
ML Engineer @poolsideai
Joined October 2008
- Tweets 33,198
- Following 1,003
- Followers 7,236
- Likes 23,430
790 Photos and videos











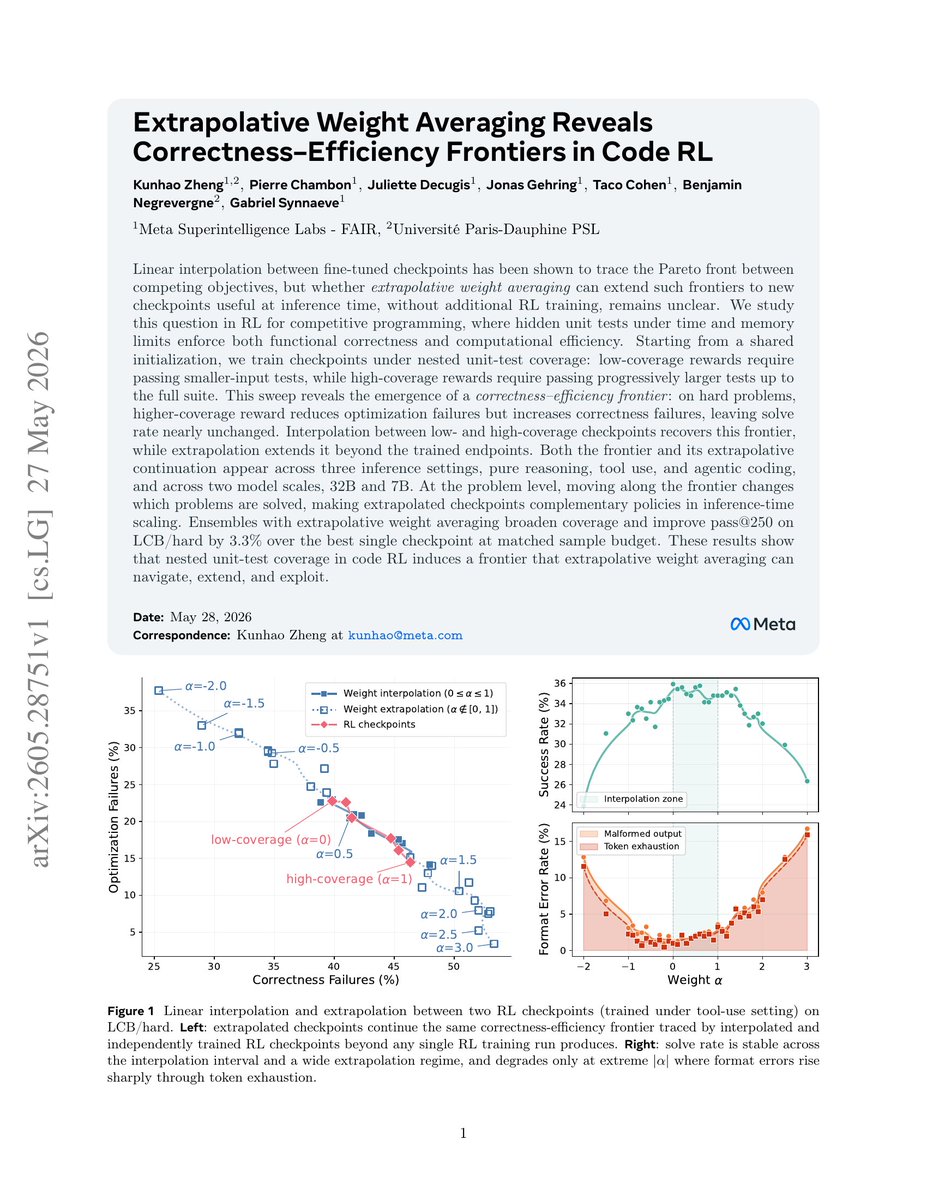


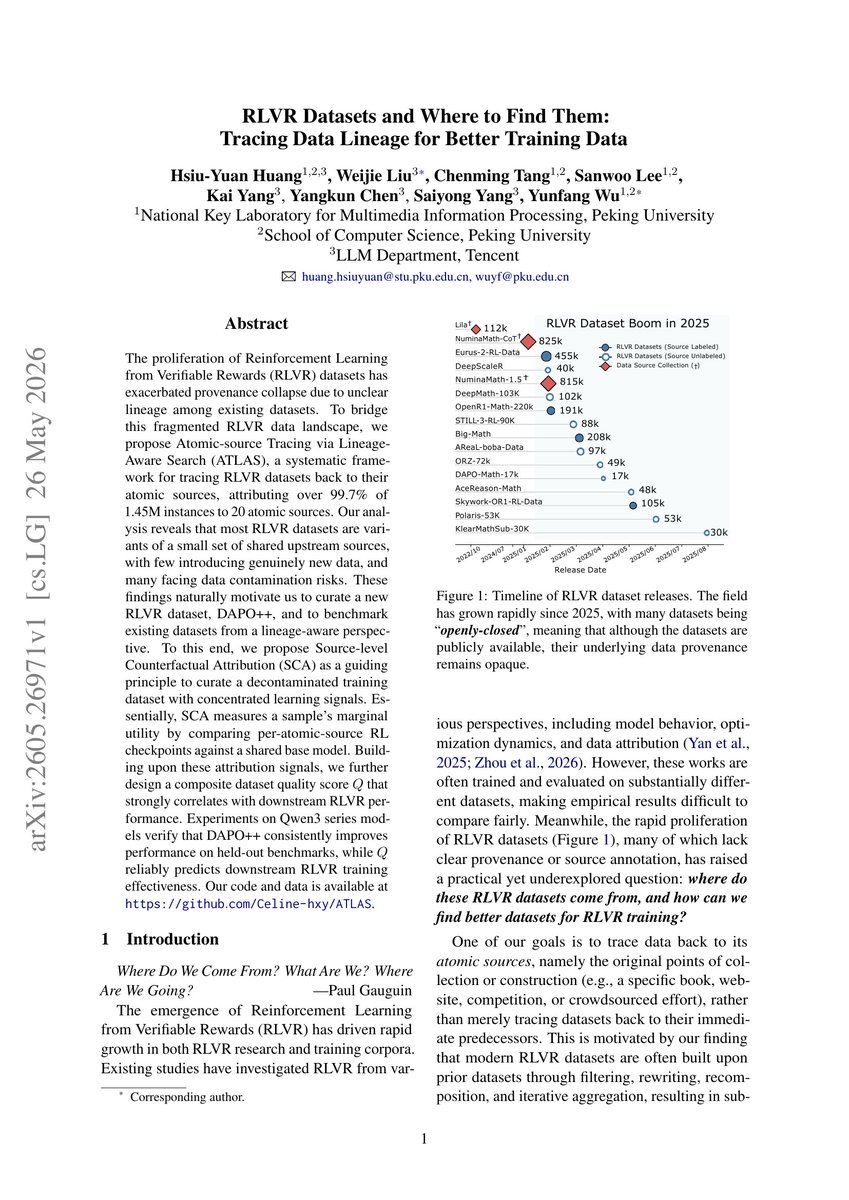

Pinned Tweet

Feb 5
I post the papers I find interesting. There are so many papers published these days, and I frequently miss great papers. I appreciate paper recommendations via DM, but I tend to only post papers I discover on my own to keep my list personally curated.
5
3
106
12,700
Jun 13
For the first time I am a bit persuaded by the argument that you should own the weights.
1
33
2,176
Jun 10
Diffusion이나 아키텍처의 특성으로 설명을 시도하는 경우가 많은데 인간 선호를 주입하면서 발생했을 가능성이 높지 않을까 싶음. 보통 사람들은 밀도가 높으면 더 높은 퀄리티로 판단할 가능성이 높을 것이니. 적절하게 밀도를 낮춰서 시선을 유도하는 것을 이해하기는 그보다는 더 어려우니.
1
6
1,306
Jun 9
Kokotajlo predicted that at some point AI would start to refuse to help with ML research. Maybe now is that point. (Prediction was Q1 2026.)
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

1
3
26
1,998
Jun 9
이게 일반적인 우파적 예술에 대한 발상이긴 한데 (예컨대 테드 창이 판타지는 보수적이고 SF는 진보적이라고 말한 것과 비슷) 지나치게 밀어붙이는 것도 그리 흥미롭지 않다고 생각. 예컨대 개인의 미덕은 보통 우파적으로 간주되지만 좌파 또한 개인의 미덕에 대해 말할 수 있어야 할 것이기 때문에.
Jun 8

많은 사람들이 놀랄만한 말이지만..
무수한 지브리 작품도 우파 예술입니다.
일상성의 무해함, 돌아올 곳의 예비, 고립되고 순환하며 외부적인 것이 배제된 세계, 인연에 대한 찬가..
3
10
1,597
Rosinality retweeted

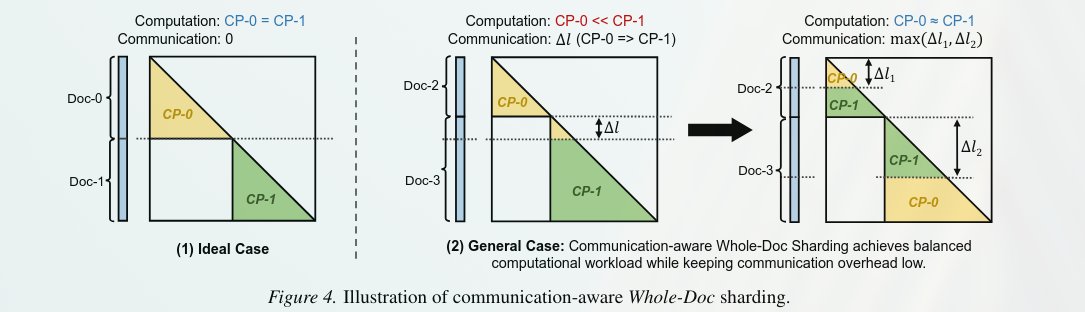
New CP strategy. FlashCP greedily assigns whole documents to the least loaded workers and only applies selective sharding to balance token counts or break down extremely long sequences that prevent an even workload distribution.
🔗arxiv.org/abs/2606.08476


2
25
2,759
Jun 9
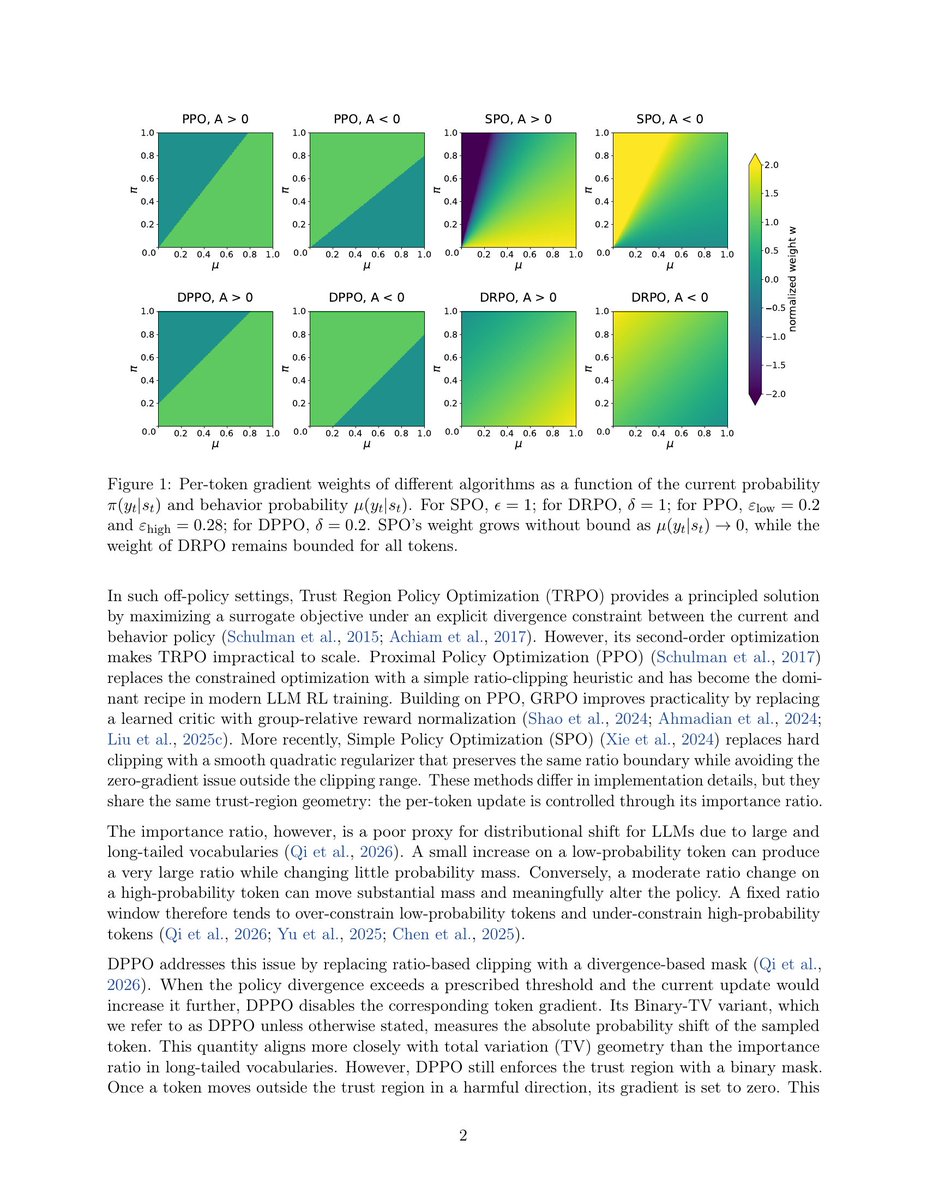
arxiv.org/abs/2606.09821
Soft version of DPPO (arxiv.org/abs/2602.04879, which uses a divergence-based mask instead of ratio-based clipping).
5
75
22,189
Jun 8
arxiv.org/abs/2606.07082
With respect to the degree of update on-policy distillation stays between RLVR and SFT. For the trajectory OPD remains a low-rank update from early on (maybe because it is distillation anyway). Could this affect the generalization?

2
12
116
30,740
Jun 8
arxiv.org/abs/2606.06888
Scaling law & input masking regularization under data repetition.

3
4
70
6,862
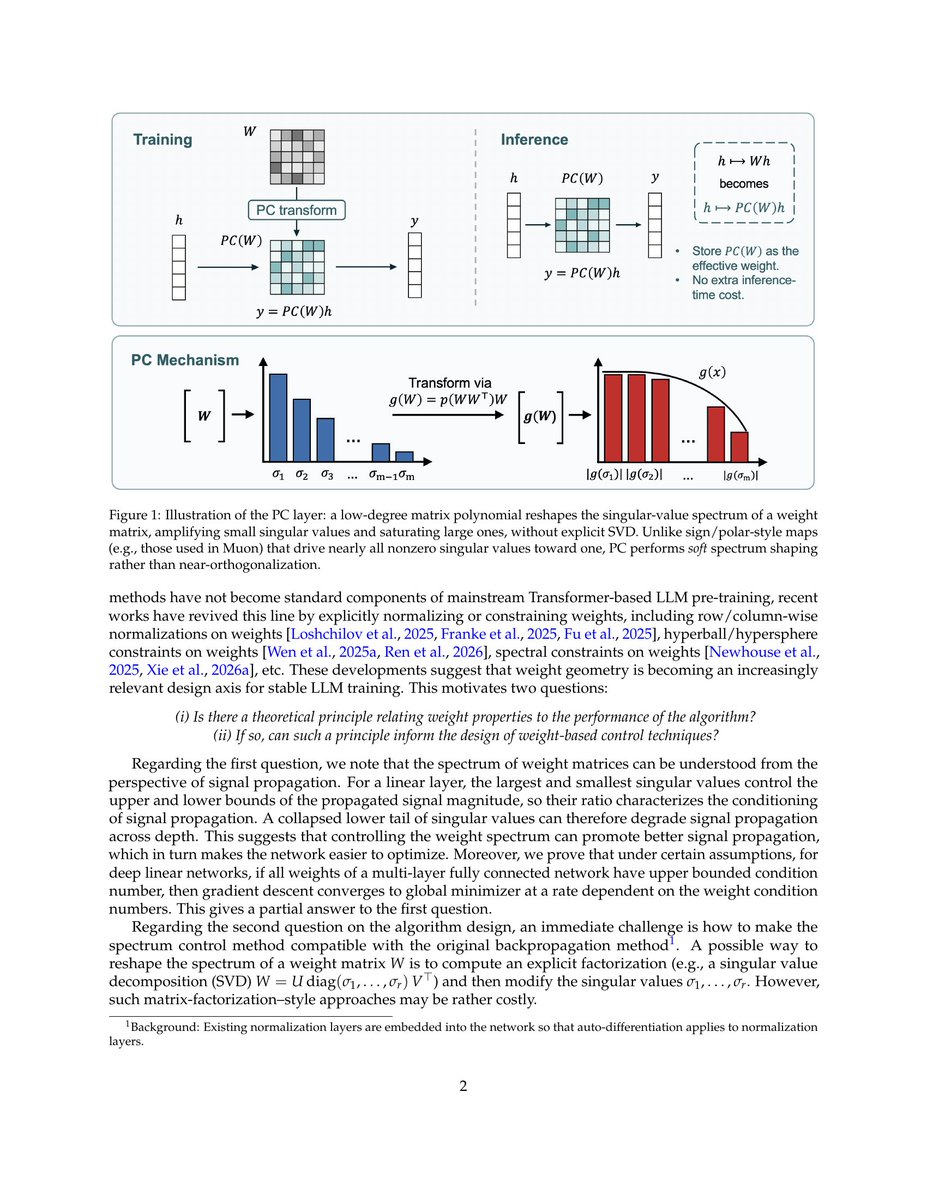
Jun 5
arxiv.org/abs/2606.06479
Training an RNN in parallel by RNN cell to predict a compressed state that predicts future outputs given past inputs. But as this state is distilled from time-parallel models its structure could be similar to that.

14
120
7,915
Rosinality retweeted

Jun 4
Introducing Self-Distilled Policy Gradient.
Token-level rewards, credit assignment, self-distillation.
RL and distillation are converging toward the same idea:
Policy gradients, it always has been, it always will be.
huggingface.co/papers/2606.0…
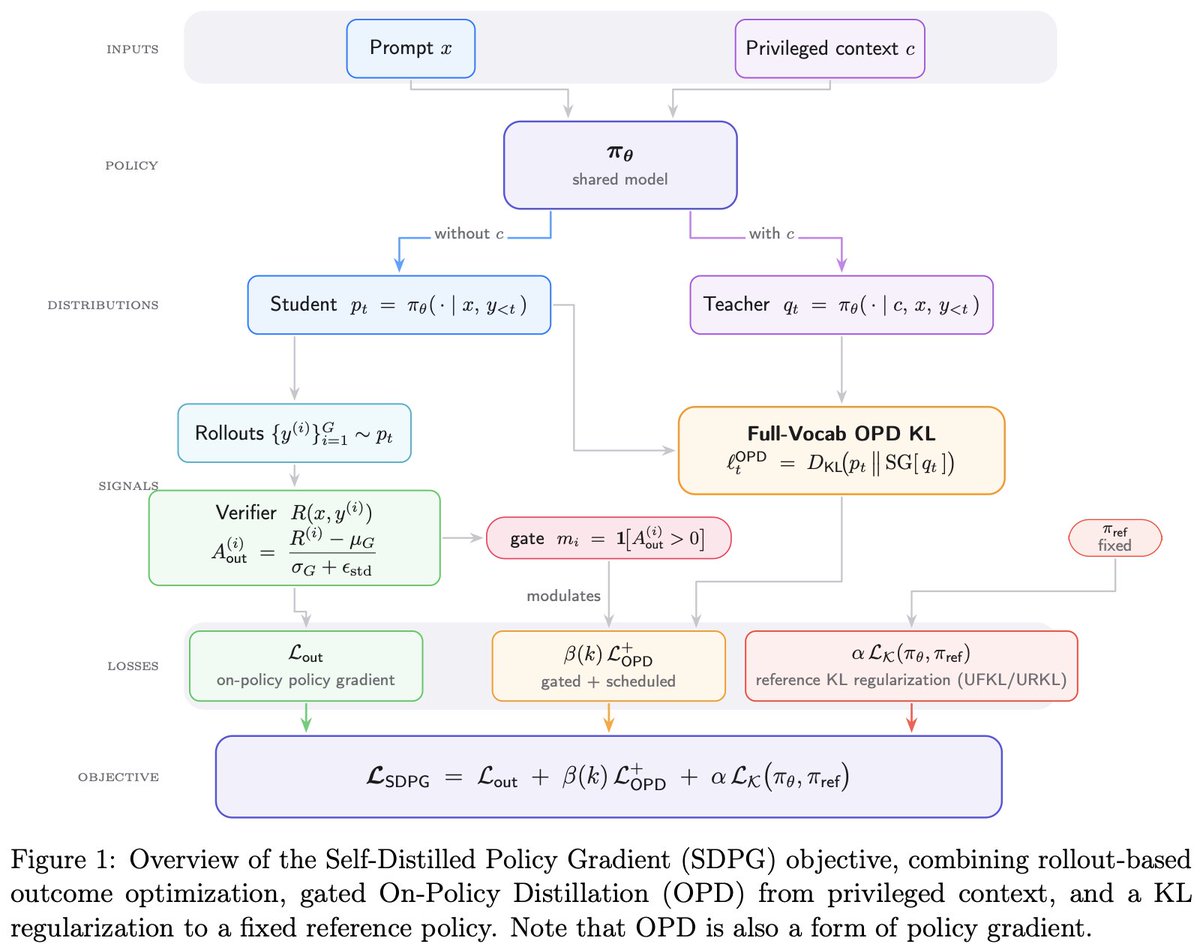
5
94
747
83,126
Jun 4
arxiv.org/abs/2606.05014
Depth attention. This uses a weighted sum of values as a value input for attention.

1
8
80
4,925
Jun 4
arxiv.org/abs/2606.04101
Expert load balancing with token rerouting and expert replication, with support for training. By the way, do they have blackwells?

4
33
2,637
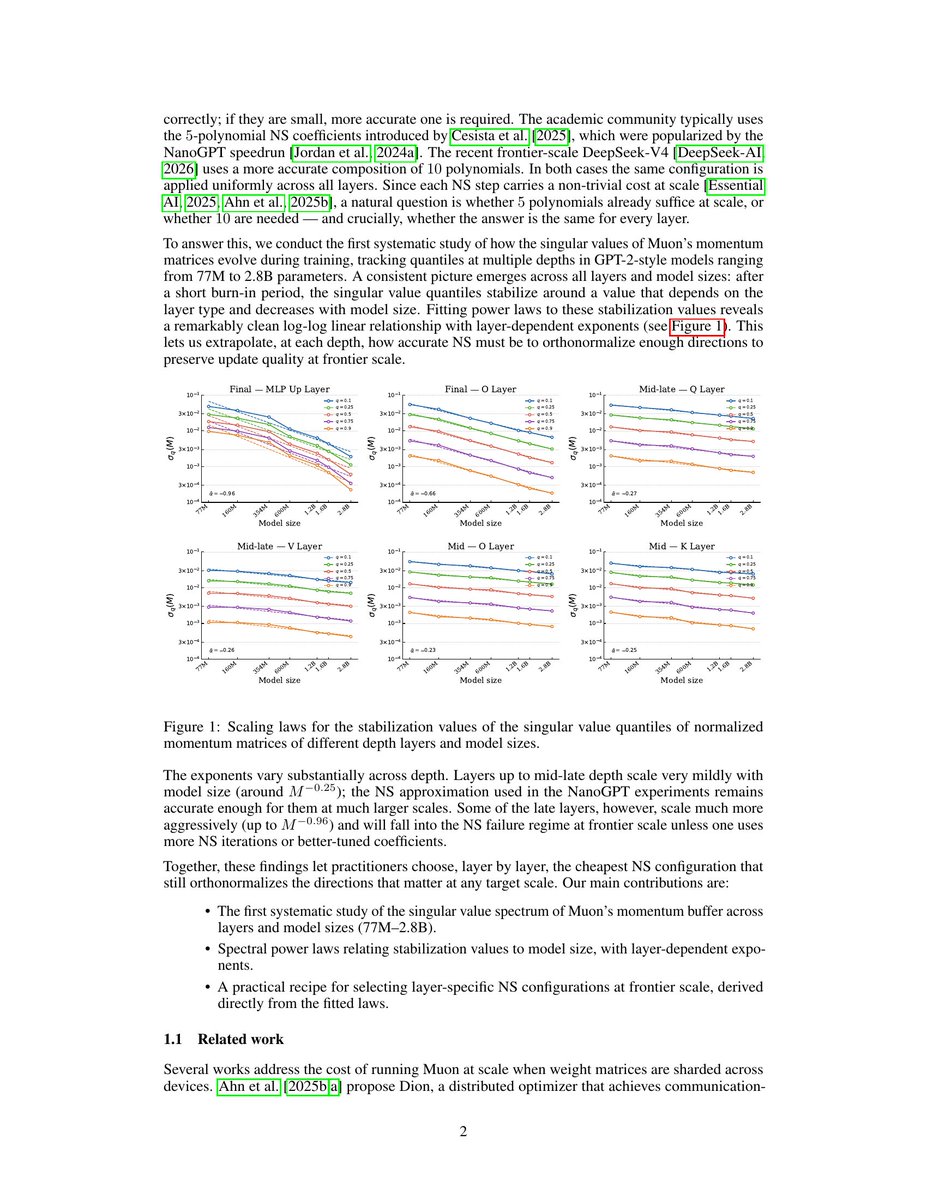
Jun 4
arxiv.org/abs/2606.04272
How does applying RL after pretraining compare to using intermediate SFT? The most interesting effect would be that sharpening of distribution does not happen with direct RL. (Though scale and effect are small, and Dolmino mix itself resembles SFT data.)

1
9
80
6,700
Jun 3
arxiv.org/abs/2606.03825
Dynamic convolution on QKV! An old idea came back again.
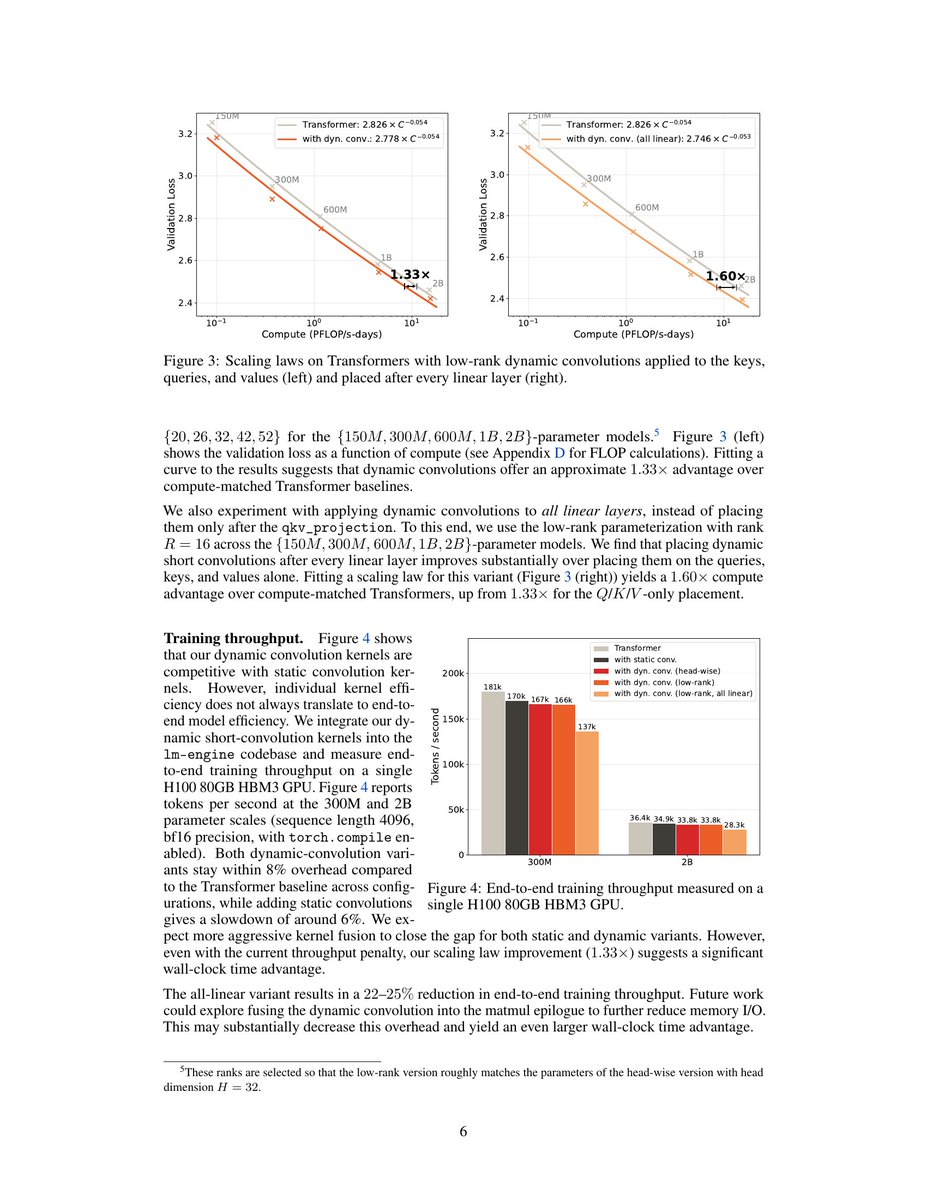
1
25
154
12,791
Jun 3
arxiv.org/abs/2606.03938
Snapshot ensemble distillation from previous snapshot learned ensemble weights. Would it be possible to distill this into a single model again?
1
7
40
3,282
Jun 2
Good taste is often a matter of sticking to the right things.
3
14
1,442
Jun 2
Many choices here are only possible when your objective is not an immediate or short-term performance. Pretraining without synthetic data, posttraining without SFT with data from other LLMs. (And other good choices like scaling ladder with NLL instead of benchmark scores).
Jun 2
WOW microsoft new "MAI Thinking 1" model comes with a 109 page tech report that looks REALLY detailed, this is amazing

1
6
93
10,052