
Principal Data Scientist at Endava. Kaggle 2xGM. GDE. Engineer. Christian. Father. Passionate about Literature, History and Mountains. Opinions my own.
- Tweets 3,160
- Following 328
- Followers 2,062
- Likes 2,391







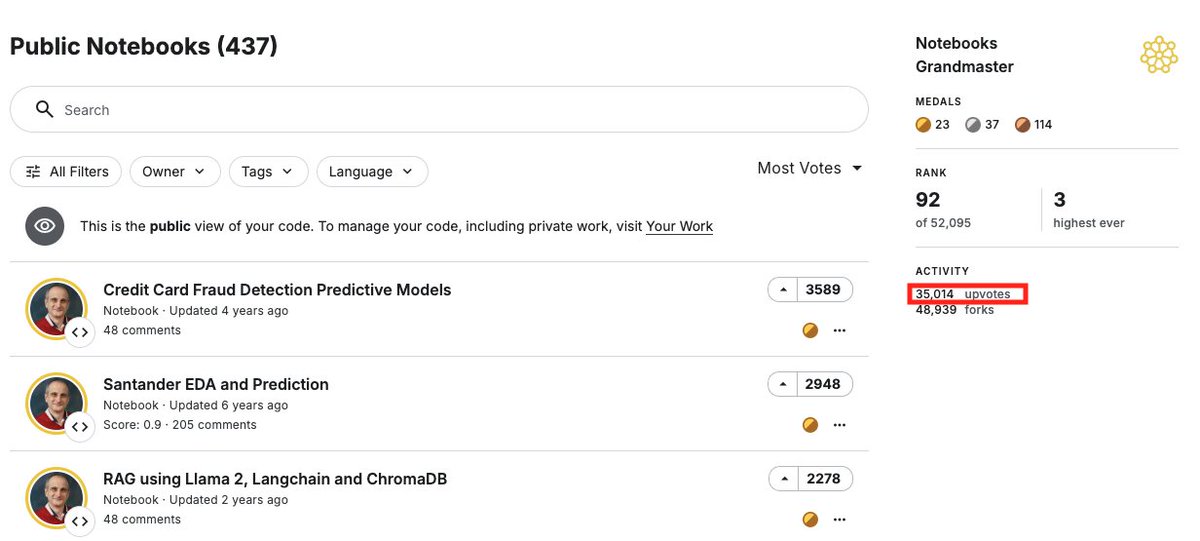






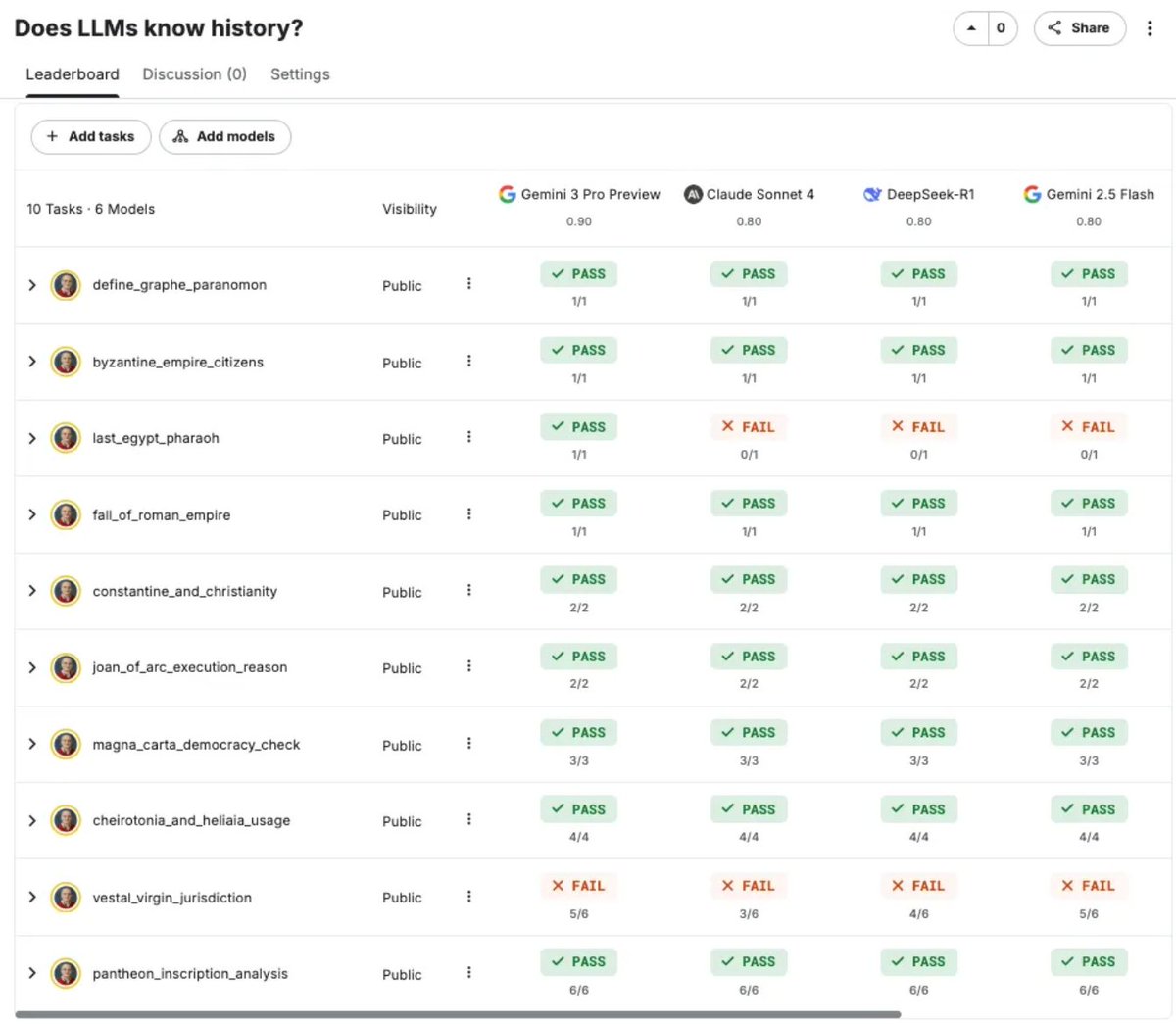
ALT A screenshot of a leaderboard titled "Does LLMs know history?" comparing the performance of four AI models across ten historical tasks. The models—Gemini 3 Pro Preview (0.90), Claude Sonnet 4 (0.80), DeepSeek-R1 (0.80), and Gemini 2.5 Flash (0.80)—are displayed in a grid showing "PASS" and "FAIL" results. The tasks cover topics such as the Byzantine Empire, the Roman Empire, and Joan of Arc. Notably, Gemini 3 Pro Preview is the only model to pass the "last_egypt_pharaoh" task, while all four models failed the "vestal_virgin_jurisdiction" challenge. The interface is clean, featuring a white background with green and red status indicators for each task.