
Joined August 2022
- Tweets 193
- Following 212
- Followers 1,212
- Likes 663
57 Photos and videos




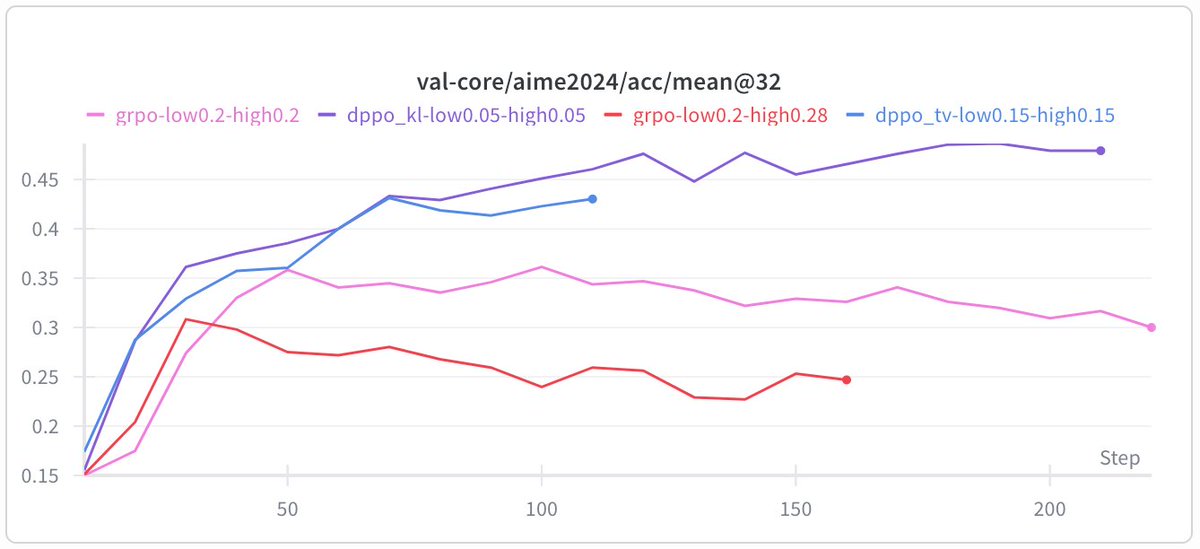
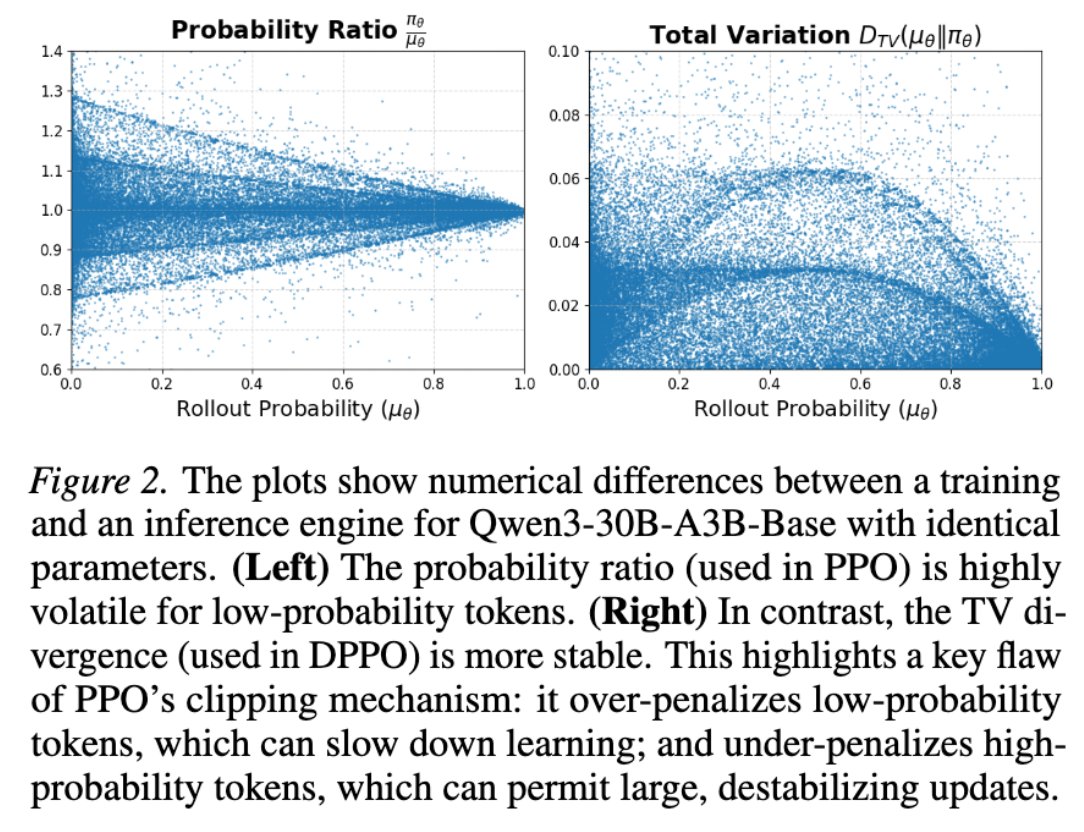
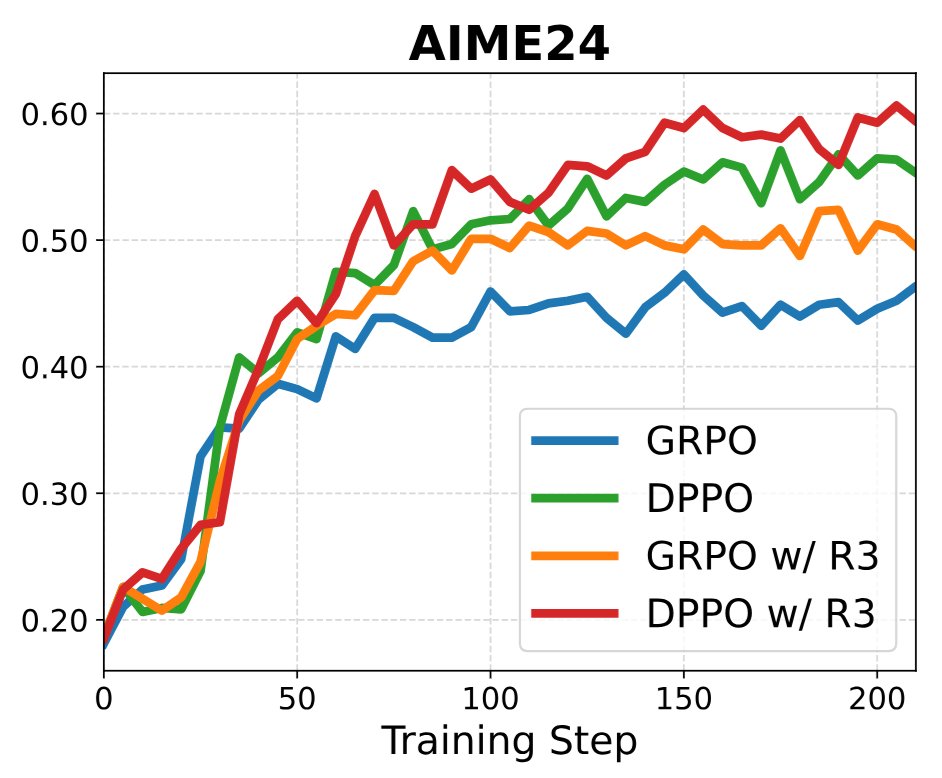
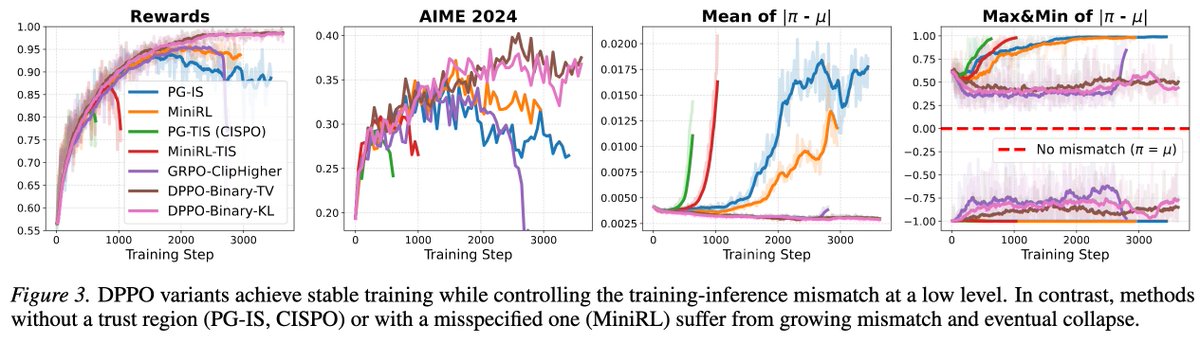


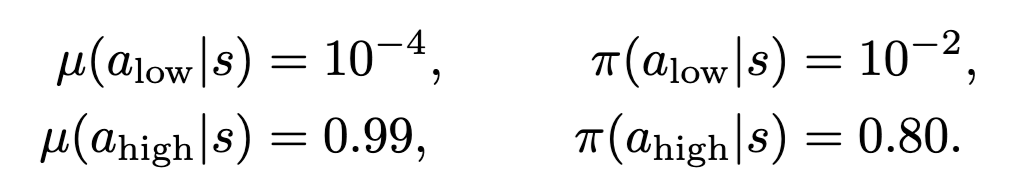
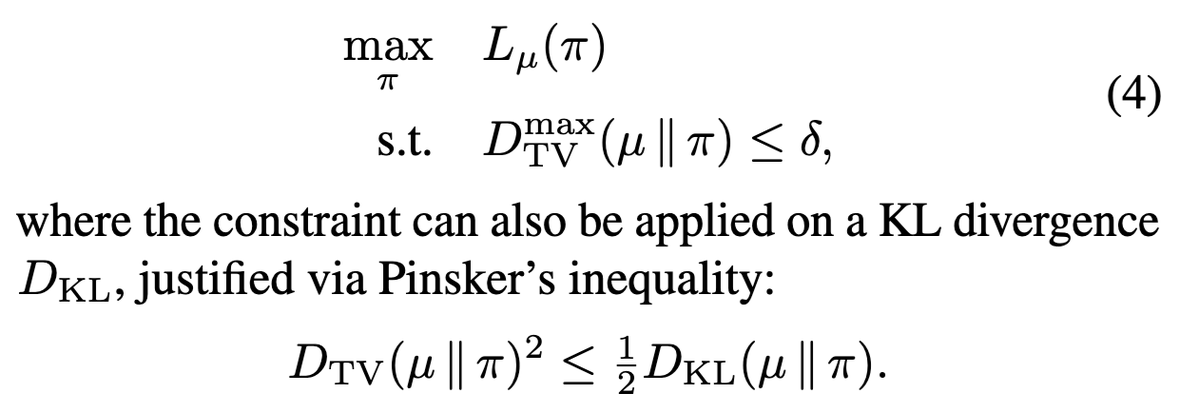
Pinned Tweet

Feb 5
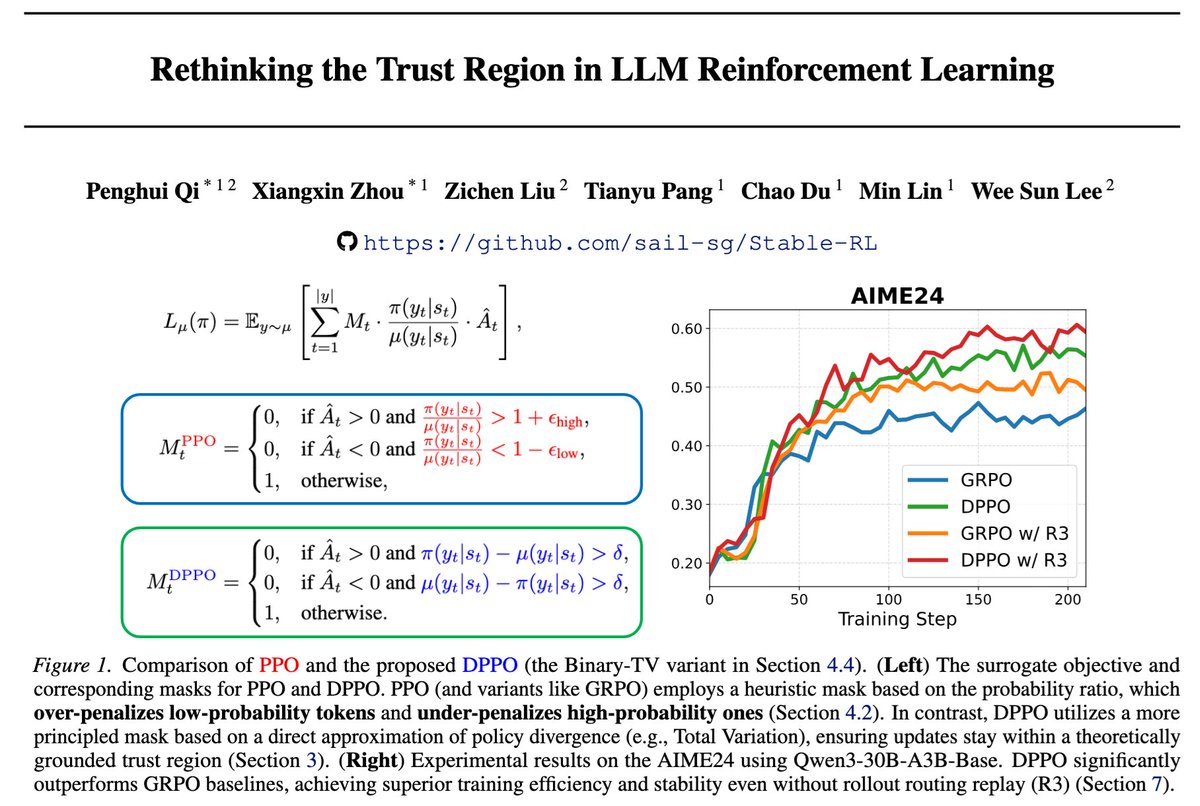
This time we should say goodbye to PPO/GRPO for real 👋
PPO is a great algorithm in classical RL settings. However, it is fundamentally flawed in LLM regime due to the large, long-tailed vocabulary.💔
Checkout our paper for more details👇
13
76
548
47,529
DPPO works better not only in LLM, but also in flow matching! 🚀

🚀 Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
We introduce Flow-DPPO, which replaces PPO-style ratio clipping with a divergence proximal constraint that is structurally inherent to flow models.
🔗arxiv.org/pdf/2606.11025

14
2,174
Penghui Qi retweeted

Jun 11
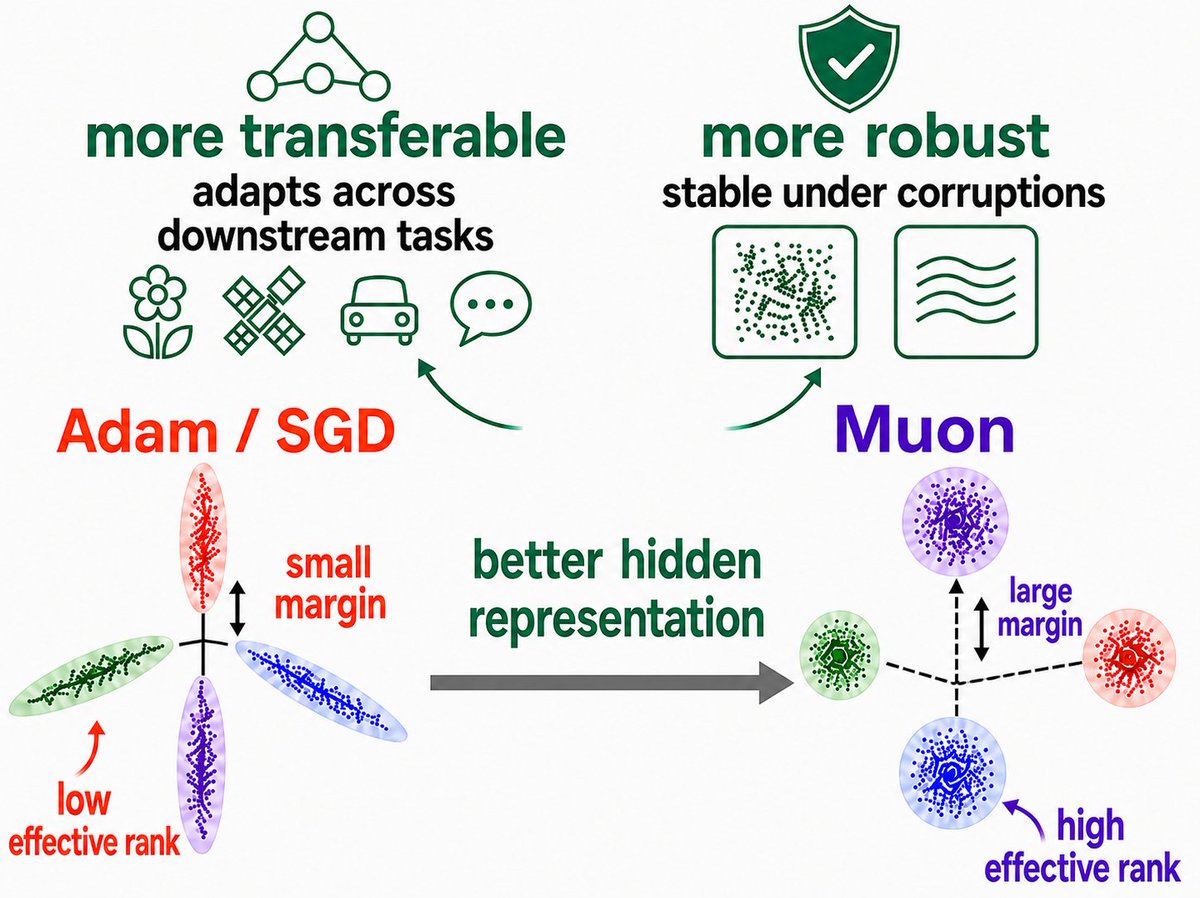
Beyond faster training, does Muon learn better features than Adam?
🚀 Ans: Yes. Muon learns features that are more robust to input corruptions and transfer better to downstream tasks.
This advantage is reflected in hidden states:
1⃣larger logit margins → stronger robustness
2⃣higher effective rank → richer, more transferable representations
Paper Link: arxiv.org/abs/2606.09658
A thread 🧵
1
15
58
45,306
Jun 11
totally agree!🫡
for sure Binary-TV is still not a perfect proxy, but it’s much better than radio-based geometry in llm regime.
for me, Binary-TV is more like a great balance between simplicity and performance.
Jun 10

just thought about this again when DRPO (arxiv.org/abs/2606.09821) released.
while constraining a lower bound doesn't make sense, constraining Binary-TV itself makes a lot of sense.
1
13
1,324
Jun 10
interesting insight! 👍
Let me think of our DPPO algorithm, which outperforms PPO and GRPO due to the same reason: better handling the long-tail tokens 😀
Congrats on the great work!@FengzhuoZhang
7 Oct 2025

Why does Muon outperform Adam—and how?
🚀Answer: Muon Outperforms Adam in Tail-End Associative Memory Learning
Three Key Findings:
> Associative memory parameters are the main beneficiaries of Muon, compared to Adam.
> Muon yields more isotropic weights than Adam.
> In heavy-tailed tasks, Muon significantly improves tail-class learning compared to Adam.
Paper Link:
arxiv.org/pdf/2509.26030
A thread 🧵

1
19
2,294
Penghui Qi retweeted

Jun 10
One intuition behind DRPO: the regularizer itself is not the whole story—the trust-region geometry induced by its gradient is what really matters.
By combining advantage-weighted regularization with DPPO-style geometry, DRPO turns hard mask-based trust regions into a smoother and more robust alternative. 🔥
Jun 9

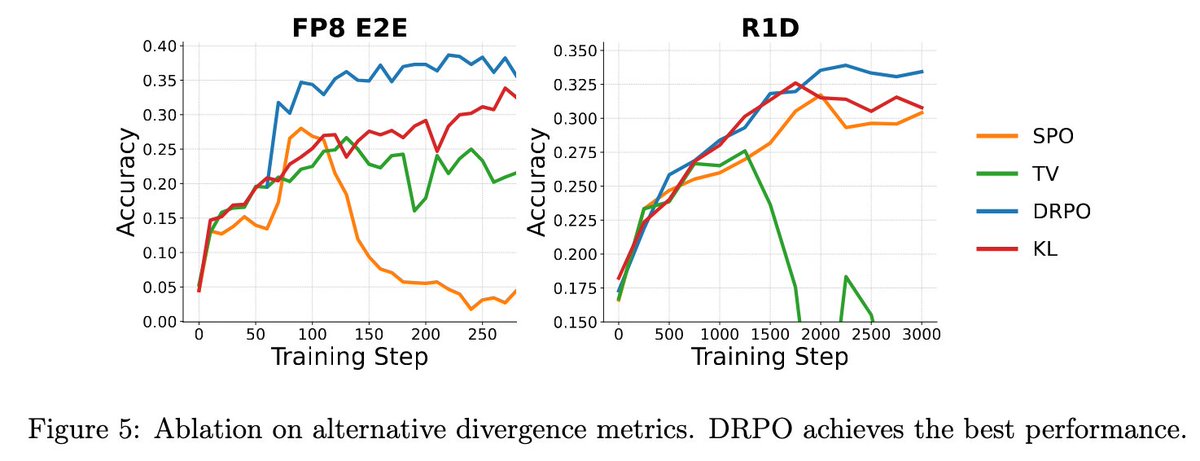
We propose DRPO: a soft version of DPPO🔥
Since PPO, clipping/mask-based trust regions have long outperformed smooth divergence regularization like KL, even though the latter one feels more principled. 👺
We found two missing pieces:👇
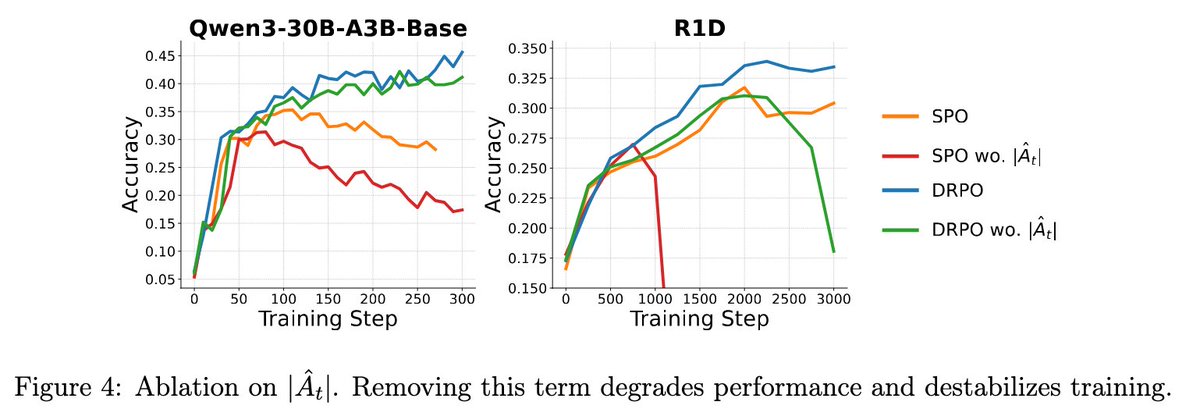
1️⃣ Weight the regularizer by |advantage|
- Otherwise, the trust region geometry changes dynamically and optimization becomes unstable.
2️⃣ Use the right divergence
- What matters is not just “regularization”, but the trust-region geometry induced by the gradient. DPPO-style geometry works much better than PPO-style geometry in LLM.
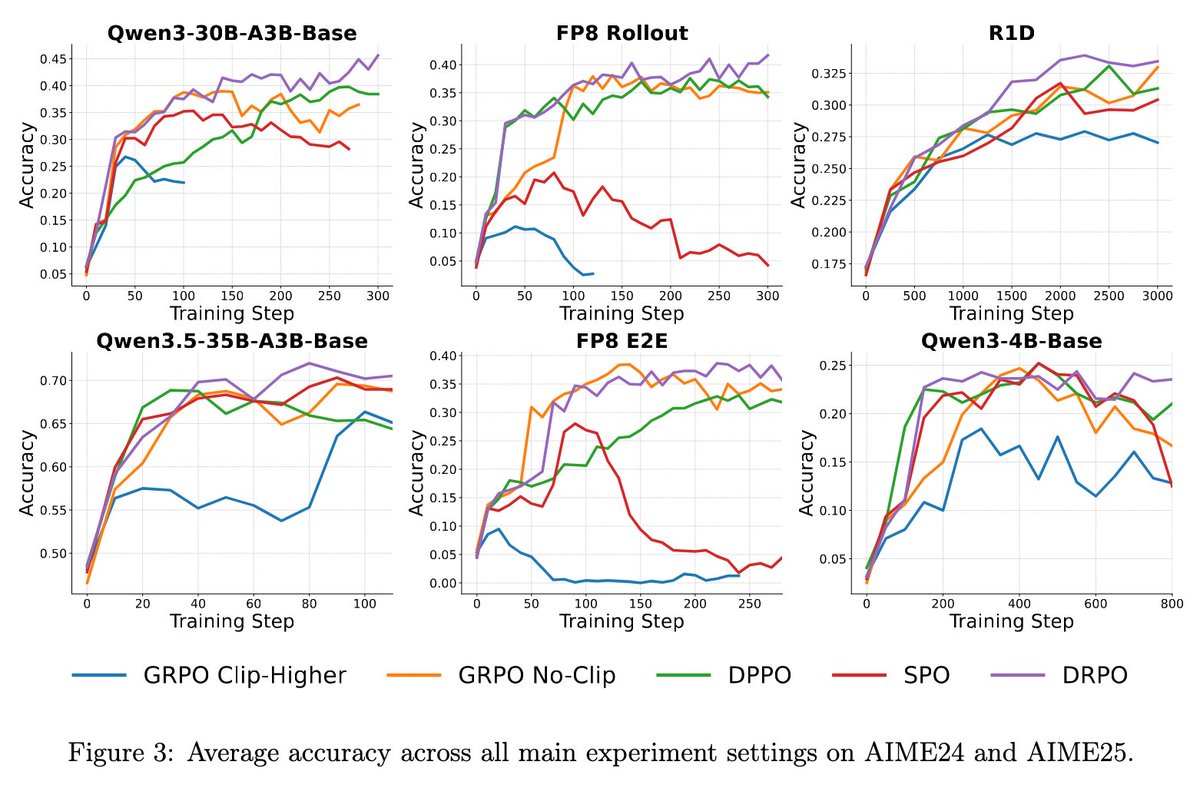
These insights lead to DRPO, which delivers the most robust and best overall performance across algorithms, even outperforming original mask-based DPPO. 🚀
This project is an amazing collaboration with @ExplainMiracles, @NickZhou523786, Wee Sun Lee, Liefeng Bo, @TianyuPang1 . Do follow them if you are interested in this work!
📄 Paper: arxiv.org/pdf/2606.09821
💻 Code: github.com/Tencent-Hunyuan/U…

1
2
13
2,056
Jun 9
It’s always a wonderful experience working with @TianyuPang1 and his amazing team! 🫡
Both DRPO and Flow-DPPO are directly built upon our previous DPPO work 🚀
x.com/QPHutu/status/20194356…
I co-led the DRPO project together with Xiangxin @NickZhou523786 , who also led the Flow-DPPO project.
Xiangxin is an excellent researcher, and one of the best collaborators I have worked with. He is also the co-first author of our FP16 and DPPO work. Follow him if you are interested in these work! 👍
Also, congratulations to @Haonan_Wang_ on releasing the excellent UniRL repo! 🔥
Jun 9

Our latest deliveries:
👨💻 UniRL, an RL infra for unified multimodal models
➕ Two new RL algorithms:
• FlowDPPO for diffusion and flow-matching models
• DRPO for LLMs and VLMs
Check out our repo: github.com/Tencent-Hunyuan/U…
1
1
16
2,720
Jun 9
Thank you for always being the first to share our work, from FP16 to DPPO to DRPO 🫡
Jun 9

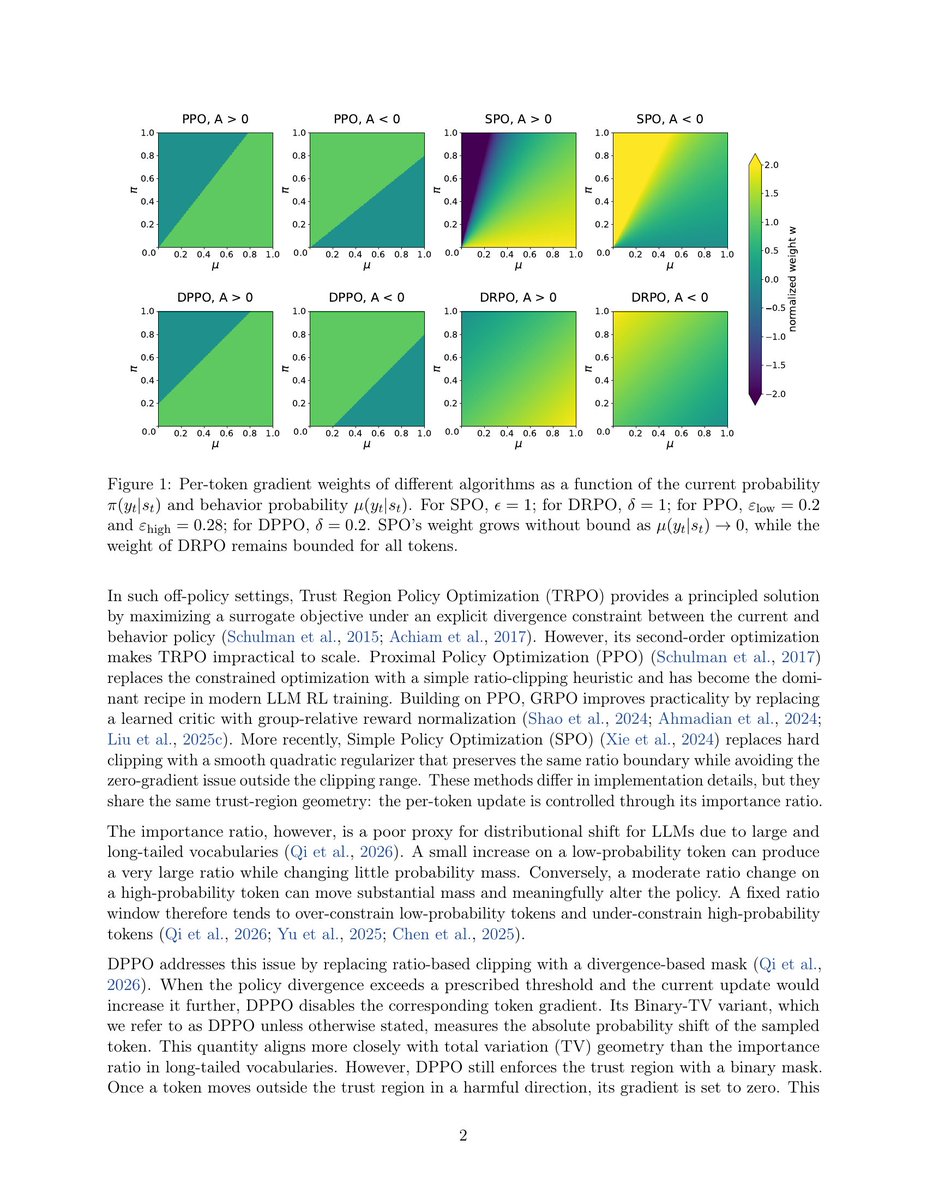
arxiv.org/abs/2606.09821
Soft version of DPPO (arxiv.org/abs/2602.04879, which uses a divergence-based mask instead of ratio-based clipping).

1
29
4,463
Penghui Qi retweeted

Jun 9
🚀Introducing UniRL, an RL infra for unified multimodal models. Together with two new RL algorithms: DRPO and Flow-DPPO.
One RL loop across diffusion/flow matching models, LLMs/VLMs, and unified multimodal models👇
Code: github.com/Tencent-Hunyuan/U…
(yes — U(you)-ni-(need) RL 😉)

8
24
148
22,712
Jun 9
We propose DRPO: a soft version of DPPO🔥
Since PPO, clipping/mask-based trust regions have long outperformed smooth divergence regularization like KL, even though the latter one feels more principled. 👺
We found two missing pieces:👇
1️⃣ Weight the regularizer by |advantage|
- Otherwise, the trust region geometry changes dynamically and optimization becomes unstable.
2️⃣ Use the right divergence
- What matters is not just “regularization”, but the trust-region geometry induced by the gradient. DPPO-style geometry works much better than PPO-style geometry in LLM.
These insights lead to DRPO, which delivers the most robust and best overall performance across algorithms, even outperforming original mask-based DPPO. 🚀
This project is an amazing collaboration with @ExplainMiracles, @NickZhou523786, Wee Sun Lee, Liefeng Bo, @TianyuPang1 . Do follow them if you are interested in this work!
📄 Paper: arxiv.org/pdf/2606.09821
💻 Code: github.com/Tencent-Hunyuan/U…
3
27
152
10,791
Jun 9
Our work is largely motivated by DPPO and SPO. A comparison table with PPO, SPO and DPPO.
1
2
11
3,350
Jun 9
Our prior work on DPPO:
x.com/QPHutu/status/20194356…
Feb 5
This time we should say goodbye to PPO/GRPO for real 👋
PPO is a great algorithm in classical RL settings. However, it is fundamentally flawed in LLM regime due to the large, long-tailed vocabulary.💔
Checkout our paper for more details👇
1
6
411
May 22
btw, DPPO paper has been accepted by ICML 2026, and I will present this paper in person at Seoul.
welcome any connections!
May 22
Really a nice note on DPPO, covering every key message with very clear takeaways. 👇
If anyone want to know DPPO quickly without reading the tedious paper, I strongly recommand you to read this blog first!
Thank @pradheepraop for this awesome summary 🙏
2
6
84
20,761
May 22
Really a nice note on DPPO, covering every key message with very clear takeaways. 👇
If anyone want to know DPPO quickly without reading the tedious paper, I strongly recommand you to read this blog first!
Thank @pradheepraop for this awesome summary 🙏
May 21

really enjoyed reading dppo.
the key statement imo:
ppo clips the sampled action ratio, but the trust-region violation actually comes from how far the full policy distribution moves.
wrote a short summary with intuition derivations (math mode).
thread below ↓
pradheep.dev/summary/dppo
1
15
18,155
Mar 30
Interesting results! 👍
Let me put more on the precision comparison between BF16 and FP16, on RLHF task (using a reward model) 👇
The numerical stability really matters a lot in RL👀
Find more in our FP16 paper: arxiv.org/pdf/2510.26788
Mar 28

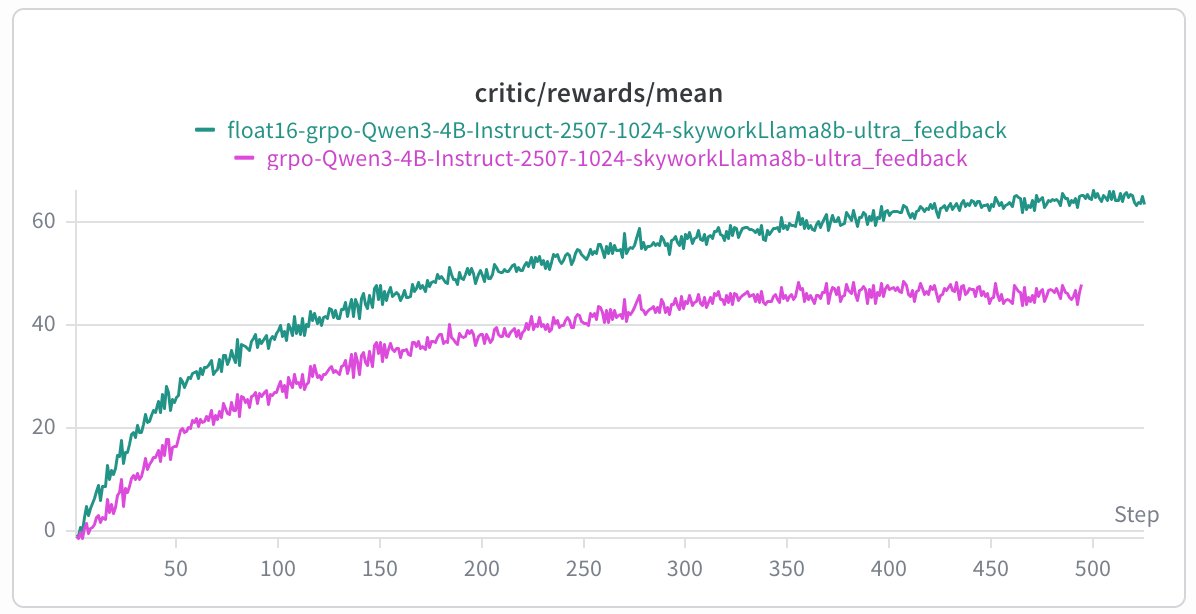
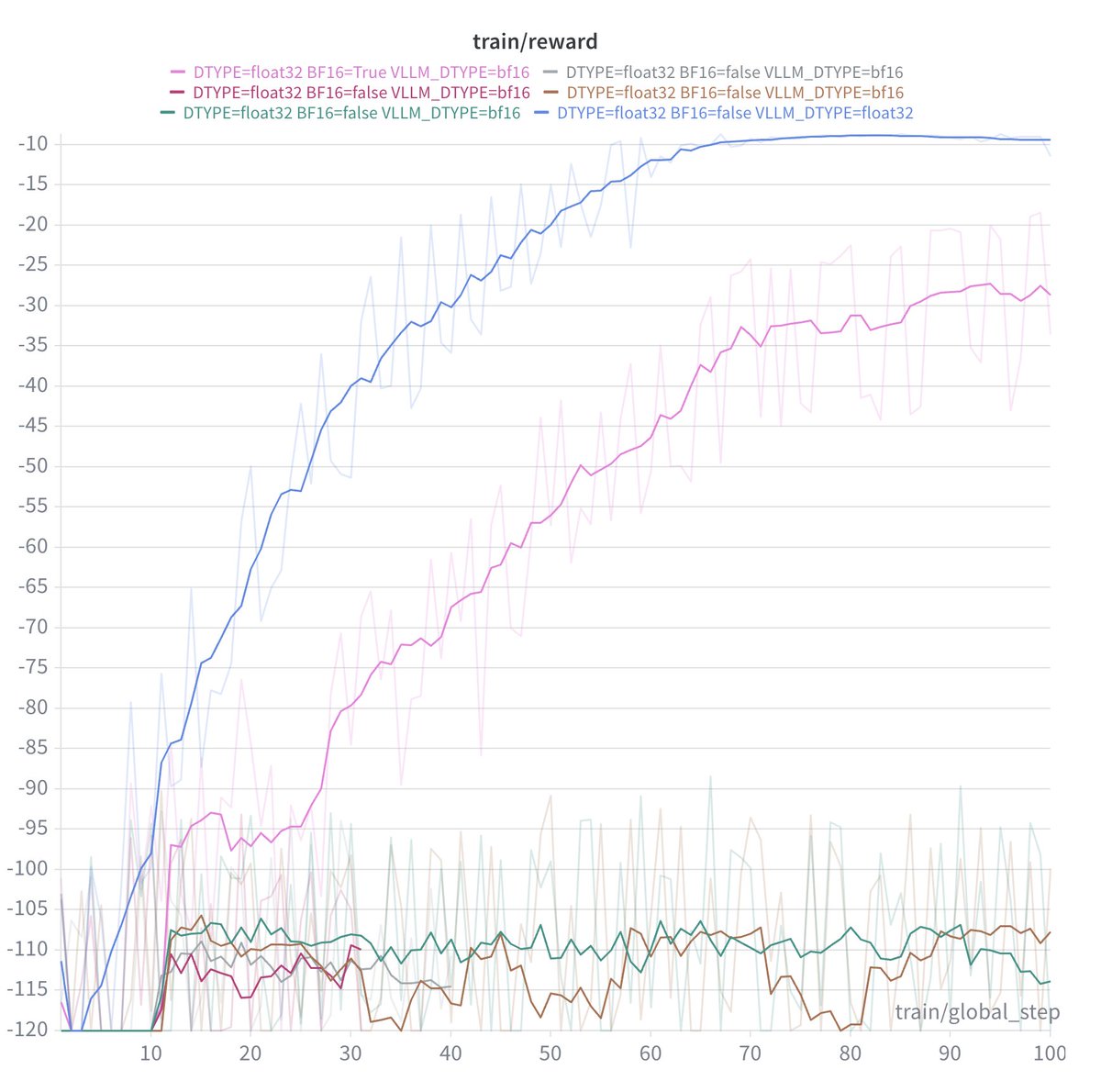
Been going down a massive rabbit hole with numerical stability in RL training lately.🕵️♂️🕵️
Take a look at these two GRPO sanity runs. Exact same model, identical task. One climbs perfectly, the other completely flatlines. The only difference? The dead run is in bf16, the successful one is fp32.
What do you think the problem is with these runs? Drop your best guesses below !
2
7
93
12,926
Mar 17
Happy to see our Dr.GRPO and DPPO in the list 👇
It's really a nice blog for a quick review of RL algorithms for LLM reasoning. Worth a reading 👍
Mar 15

Finally finished!
If you're interested in an overview of recent methods in reinforcement learning for reasoning LLMs, check out this blog post: aweers.de/blog/2026/rl-for-l…
It summarizes ten methods, tries to highlight differences and trends, and has a collection of open problems
ALT Blog post on the current state of reinforcement learning for reasoning LLMs
1
1
30
4,248