
2,294 Photos and videos
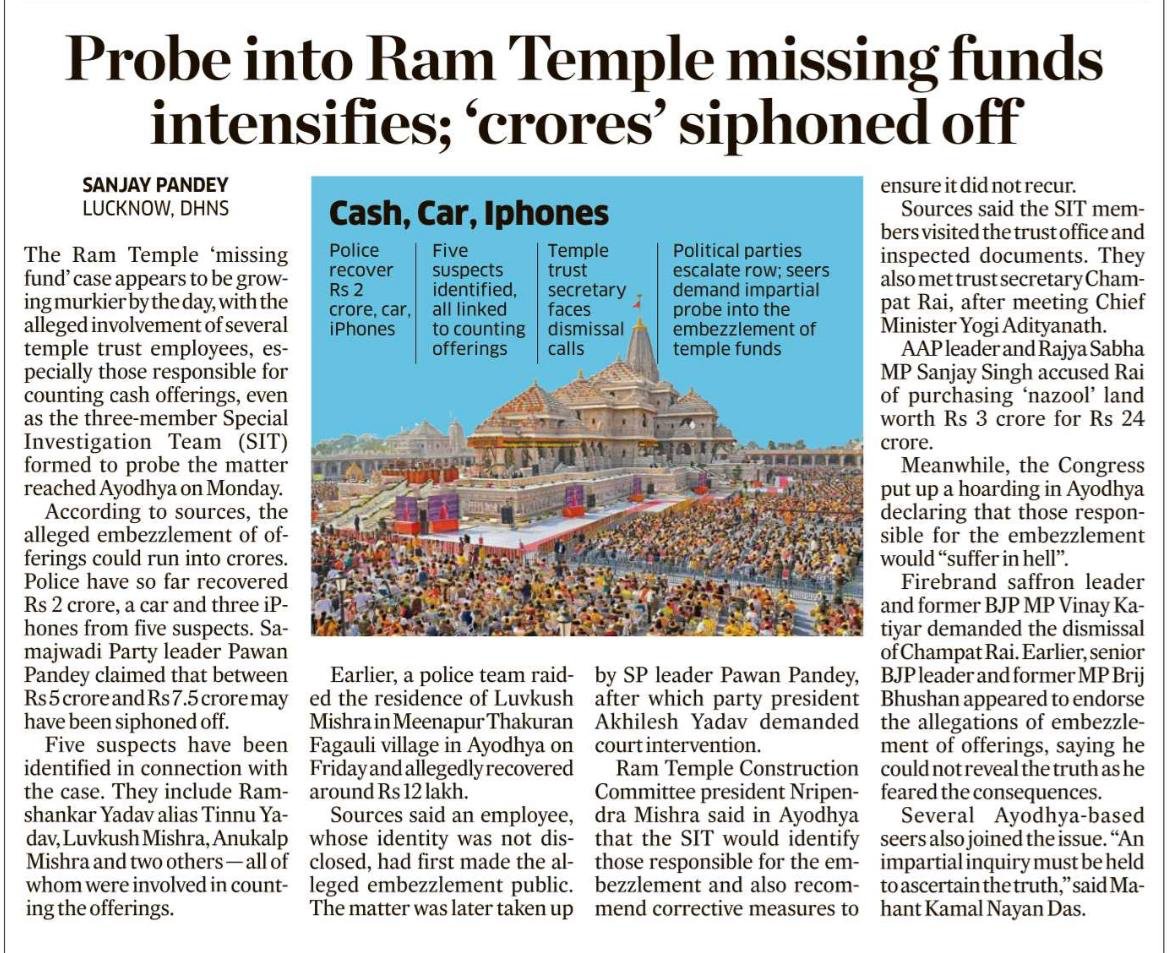











Happy to share my article for Vice about censorship. It is based on my own experiance of getting banned by LinkedIn for absolutely no fault of mine. 5 months later LinkedIn restored my account with an apology. How did this happen? Read here.
vice.com/en/article/dy8m9z/l…
8
9
35
Aaron 🌪️ retweeted

Such a blot on this World Cup. FIFA lets the US do their thing
Iran manager Amir Ghalenoei- "We spent so much time in the air commuting, they didn't even give us time to recover. After the game today, they said to us you have to leave immediately. It's very important for us to have time for recovery, but we've been told to return to our camp in Tijuana and we are really troubled by that. I think perhaps our team is the most repressed team in the whole World Cup."
goal.com/en-in/lists/most-re…
5
247
632
20,525
Cabo Verde's Hero Goal Keeper couldn't have his family in the stadium because of discriminatory Visa rules of US. This is naked racism basically. FIFA enabled it.

Cape Verde goalkeeper Vozinha after his man-of-the-match display against Spain:
"I cried after the game because I grew up with my grandparents when I was a kid, and they could not be there. They passed away a few years ago.
"My mum could not be here either for a VISA issue, and the money we had to pay for it. We did not manage to do this in time."

25
Lmao.

The BIG difference between cricket and football is that the European Union consists of different countries, whereas the Indian Union consists of different states. That is why football appears to be a global sport.
Otherwise, it is largely a two-continent sport, and because it is easy to understand, it has built a diverse fanbase around the world.
Cricket could easily have a 48-team World Cup if the Indian Union were made up of different countries like the European Union. Maharashtra, Karnataka, Delhi, Tamil Nadu, and several other states could become proper Test nations within a few years.
If the West Indies were split, they could field 6 international teams that would be highly competitive in T20 World Cups.
And if Wales were separated from the ECB, cricket would gain another European World Cup team.
So, Cricket if not to football levels still is far more global than many people think.
18
No, Indian Football is a specific term. It means Football of India or played in India. Includes National team as well as Indian First Division and local league matches plus Santhosh Trophy among other things. All Football fans from India aren't Indian Football's fan or follower.

Dumb guilt-tripping as ever from the Indian Football community. Football fans in India will automatically become Indian Football fans as well, in large numbers, if there’s something in Indian football to actually be a fan of.
1
75
No water breaks weren't a discretion of refferee. It was decided by both the team captains in Europe prior to the game. Once decided there isn't discretion involved.
Jun 15

Oh my friend... That was at the discretion of the refree... This is mandatory. Know the difference...Also - Be informed.
You are welcome to look that up 👍
16
Aaron 🌪️ retweeted

For all the joy of Cape Verde winning let's not forget that Vozinha was denied celebrating this win with his family because if you come from Cape Verde, you have to pay $15,000 dollars for the privilege of maybe being allowed into the US, something his mother didn't have.
Virtually every Cabo Verdean without a foreign passport were in the same position.
26
758
4,654
107,894
Aaron 🌪️ retweeted

Incredible result. Would've been even better if Zee5 hadn't cut to the ads almost 10 seconds after it ended, making sure we didn't see any emotional post-game scenes.
Happens when people who don't know football run those teams
26
149
2,483
31,278
Aaron 🌪️ retweeted

Malayali women dancing in government buses on tax payer's money: "Kerala is writing history 😍"
Gujarati women dancing in Kochi water metro after paying full ticket price: "Gujjus have no civic sense 🤬"

50
137
1,431
38,651
Aaron 🌪️ retweeted

As the FIFA World Cup is going on, a reminder:
Football fans from India ≠ Indian football fans.
81
262
2,851
90,814
Aaron 🌪️ retweeted

Jun 14
Apparently, Hindi is the first language of Kerala now according to Indian Railways!!? 🤌🏾
reddit.com/r/NewKeralaRevolu…


9
3
67
22,751
If India defeated Turkey or any team in a Fifa World Cup. Actually if India so much as qualify for the WC, we will celebrate it unlike anything the country has seen. Bigger than the 2011 win.
Jun 14

Six ODI World Cups barely moved Australia, but one FIFA World Cup victory had them celebrating like it was their first major trophy. Insult to cricket.
99
Aaron 🌪️ retweeted

Jun 14
He didn’t meet the family members of 3 Indians killed by USA but went to France for his PR.
Shameless PM
Jun 14

🎥#WATCH | PM Modi’s joyful moments with a kid during warm reception in Nice, France
#NarendraModi #IndiaFrance #DiasporaConnect #Nice
214
1,484
8,194
89,359
Aaron 🌪️ retweeted

Jun 14
The autowala can behave like this because his children are not American citizens, and he has no funders that the US govt can threaten to prosecute for fraud.
Jun 14

“Don’t put anything related to America’s propaganda on any auto. Our fellow Indians are being killed,” says auto drivers tearing down Donald Trump’s posters on autos across Delhi that were placed by the U.S. Embassy
10
350
2,467
27,145
Aaron 🌪️ retweeted

Jun 14
Compromised PM के राज में एक भारतीय होने का मतलब दुर्गति है।
विदेशी ताकत हमारे नागरिकों को मारती है। हमारी सरकार एक आज्ञाकारी नौकर की तरह चुप-चाप आदेश मान लेती है - और हमारे नागरिक सड़ने के लिए छोड़ दिए जाते हैं।
इस भारतीय को घर लाइए। अभी।
Jun 14
“This is the dead body of our second officer. He died two days ago and his body is decomposing. We reached out to the Indian Embassy but haven’t got a positive response. Our company is hiding from us,” says Indian captain of MT Celestial anchored in Oman
647
10,096
29,035
479,728
Aaron 🌪️ retweeted

Jun 13
And here is Laal Aankh response by US Secretary of State Marco Rubio.

Jun 12

Spoke to US Secretary of State Marco Rubio this evening. I reiterated India’s strong protest at the attacks by the US Navy in the Gulf that killed three Indian mariners. Such lethal actions against commercial shipping are not justified.
183
2,409
8,327
155,973
Did you pay for the Rs 300 Fancode ISL 1 season subscription pack a few months earlier? I guess not. No use complaining about it now.
Jun 12

I cannot able to digest that Syria is higher ranked than India in football
How come civil war torn failed country scores more than us 4th largest GDP
49
Moroccan scout network is called La Fabrica, it is located in Madrid and operated by Real Madrid. Other Spanish and French clubs also chime in 😂.
Jun 13

That’s a gross oversimplification, something not expected of you! Be more objective
Moroccan scout network is among the best in the world, even if they operate in Europe
Where’s Kerala’s analytics driven scouting framework? Admit the fault
33
Aaron 🌪️ retweeted

Kerala is crowdfunding that much of an amount for an HSR because we can’t get it funded like bullet trains from Gujarat from the centre. Maybe Twitter desis should consider crowdfunding for a sovereign model.

Jun 13

To train a GPT class 1T model from scratch - including failed runs, data acq clean rlhf, post-training, team/people will likely req $250M of compute on an aggressive 3-4mo schedule (i.e. more reserved GPUs), $500-600M all-in IF you do a dense one. MoE fp8 will cut costs by 1/10th depending on how many active params you have. If you want SOTA however, the budgets go significantly higher on test-time compute, post-training RL, and data/synthetic generations..and v. high on talent. Maybe $2-4B all-in. After that comes serving the model. The talent is key to get to SOTA/beat it - and then you have to ensure this is useful enough to have inference vol over time - for which the capital will come if there is usage / TAM. So this is not as much about raising $50-60B, or raising it all at once as the OP says - we are investors in mistral, sarvam, reflection and anthropic - and they all scaled capital over time as models got adoption, but the early bottleneck is more on talent GPUs at that scale where you can do interesting things.
3
1
5
518