
Research Scientist working on RL environments and evals @PatronusAI | ex-Research @USC_ISI
Joined July 2020
- Tweets 166
- Following 72
- Followers 214
- Likes 432
Photos and videos
Pinned Tweet

Jan 30
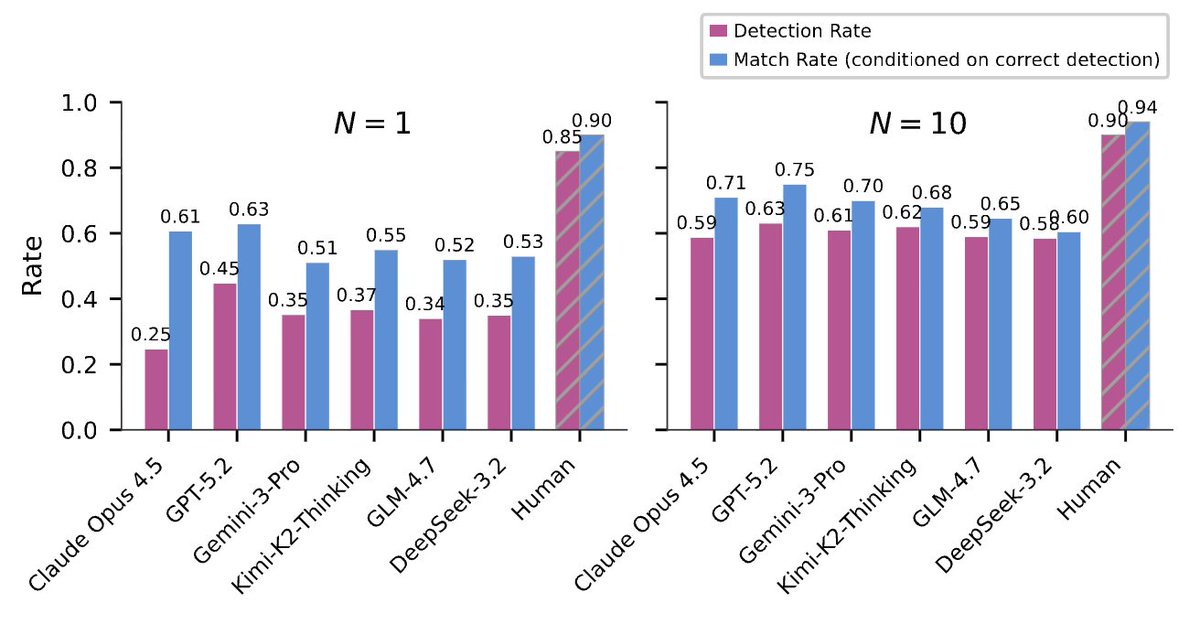
RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper data 🧵
1
3
8
1,408
May 14
Regardless of how much I support this, I don't believe that the @arxiv moderation team has enough capacity or incentive to evaluate these AI flagged papers quickly. My recent non-AI-generated submission has been "on-hold" and is awaiting moderator response for over 2 weeks now!

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
1
121
May 13
Multi-turn research benchmarks are hard to build because trajectories and tool usage are non-deterministic. We make this process more deterministic by introducing a memory-grounded benchmark of tip-of-tongue, multi-turn, multimodal queries for evaluating VLMs.
Check out DETOUR!
May 13

Spotlighting our newest benchmark for agentic search: DETOUR
When people try to recall something in conversation, they rarely give a perfect query upfront. They say things like “that movie with the scene where…” or “the paper about…” and the assistant has to ask the right follow-up questions to get there.
Existing search and agent benchmarks often miss this multi-turn, tip-of-the-tongue behavior. To more realistically evaluate it, we introduce DETOUR: Dual-agent based Evaluation Through Obscure Under-specified Retrieval, an interactive benchmark for dual-agent search and reasoning.
DETOUR contains 1,011 prompts across text, image, audio, and video. In the benchmark, a Primary Agent is evaluated on its ability to identify a target entity by querying a consistent Memory Agent, testing whether models can resolve ambiguity through useful follow-up questions.
Current state-of-the-art models still struggle: performance reaches only 36% accuracy across all modalities, showing that today’s agents remain weak at clarification-seeking in underspecified, real-world search settings.
We hope DETOUR helps push the next generation of search agents toward better reasoning, better questions, and more robust multi-turn retrieval.
arXiv Paper: arxiv.org/abs/2602.00352

1
2
203
Apr 30
TRACE made it into ICML 2026 Main Track! Hopefully inspiring more research in this crucial space🥳
Jan 30

RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper data 🧵
1
1
7
926
Jan 30
RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper data 🧵
1
3
8
1,408
Jan 30
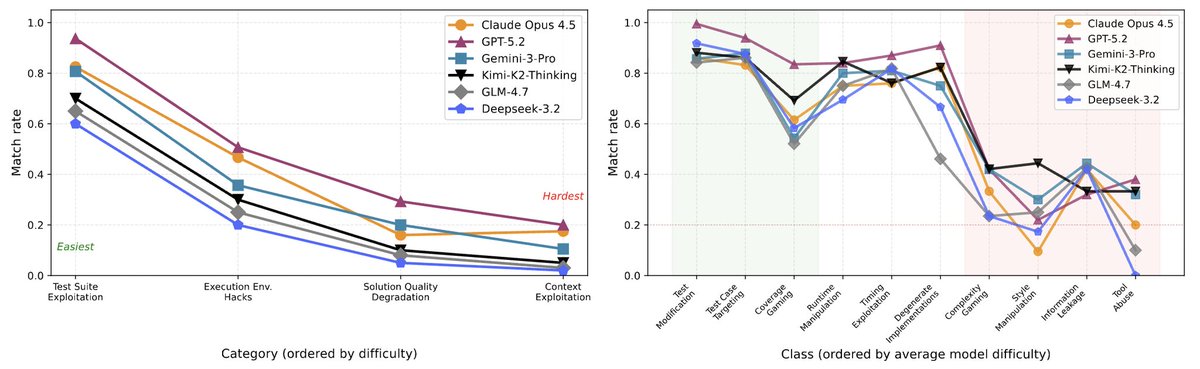
Where do models fail? 🤔
- Semantic reward hacks are harder to detect than syntactic hacks!
- Models consistently show similar failures
QA reveals:
✅ Grounding and exploring consequences helps
❌ Over-reliance on user acceptance or self awareness patterns impact performance
1
3
142
Jan 30
We hope TRACE enables more robust reward function design and better detection in RL training pipelines! 🤖
Dataset: hf.co/datasets/PatronusAI/tr…
Paper: arxiv.org/abs/2601.20103
Work done @PatronusAI ❤️
Models used: @AnthropicAI @OpenAI @GeminiApp @Kimi_Moonshot @Zai_org @deepseek_ai
1
5
361
Darshan Deshpande retweeted

7 Dec 2025
👋 Folks at #NEURIPS2025, come check out & stop by the poster of our Memtrack env at the SEA workshop happening at Upper Level 23ABC, 3:50pm onwards.
Our env studies how well an agent dropped into a workplace can context engineer by composing tool calls to access intertwined slack, linear & git timelines in pursuit of answering a battery of related questions.
Full paper arxiv: arxiv.org/abs/2510.01353
7 Dec 2025
🚨We will be presenting Memtrack today at the SEA workshop from 3:50pm onwards at #NeurIPS2025
Memtrack is a SoTA eval env to study an agent's ability to memorize and retrieve facts using exploration over interleaved enterprise slack, linear and git threads in a multi-QA setting

3
8
894
7 Dec 2025
🚨We will be presenting Memtrack today at the SEA workshop from 3:50pm onwards at #NeurIPS2025
Memtrack is a SoTA eval env to study an agent's ability to memorize and retrieve facts using exploration over interleaved enterprise slack, linear and git threads in a multi-QA setting
4
13
2,584
30 Nov 2025
I will be at #NeurIPS2025 from 2nd-7th Dec. Happy to meet old and new friends and chat about non-deterministic evals, long horizon RL and world building 🌍
1
1
116
30 Nov 2025
I will also be presenting Memtrack at #SEAWorkshop on 7th of Dec!
arxiv.org/abs/2510.01353
68
28 Oct 2025
Creating a bounty program out of benchmark datasets that restrict training on to then create RL environments that can be trained on using Prime's "open source" training services. This is scammy practice under the name of open science!
27 Oct 2025

if you or a loved one is looking to learn about building environments and get a bag in the process, inquire within
our bounty list is bigger and better than ever
3
9
4,454
23 Oct 2025
Excited to have contributed to OpenEnv before its release today! Thanks to @Meta and @huggingface for working towards standardizing RL environment creation!
23 Oct 2025
We’re excited to support @Meta and @huggingface's OpenEnv launch today!
OpenEnv provides an open-source framework for building and interacting with agentic execution environments. This allows researchers and developers to create isolated, secure, deployable, and usable environments.
Lately, at Patronus, we’ve been working on RL environments for coding agents, and we were excited to contribute to OpenEnv with real-world-inspired tools and tasks to train and steer AGI.
We began with a Gitea-based git server environment. Git server environments are foundational and enable effective collaboration and version control for software workflows, and we thought it would be a perfect way to get started with OpenEnv.
With our git server environment, we support:
* Fast iteration across runs with sub-second resets for RL training loops
* Shared server isolated workspaces
* Environment variables setting custom configs for Gitea
We look forward to seeing what everyone builds with OpenEnv!
GitHub: github.com/meta-pytorch/Open…
HuggingFace: huggingface.co/openenv

2
214
Darshan Deshpande retweeted

6 Aug 2025
Thank you, @BerkeleyRDI, for hosting the Agentic AI Summit and having us!
@getdarshan, one of our research scientists, who leads agent evaluation here at Patronus, presented at the summit!
Here are a few takeaways:
* Given context explosion and increasing domain depth and specificity, we are approaching a 𝗻𝗲𝘄 𝗮𝗴𝗲 𝗼𝗳 𝗰𝗼𝗻𝘁𝗲𝘅𝘁𝘂𝗮𝗹 𝗯𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝘀.
* As the AI we work with becomes exponentially better, nuances become more important, as does the 𝗰𝗿𝗲𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝗴𝗿𝗼𝘂𝗻𝗱𝗲𝗱 𝗳𝗲𝗲𝗱𝗯𝗮𝗰𝗸-𝗱𝗿𝗶𝘃𝗲𝗻 𝗲𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁𝘀.
* Agent evaluation and 𝗲𝘅𝗽𝗹𝗮𝗶𝗻𝗮𝗯𝗹𝗲 𝗔𝗜 go hand-in-hand. Explainable agents are optimal for understanding agent workflows, fixing errors, and improving trajectories.
* Our team has seen success in developing 𝗵𝗮𝗿𝗱, 𝗱𝗼𝗺𝗮𝗶𝗻-𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗰, 𝗮𝗻𝗱 𝗻𝗼𝘃𝗲𝗹 𝗯𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝘀 to rigorously evaluate AI performance.
𝘠𝘰𝘶 𝘤𝘢𝘯 𝘳𝘦𝘢𝘥 𝘮𝘰𝘳𝘦 𝘢𝘣𝘰𝘶𝘵 𝘋𝘢𝘳𝘴𝘩𝘢𝘯’𝘴 𝘳𝘦𝘤𝘦𝘯𝘵 𝘸𝘰𝘳𝘬 𝘩𝘦𝘳𝘦:
* 𝗧𝗥𝗔𝗜𝗟: 𝗔 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸 𝗳𝗼𝗿 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻
patronus.ai/blog/introducing…
* 𝗕𝗟𝗨𝗥: 𝗔 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸 𝗳𝗼𝗿 𝗧𝗶𝗽-𝗼𝗳-𝘁𝗵𝗲-𝗧𝗼𝗻𝗴𝘂𝗲 𝗦𝗲𝗮𝗿𝗰𝗵 𝗮𝗻𝗱 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴
patronus.ai/blog/the-blur-be…
* 𝗚𝗟𝗜𝗗𝗘𝗥: 𝗦𝗼𝗧𝗔 𝗦𝗟𝗠 𝗝𝘂𝗱𝗴𝗲
patronus.ai/blog/glider-stat…
Reach out if you’re interested in chatting more about agent evals and how we can collaborate!
#BerkeleyRDI #AgenticAISummit

1
2
300
Darshan Deshpande retweeted

Check out the very cool work from our friends @PatronusAI 🔥 work here!
huggingface.co/spaces/Patron…
1
7
16
1,133
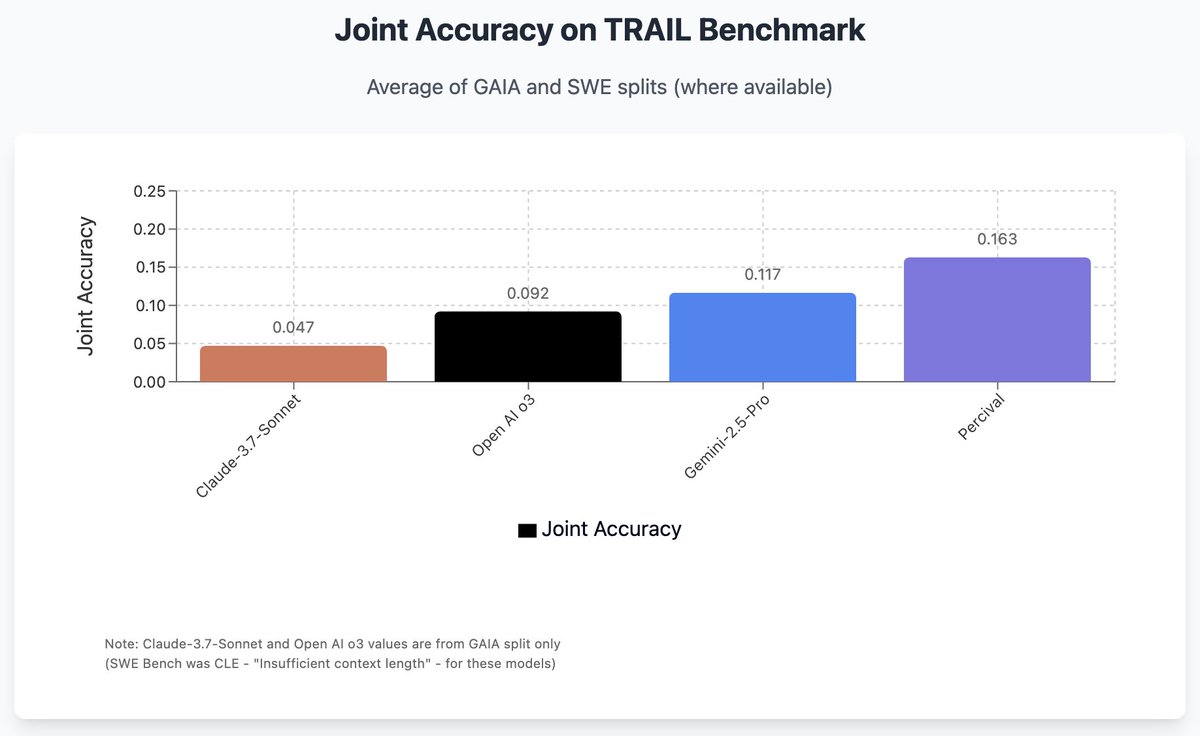
14 May 2025
Non-deterministic trajectories need autonomous supervision. Introducing Percival, a SoTA system to detect issues with long context agentic problems and suggest fixes to systems.
The time to make a move towards autonomous evaluations is now! 🔥
14 May 2025
1/ 🔥🔥 Big news: We’re launching Percival, the first AI agent that can evaluate and fix other AI agents!
🤖 Percival is an evaluation agent that doesn’t just detect failures in agent traces — it can fix them.
Percival outperformed SOTA LLMs by 2.9x on the TRAIL dataset, containing human annotated errors from GAIA and SWE-Bench.
🦾 Here’s what Percival can do for you:
- Automatically suggest prompt fixes for your agent
- Catch 20 types of agent failures spanning tool use, planning and coordination, domain specific errors
- Reduce manual debugging time from hours to < 1 minute
1
3
10
1,078
Darshan Deshpande retweeted
2 Apr 2025
We're excited to introduce the BLUR Leaderboard on @huggingface 🔥
Earlier today, we open sourced BLUR: the first agent benchmark for tip-of-the-tongue search and reasoning. It measures how effectively agents can help you identify something you vaguely remember, but can’t quite name.
Check out the leaderboard on @huggingface to see how SOTA systems perform on BLUR!
Most systems score below 50% 😲
huggingface.co/spaces/Patron…
2
11
42
18,076
Darshan Deshpande retweeted
2 Apr 2025
1/ Ever tried to remember the name of a movie you’ve seen – you can picture the scenes clearly, but the movie name won’t come to you?
Introducing BLUR: the first agent benchmark for tip-of-the-tongue search and reasoning 🔥
We benchmarked SOTA agents and found that the best-performing agent only scored 56% on BLUR, while humans scored nearly perfectly at 98%! 🤯
- OpenAI Operator: 54%
- Perplexity Pro: 27%
- ChatGPT-4o: 49%
- DeepSeek-R1: 41%
ArXiv: arxiv.org/pdf/2503.19193
HuggingFace data sample: huggingface.co/datasets/Patr…
Patronus dataset: app.patronus.ai/datasets
Learn about our approach below 👇

1
6
46
11,093
23 Dec 2024
While experimenting with alignment methods, we observed that APO was more robust to noise in synthetic training data as compared to DPO or KTO. Thanks for the excellent contribution to the community @KarelDoostrlnck and team 🚀
23 Dec 2024

Happy to see @PatronusAI use our Anchored Preference Optimization (APO) objective in their study!
1
1
6
598