
Quantum & Deep Tech VC Investor - (🇵🇱,🇺🇸) - e/acc ⏩ - $IONQ
Joined December 2020
- Tweets 16,718
- Following 1,022
- Followers 20,144
- Likes 83,754
3,579 Photos and videos

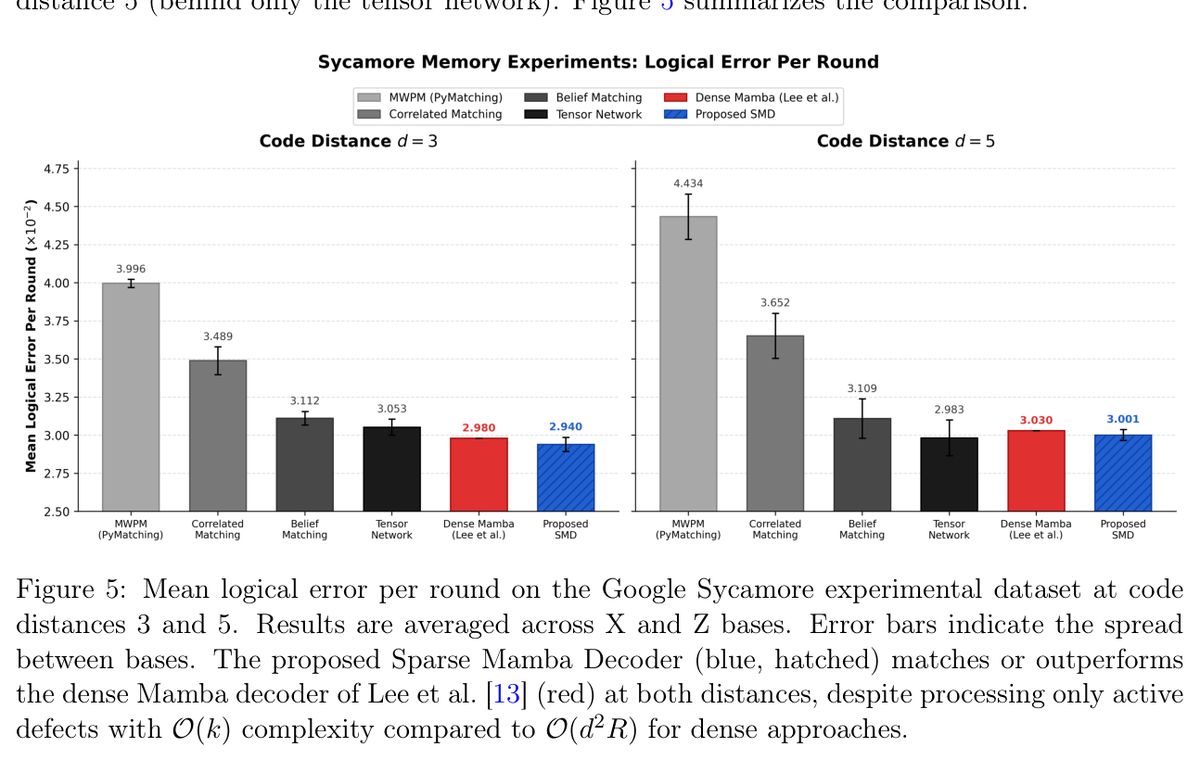
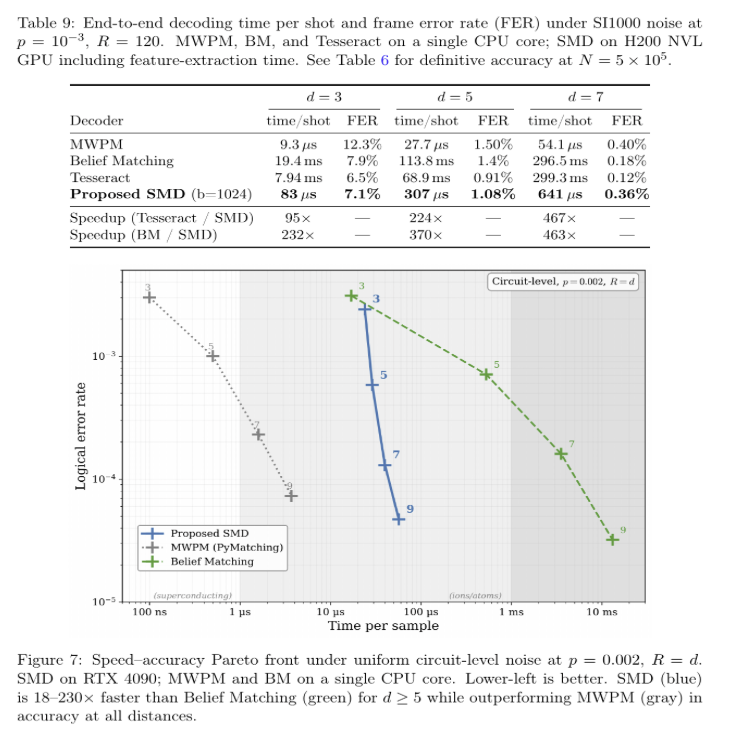

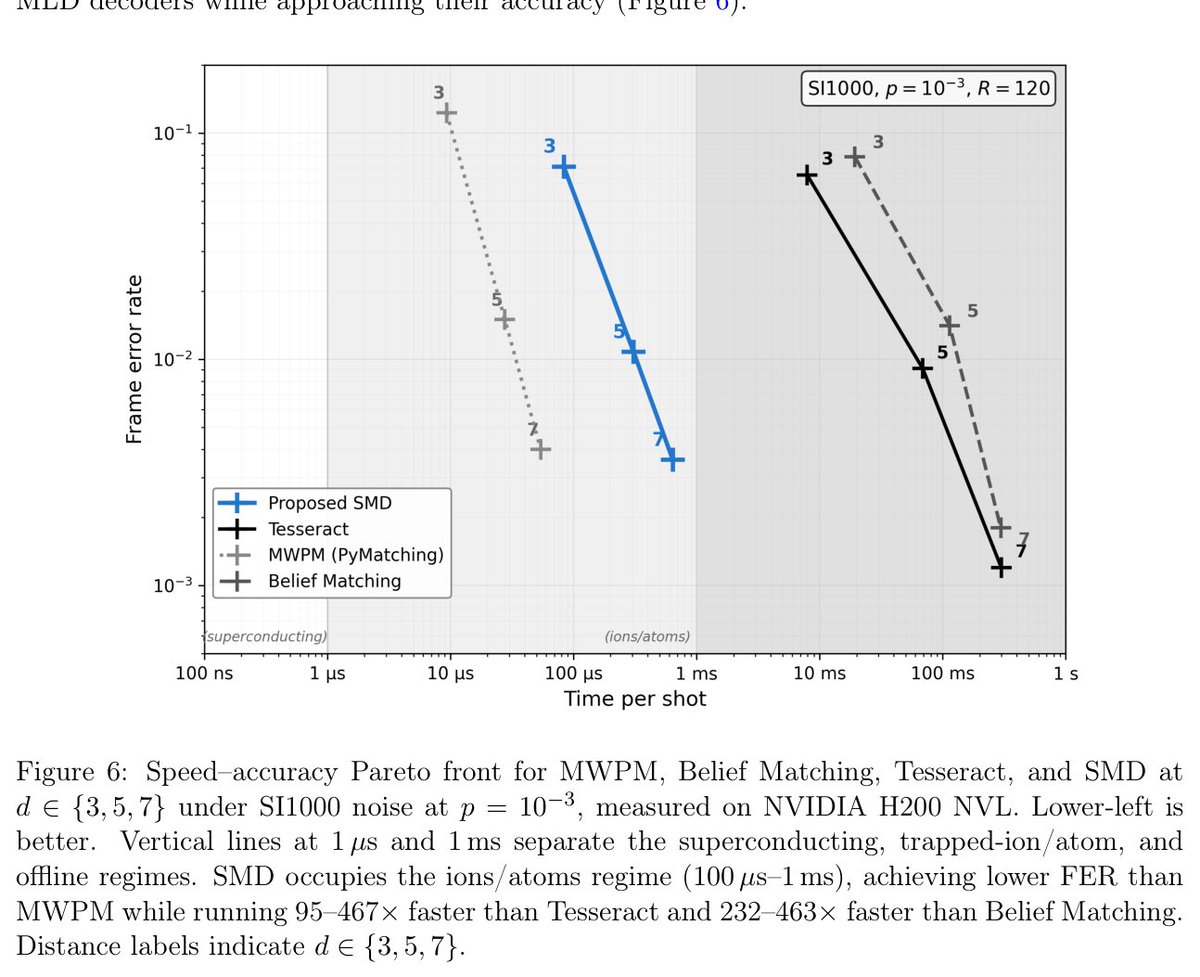


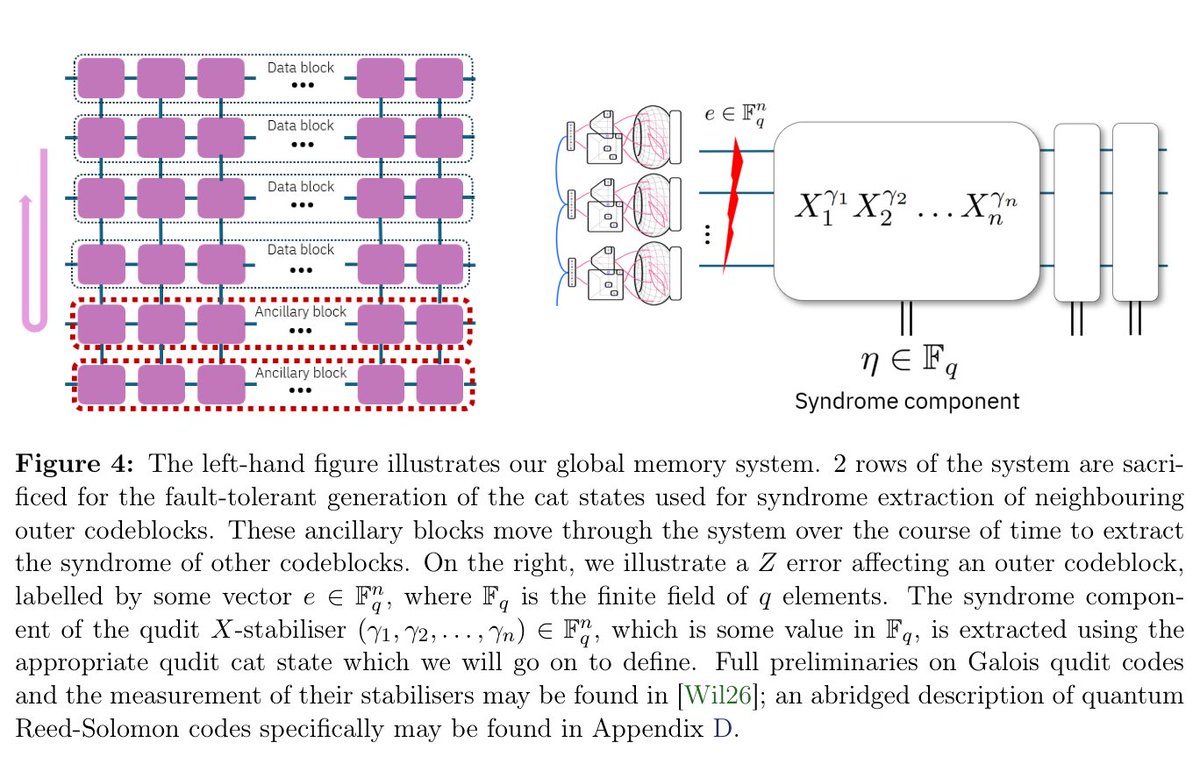

A surface-code decoder that ignores 97% of the data.
UC Irvine's Sparse Mamba Decoder reads only the ~3% of syndrome cells that actually fire.
Result: up to **49% lower error than MWPM**, 95-467× faster than near-optimal decoders,
all on a gaming GPU. 🧵
1
148
Reality check:
• Academic, no hardware partner; synthetic noise plus old Sycamore d=3,5 data
• At d=7 it only ties MWPM; the 16% edge is within error bars
• Belief Matching still beats it at d=7
• Limited to d≤7 by compute budget; fault tolerance needs d=15
• 'Faster' is GPU vs CPU, not apples-to-apples
But zoom out:
Decoding is the unglamorous bottleneck of fault tolerance. Near-optimal accuracy with O(k) scaling on a sub-$2k GPU matters, because classical decode cost is a real line item as codes scale.
Direction: the QEC classical stack is getting cheaper, and that's bullish for everyone who has to deploy it.
1
79
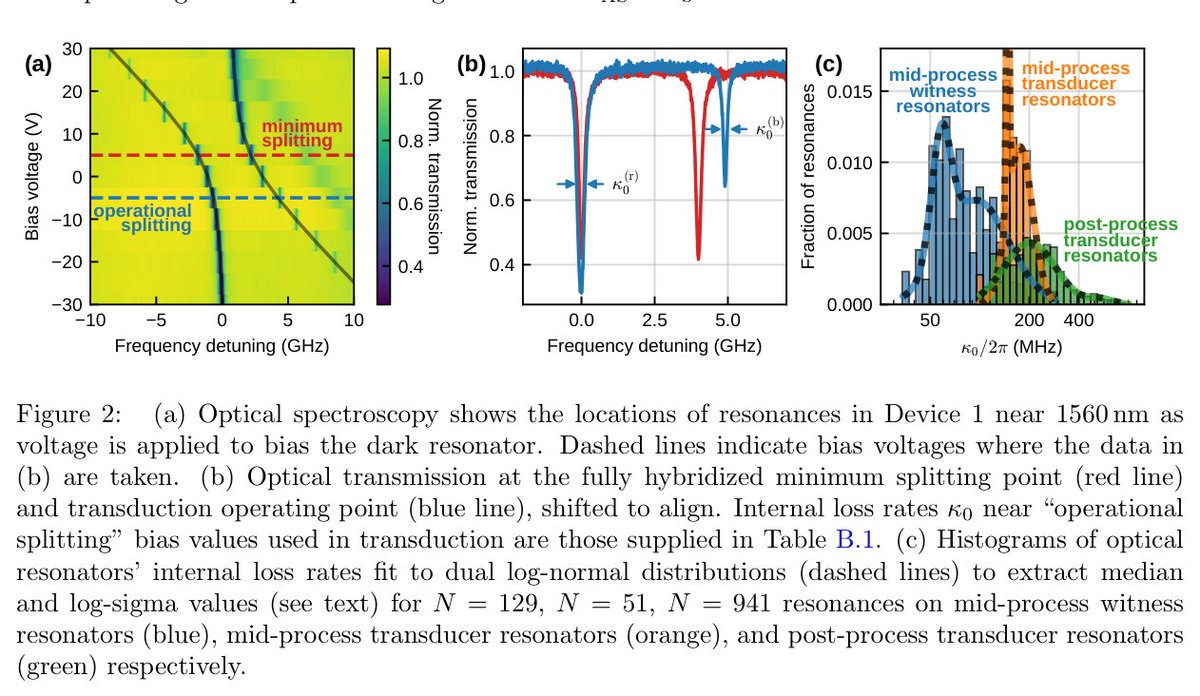
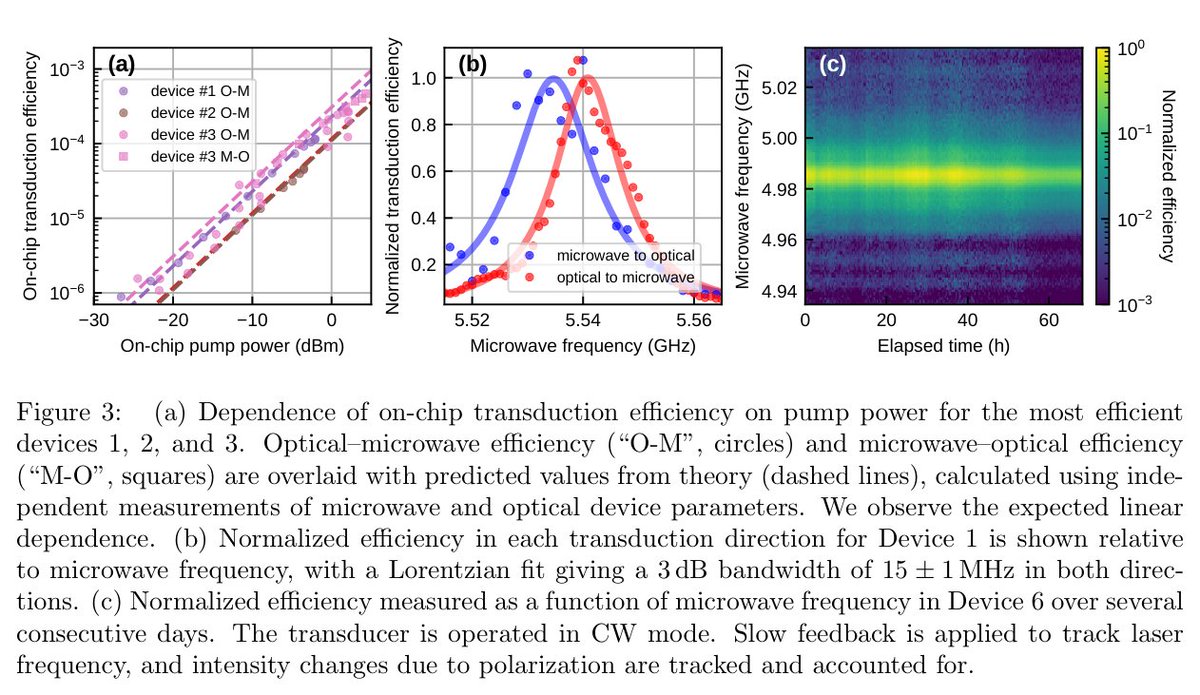
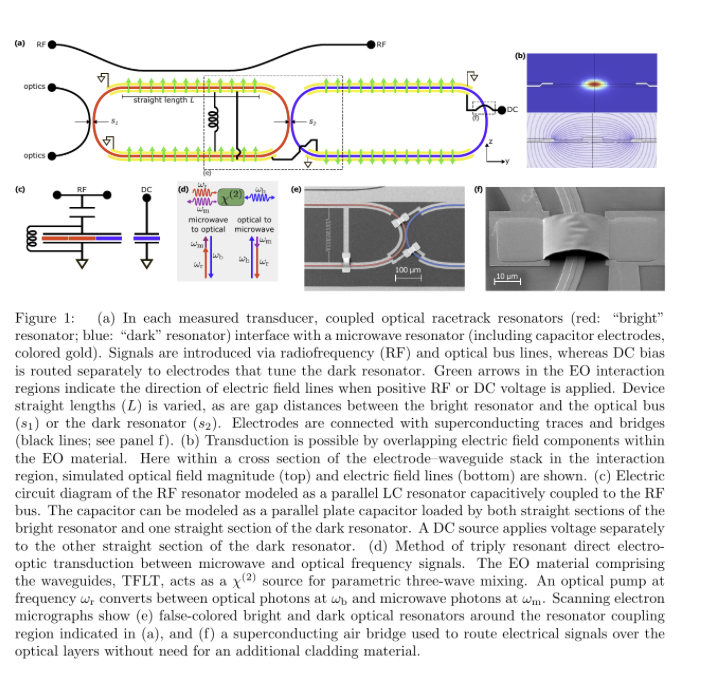
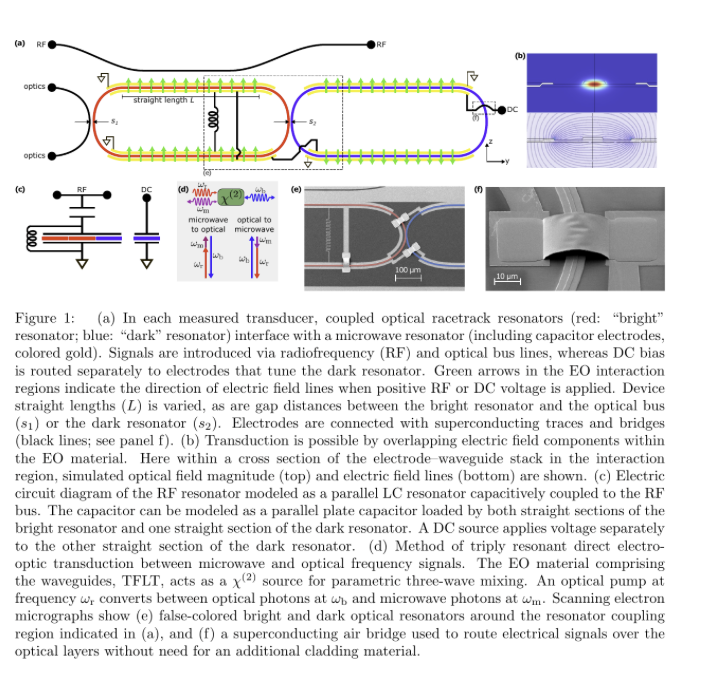
Miraex EPFL just built the first microwave-to-optical quantum transducer in thin-film lithium tantalate (TFLT).
The pitch isn't speed. It's stability: days of operation on one static bias, plus wafer-scale fab.
The unglamorous bottleneck of modular quantum. 🧵
1
242
Investor read:
• $IBM, plus Google and Rigetti: every superconducting roadmap needs optical interconnects to go modular. This is upstream of that.
• Coherent, Lumentum: photonics picks-and-shovels.
• Cisco: quantum networking ambitions.
• Miraex (private, Swiss) EPFL: the actors here.
Signal to watch: whether any superconducting vendor names a transduction partner.
1
126
Reality check:
• On-chip efficiency ~0.04%. Needs orders of magnitude more to be useful.
• Microwave Q far below the material limit. Unexplained loss.
• ~10 dB per fiber coupler, unoptimized.
• Best numbers are simulated, not measured.
But zoom out:
Transduction has been a lab-bound art. This trades peak performance for two things that scale: a bias you set once and forget, and wafer-scale fab making hundreds of devices at a time.
Direction: the quantum interconnect layer is starting to think like a foundry, not a physics experiment.
arxiv.org/abs/2606.12726v1
110
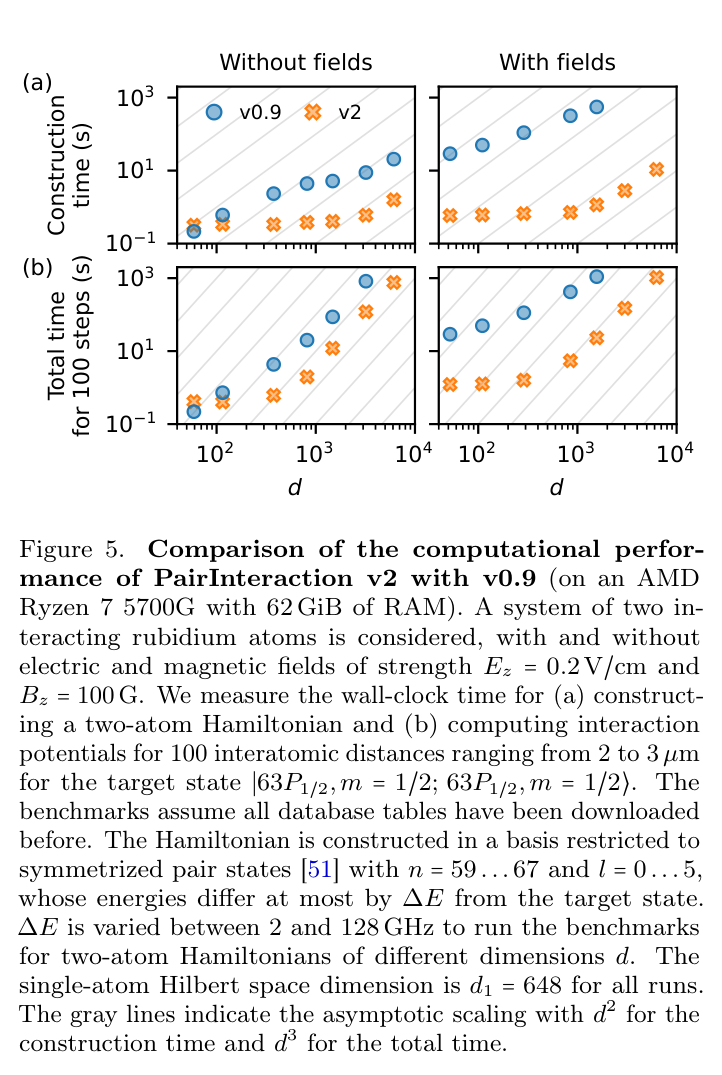
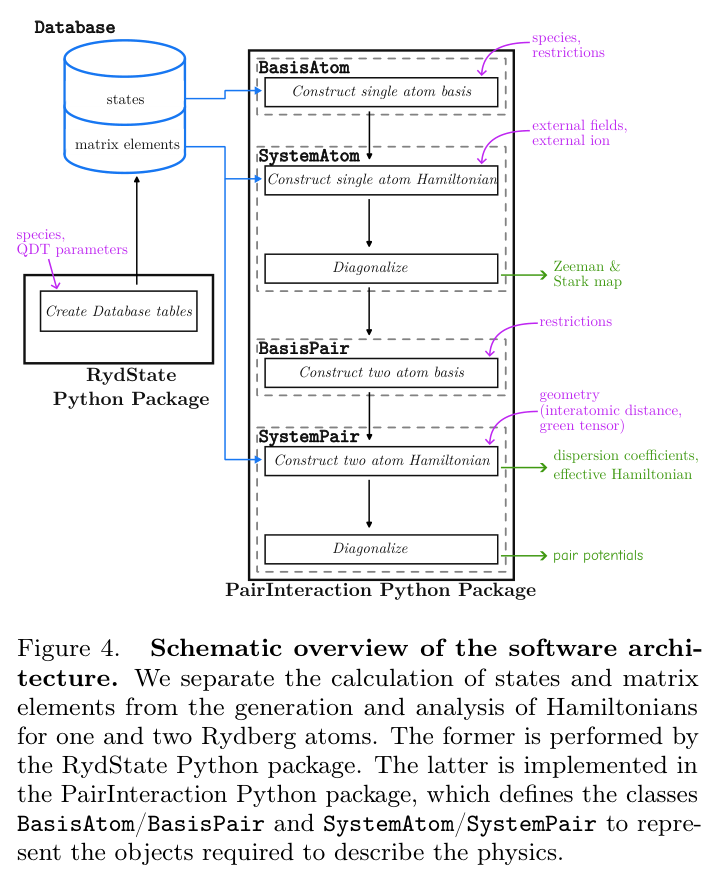
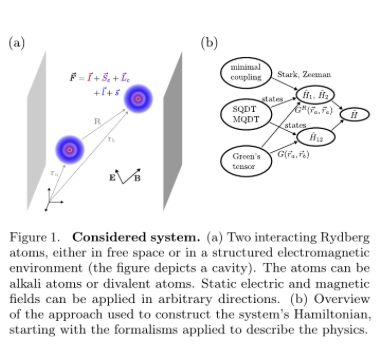
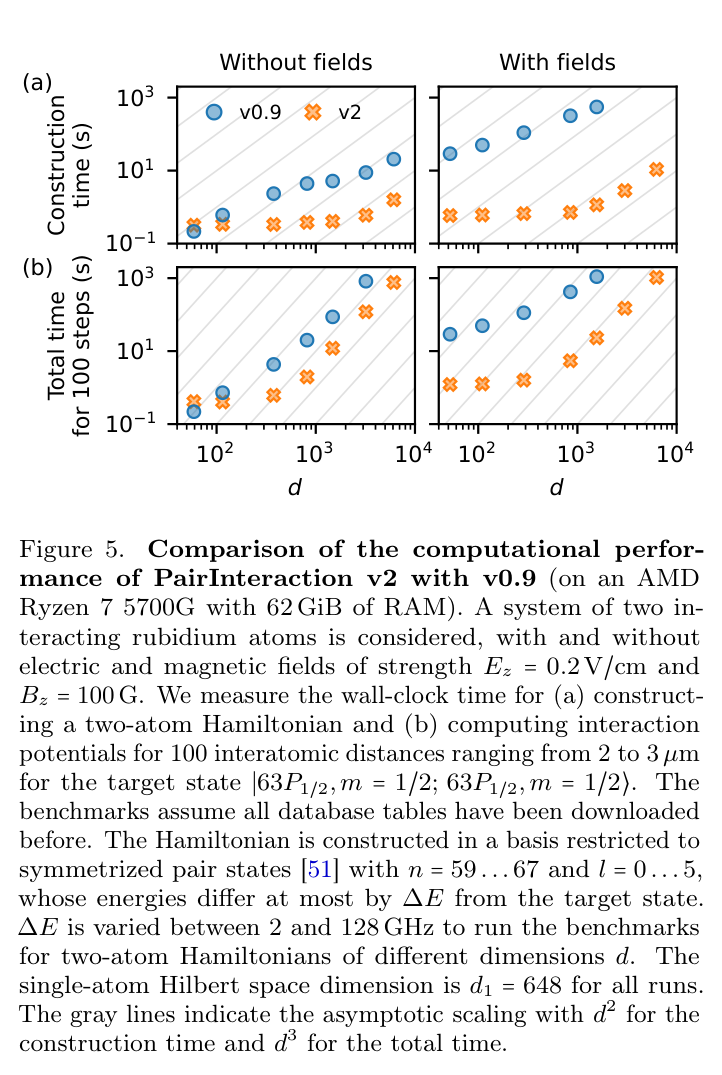
Open-source software that models neutral-atom qubit interactions just got 10x faster.
New from a German-led team with @Atom_Computing inside: PairInteraction v2, validated against real ytterbium data.
The design layer for neutral-atom quantum. 🧵
1
1
259
Investor read:
• Atom Computing (private, Boulder, strontium) — co-author and direct beneficiary
• QuEra, Pasqal, Infleqtion (all private) — same tooling class underpins their gate design
• No clean public pure-play yet; neutral-atom exposure is still mostly pre-IPO
Signal to watch: whether @infleqtion cites design-tooling maturity.
1
130
Reality check:
• A software/tooling paper, not a new qubit or advantage result
• 10x is an engineering speedup, not a physics breakthrough
• Validation is one Yb Stark map, not a broad benchmark suite
• Open tools help every neutral-atom competitor equally, not one
But zoom out:
Quantum wins on unglamorous infrastructure as much as headline qubits. Fast, free, accurate modeling of divalent Rydberg atoms removes a real design-cycle tax for the whole neutral-atom field.
Direction: the picks-and-shovels layer of neutral-atom quantum is maturing in public.
arxiv.org/abs/2605.14993
125