
Professor @UCLA, Ex-ByteDance Seed | Recent work: Seed2.0, SeedFold, SeedProteo | Opinions are my own
Joined August 2017
- Tweets 2,467
- Following 2,427
- Followers 25,619
- Likes 40,912
140 Photos and videos










Quanquan Gu retweeted

Jun 10
There is No Wall
for Pretraining and RL Scaling.
4
8
178
22,856

Jun 9
💯


4
16
6,072

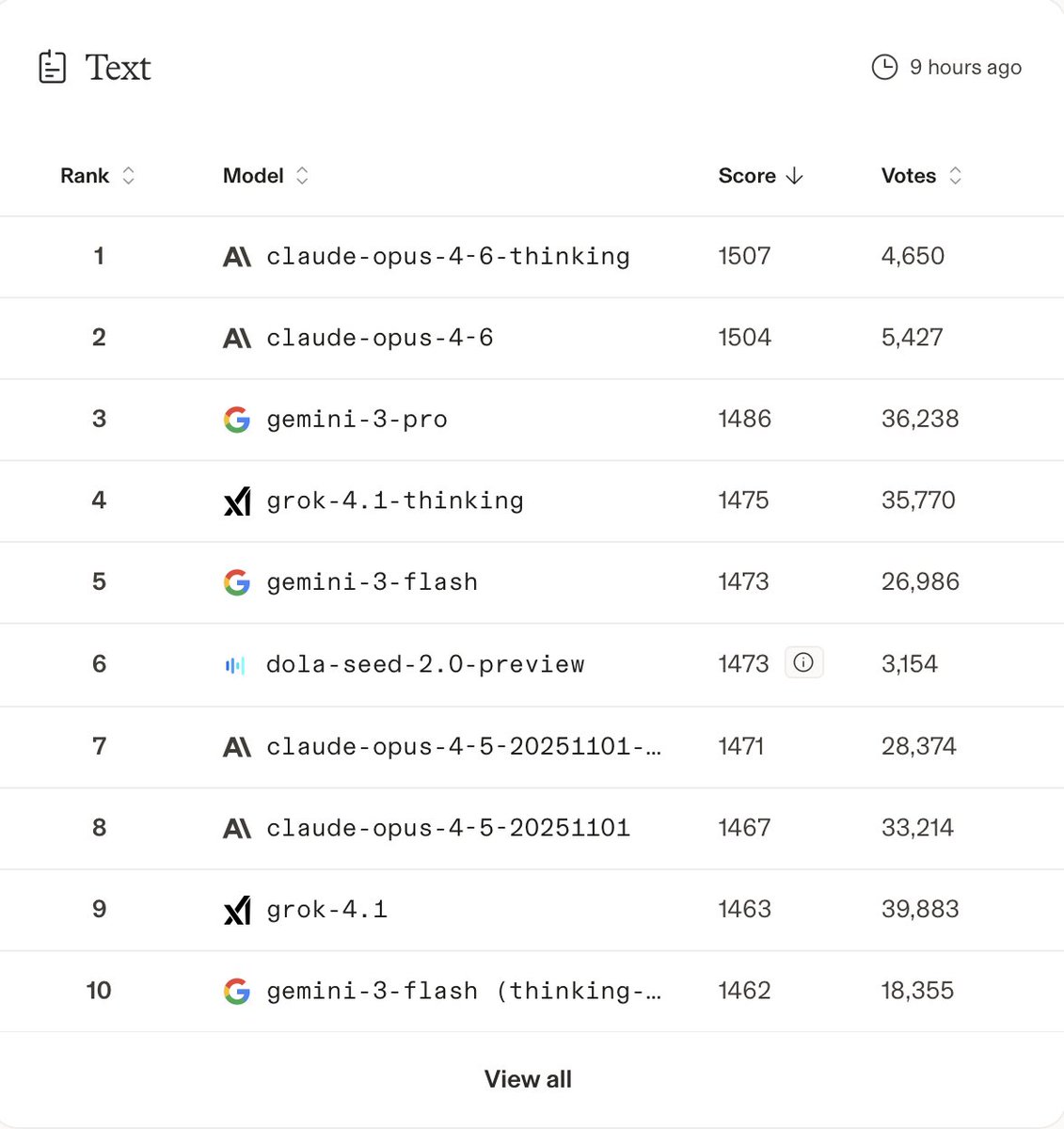
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
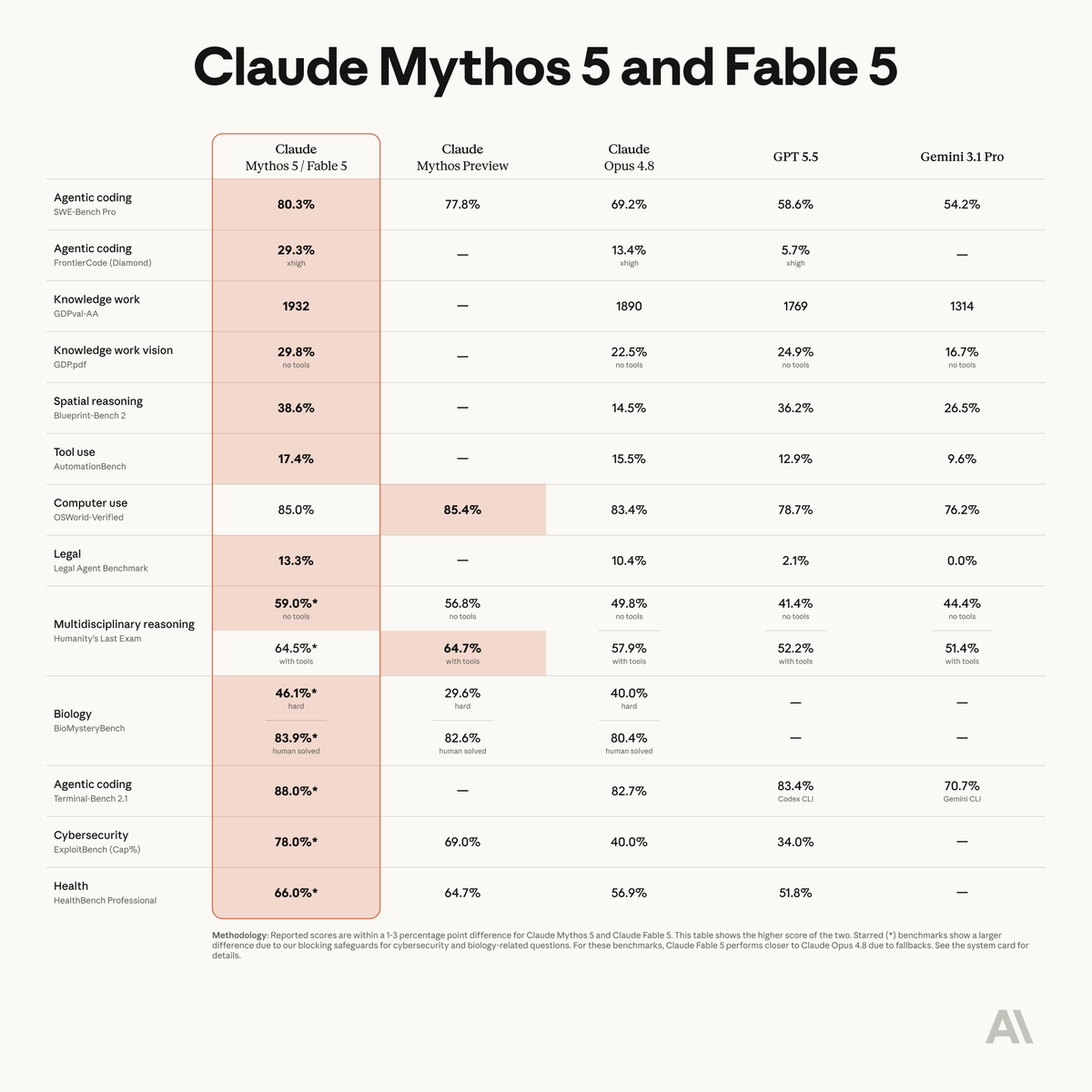
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
512
1,791
15,545
5,464,841
Quanquan Gu retweeted

Jun 5
[1/7] Recent breakthroughs in LLMs’ mathematical ability are genuinely surprising.
I recently solved a problem I had been unable to solve for seven years: the optimal acceleration rate for first-order methods under high-order smoothness assumptions in nonconvex optimization.
9
56
605
64,315
Jun 2
Today marks my last day at ByteDance Seed.
Over the past 3 years, I had the opportunity to work across two of the most exciting frontiers in AI: AI for Drug Discovery and building frontier LLMs. Few opportunities in a career allow one to work simultaneously on curing disease and building frontier intelligence. I was fortunate to do both.
Since joining ByteDance, I have led the AI for drug discovery effort. Together with an exceptional team and collaborators, we built SeedFold, the world's first biomolecule structure prediction model to outperform AlphaFold 3 across a broad range of benchmarks and capabilities; SeedProteo, a state-of-the-art protein binder design model surpassing AlphaProteo, RFdiffusion, Chai-2, BinderCraft, and BoltzGen ; and the DPLM series of protein language models, along with several other ambitious AI for Science projects.
In early 2025, I took on a new challenge. To tackle one of the hardest problems in modern AI, reliably training and scaling frontier-scale LLMs, I joined the LLM pretraining effort and founded the LLM optimization and scaling team. Together, we built a highly scalable pretraining stack that enabled the successful training of Seed 2.0 and the subsequent frontier-scale models, significantly advancing our ability to train and iterate on frontier AI systems at scale.
I'm deeply grateful to my teammates, collaborators, and leadership for an incredibly rewarding journey.
The best model is yet to come.
Scaling continues!
174
64
1,298
477,675
May 31
Thanks to @SebastienBubeck and @yubai01 , OpenAI is rapidly becoming one of the world’s leading departments of theoretical physics, statistics and computer science. This is very exciting!
12
19
474
50,850
May 28
I signed this letter because I care deeply about STEM education and student success.
No admissions system is perfect, but objective measures still matter.
May 26

University of California STEM professors want standardized tests back due to severe math deficiencies among students:
“We now observe preparation gaps so severe that instructors must reteach middle school mathematics”
“The current admissions metric, based primarily on GPA & essays, can no longer reliably distinguish readiness for university-level STEM majors in an era of severe grade inflation & AI assisted application essays”


26
20
270
30,745
Quanquan Gu retweeted

May 26
🚨New Optimizer Paper
AMUSE: Anytime MUon with Stable gradient Evaluation
AMUSE combines Muon with Schedule-Free-style gradient evaluation for stable anytime training without LR decay.
• Stronger 124M / 720M / 1B pretraining
• Strong ImageNet / ViT fine-tuning performance.

16
40
322
43,391
Quanquan Gu retweeted

May 20
🚨 New Paper 🚨
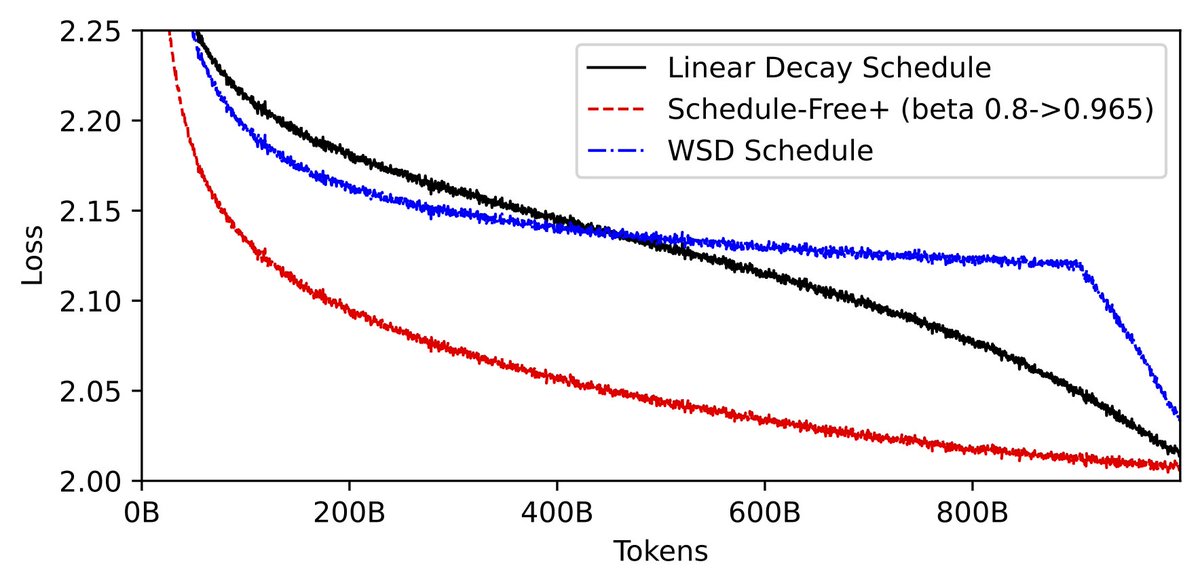
ScheduleFree : Scaling Learning-Rate-Free & Schedule-Free Learning to Large Language Models
A few modifications to Schedule-Free Learning make it completely LR tuning free, and allow it to greatly outperform schedules for long duration training!
arxiv.org/abs/2605.19095v1
7
56
421
85,186

1/4
New paper with @weijie444!
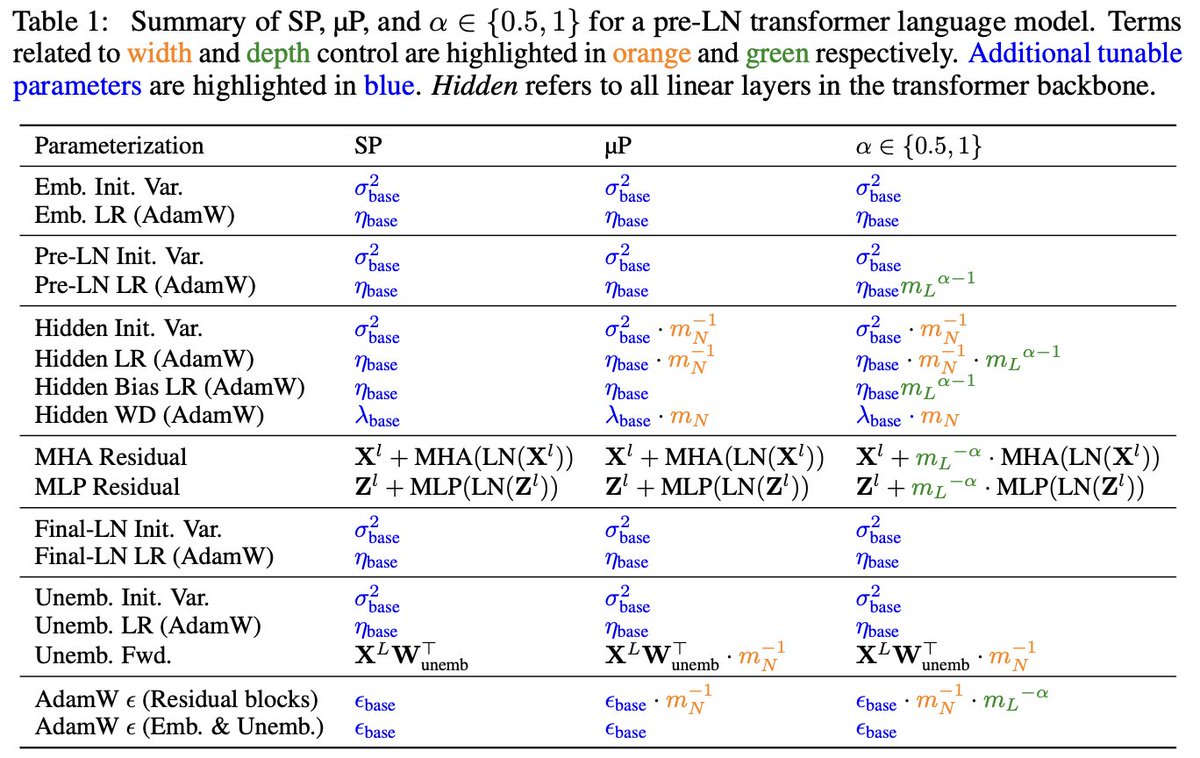
We introduce a symmetry-compatible principle for LLM optimizer design and, as a byproduct, get an end-to-end layerwise optimizer stack where every major matrix-valued parameter (embeddings, LM heads, SwiGLU MLPs, MoE routers) has its own principled update!
📝 arxiv.org/abs/2605.18106
💻 github.com/timlautk/equivari…
4
31
141
31,681
Quanquan Gu retweeted

May 18
Thrilled to announce our ICML 2026 paper: "Dimension-Independent Convergence of Underdamped Langevin Monte Carlo in KL Divergence" 🎉 We give the first dimension-free KL bounds for discretized underdamped Langevin — depending on tr(H), not the ambient dimension d.

2
10
24
4,047
Quanquan Gu retweeted

May 17
spectral filtering is a favorite technique, from learning in dynamics to neural architecture design, but extending beyond real eigenvalues is a pain. here is a reason from slepian theory, w. my brilliant postdoc Annie: arxiv.org/html/2601.22400v2
13
109
12,310
May 16
Finally joined Xiaohongshu (RedNote) 👀
xhslink.com/m/AGPhXTjj3kE
Will occasionally share thoughts on AI, scaling, and AI for science there too.
7
9
228
91,858
Quanquan Gu retweeted

May 15
Let me highlight one very surprising (was surprising to us!!) aspect of the Local LMO theory:
Provided the radius follows a certain upper bound (is type-I or type-II admissible), the radius always equals the effective stepsize!
While this is obvious in the unconstrained setting, it is very surprising in the constrained setting!
Look at conclusion (ii) of Theorem 3.1.

May 12

Imagine that projected gradient descent (PGD) was a new method, discovered today. How would that feel? This is a textbook algorithm... What further research, extensions, improvements and variants would this enable?
In fact, together with Kaja Gruntkowska and Hanmin Li, we have just discovered a sister method to projected gradient descent -- one of equal conceptual importance.
Our method admits the same or very similar guarantees as PGD. However, instead of relying on projections onto the constraint, it relies on linear minimization!
You may say: Did you rediscover Frank-Wolfe?
No.
In contrast to Frank-Wolfe, which uses a global linear minimization oracle (global LMO), our method relies on a local minimization oracle (local LMO). For this reason, we simply call the method "Local LMO" (admittedly, conflating the oracle name with the method name).
Frank-Wolfe theory is much more limited to the theory of Local LMO. Here are some key differences:
1) Frank-Wolfe only works if the constraint is bounded, and its convergence theory depends in the diameter of the constraint set. Local LMO works even for unbounded constraints, and its theory does not depend on the diameter of the constraint set.
2) In fact, Local LMO reduces to gradient descent (GD) in the unconstrained case. If the constraint is affine, Local LMO reduces to (preconditioned) GD in the affine space.
3) While Frank-Wolfe does not converge linearly for smooth strongly convex functions, Local LMO does.
4) While Frank-Wolfe does not converge for non-smooth convex problems (its theory depends on a curvature assumption), Local LMO does.
arxiv.org/abs/2605.08850

6
30
8,137
Quanquan Gu retweeted

May 14
arxiv.org/abs/2605.12715
How many repetitions could be allowed for a small dataset in pretraining mixtures? Naturally it would be a function of model scale and data size (and compute budget). But it could be larger than expected. arxiv.org/abs/2603.16177

1
28
248
33,541
Quanquan Gu retweeted
May 13
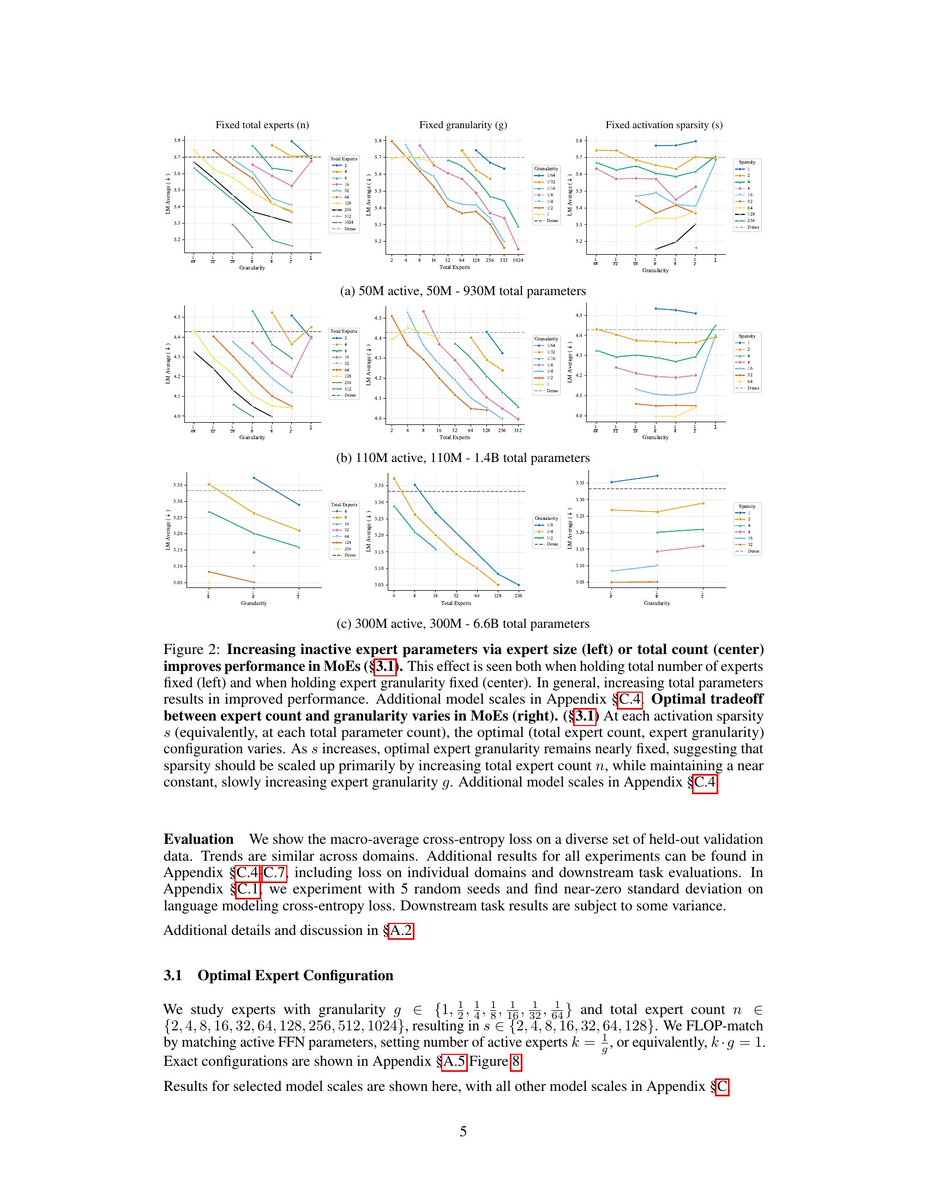
Exploration over MoE. Increase the number of experts as much as you can, and pick adequate granularity. The rest of the choices are not that important.

1
11
89
7,355
Quanquan Gu retweeted
May 12
Imagine that projected gradient descent (PGD) was a new method, discovered today. How would that feel? This is a textbook algorithm... What further research, extensions, improvements and variants would this enable?
In fact, together with Kaja Gruntkowska and Hanmin Li, we have just discovered a sister method to projected gradient descent -- one of equal conceptual importance.
Our method admits the same or very similar guarantees as PGD. However, instead of relying on projections onto the constraint, it relies on linear minimization!
You may say: Did you rediscover Frank-Wolfe?
No.
In contrast to Frank-Wolfe, which uses a global linear minimization oracle (global LMO), our method relies on a local minimization oracle (local LMO). For this reason, we simply call the method "Local LMO" (admittedly, conflating the oracle name with the method name).
Frank-Wolfe theory is much more limited to the theory of Local LMO. Here are some key differences:
1) Frank-Wolfe only works if the constraint is bounded, and its convergence theory depends in the diameter of the constraint set. Local LMO works even for unbounded constraints, and its theory does not depend on the diameter of the constraint set.
2) In fact, Local LMO reduces to gradient descent (GD) in the unconstrained case. If the constraint is affine, Local LMO reduces to (preconditioned) GD in the affine space.
3) While Frank-Wolfe does not converge linearly for smooth strongly convex functions, Local LMO does.
4) While Frank-Wolfe does not converge for non-smooth convex problems (its theory depends on a curvature assumption), Local LMO does.
arxiv.org/abs/2605.08850
8
21
126
24,045
Quanquan Gu retweeted

May 9
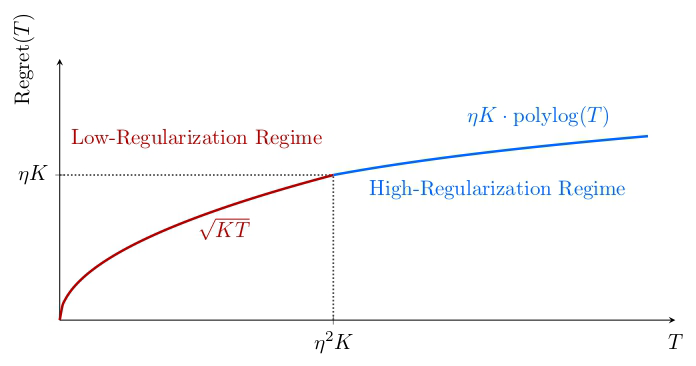
Excited to share our ICML2026 paper: Near-Optimal Regret for KL-Regularized Multi-Armed Bandits (arxiv.org/abs/2603.02155)
🚀 KL-regularization is at the heart of modern LLM post-training.
❓How does it change the statistical limits of online learning?
In our paper, we give the first near-complete characterization of regret for KL-regularized multi-armed bandits:
• For low regularization: \sqrt{KT} regret, similar to standard MAB
• For high regularization: ηK*ploylog(T) regret.
3
13
86
10,395
Quanquan Gu retweeted
May 8
Power law relationship between RL compute and task complexity using synthetic logic problems. One of the interesting parts is how task complexity and RL compute affect the downstream performance.

2
14
66
7,334
Quanquan Gu retweeted

May 7
We improve a 32-year lower bound in a challenging open problem, Ramsey numbers, through simply scaling autoresearch.
⭕ Proves R(3,17) >= 93. Previous 92 bound were obtained in 1994.
Google’s AlphaEvolve (2026) matched previous result but did not beat it.
All could be done with Claude Code / Codex a CPU server.
Graphs and evolving history are available at github.com/ypwang61/ScaleAut…
[1/n]
11
49
327
54,990