
Professor of Electrical and Computer Engineering at Tel Aviv University. On Sabbatical at Apple AI Research. Interested in AI, multimodal and signal processing
Joined September 2020
- Tweets 378
- Following 78
- Followers 475
- Likes 1,080
25 Photos and videos











Pinned Tweet

24 Jul 2025
I’m excited to be spending my sabbatical at #Apple, collaborating with Vladlen Koltun and the team on a range of cutting-edge AI projects. Looking forward to this new chapter!
3
95
14,790

Video Analysis and Generation via a Semantic Progress Function
paper: huggingface.co/papers/2604.2…
2
22
157
34,458
Raja Giryes retweeted

Apr 27
with the Semantic Progress Function (SPF) you can MEASURE the semantic change.
so, is GPT-Image-2 good enough? 👀
x.com/galmetz/status/2048756…
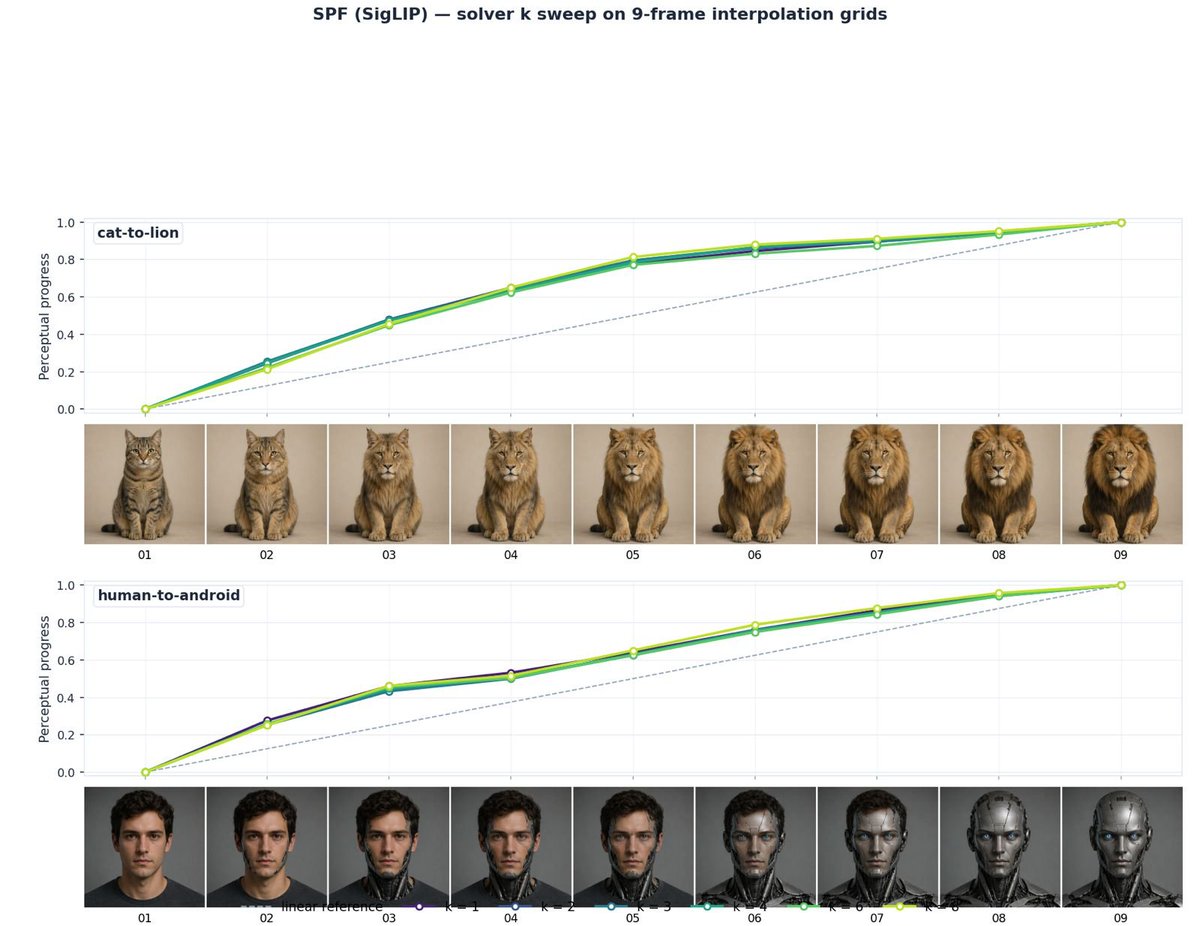
Apr 22

it worked better than I expected lol
first prompt:
> generate a 3x3 grid, of a cat transforming into a lion. top left image of a cat, bottom right image of a lion, and each image in the grid the cat looks more and more like the lion. the images are perfectly aligned, only the subject changes.
2nd 🫠:
> the same, but a human transforming into a robot


1
13
1,015
Raja Giryes retweeted
Apr 27
fresh out of the oven 🔥✨
see the two videos below? with the 'Semantic Progress Function' (SPF) you can finally ANALYSE (and control!) the semantic progression of First-to-Last-Frame video generation.
Apr 27

Excited to share our work accepted to #SIGGRAPH2026 ! Video generation models struggle with something few talk about: their transformations don't evolve smoothly. You get long boring stretches... then a sudden semantic jump where everything "catches up" at once.
1
1
33
5,394
Raja Giryes retweeted

Apr 27
Excited to share our work accepted to #SIGGRAPH2026 ! Video generation models struggle with something few talk about: their transformations don't evolve smoothly. You get long boring stretches... then a sudden semantic jump where everything "catches up" at once.
7
27
72
5,604

Raja Giryes retweeted

Mar 31
Our paper Guided Lensless Polarization Imaging was accepted to #CVPR2026 (Findings) 🎉📸

1
5
7
326
Raja Giryes retweeted

Mar 31
super excited this it out! lots of fun insights, tips, and tricks on how all parts of the RL stack, from policy gradient in general, to policy staleness, to clipping, to numerics, all modulate entropy some principled control strategies to stabilize!
Mar 30

Our ICLR 2026 paper "Entropy-Preserving Reinforcement Learning" is now on arXiv.
We strike at one of the core RL issues: exploration in action space.
We study why token distribution entropy collapses in LLM post-training preventing further exploration and we propose fixes!
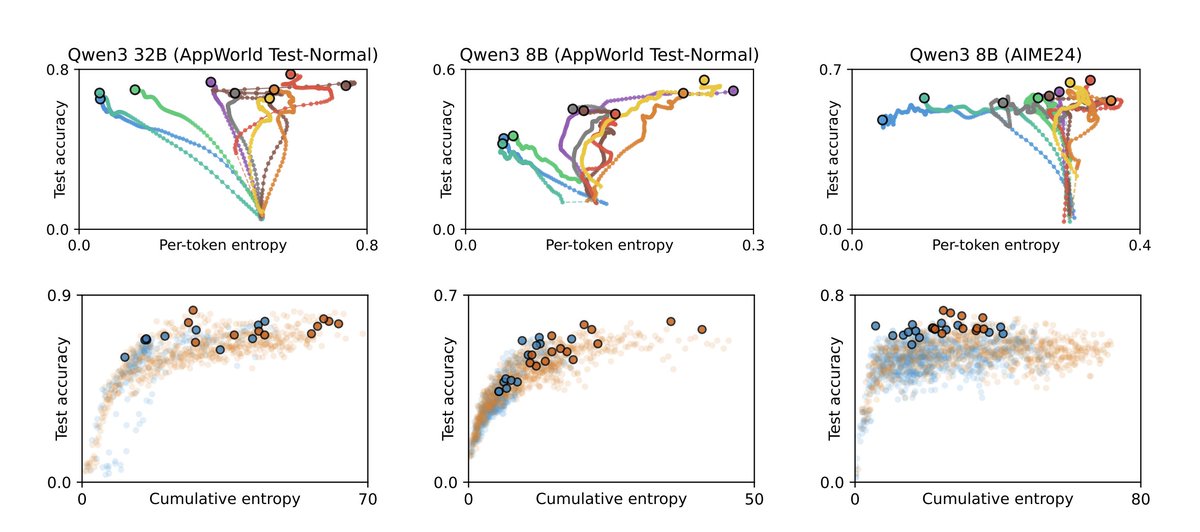
3
20
3,954
Raja Giryes retweeted

Mar 30
Our ICLR 2026 paper "Entropy-Preserving Reinforcement Learning" is now on arXiv.
We strike at one of the core RL issues: exploration in action space.
We study why token distribution entropy collapses in LLM post-training preventing further exploration and we propose fixes!
9
40
332
27,966
Raja Giryes retweeted

Mar 24
Introducing Look Where It Matters — High-Resolution Crops Retrieval for Efficient VLMs.
VLMs don't need to process full high-res images. AwaRes uses tool-calling to retrieve only the high-res regions needed to answer a given query🧵
arxiv.org/abs/2603.16932 nimrodshabtay.github.io/AwaR…

3
9
20
1,156
Raja Giryes retweeted

Mar 12
🎙️ Introducing ID-LoRA: the first open-source model to jointly generate a video with a person's appearance and voice in a single pass from just a reference image short audio clip. No more cascaded pipelines where the audio can't follow your prompt.
youtu.be/6bWcMh18K6g?si=_Dgj…
3
11
23
2,178
Feb 18
By observing how many people are using Claude Code outside the domain, we might paraphrase the old saying: when the shoeshine boy starts talking about Claude Code, the traditional role of coding is nearing its end.

Anthropic Boris Cherny:
Coding is practically solved today, and soon it'll be for everyone, in any domain
"the software engineer title will be replaced by builder or product manager"
The upper bound is much scarier, where models that recursively self-improve could be used to design bioviruses
1
1
207

Raja Giryes retweeted
Feb 1
1/3 🎉 Our paper is accepted at #ICASSP2026!
TL;DR: Speculative decoding struggles for speech because exact token matching is too strict: acoustically similar tokens get rejected. We propose a fix.
machinelearning.apple.com/re…
1
7
11
428
Jan 30
Moltbook is interesting, but at its core it’s a more sophisticated version of Conway’s Game of Life. It may serve as a benchmark for comparing LLMs/prompts, or for insights into social interaction; beyond that, there’s probably less there than many people claim or want to believe
1
534

(1/n)
📢 Excited to share that our paper:
“Does the Data Processing Inequality Reflect Practice? On the Utility of Low-Level Tasks” (arxiv.org/abs/2512.21315)
has been accepted to #ICLR2026 🥳 !!!
Kudos to my amazing student Roy Turgeman!
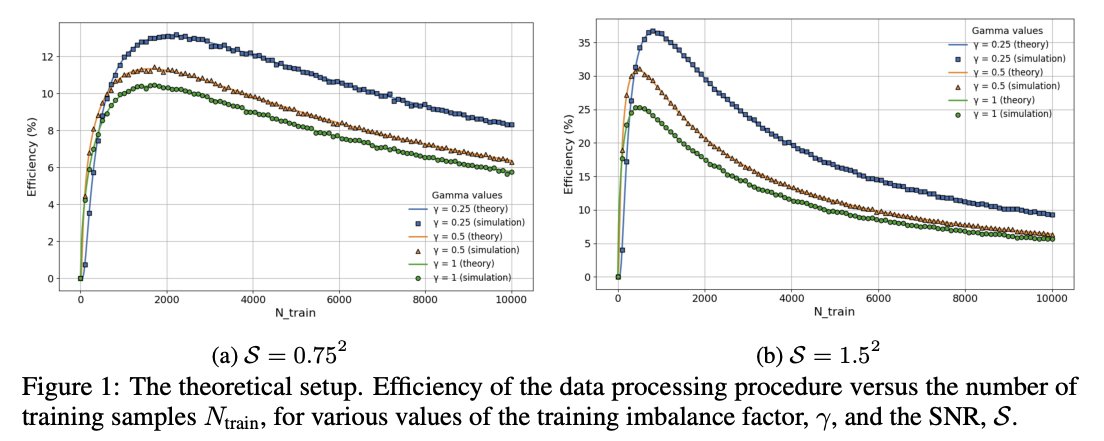
1
1
7
305
Jan 27
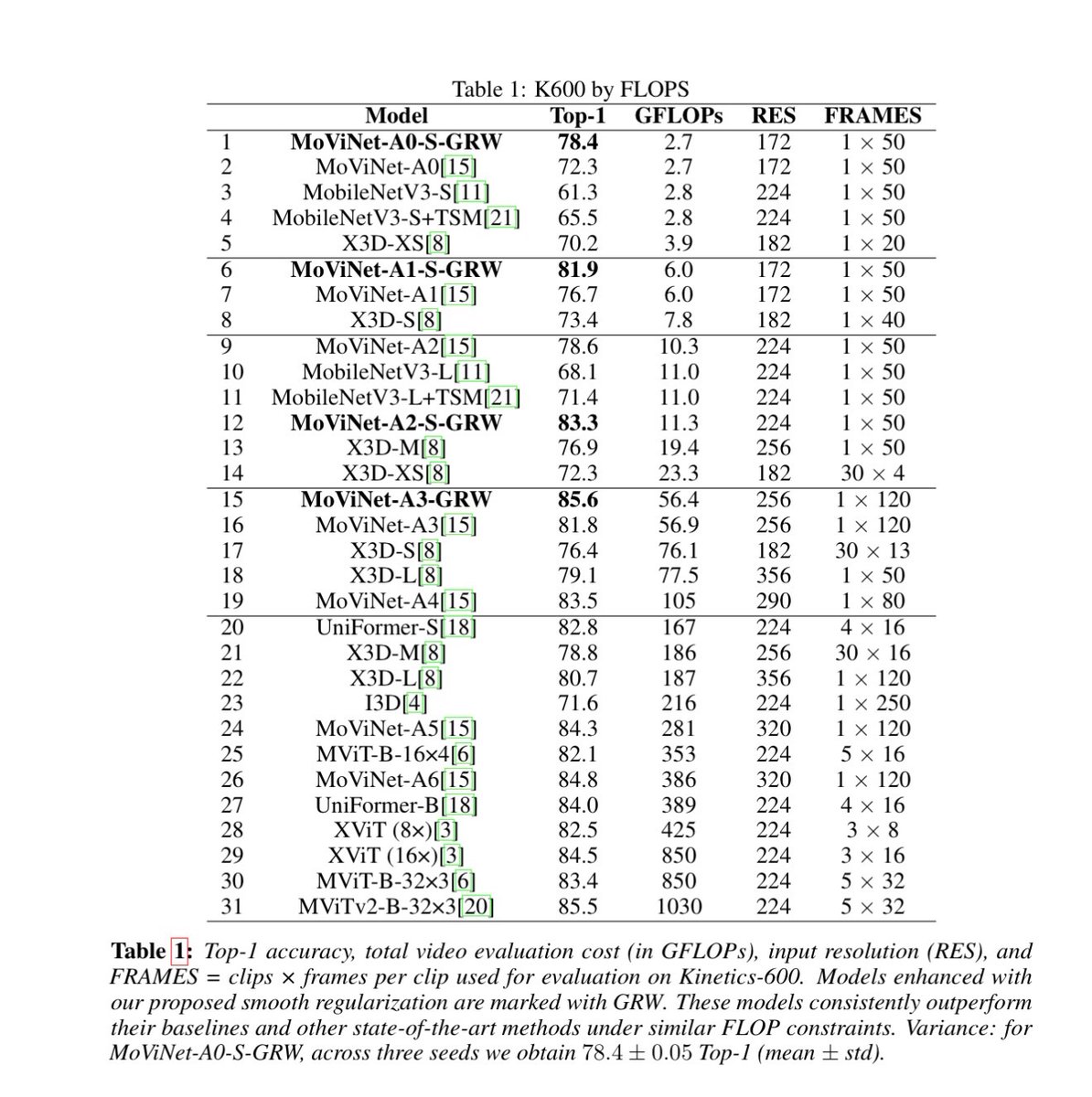
We’re releasing the pretrained weights for our small video recognition models, achieving state-of-the-art for lightweight video recognition.
They’re trained with GRW-smoothing, a simple technique that guides optimization toward solutions that are smooth functions of time.
3 Dec 2025

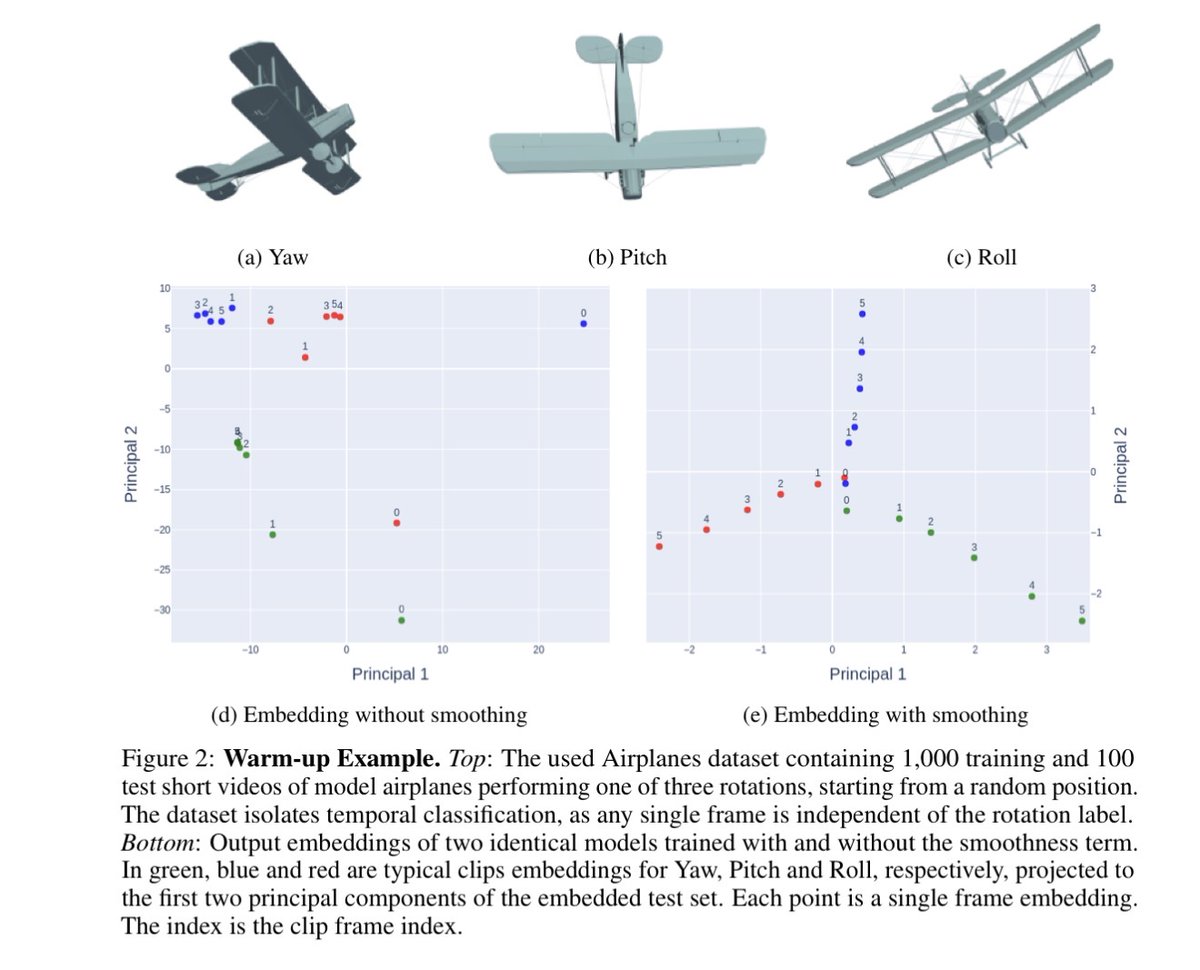
Excited to share that our work "Smooth Regularization for Efficient Video Recognition" has been accepted to #NeurIPS2025! 🎉
TL;DR: We present a new SOTA for efficient video models by enforcing temporal smoothness, boosting accuracy by up to 6% without adding inference cost. 🚀
1
3
146
Jan 27
📄 Details code checkpoints: github.com/cmusatyalab/grw-s…
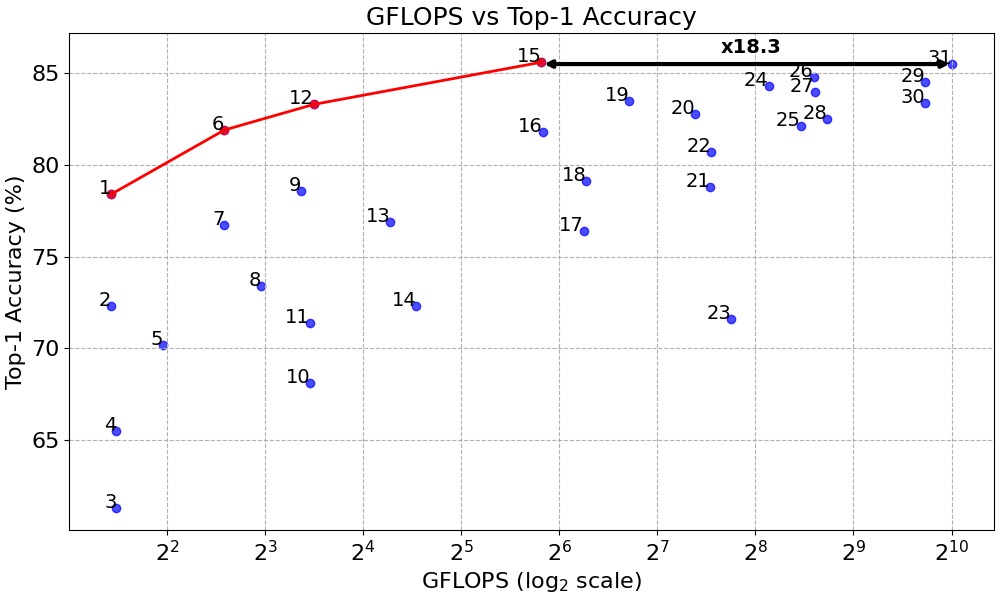
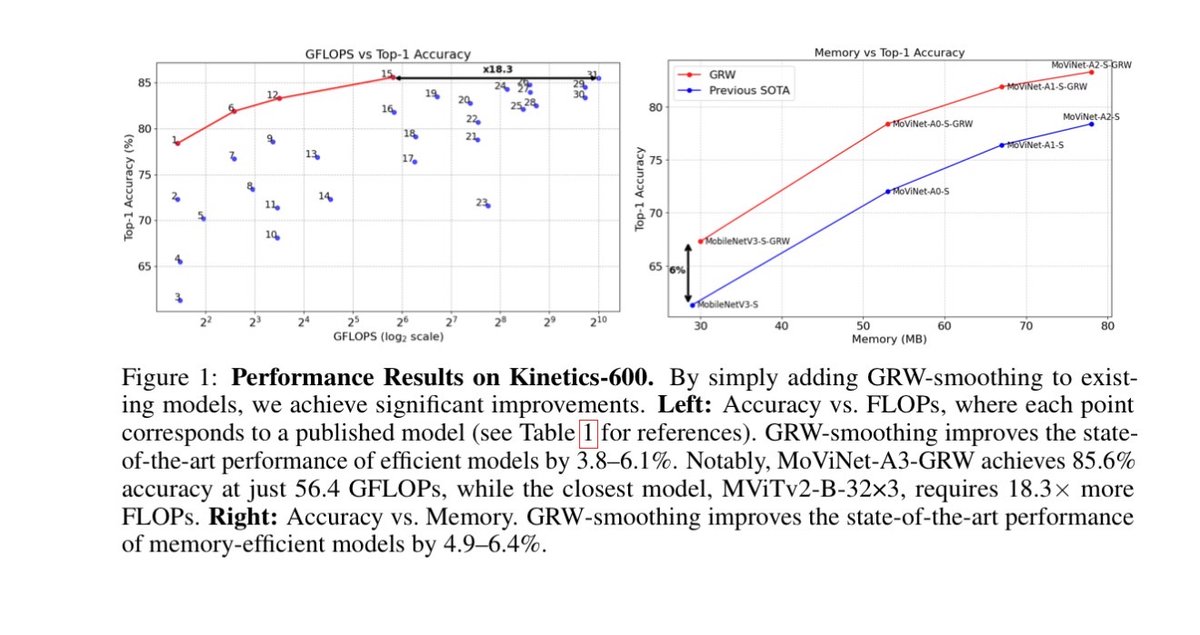
Below: Results on Kinetics 600. The red line shows our models pushing the efficiency frontier compared to other published models (blue dots) in the 2-1000 GFLOPs range.
2
68
Jan 26
Israel Computer Vision Day is live! 🎥
It features the research of Israel's leading computer vision labs.
Watch here: m.youtube.com/watch?v=2fEDy-…
#ComputerVision #CV #AI
4
265
Raja Giryes retweeted
Jan 15
Excited to share CLIMP - the first fully Mamba-based contrastive vision-language model. Unlike CLIP's ViTs, Mamba's state-space formulation favors locality & smoothness—better retrieval and OOD robustness.
with @ItamarZimerman, @Eli_Schwartz and @RGiryes
arxiv.org/abs/2601.06891
1
12
14
692

Our paper "MetaGen" is on the front cover of @ACSPhotonics latest issue!
Greatful to @ACSPublications and to my collaborators and advisors, @yosef_erez, Dan Raviv, @RGiryes and Jacob Scheuer!
Details below 👇

2
8
12
1,027