
Dean coding in Perl. Probably won't follow you. This account won't tweet or retweet politics.
Joined September 2011
- Tweets 6,399
- Following 103
- Followers 288
- Likes 2,541
50 Photos and videos














Jun 13
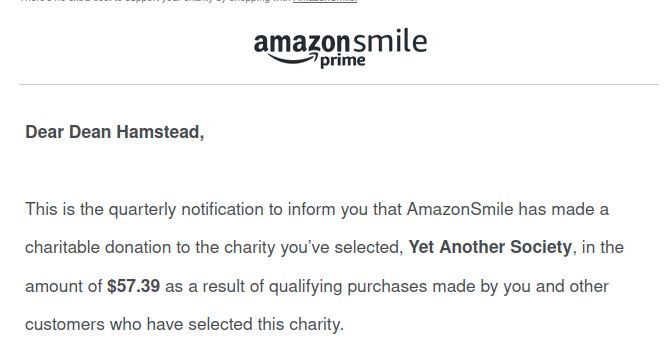
I've been playing with timescaledb (and collectd) which has proved to be a very performant combination in my home lab.
I did a write up and hope people can either learn from it or tell me where I have gone horribly wrong
dev.to/perldean/using-timesc…
#postgresql #sre #timescaledb
11
Dean Hamstead retweeted

Jun 9
AN MIT RESEARCHER PROVED GIT ISN'T HARD BECAUSE YOU'RE BAD AT IT -- IT'S HARD BECAUSE IT WAS DESIGNED THAT WAY
27 minutes from a PhD researcher in MIT's Software Design Group, using actual design theory to show why the tool that confuses everyone confuses everyone for a reason.
-> The moment it lands, years of feeling stupid evaporate. The gap between what git's commands say and what they actually do was never in your head. It's baked into the tool.
He maps the difference between what you think a command does and what git really does underneath. Once you see that gap, the confusion finally has a name and it stops being yours to carry.
Struggling with git was never a skills issue -> it's a design issue, and knowing where the model lies to you is what turns panic into control. And as AI agents fire off commits and rebases you didn't write, the person who understands where git misleads is the one who untangles the mess.
You were never bad at git. You were just never shown where it was built to trip you.
Bookmark & Watch it today ↓
Jun 8

MICROSOFT PUT THE ENTIRE SOURCE CODE OF WINDOWS INTO A SINGLE GIT REPO -- 300 GIGABYTES, 3.5 MILLION FILES AND MADE IT CLONE IN SECONDS
31 minutes from the Microsoft engineer who actually did it, bending the tool you use for a 50-file side project to hold the biggest codebase on the planet.
-> The moment it lands, every excuse dies. You've heard "Git doesn't scale, use something else" your whole career. They ran git status on the largest repo alive and it came back instantly.
The secret wasn't a different tool. It was understanding what git actually stores and realizing you never need the whole thing on disk. Pull only the files you touch. Ignore the 3.4 million you never will.
Knowing the commands was never the ceiling -> understanding how git stores and moves things is what lets you do what everyone swears is impossible. And as AI agents spin up repos that balloon overnight, knowing how git scales is what keeps you from drowning in your own history.
Everyone treats git like it maxes out at a hobby project. One team quietly proved it can hold an operating system.
Bookmark & Watch it today ↓
26
57
452
136,290
May 30
This may come as a shock to many business leaders, but you can run LLM's on your own GPU infra and not pay per token.
14
May 20
This is fun. One click and your company is gone. In this case a supposed "all-in-one" cloud provider that is apparently all-in-gcp not actually in them?
May 20

Do you know what's crazy about Google deleting Railway's account accidentally?
It's not the first time they've done it.

20
May 19
True.

Normal people use AI for help.
Developers use AI at 3AM like unpaid farm workers.

12
May 17
Indeed.
May 16

Layoff has zero correlation with AI. The reason usually is excessive hiring in the past. When Elon trimmed Twitter, that was the start. Companies waited to see the results and then floodgates opened.
What further gave boost to that decision was higher interest rates. Stockholders stopped being OK with share grants at their expense.
But many of these laid off employees have a big struggle ahead. This is because past employers did not make them do real work. So such employees have lost touch.
17
Dean Hamstead retweeted

4 Jun 2025
Good post from @balajis on the "verification gap".
You could see it as there being two modes in creation. Borrowing GAN terminology:
1) generation and
2) discrimination.
e.g. painting - you make a brush stroke (1) and then you look for a while to see if you improved the painting (2). these two stages are interspersed in pretty much all creative work.
Second point. Discrimination can be computationally very hard.
- images are by far the easiest. e.g. image generator teams can create giant grids of results to decide if one image is better than the other. thank you to the giant GPU in your brain built for processing images very fast.
- text is much harder. it is skimmable, but you have to read, it is semantic, discrete and precise so you also have to reason (esp in e.g. code).
- audio is maybe even harder still imo, because it force a time axis so it's not even skimmable. you're forced to spend serial compute and can't parallelize it at all.
You could say that in coding LLMs have collapsed (1) to ~instant, but have done very little to address (2). A person still has to stare at the results and discriminate if they are good. This is my major criticism of LLM coding in that they casually spit out *way* too much code per query at arbitrary complexity, pretending there is no stage 2. Getting that much code is bad and scary. Instead, the LLM has to actively work with you to break down problems into little incremental steps, each more easily verifiable. It has to anticipate the computational work of (2) and reduce it as much as possible. It has to really care.
This leads me to probably the biggest misunderstanding non-coders have about coding. They think that coding is about writing the code (1). It's not. It's about staring at the code (2). Loading it all into your working memory. Pacing back and forth. Thinking through all the edge cases. If you catch me at a random point while I'm "programming", I'm probably just staring at the screen and, if interrupted, really mad because it is so computationally strenuous. If we only get much faster 1, but we don't also reduce 2 (which is most of the time!), then clearly the overall speed of coding won't improve (see Amdahl's law).

AI PROMPTING → AI VERIFYING
AI prompting scales, because prompting is just typing.
But AI verifying doesn’t scale, because verifying AI output involves much more than just typing.
Sometimes you can verify by eye, which is why AI is great for frontend, images, and video. But for anything subtle, you need to read the code or text deeply — and that means knowing the topic well enough to correct the AI.
Researchers are well aware of this, which is why there’s so much work on evals and hallucination.
However, the concept of verification as the bottleneck for AI users is under-discussed. Yes, you can try formal verification, or critic models where one AI checks another, or other techniques. But to even be aware of the issue as a first class problem is half the battle.
For users: AI verifying is as important as AI prompting.
134
536
4,428
844,837
May 16
Big Pickle is a respectable model. It's been enjoyable to experiment with. It is enthusiastic and capable, but needs careful guidance and unit tests.
14

💥 Introducing "Dirty Frag"
A universal Linux LPE chaining two vulns in xfrm-ESP and RxRPC. A successor class to Dirty Pipe & Copy Fail.
No race, no panic on failure, fully deterministic. ~9 years latent.
Ubuntu / RHEL / Fedora / openSUSE / CentOS / AlmaLinux, and more.
Even if you've applied the "Copy Fail" mitigation, your Linux is still vulnerable to "Dirty Frag". Apply the Dirty Frag mitigation.
Details:
dirtyfrag.io
41
703
2,088
531,846
Dean Hamstead retweeted

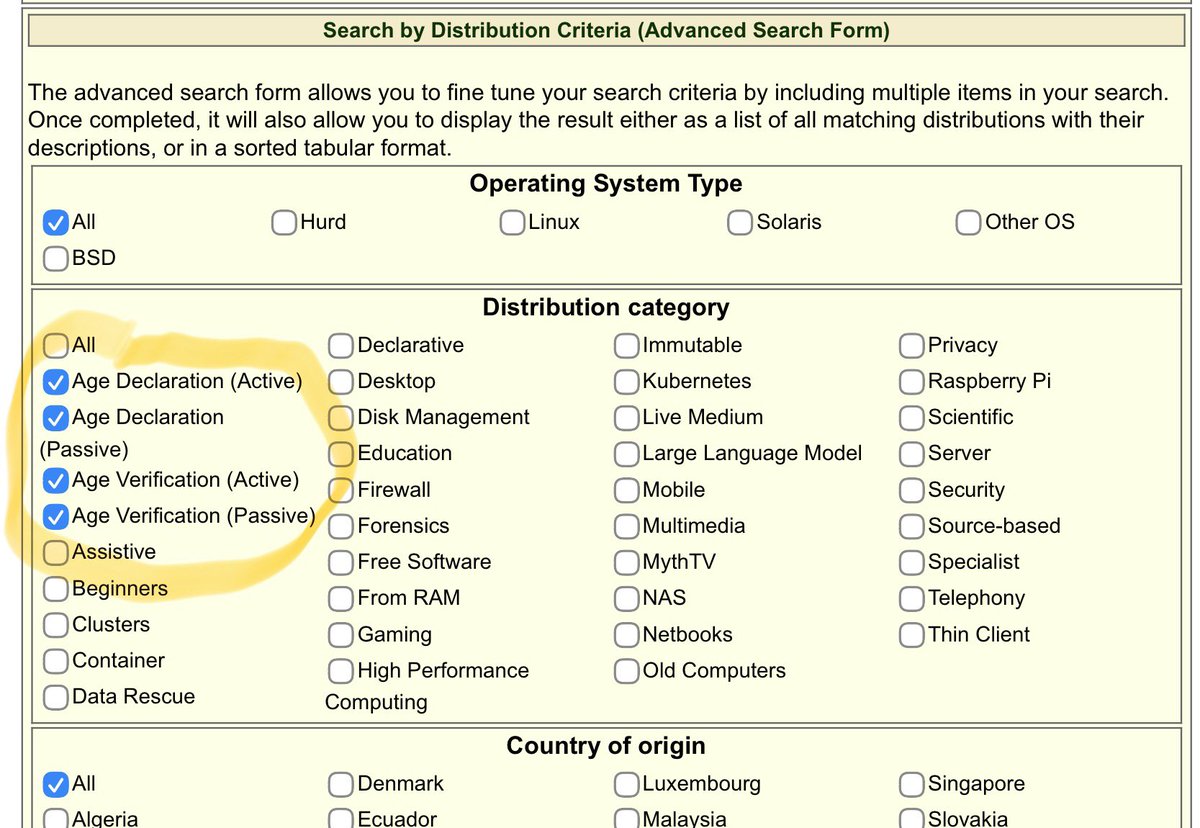
DistroWatch has added “Age Verification” options to their advanced Linux & BSD distribution search page.
At the moment there are only two with confirmed, implemented Age Verification (MidnightBSD, and the Brazilian “BigLinux”).
distrowatch.com/search.php#a…
13
47
378
9,570
Dean Hamstead retweeted

I don't want a new GitHub. I want a new source control platform.
One that highlights elements from new version control systems like jj.
One that allows developers to force push without messing up reviews.
One that works with mono repos, not against them.
May 4

What is unclear to me is what people actually want some new GitHub to be.
To me, the biggest challenge GitHub has always had is that it is trying to serve two very different worlds. On one side, it is a social network around code and open source. On the other, it is infrastructure for companies building software.
Those two groups operate almost in opposite ways, so the product has always been some kind of compromise between them. Because those users are so far apart, it can fail both of them in different ways.
Inside a company, you mostly just want to review and merge code. You are not discovering new code, and you are probably not forking things. You may have a monorepo, a known team, and a trusted environment. What you want from GitHub is efficiency and safety: PRs, review, ownership, CI, Actions, tests, security checks, and a clear path to getting code merged.
Open source is different. It is much more public and much less trusted. You need better ways to figure out who is contributing, what to accept, how to manage the project, how to handle issues, and how to maintain trust with people you may not know.
So are people asking for a new open source code hosting and social network, or do they want better private infrastructure for software teams? Or both?
I would never choose to build both from the start. I think every product gets better when it is more purpose-built and designed around a specific need.
You could maybe imagine some nested model, where private repos have a much simpler and more focused mode, but you can still exit that mode and browse around the public space.
6
1
19
5,481
May 4
Carmack and it isn't close.

4 engineers who shaped modern software. You get 1 as your mentor for a year. Pick one.
-DHH
(creator of Ruby on Rails, CTO of 37signals)
-John Carmack
(creator of Doom, ex-CTO Oculus)
-Linus Torvalds
(creator of Linux & Git)
-Guillermo Rauch
(CEO of Vercel, creator of Next.js)
Who are you picking, and why?
15
Dean Hamstead retweeted

May 3
Manager: We use agile.
Me: Be honest
Manager: We implemented SCRUM for our tasks.
Me: I said 'honest'.
Manager: We cut Waterfall into sprints.
Me: Thank you
5
43
402
20,332
Apr 29
Just cut it back to the 10% people need.

17

i've been using @SaplingSCM for 2 weeks now on a private git repo. if you've ever heard folks on the React team/engs at Meta talk about stacked diffs, or the magical `hg absorb` command, you can try it yourself too even if you're not using mercurial! sapling-scm.com/docs/introdu…
2
6
43
14,005
Dean Hamstead retweeted

Jan 9
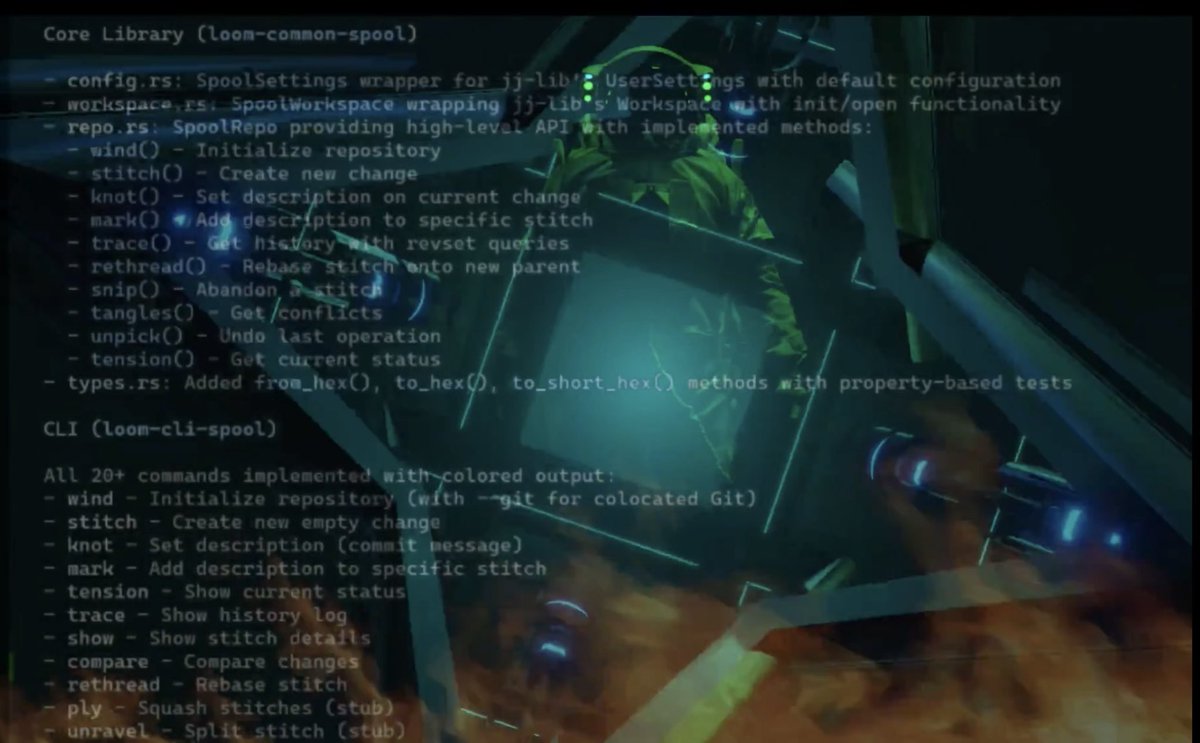
we now have our own source control (based off jj initially but likely to diverge) called “spool”
tired: git beads
wired: stacked diffs and anything an agent orchestrator needs to do whatever it needs to do backed by a custom filesystem.
next milestone: perhaps the worlds first JJ source code management host (that is self hosted). i’m going for full sync protocol - something the JJ folks haven’t done yet
then we move onto monoke / piper topics
imagine having the google/meta engineering system (the good bits) but self hosted on your own infrastructure and designed for agents; not humans.
the world stopped dreaming when phabricator shut down. it’s time to do phabricator v2.0.
15
7
112
8,638
Dean Hamstead retweeted

Apr 29
GitHub was great in 2008. Now it holds developers back.
It made us accept the same workflows for almost two decades and stop questioning if there’s a better way to build software.
There is.
It’s time for better alternatives.
Apr 28

Ghostty is leaving GitHub. I'm GitHub user 1299, joined Feb 2008. I've visited GitHub almost every single day for over 18 years. It's never been a question for me where I'd put my projects: always GitHub. I'm super sad to say this, but its time to go. mitchellh.com/writing/ghostt…
2
2
12
2,362
Dean Hamstead retweeted

Apr 28
Ghostty is leaving GitHub. I'm GitHub user 1299, joined Feb 2008. I've visited GitHub almost every single day for over 18 years. It's never been a question for me where I'd put my projects: always GitHub. I'm super sad to say this, but its time to go. mitchellh.com/writing/ghostt…
548
1,607
16,748
2,913,836
Apr 27
The AGPL is license you should actively avoid.
You don't need it's compliance burdens in your life.
10