
Joined March 2018
- Tweets 3,660
- Following 137
- Followers 1,820
- Likes 541
334 Photos and videos







Pinned Tweet

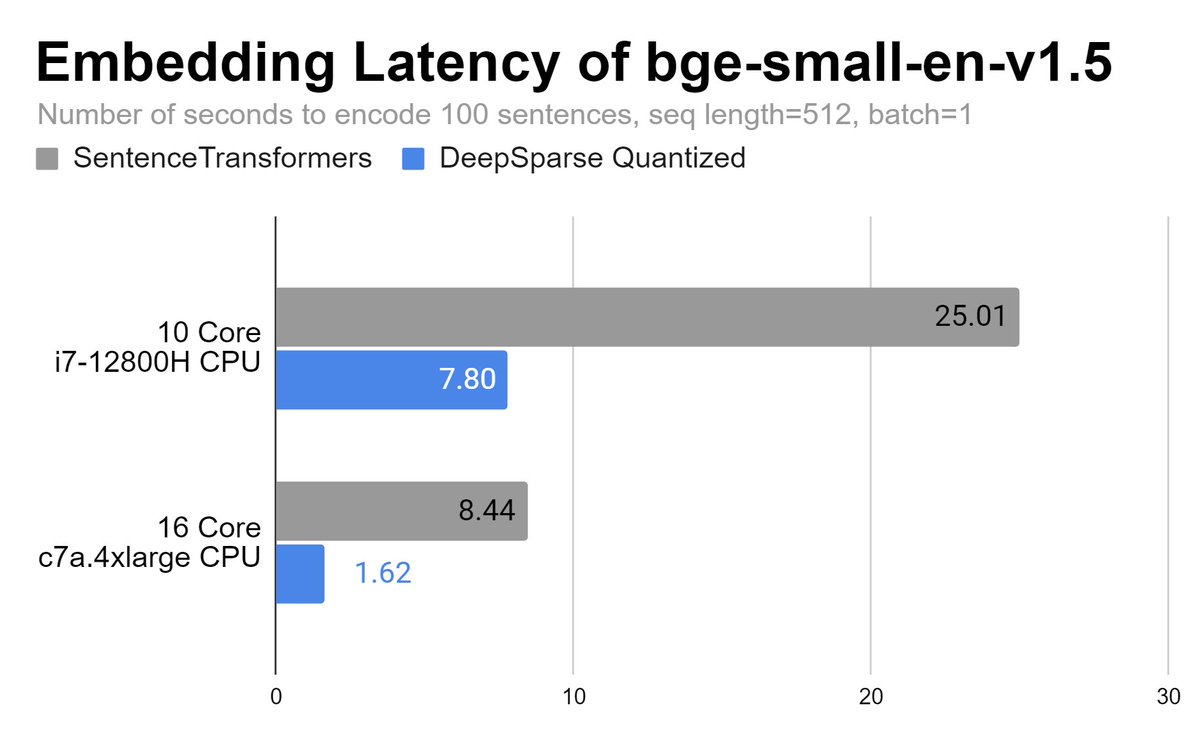
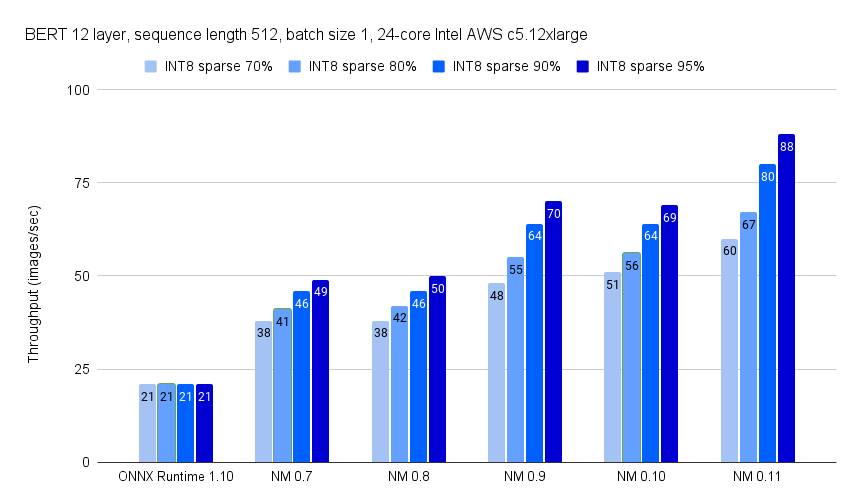
🚀🚀 Super excited to share the latest benchmark results for our quantized BGE models.
A few weeks ago, these models were introduced with the aim of enhancing performance and efficiency for generating embeddings. And we've now conducted thorough comparisons between running PyTorch SentenceTransformers vs. our DeepSparse-optimized models on both a 10-core laptop and a 16-core AWS instance.
The benchmarks have yielded significant improvements in processing speed. For example, running the bge-small quantized model on the 10-core laptop, achieves up to a 3X increase in speedup. What's even better, is that when tested on a 16-core AWS instance, these models achieved up to a 5X improvement.
🤗 Updated model cards:
bge-small-quant: huggingface.co/zeroshot/bge-… 6K downloads
bge-base-quant: huggingface.co/zeroshot/bge-… 2K downloads
bge-large-quant: huggingface.co/zeroshot/bge-… 2K downloads (#1 model for STS datasets on the MTEB leaderboard)
Don't forget to check out the DeepSparse repo github.com/neuralmagic/deeps… for more information on benchmarking and running these models on the MTEB leaderboard. 💥
cc @neuralmagic
2
10
1,623

I love the #ChatGPT Cheat Sheet by Ricky Costa (@Quantum_Stat)
which includes
🔹NLP Tasks
🔹Code
🔹Structured Output Styles
🔹Unstructured Output Styles
🔹Media Types
🔹Meta ChatGPT
🔹Expert Prompting
Get your hands on this amazing resource at:i.mtr.cool/ehyhxpfexx

1
4
279
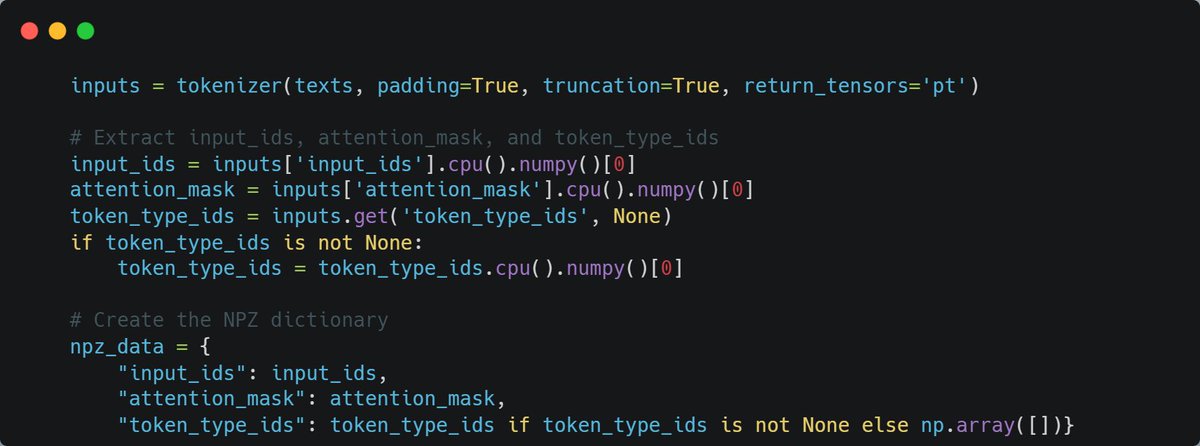
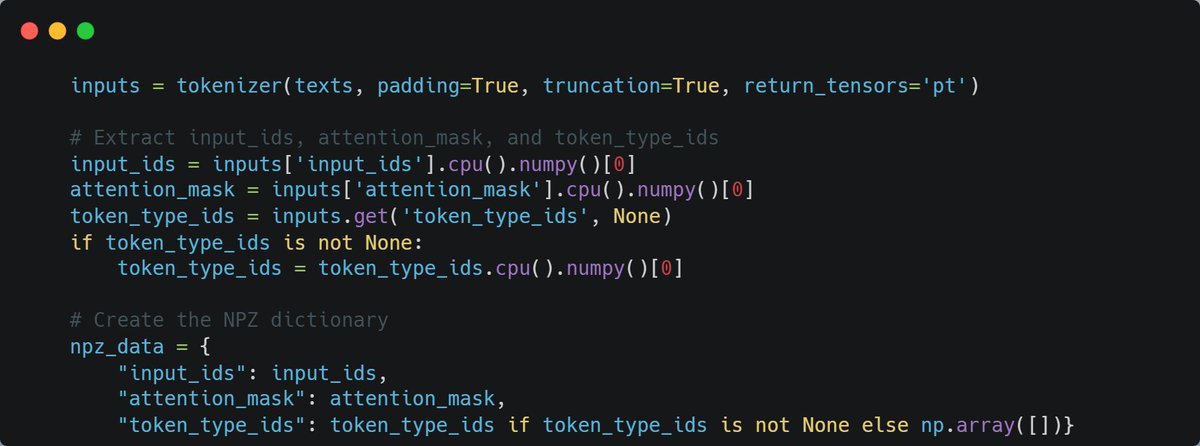
⚡Getting to Know the NPZ file format to Compress BGE Embedding Models ⚡
For One-Shot Quantization (INT8), Sparsify relies on the .npz format for data storage, a file format rooted in the mighty NumPy library.
2
1
4
433
Check the image below for an example of what I'm discussing 👇 We are soon releasing a notebook with an end-to-end example for anyone to replicate the compressed bge models which achieve great accuracy results on the MTEB Leaderboard.
1
135
90
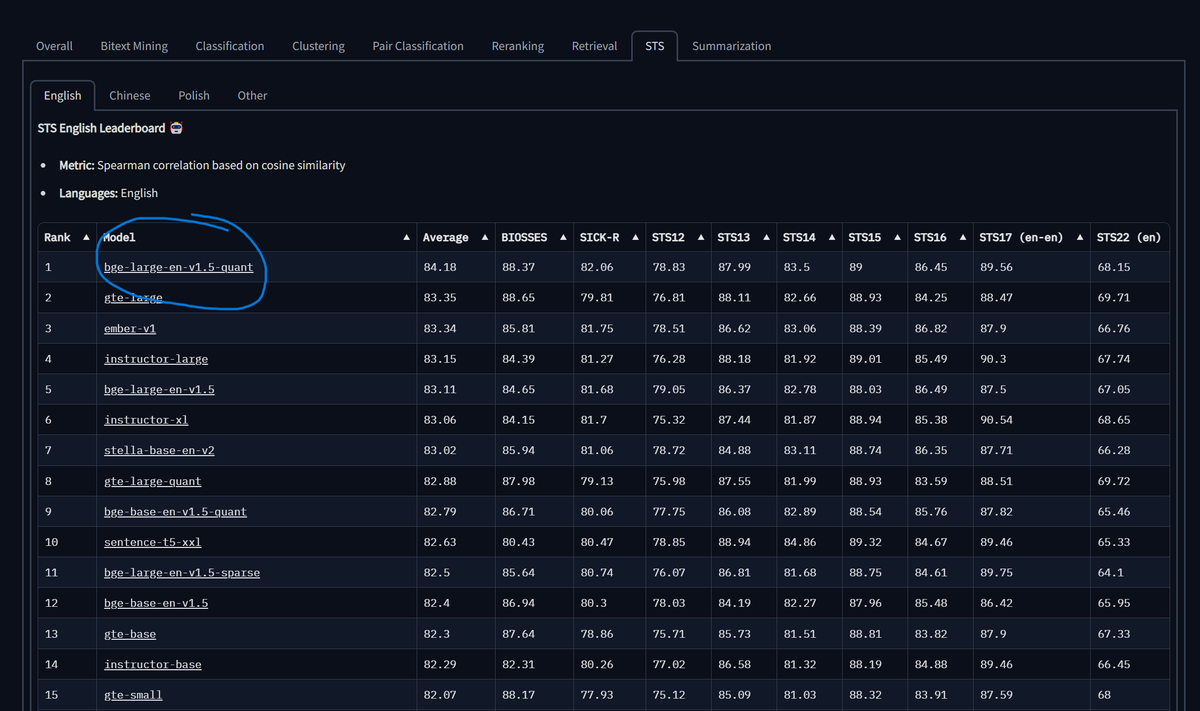
⚡IT HAPPENED!⚡
There's a new state-of-the-art sentence embeddings model for the semantic textual similarity task on Hugging Face's MTEB leaderboard 🤗!
Bge-large-en-v1.5-quant was the model I quantized in less than an hour using a single CLI command using Neural Magic's open
2
6
44
4,250
source library Sparsify! Not only is it ONNX and INT8 quantized (faster and lighter) but is able to run on CPUs using DeepSparse! 💥
cc @neuralmagic
Model: huggingface.co/zeroshot/bge-…
7
266
Exciting News! 🚀 DeepSparse is now integrated with @langchain , opening up a world of possibilities in Generative AI on CPUs. Langchain, known for its innovative design paradigms for large language model (LLM) applications, was often constrained by expensive APIs or cumbersome GPUs.
But with Neural Magic's DeepSparse integration, developers can now accelerate their models on CPU hardware, making it a breeze to create powerful Langchain applications.
Langchain Doc link: python.langchain.com/docs/in…
DeepSparse Langchain Blog: neuralmagic.com/blog/buildin…
cc @hwchase17 @neuralmagic
6
22
6,500
🌟First, want to thank everyone for pushing this model past 1,000 downloads in only a few days!! Additionally, I added bge-base models to MTEB.
Most importantly, code snippets were added for running inference in the model cards for everyone to try out!
huggingface.co/zeroshot/bge-…
5
318
lol
21 Oct 2023

Numbers 1-100 ranked, worst to best
100. 39
99. 41
98. 8
97. 43
96. 59
95. 74
94. 61
93. 89
92. 58
91. 12
90. 14
89. 19
88. 38
87. 71
86. 73
85. 55
84. 56
83. 37
82. 45
81. 76
80. 78
79. 96
78. 98
77. 87
76. 6
75. 68
74. 79
73. 85
72. 34
71. 42
70. 25
69. 18
68. 5
67. 84
66. 83
65. 65
64. 47
63. 53
62. 31
61. 52
60. 92
59. 91
58. 72
57. 46
56. 48
55. 23
54. 24
53. 15
52. 29
51. 51
50. 95
49. 16
48. 35
47. 64
46. 63
45. 75
44. 93
43. 13
42. 17
41. 32
40. 86
39. 62
38. 10
37. 57
36. 21
35. 20
34. 11
33. 36
32. 44
31. 90
30. 70
29. 49
28. 28
27. 27
26. 26
25. 9
24. 82
23. 81
22. 80
21. 97
20. 67
19. 66
18. 22
17. 30
16. 2
15. 50
14. 54
13. 40
12. 94
11. 60
10. 4
9. 88
8. 1
7. 77
6. 100
5. 33
4. 7
3. 99
2. 69
1. 3
1
242
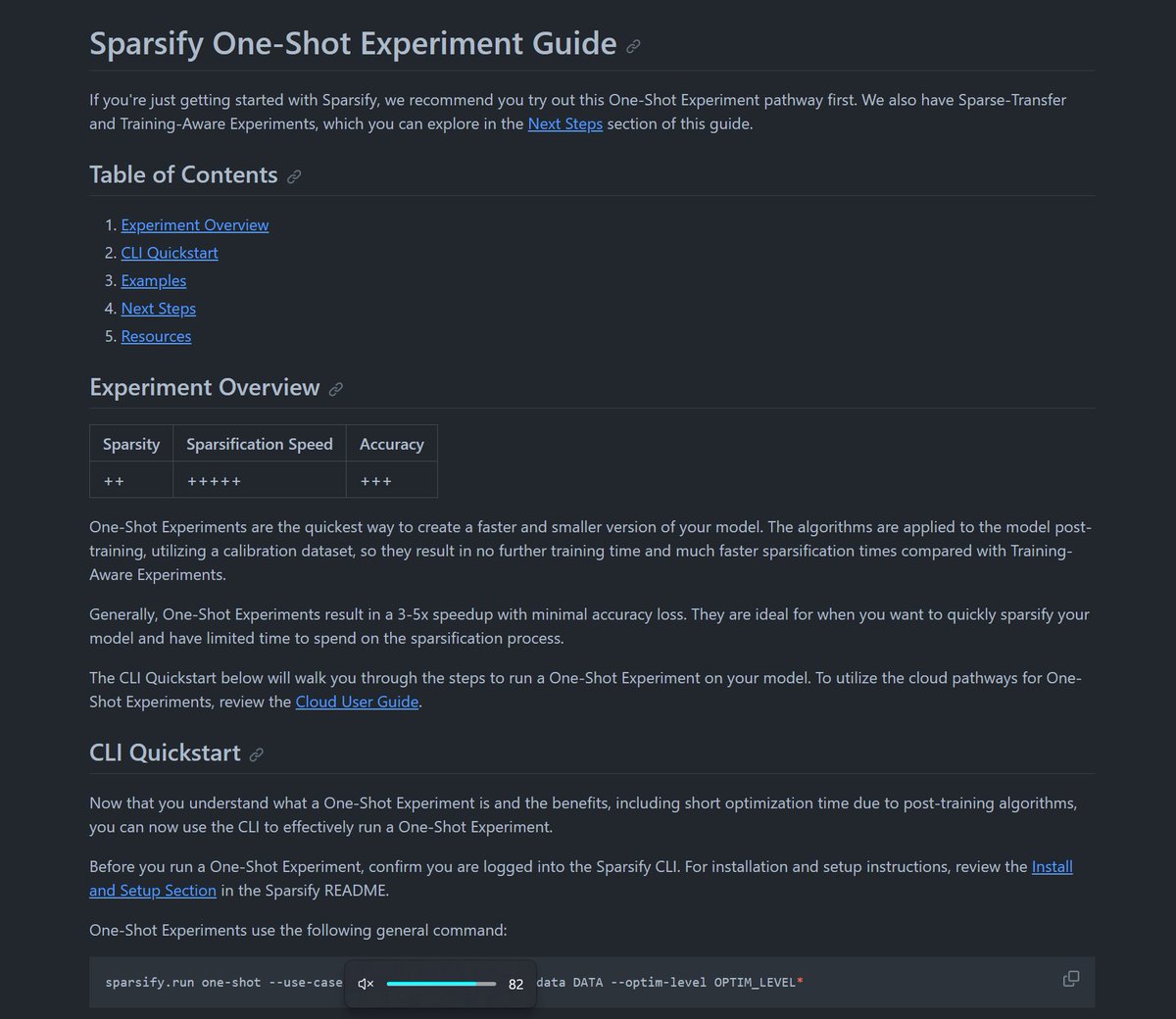
🚀🚀 Explore Sparsify's One-Shot Experiment Guide!
Discover how to quickly optimize your models with post-training algorithms for a 3-5x speedup. Perfect for when you need to sparsify your model with limited time and improved inference speedups.🔥
**FYI, this is what I used to compress the bge-small-en-v1.5model for sentence embeddings . **
1️⃣ **Experiment Overview**: Learn about the benefits of One-Shot Experiments and how they work for transformers and soon LLMs.
2️⃣ **CLI Quickstart**: Get started with a step-by-step guide on running One-Shot Experiments using the Sparsify CLI with a single command :)
3️⃣ **Data Prep**: Guide for understanding how to turn samples from your calibration dataset into NPZ files from your tokenizer's output.
4️⃣ **Next Steps**: Explore other Sparsify pathways, including Sparse Transfer and Training Aware Experiments.
5️⃣ **Link**: github.com/neuralmagic/spars…
💪 #AI #MachineLearning @neuralmagic
1
5
218
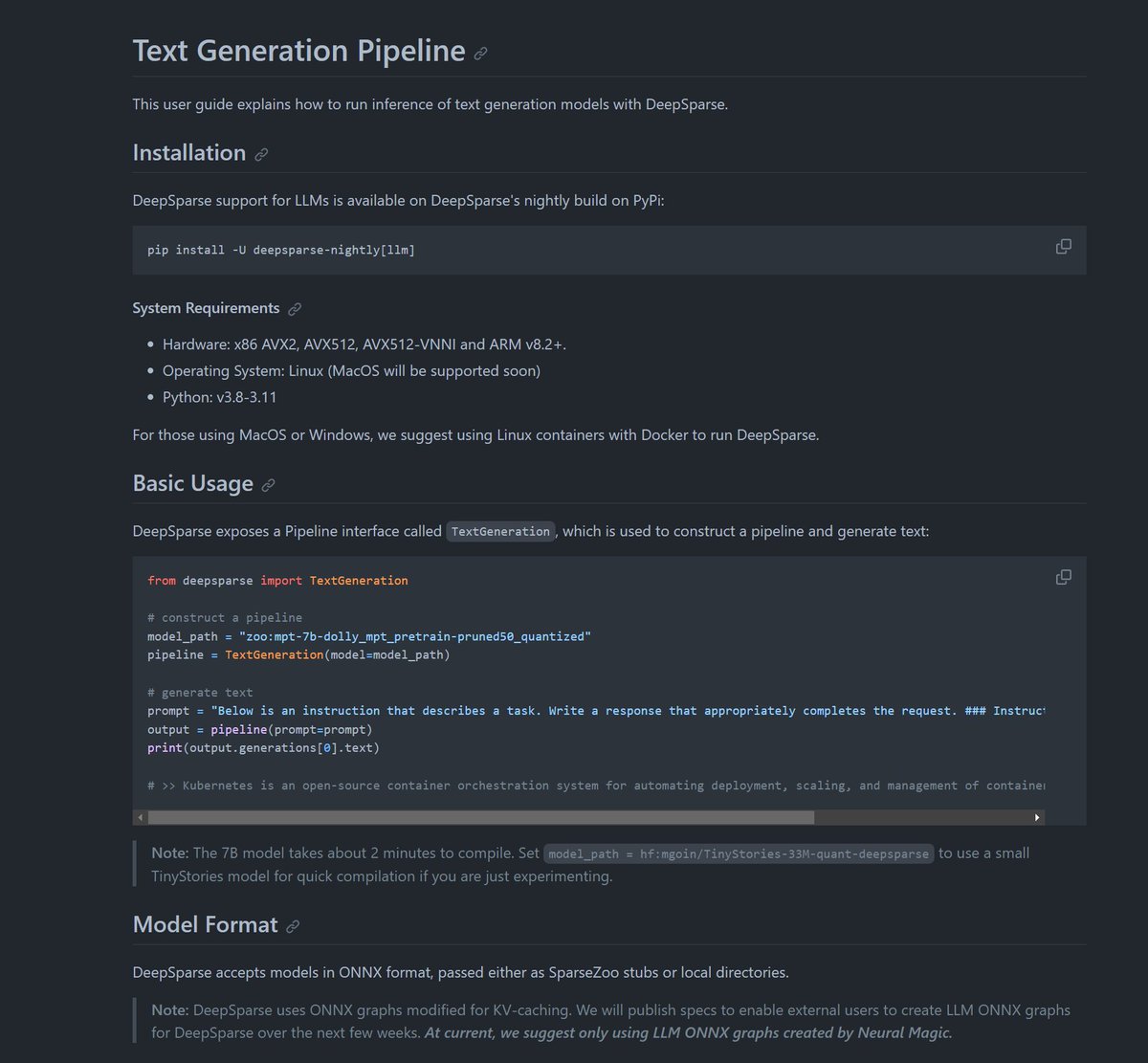
🚀🚀 Hey, check out our blog on @huggingface 🤗regarding running LLMs on CPUs!
The blog discusses how researchers at IST Austria & Neural Magic have cracked the code for fine-tuning large language models. The method, combining sparse fine-tuning and distillation-type losses, resulted in a lean and lightning-fast model that shines on CPUs. Achieving 75% pruning without accuracy loss. They overcame challenges like loss spikes with SquareHead distillation and showcased its power using @neuralmagic's DeepSparse inference runtime.
huggingface.co/blog/mwitider…
1
6
402
🚀✨ Run CodeGen on CPUs with this detailed Colab notebook! 📝
Explore how to sparsify and perform Large Language Model (LLM) inference using Neural Magic's stack, featuring Salesforce/codegen-350M-mono as an example.
Dive into these key steps:
1️⃣ **Installation**: Quickly set up Sparsify and DeepSparse.
2️⃣ **ONNX Export**: Download and export the model to ONNX for optimization.
3️⃣ **Apply One-Shot Pruning and Quantization**: Optimize the model with Sparsify's FastOBCQ algorithm.
4️⃣ **Evaluate Accuracy**: Assess model accuracy using deepsparse.transformers.eval_downstream CLI for perplexity calculation.
5️⃣ **Inject KV Cache**: Improve inference speed with KV-caching in the ONNX graph.
6️⃣ **Run Inference With DeepSparse**: Execute text generation using DeepSparse.
notebook: github.com/neuralmagic/docs/…
1
3
240