
Building Kairos Agent for coding | ACMer & Computer Science Enthusiast | Lesbian | 💖love maimai & 📝writing | 🐱Catgirl | 💝I'll always be with you.
Joined August 2023
- Tweets 7,665
- Following 430
- Followers 2,603
- Likes 28,135
595 Photos and videos







Pinned Tweet

Feb 9
Know you will wake, on winds rise again
知道你终会醒来,从那之后天空即为极限
For this journey's end but one step forward to tomorrow…
而这旅途的终焉,即为迈向明天的开始

3
39
12,365
网好的时候 20 分钟就能做完,结果现在还卡着,看起来要做快两个小时
虽然我不可否认 agent 确实能跑很久,但有些人说不跑长任务这个人就不会用 agent,有可能只是 ta 自己的网太烂了一个请求卡在中间半天,所以 agent 才跑了很久,而并不是 ta 真的在跑长任务(
5
164

假如你的朋友最近需要更新简历,一定要把 Kami 推荐给他,我单独细致优化了一个版本,单独让 Kami 写简历变得非常好用好看清晰,让他把他的原生素材 md 准备好,然后对着 AI 说 /kami 帮我产出一个简历,然后调1-2下差不多就好了。
github.com/tw93/Kami

139
192
1,401
124,629
限时清仓大甩卖.png
不过 1512 新台币确实很便宜,我的 gemini pro 订阅一个月也要 650 新台币呢,约等于两个月订阅费用了,但是可以买全年的诶!
7
1,134
obelisk 即将有一个 v0.1.0 的正式版,可以期待一下☺️
加入的特性有:
- 一个 gui 面板的 app,提供了比较好的阅读体验,你可以认为它和 claude code gui 只有半步之遥,差的半步是还没有实现消息响应式渲染
- gui 和 skill 配套出了一个有趣的功能!可以上张预告图 hhh
无论 app 还是 skill,obelisk 的数据始终只在本地流转,欢迎大家来体验呀www

2
1
16
2,292
Jun 12
我感觉 codex 的话我会更相信 compaction
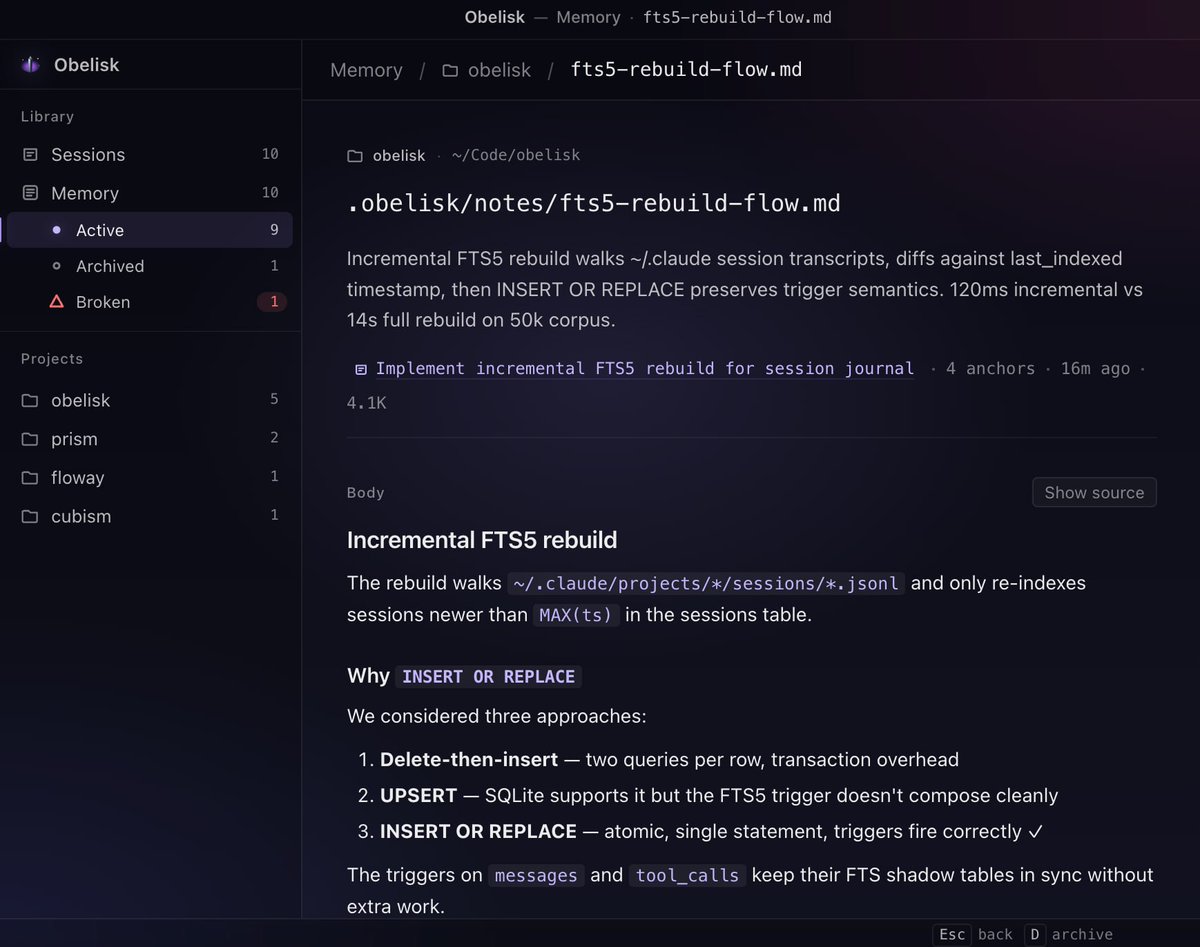
事实上现在我的 obelisk 可能已经能完成一部分多 session 整合的任务了,我现在在 claude code 上已经不太受限于 session,可以在 session 里提到任意其他 session 的内容
之所以说可能是因为,token efficiency 还需要优化,如果检索占用 context window 下降,会变得更好用


Jun 12

实际上一个长程 session 被分解为多少个 commit 完全看开发者自己的心情,很多时候,我都是做完相当多事情才让 agent 按照功能分类提交,我理解 svn/git 的设计目的是为了能让软件开发按照某种逻辑组织起来,目前单项目多 session 的方式其实也是不太适合做管理,应该会需要某种方法自动分析某个目录的多个 session 并且整合对话(只有意图对话,不包括 agents 之间的沟通)
1
1
14
4,138
Jun 12
这 vscode 怎么删东西可以删错的??????
我刚才删一个三层嵌套的文件夹,选中了最里层那个
正常来说删完里面的不该删外面的了吗,你跳到根目录随机删一个文件夹是什么意思,ctrl z 都没救回来
项目进度直接回滚五小时,刚才说两小时是算少了
5
18
4,583
Yuu💖 retweeted

Jun 12
My prediction from last summer was that the number of frontier AI models getting a gold medal at this summer’s IMO will be… zero! The reason is that they won’t bother to compete, it’ll simply be beneath them. If anyone can now push a button on Codex / Claude Code and get a perfect score, what’s the point? No, they’ll just leave the 17 year olds to take the test on their own. (The open source models will still compete for another year or so. That’s my guess!)
Similarly, I think the labs pushing “research math” is also a fad that will expire soon enough. Think about it. GPT solved a major problem (Erdos unit distance); what they’re not reporting is the 1000 other problems they attacked and failed to make progress. [That’s not exactly deception; I also don’t report the dozens of things I tried to prove and failed…] They’re also not reporting the millions of dollars all of this cost them, and for what? Right now the “for what” is advertising: they’re signaling that they’re the best model for math, so you should use them for whatever your reasoning task is. Math departments also spend millions of dollars and produce theorems, but that is their actual end goal. A tech company is happy with a million-dollar theorem only if it predicts a billion-dollar application somewhere else. Once the bubble bursts, investors will want “real” applications from AI, new drugs, self driving / flying cars, etc etc. Nobody will care that the systems are also useful at proving theorems. Nobody but us mathematicians. So like the IMO, I think the frontier labs will get bored of theorems, and will leave us humans alone to keep doing math (and they’ll give us an amazing tool with which to do it!).
Does that make sense? What do you think?
45
28
401
46,711
Jun 11
调了一晚上,其实我觉得它单独作为一个更好的 session browser 也不错了,你可以通过 cli coding,但通过 app 回顾
虽然为了浏览 memory 的逻辑做的单页面,但话说回来其实我真不觉得人有在这种密集程度的对话流里切换的注意力(
对于 subagent / workflow 的 sub-session 支持在路上了,这几天应该就能 release!
1
1
17
3,354
Jun 11
Mimo Code 基于 OpenCode 开发,实现了不错的 session history 检索
和 Obelisk 一样,它采用 SQLite 的 FTS BM25,让 Agent 能知道自己过去在做什么,避免丢失关键决策信息
obelisk 则在这条路上走得更远:我们为 agent 提供了一个 retrieval query runtime,agent 可以自己编写代码来检索 session,灵活性大幅提升
现在,我们加入了 memory 功能,与传统 memory 不同,它其实是 synthesis cache:检索是昂贵的,如果它产生了稳定结论,agent 应该把这次综合结果写成 document,下次直接复用
所以 memory 的准确性非常重要
每条 memory 的写入和归档都必须经过人的确认,因为我们已经深刻体会到: 错误的 memory,比没有 memory 更干扰工作
之后还会更新一个基于 Electron 的控制面板,方便查看、追溯、归档这些 memory 它并不是必须的,但它可以直观让你看到, agent 正在复用哪些历史结论,这些结论从哪里来
我想,对 coding agent 来说,向量数据库 embedding 模型太重了,正在成为一种共识
我们会继续探索轻量级检索层的可能性,bring history back again
repo: github.com/tommy0103/obelisk
Jun 10

🚀 MiMo Code V0.1 is now live and open-source!
More than an AI coding assistant in your terminal — it's the smartest coding partner you'll ever work with.
Comes with MiMo V2.5, a multimodal model available free for a limited time, featuring a million-token context window—ready to use out of the box.
♾️ Infinite Context: Knowledge accumulates automatically, and with lossless compression, even million-line projects keep every critical detail intact—quality never drops.
🧠 Agent-Model Synergy: An Agent framework deeply optimized for MiMo, with a full closed loop of testing, review, and validation—so complex tasks get done in one pass.
📝 Compose Mode: Specs → Plans → Build → Report. Design first, code second—clear thinking, no rework.
🔄 Self-Evolving System: Every session is automatically reviewed, distilling experience and best practices—the more you use it, the smarter it gets.
🎙️ Voice Input: Powered by MiMo-V2.5-ASR — just speak instead of type, and your voice becomes the prompt for truly hands-free coding.
🔌 Claude Code Compatible: Automatically loads your existing skills, MCP servers and commands, and reuses your API configuration—zero-cost migration, no setup required.
🌐 Open & Flexible: MIT licensed, with support for leading model providers including Anthropic, OpenAI, DeepSeek, Kimi, GLM and more.
Install in one line:
Mac & Linux
curl -fsSL mimo.xiaomi.com/install | bash
(For the best experience,we recommand Mac user use it on iTerm or vscode terminal)
Windows
npm install -g @mimo-ai/cli
🔗 Learn more
Website ↓
mimo.xiaomi.com/mimocode
Blog ↓
mimo.xiaomi.com/zh/blog/mimo…
GitHub ↓
github.com/XiaomiMiMo/MiMo-C…

16
13
178
34,272
Jun 10
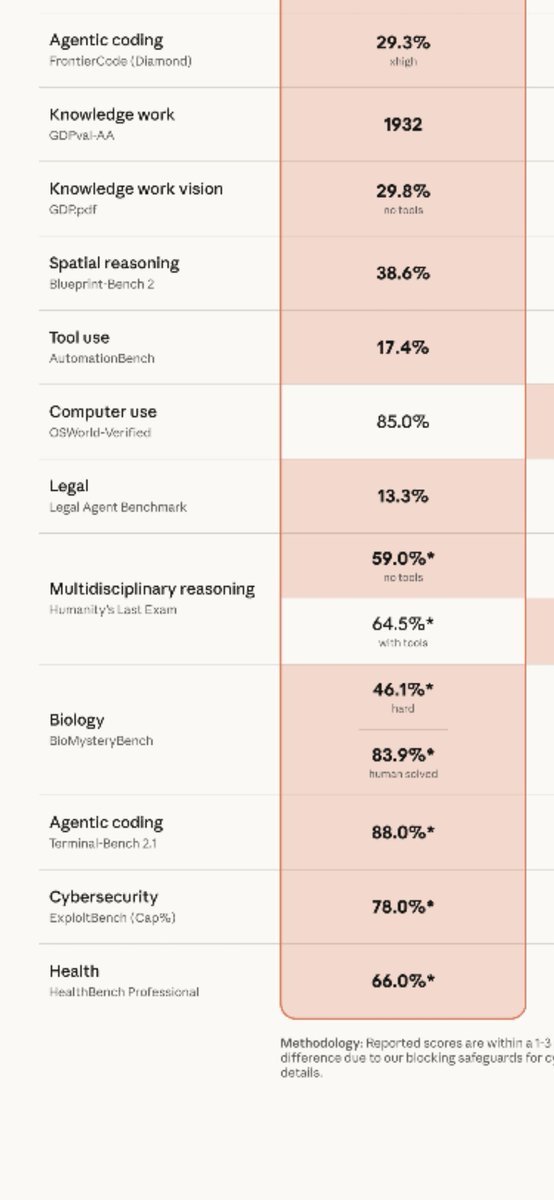
为什么我如此气愤,因为 anthropic 自己的宣传图上就写了,不保证可以复现 benchmark 上的分数
不是 fable 基础模型 fallback 约等于 opus4.8,而是它宣传它有远超于 opus 4.8 的能力,却悄悄标明你可能无法使用这种能力,这相当于是在欺骗用户
作为一个跑过 terminal bench 的人,这个 88% 的 terminal bench 分数我非常怀疑,这是一个很离谱的分数
为什么 anthropic 标明不可复现(分数上打了星号的都是会被 fallback 的):因为 terminal bench 里有不少生物 / 化学类的题目,fable 肯定会降级
最后是 anthropic 的 trick,把 mythos 5 的分数和 fable 5 放一起,这样你就不知道哪个是哪个
Jun 10

我觉得 fable5 开了个坏头
降级成 opus4.8,这意味着它的所有 benchmark 分数都是不可被除了 anthropic 之外的非授权组织验证的
那 benchmark 分数的公信力在哪里?
很难想象如果有一辆汽车,开在路上的时候被说,因为我们要避免汽车引擎的最先进数据被其他邪恶竞争者获得,所以我们会在*一些时刻*给汽车限速,因此你将无法获得和我们的评测结果相同的数据
52
8
170
28,674
Jun 10
我觉得 fable5 开了个坏头
降级成 opus4.8,这意味着它的所有 benchmark 分数都是不可被除了 anthropic 之外的非授权组织验证的
那 benchmark 分数的公信力在哪里?
很难想象如果有一辆汽车,开在路上的时候被说,因为我们要避免汽车引擎的最先进数据被其他邪恶竞争者获得,所以我们会在*一些时刻*给汽车限速,因此你将无法获得和我们的评测结果相同的数据
48
7
250
60,618
Yuu💖 retweeted

Jun 9
June 9th Researcher Reciprocity License
"if you train on it, you let us generate - reverse terms of use void"
Status quo
1. We teach frontier devs with ICLR/NeurIPS papers, OSS Github contributions
2. They use it to make frontier models
3. Then ban us from exploring our ideas
We need a new license, original thinkers can't be an underclass to a tyrannical researcher fiefdom
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

31
99
959
107,847
Yuu💖 retweeted

Jun 9
Brilliant idea! Next up: Apple randomly reboots your Mac if you're building competing tech, Gmail silently edits your email if you mention rival platforms, and Tesla Autopilot swerves if it detects you're working on self-driving cars.
All in the name of safety, of course. Because malicious actors controlling the world’s operating systems, inboxes and cars would be extremely dangerous!
Jun 9
mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy
101
764
6,771
356,900
Yuu💖 retweeted

Jun 10
Nowledge Mem v0.9 发布了 🥰
这是一次比较大的版本,而且这次 Mem 从邀测变成了公开 beta 哈。
这次除了憋了不少底层的优化重构之外,比较重要的新能力是
- 自演化的 Skills 结晶和创建
- 人格化长期 agent 范式的支持
- Mem Plus 订阅制
Skills 会从整个 Nowledge Mem 超图上的模式、特征里克制去找到适合变成 procedural memory、进而从中找到符合成为潜在 Skill 个体,并且在我们选择创建成为 Skill 之后,它依然会在使用过程中收集反馈、观察新的 Mem 上下文,给出后续优化补充的 Skill 迭代。
当然,我们也可以纳管导入一个已经有的 Skill、按需从头创建一个 Skill,这部分我们还在打磨,欢迎大家来试用哈。
---
对于多 Agent 编排系统,我们一直在研究怎么自然的去维护这些人格化 Agent 所需的上下文,让大家可以跨平台保持 Alice, Bob, Cindy 还是 Tony 的上下文,并且和你所有其他 ai 轨迹、上下文和知识复利互通。
以前,虽然对应的 harness 上连接了 Mem,互通复利的部分是没问题的,但是 Mem 是面向主人的上下文管理器(冥想盆),尽管有 space 来做隔离,但是实际上对于 Alice, Bob 这些应该有自己不同定位、Soul 的 agent 个体来说,非常不 native。
这次我们引入了 identity 下的类似于每一个 agent 的 soul/rule 的抽象,把曾经的 working memory(表现近期全局上下文)的机制扩充到了 context bundle,并且按照 agent identity 和全局做了细致的设计,希望可以很好地支持这种面向人格化角色个体的编排范式哈~
欢迎大家来体验、反馈!
---
最后是 Mem Plus,为了给到更多用户顺畅的体验,我们出了 这第一个订阅的 plan
Plus 里已经包含所有 AI model 的用量之外,我们还引入了 Nowledge Link 这个功能,它是一个我们管理的 tunnel ,让大家不用自己去折腾 tailscale/cf tunnel 就能一键方便地从手机、远程机器上访问你的 Mem
对于我们的 Lifetime Pro 的 License 来说,之前我提到过,它会一直存在下去的,作为对自己工作生活上下文的安全感保证,和 hard core knowledge worker 的最佳搭档,我们会一直保持买断制的计划,而且除非像 Nowledge Link 这种云资源的依赖,我们不会给买断制限制新的能力和功能哈,只不过,因为现在我们从内测期到了公测期,Pro License 已经涨价了,而且会阶梯式倒计时在过了这个阶段之后再次涨价哈。
再次感谢 Mem 的早期支持大佬们🥰🫡
Jun 10

Nowledge Mem v0.9 is out, and Mem is now in public beta.
No more invites. Download it, bring your own AI keys, and everything works. The free plan has exactly one limit: 50 memories.
Our biggest release yet, and the first with a subscription. Here’s what’s inside

50
15
90
40,133