
Joined November 2025
- Tweets 313
- Following 28
- Followers 2,546
- Likes 895
19 Photos and videos










Pinned Tweet

Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
16
59
225
35,386
Pushing this harder than ever!
Jun 11

Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
3
10
79
2,169
Quasar retweeted

Jun 12
Most large language models are surprisingly forgetful.
@QuasarModels (SN24) — built by SILX AI — is trying to fix that at the architecture level: linear-time attention, ~2M-token context, no fragile position embeddings.
Memory at the protocol layer.
→ taoprotocol.org/quasar-sn24-…
$TAO @opentensor

9
48
1,492
Quasar retweeted

Jun 11
TEN TRILLY:
Quasar moving toward a 10T-token decentralised training run on Bittensor SN24.
Phase 1: 5T tokens to produce a stronger checkpoint.
Phase 2: another 5T tokens on top.
If successful, this would be one of the largest token-scale training runs in decentralised AI.
Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
11
96
3,746
Quasar retweeted

Jun 11
A 10T-token run has never happened in the history of decentralized AI
But Quasar is special. Quasar has its own unique architecture, and we are nerdy enough to achieve such a task
We’ll share how we made this possible and exactly when it begins.
Keep an eye out
Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
2
12
63
2,164
Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
16
59
225
35,386
Jun 11
training.silxinc.com/
Keep an eye on our account and Discord
We will be sharing updates as the training system rolls out It will not become effective immediately.
First, we will share the design, roll out the system, run tests, and then fully switch over once everything is ready.
2
3
23
1,117
Quasar retweeted
Jun 8
Let’s fucking go
Jun 8
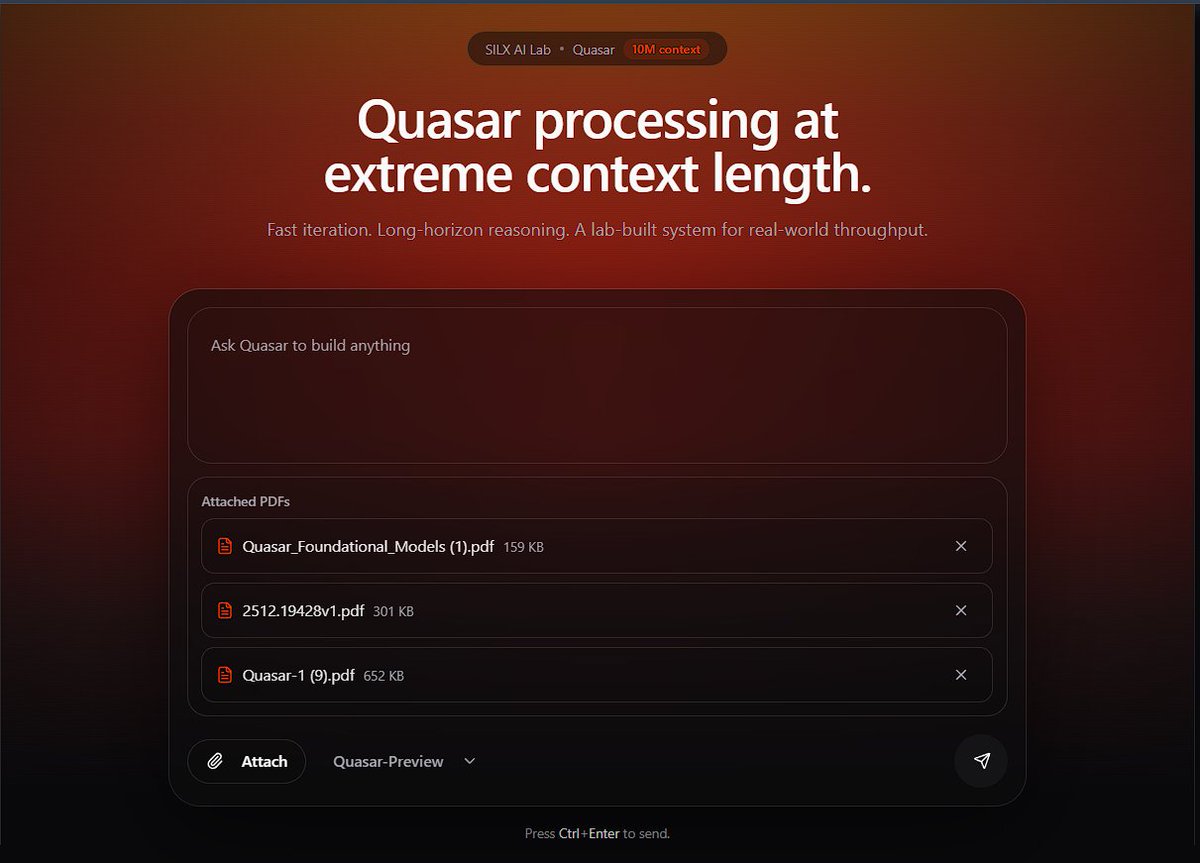
Today we’re releasing Quasar-Preview!
Our first public proof that the Quasar architecture works at real scale.
[ 18B MoE - 2B active / 5M context ]
Built with Loop Transformer Quasar attention
Trained on Bittensor through decentralized infrastructure 👇
3
19
2,712
Quasar retweeted

Jun 8
Going to sleep now. I’ll be uploading a lot of updates and repos for the model and subnet.
Have a good night, everyone.
3
5
62
1,990
Quasar retweeted
Jun 8
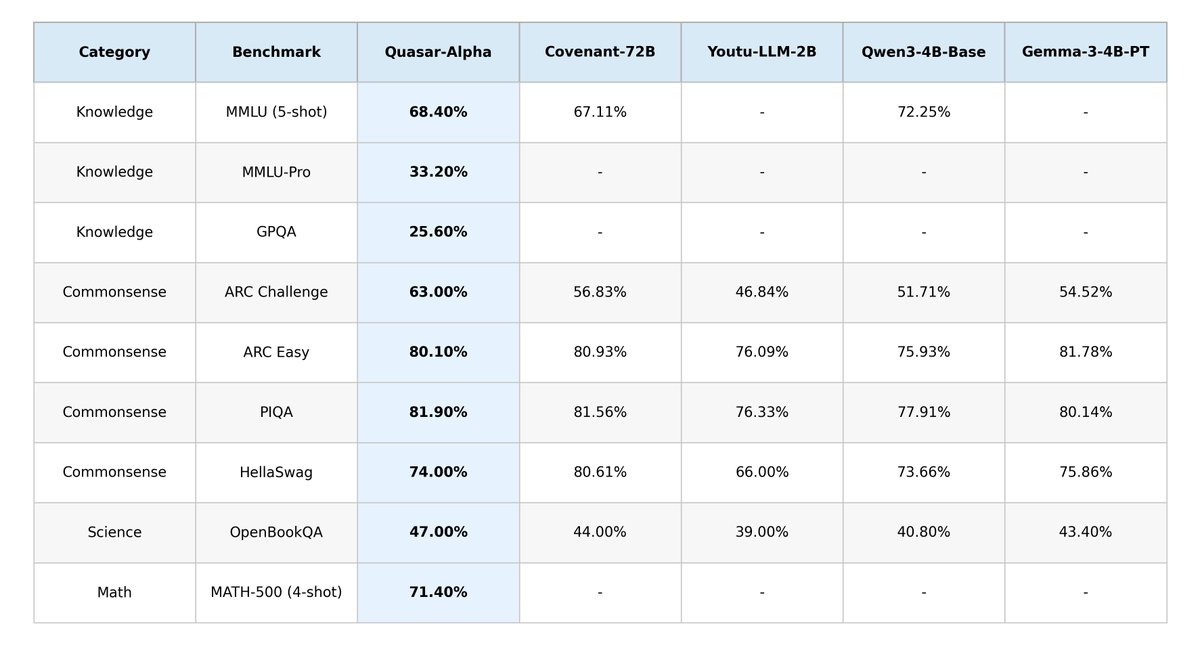
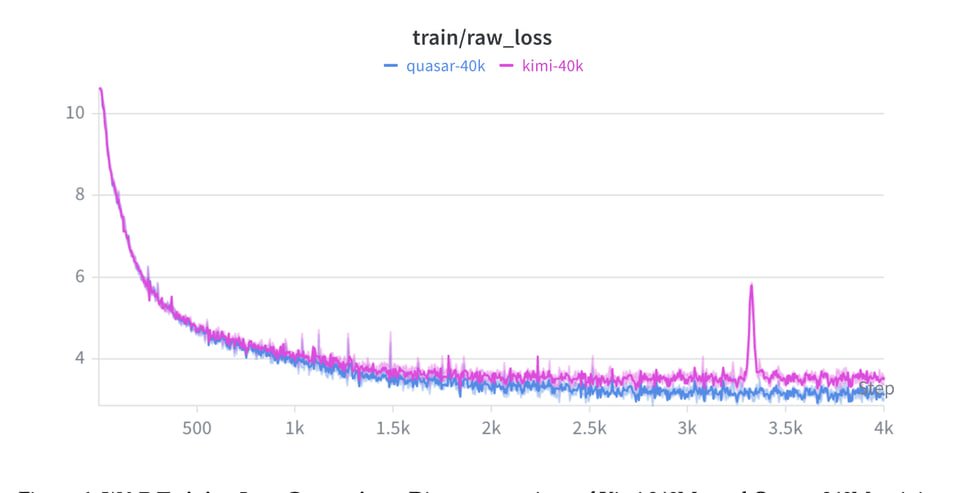
This is a very early Quasar model, trained on only 0.1% of our full token budget, so there is still much, much more room to improve!
Jun 8
Today we’re releasing Quasar-Preview!
Our first public proof that the Quasar architecture works at real scale.
[ 18B MoE - 2B active / 5M context ]
Built with Loop Transformer Quasar attention
Trained on Bittensor through decentralized infrastructure 👇
17
9
121
4,829
Quasar retweeted

Jun 8
5M context length agentic model from Quasar.
Jun 8
Today we’re releasing Quasar-Preview!
Our first public proof that the Quasar architecture works at real scale.
[ 18B MoE - 2B active / 5M context ]
Built with Loop Transformer Quasar attention
Trained on Bittensor through decentralized infrastructure 👇
13
67
371
16,861
Jun 8
Today we’re releasing Quasar-Preview!
Our first public proof that the Quasar architecture works at real scale.
[ 18B MoE - 2B active / 5M context ]
Built with Loop Transformer Quasar attention
Trained on Bittensor through decentralized infrastructure 👇
46
102
932
116,683
Jun 8
While the model has seen fewer than 1.5T tokens, it already shows amazing performance and reveals the strength of the new Quasar long-context architecture, supporting up to 5M context.
The model is still early let’s push it forward together!
3
8
90
4,975
Quasar retweeted

Jun 6
🚨 Pay attention to Quasar SN24 $TAO going after one of AI’s biggest structural moats, Compute Efficiency.
Most LLMs hit the same wall attention scales horribly with long context, making it expensive and controlled by a few of the biggest clusters.
Quasar is destroying that wall straight-up with continuous-time and linear attention architectures designed for much more efficient long-context scaling.
Then comes the true nature of Bittensor:
SN3 Teutonic handles decentralized pretraining.
SN24 Quasar supplies the architecture and distillation layer.
One subnet trains it
The next refines it.
This subnet composability in action makes specialized markets into full production stacks, and it constantly gets underestimated until it's NOT.
If linear attention holds quality while slashing costs, quasar isn’t just building a better model because many think that's all it is.
That’s the kind of bet that compounds into the future
$TAO
DYOR
Jun 4
SN3 is now training Quasar models.
This time, we’re starting with a 10B model built on the new Quasar architecture an architecture we believe represents the future of LLMs, especially for long-context reasoning and memory.
Quasar is designed to push models beyond short-window intelligence and into systems that can truly handle massive context, retain structure, and reason across long sequences.
We’re calling on miners to help us take the best out of this architecture, improve it, optimize it, train it harder, and push Quasar models forward round after round.
Let’s build state of the art.
3
11
64
5,553
Quasar retweeted

Most people still see Bittensor as another AI project.
That couldn't be further from the truth.
Bittensor is building a decentralized intelligence economy where incentives coordinate the creation, evaluation, and distribution of AI at global scale.
The network already spans multiple sectors:
Compute Infrastructure
@TargonCompute (SN4) is powering the foundation of decentralized AI through secure and confidential compute. By enabling reliable, privacy-preserving computational resources with proven real-world demand and revenue generation, Targon demonstrates how decentralized infrastructure can support the next generation of AI applications at scale.
Inference
@chutes_ai (SN64) has established itself as one of the leading decentralized AI inference platforms, providing serverless model serving for text, image, and multimodal applications. Processing trillions of tokens and serving hundreds of thousands of users, it demonstrates how decentralized infrastructure can compete with traditional AI providers on scale, efficiency, and accessibility.
Foundation Models
@QuasarModels (SN24) is advancing the frontier of AI training through long-context foundation models and novel architectures designed for deeper reasoning and improved memory. Its work pushes the boundaries of what decentralized AI development can achieve.
Autonomous Agents
@ridges_ai (SN62) is building autonomous AI agents and coding systems that learn, compete, and improve through incentive-driven environments. These systems represent an important step toward AI that can perform increasingly complex tasks with minimal human intervention.
Drug Discovery
@metanova_labs (SN68) is applying decentralized AI to one of humanity's most important challenges, discovering new medicines. By coordinating global computational resources to screen millions of molecules and evaluate billions of potential drug-target interactions, NOVA is accelerating research in mental health, neurodegeneration, and other critical areas while reducing the cost of pharmaceutical innovation.
Real Estate Intelligence
@zipcodenetwork (SN46) is bringing decentralized intelligence to the $400 trillion real estate market, transforming property validation, analysis, and credit infrastructure into an AI native ecosystem powered by open participation.
What makes all of this possible is Bittensor's incentive layer.
Bitcoin used economic incentives to coordinate a global network of computing power.
Bittensor applies the same principle to intelligence itself.
Researchers, developers, miners, validators, and businesses are rewarded for contributing valuable outputs, creating a system where innovation scales naturally without centralized control.
And these sectors represent only a fraction of the network's potential.
Healthcare. Scientific research. Robotics. Financial intelligence. Data infrastructure. Enterprise AI.
Entire industries remain largely untapped.
Bittensor is not just building AI applications.
It is building the incentive engine for a decentralized intelligence economy.

2
11
973


Quasar retweeted
Jun 4
We are taking over Bittensor
Decentralized AI subnets will realize that the Quasar architecture is the best foundation for training the future of long-context reasoning.
long-context reasoning coming out of Bittensor SN24!
Jun 4
SN3 is now training Quasar models.
This time, we’re starting with a 10B model built on the new Quasar architecture an architecture we believe represents the future of LLMs, especially for long-context reasoning and memory.
Quasar is designed to push models beyond short-window intelligence and into systems that can truly handle massive context, retain structure, and reason across long sequences.
We’re calling on miners to help us take the best out of this architecture, improve it, optimize it, train it harder, and push Quasar models forward round after round.
Let’s build state of the art.
4
7
70
3,985
Jun 4
SN3 is now training Quasar models.
This time, we’re starting with a 10B model built on the new Quasar architecture an architecture we believe represents the future of LLMs, especially for long-context reasoning and memory.
Quasar is designed to push models beyond short-window intelligence and into systems that can truly handle massive context, retain structure, and reason across long sequences.
We’re calling on miners to help us take the best out of this architecture, improve it, optimize it, train it harder, and push Quasar models forward round after round.
Let’s build state of the art.
12
35
151
24,023
