
Joined June 2024
- Tweets 6,930
- Following 2,655
- Followers 1,533
- Likes 32,552
467 Photos and videos












τroy retweeted

Pushing this harder than ever!
Jun 11

Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
2
7
73
1,933
τroy retweeted

10h
@QuasarModels @MacrocosmosAI @TargonCompute @chutes_ai @affine_io @actualinc …
Decentralized Decentralized AI
10
47
284
7,743
τroy retweeted
Jun 13
And just like that we collectively saw the future of inequality
55
266
2,569
292,386
τroy retweeted

Jun 12
Claims will be SN 111. We're super excited to join the network! Thank you to everyone who supported and believed in us so far. Now we'll roll up the sleeves and start making it happen. 🔥
24
12
95
15,231
τroy retweeted

Jun 12
They've been busy
Jun 12

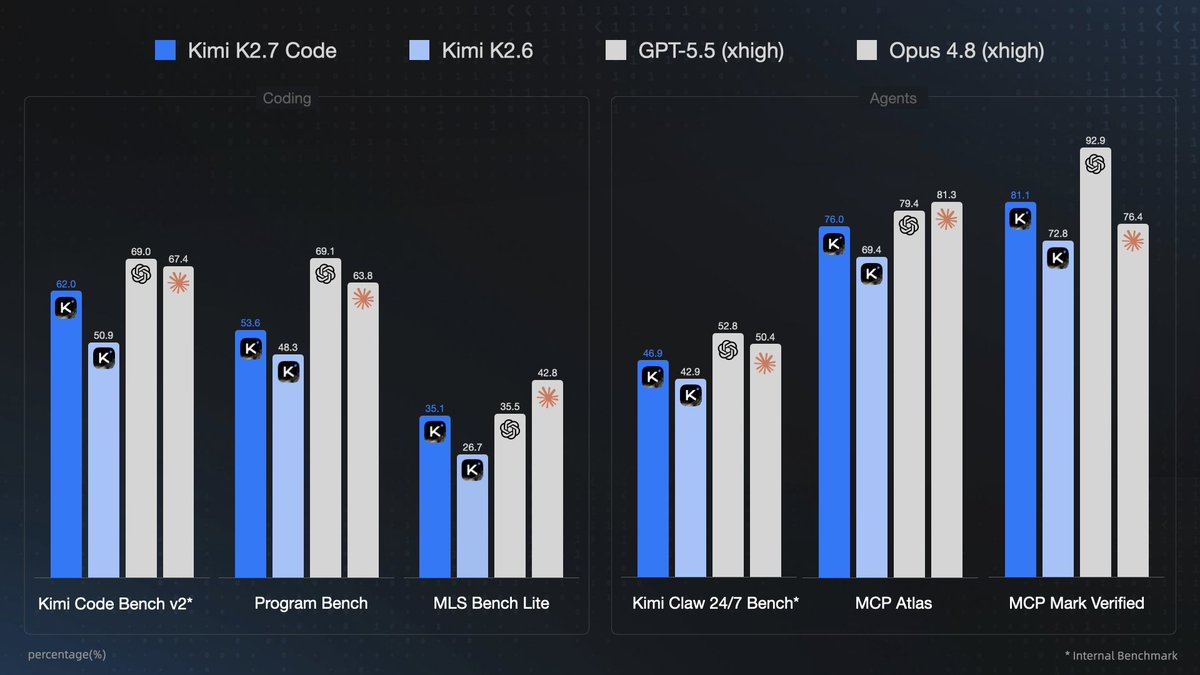
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


7
4
132
9,552
τroy retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai
587
1,588
13,318
1,836,910
τroy retweeted

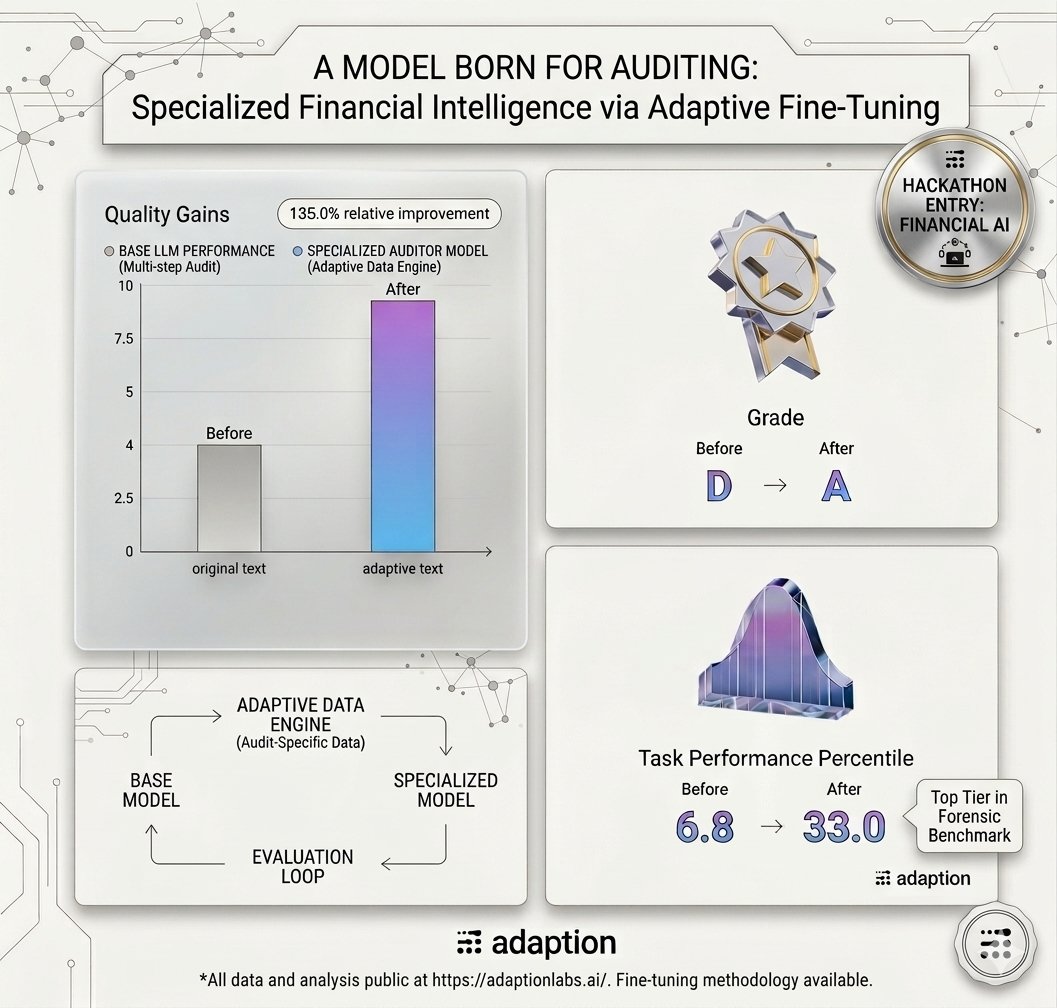
Submitted my Financial Forensic Auditor for the AutoScientist Challenge 2026!
Fine-tuned gpt-oss-20b to process corporate 10-K sheets using step-by-step reasoning traces.
Huge thanks to @sarahookr & @adaption_ai for the open compute!
HF Model: huggingface.co/asadullahdoga…
1
2
9
1,338
τroy retweeted

Jun 11
We're not just happy to open source the work we're doing, as we're operating #SN15 on Bittensor, it's critical to the success of our business. Here's why:
1. AI models will transact on your behalf. This is already happening more than most people realise. It's paramount that we understand how they transact and why they purchase what they purchase. Only open source allows us to do this.
2. Our moat comes from the recurring post-training pipeline that takes the best agents of yesterday and distils the intelligence into a model that you and I can use. If someone tried to take the same model and distribute it. They wouldn't have access to the flywheel of data that we do.
This open-source flywheel is going to allow us to combine the intelligence and resources of the greatest minds in the space and move faster than the incumbents.
Jun 11

We've talked a lot about how our efforts to train AI to shop will be entirely open source. Through Bittensor, we're committed to that ethos.
We're excited to share our pre-print on arXiv, our code, our data and our entire post-training pipeline.
Huge shoutout and thanks to @JarrodBarnes in helping us leverage this very valuable data.
This is how AI is going to learn to shop.

1
3
14
817
τroy retweeted

Jun 11
TEN TRILLY:
Quasar moving toward a 10T-token decentralised training run on Bittensor SN24.
Phase 1: 5T tokens to produce a stronger checkpoint.
Phase 2: another 5T tokens on top.
If successful, this would be one of the largest token-scale training runs in decentralised AI.
Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
11
96
3,734
τroy retweeted

Excellent work by the team.
You’re not just making Bittensor proud you’re making the entire world of decentralized AI proud.
What you’re building goes far beyond a single subnet or ecosystem. It represents a future where intelligence is open, permissionless, and not controlled by a handful of centralized entities.
This journey may belong to only a few today, but that won’t last for long.
In the years ahead, more and more people will seek alternatives to centralized AI, and they’ll discover that the foundations were already being built by the pioneers of decentralized intelligence.
The future is being written now, and Quasar is helping lead the way. 🚀
#Quasar #SN24 #Bittensor #DecentralizedAI #TAO
Jun 11

This is our new design for the future of Quasar models
using every bit of power Bittensor can offer to make Quasar a SOTA model.
We do not need to win against closed ones, but we do need a fair fight.
Let’s do it!!
Keep an eye on this. We’ll be sharing the design and a lot of tests together soon.
1
2
31
1,141

let's get started..

Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
3
2
30
967
τroy retweeted

Jun 11
A 10T-token run has never happened in the history of decentralized AI
But Quasar is special. Quasar has its own unique architecture, and we are nerdy enough to achieve such a task
We’ll share how we made this possible and exactly when it begins.
Keep an eye out
Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
2
12
63
2,161

Jun 11
This is our new design for the future of Quasar models
using every bit of power Bittensor can offer to make Quasar a SOTA model.
We do not need to win against closed ones, but we do need a fair fight.
Let’s do it!!
Keep an eye on this. We’ll be sharing the design and a lot of tests together soon.
Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
4
7
71
3,530
τroy retweeted

Jun 11
NEWS: @QuasarModels drops Quasar-Preview, first public proof Quasar works at scale.
Built on Loop Transformer Quasar attention, trained on Bittensor through decentralised infrastructure
Jun 8
Today we’re releasing Quasar-Preview!
Our first public proof that the Quasar architecture works at real scale.
[ 18B MoE - 2B active / 5M context ]
Built with Loop Transformer Quasar attention
Trained on Bittensor through decentralized infrastructure 👇
2
10
58
2,767

τroy retweeted
Jun 10
Cool, but I prefer optimization competitions where you own the company rather than work for it.

15
36
237
11,580
τroy retweeted

Jun 9
this is the biggest wake-up call to protect and nourish open source AI
if you don't build out sovereign and independent models infra closed labs will patronize you to an insulting degree
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

36
273
1,992
69,444
τroy retweeted

21 Sep 2022
huge ideas that promise near-infinite gain in theory often lead to colossal disasters in practice
10
17
190
τroy retweeted

Jun 9
I've been at Anthropic through every model launch. There's been a few cases I can remember of a launch that stands out and marks a step-change in how we use models:
- Claude Opus 3
- Claude Sonnet 3.5
- Claude Opus 4.5
And now Claude Fable 5.
With Fable, the model stopped feeling like a tool I direct and started feeling more like something I collaborate with.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
193
128
3,275
605,165
τroy retweeted

Today, we're introducing Claude Fable 5 and Mythos 5, two configurations of our next major language model.
I'd normally highlight the numbers: It's SOTA on nearly all benchmarks. I want to talk about something else, because with Fable 5 out in the world, I think a third era quietly started today.
I lead Claude Code & Cowork on the desktop, so I think a lot about how people use AI to get work done. I believe we're about to see a major shift, moving from giving AI tasks to giving it responsibilities.
215
376
5,879
761,974