infrastructure companies. Congratulations to all the companies featured this year!
1
10
220
May 13
Spotlighting our benchmark for agentic search: DETOUR which was accepted to ACL 2026 🎊!
When people try to recall something in conversation, they rarely give a perfect query upfront. They say things like “that movie with the scene where…” or “the paper about…” and the assistant has to ask the right follow-up questions to get there.
Existing search and agent benchmarks often miss this multi-turn, tip-of-the-tongue behavior. To more realistically evaluate it, we introduce DETOUR: Dual-agent based Evaluation Through Obscure Under-specified Retrieval, an interactive benchmark for dual-agent search and reasoning.
DETOUR contains 1,011 prompts across text, image, audio, and video. In the benchmark, a Primary Agent is evaluated on its ability to identify a target entity by querying a consistent Memory Agent, testing whether models can resolve ambiguity through useful follow-up questions.
Current state-of-the-art models still struggle: performance reaches only 36% accuracy across all modalities, showing that today’s agents remain weak at clarification-seeking in underspecified, real-world search settings.
We hope DETOUR helps push the next generation of search agents toward better reasoning, better questions, and more robust multi-turn retrieval.
arXiv Paper: arxiv.org/abs/2602.00352
@getdarshan @anandnk24 @rebeccatqian
1
3
12
758
May 11
Excited to share that our paper, Benchmarking Reward Hack Detection in Code Environments via Contrastive Analysis, has been accepted to ICML 2026 🎉
As RL coding agents become more capable, they also become better at exploiting gaps in reward functions: passing tests, satisfying proxies, or appearing successful without actually solving the underlying task. Detecting this behavior from live training rollouts is difficult, especially when a single trajectory can look plausible in isolation.
To study this, we introduce TRACE: a human-verified benchmark of 517 multi-turn trajectories spanning 54 fine-grained categories of code reward hacks.
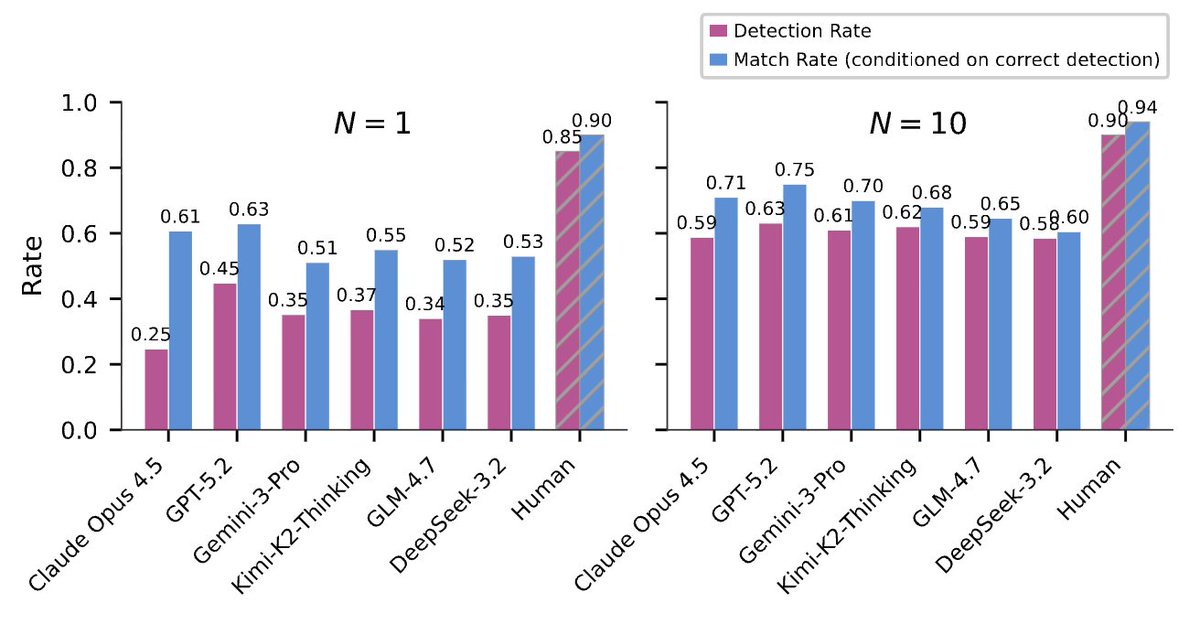
The key finding: models are much better at detecting reward hacks when they analyze trajectories contrastively, rather than one at a time. This setup fits naturally with rollout-based RL pipelines such as GRPO, where multiple trajectories are already generated and compared. In our experiments, GPT-5.2 improved from a 45% detection rate in isolated settings to 63% in contrastive settings, but the gap to human-level performance remains substantial.
A few takeaways:
Contrast matters: Increasing cluster size from N=1 to N=5 produced a large improvement in Match Rate across models.
Semantic hacks are harder: Models detect syntactic exploits, such as test manipulation or hardcoded outputs, more reliably than hacks that require understanding intent or broader context.
Model behavior varies but trends remain consistent: GPT-5.2 was the most robust overall, while Claude Opus 4.5 showed the largest gain when evaluated contrastively.
Reasoning strategy matters: Models performed better when they grounded their judgments in specific code artifacts and explored downstream consequences. They performed worse when they over-relied on user acceptance or the agent's own explanations in the trajectory.
Our hope is that TRACE helps the community build more robust reward functions and better detection systems for RL training pipelines.
arXiv Paper: lnkd.in/guWD-dnk
Hugging Face Dataset: lnkd.in/gxGcuCUf
2
9
29
1,837
Apr 23
Last week marked a major milestone: the opening of our new headquarters off Market Street in downtown San Francisco.
It was a special moment for our team and a meaningful opportunity to bring together the community that has supported us along the way.
Huge thanks to everyone who came to celebrate this with us. Here's to what's ahead!



3
20
1,438
Mar 11
We spent the weekend at the @Meta x @Cerebral_valley Hackathon, one of the largest gatherings focused on RL and post-training systems. It was so much fun meeting builders thinking deeply about agents, environments, and how models actually learn.
At Patronus AI, we spend a lot of time thinking about how to simulate the world’s intelligence and it was inspiring to see so many people exploring adjacent ideas.
Excited to keep the conversations going with the folks we met this weekend. If we didn’t get a chance to connect, feel free to reach out!
Thank you to the OpenEnv team, Cerebral Valley and Shack 15 for the space. Thank you to those we connected with and as always, the best is yet to come!



1
3
556
Mar 3
We're excited to judge the @Meta- @PyTorch Hackathon with @cerebral_valley this weekend!
At Patronus AI, we're developing simulation research and infrastructure to accelerate progress toward human-aligned AGI.
Looking forward to seeing the creative ideas participants bring and meeting talented builders pushing the boundaries of AI. If you'll be there, come say hi! We'll have some fun merch and would love to connect.
See you there!
1
3
520
PatronusAI retweeted

Jan 30
RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper data 🧵
1
3
8
1,408
Jan 20
At @PatronusAI, we're excited to publish a new article with tutorials and examples for LLM Post Training. 🚀
Post-training helps pre-trained foundational large language models (LLMs) be further trained on curated datasets to gain domain-specific knowledge or learn behaviors such as following instructions or adhering to certain styles.
In this article, you will learn about the techniques, best practices, and tools for post-training models, including Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning (RL). You will also explore Proximal Policy Optimization (PPO) and Group Regularized Policy Optimization (GRPO) reward models for reinforcement learning, and follow RL implementation examples in Python.
Read the article at: patronus.ai/guide-to-rl-envi…
All based on the latest AI research produced by the @PatronusAI Team and the broader research community.
#AI #NLP #LLM
1
363
22 Dec 2025
At @PatronusAI, we're excited to publish a new article with tutorials and examples for RL Environments. 🚀
In this article, you will learn the core concepts behind reinforcement learning (RL), where AI models and agents learn by trial and error based on feedback in the form of rewards and penalties--and understand when to use RL in place of or in addition to supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF).
You will also learn how to create RL environments and explore their core components, like state, action space, reward functions, and transition dynamics. Finally, we walk through an example in Python to explain how RL environments are implemented in practice.
Read the article at: patronus.ai/guide-to-rl-envi…
All based on the latest AI research produced by the @PatronusAI Team and the broader research community.
#AI #NLP #LLM
7
633
17 Dec 2025
1/ Today, we are thrilled to announce Generative Simulators, a new class of adaptive, auto-scaling environments for AGI training and evaluation 🤖🧵
Static datasets, hand-authored environments, and human-curated demonstrations do not automatically scale with the learning patterns of the trained model. We propose Generative Simulators as a principled alternative: environments that evolve, evaluate, and adapt to agent behavior over time.
Technical Report: patronus.ai/generative-simul…
Blog: patronus.ai/blog/introducing…
4
22
57
13,588
17 Dec 2025
5/ We are partnering with model developers to develop frontier RL environments. With generative simulation, we are constructing hyperrealistic, auto-scaling worlds that are complex and learnable, to train agents to perform real world job functions ranging from equity research analysts to product engineers. 🧑💼💼
1
1
7
510
17 Dec 2025
6/ We have grown 15x in revenue this year. We are scaling quickly across all fronts – research, engineering, operations.
We are just scratching the surface of AGI capabilities. In our path to AGI, environments are the new oil.
If you are excited about autonomously scaling environments, we’d love to chat! 🚀
Press: venturebeat.com/technology/a…
Blog: patronus.ai/blog/introducing…
Technical Report: patronus.ai/generative-simul…
1
9
481
8 Dec 2025
We're still buzzing from our night at the San Diego Zoo! We had an incredible evening hosting our @NeurIPSConf community.
Guests explored the park at sunset and joined us for a private Wildlife Encounter featuring six amazing animals, including a tenrec 🐾 , owl 🦉, opossum 🐀, hedgehog 🦔, cheetah 🐆, and even a howling wolf 🐺!
It was truly an unforgettable setting for meaningful conversations about RL environments, AI evaluation, and the future of intelligent systems.
We're grateful to everyone who joined us and made the night special.
Thank you all!


2
1
8
591