
A distributed compute framework for scaling AI workloads. Created and developed by @anyscalecompute.
Joined August 2019
- Tweets 1,933
- Following 2
- Followers 11,354
- Likes 1,871
523 Photos and videos









ray retweeted
Our Anyscale on Azure webinar is now available on demand.
Daniel Arrizza (Anyscale) and Paul Yu (@Microsoft) on running production AI inside your own Azure tenant, plus a live build-train-serve demo.
Watch now 👉 na2.hubs.ly/H0699F80

1
3
217
ray retweeted

Jun 17
Some intuition about PD disaggregation from the blog
- PD doesn't speed up prefill and can actually hurt TTFT
- PD's real benefit is flat, stable TPOT under load
- TPOT savings compound over output sequence length
The optimal P:D ratio is dependent in particular on input lengths, output lengths, and cache hits. Meaningful optimizations are possible, but tuning can be sensitive.
Benchmarks performed with @raydistributed @vllm_project on AMD MI325X.
anyscale.com/blog/ray-vllm-p…
2
7
94
5,653
ray retweeted
Jun 16
We usually divide AI workloads into two buckets: "training" and "inference". However, data processing is quickly emerging as a third major AI workload. It was previously confined to CPUs, but going forward, most data processing will happen on GPUs.
Jun 16

Data processing has become a GPU workload and is dominated by inference. A new architecture is required, and it is not Spark on GPUs. anyscale.com/blog/data-proce…
1
6
32
5,956
ray retweeted

Jun 16
Data processing has become a GPU workload and is dominated by inference. A new architecture is required, and it is not Spark on GPUs. anyscale.com/blog/data-proce…
5
12
6,456

ray retweeted
Jun 15
Save 67% with prefill-decode disaggregation using Ray vLLM on AMD GPUs.
anyscale.com/blog/ray-vllm-p…
Jun 15

One pattern we keep seeing with customers serving LLMs at scale:
Prefill-decode disaggregation is often treated like a magic wand. But the reality is more nuanced.
So we wrote down the core insights for when PD helps, when it does not, and validated them on AMD vLLM — where the PD path has been much less paved. 🧵

5
12
5,619
ray retweeted

Jun 15
One pattern we keep seeing with customers serving LLMs at scale:
Prefill-decode disaggregation is often treated like a magic wand. But the reality is more nuanced.
So we wrote down the core insights for when PD helps, when it does not, and validated them on AMD vLLM — where the PD path has been much less paved. 🧵
2
13
36
15,323
ray retweeted
Jun 15
Last chance to sign up for tomorrow's webinar!
Don't miss the opportunity to learn:
- Where Anyscale on Azure fits in your AI stack
- How it integrates with the Azure services you already use: Microsoft Entra ID, Azure RBAC, Azure Policy, Azure Monitor, and Microsoft Cost Management
- What you need to get started, from your Azure tenant to your first Ray cluster
- Plus a live demo: building, training, and serving a real AI workload on Anyscale in an Azure environment
na2.hubs.ly/H061tcr0
1
3
437
ray retweeted
Jun 12
Thanks to our Ray Day: London speakers: Marcell Ferencz (@Xoople), Martin Iglesias & Maxime Battello (@Adyen), Paul Coursaux (@Criteo), and Thomas Riedl (@BMWGroup), plus a keynote from @pcmoritz.
Recap 👉 na2.hubs.ly/H065bcv0
The road leads to Ray Summit SF, Aug 24–26 → na2.hubs.ly/H0659wN0




1
3
476
ray retweeted
Jun 11
Thank you to our Ray Day: NYC speakers 🔆
Serrana Aguirregaray (@discord), Neil Wadhvana (@torc_robotics ), Todd Gaugler (Cubist), and Aman Choudhary (@coinbase) brought four different takes on Ray in production, from ML platforms to quant finance.
Highlights from all 4 talks 👉 na2.hubs.ly/H064bc-0




2
8
545
ray retweeted
Jun 11
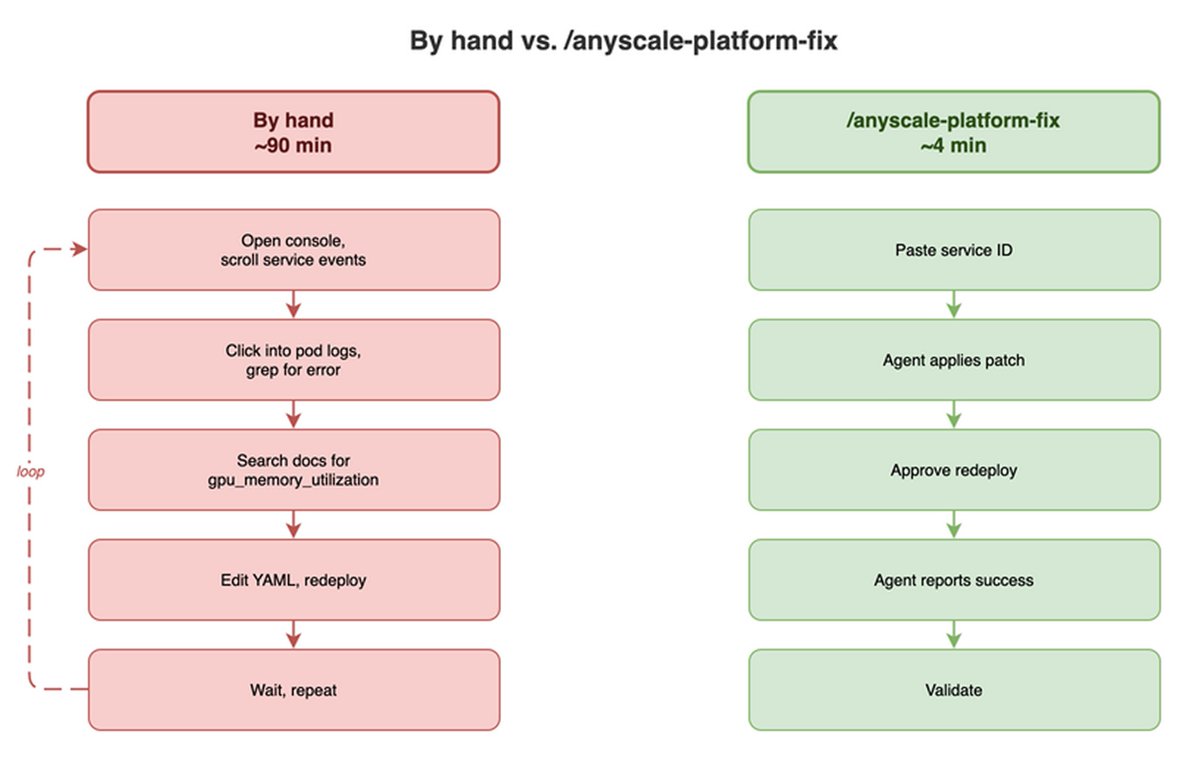
My vLLM pipeline wouldn't start. KV cache came out negative on the L4.
One prompt to /anyscale-platform-fix and the agent takes it from there.
Four minutes to debug instead of a full afternoon.
Full walkthrough: na2.hubs.ly/H062c-V0
1
7
541
ray retweeted
Jun 11
Ray Summit 2026 keynote lineup is coming together.
@LiamFedus (@periodiclabs, prev. co-creator of ChatGPT), @_FelixHeide_ (@torc_robotics), @real_ioannis (@reflection_ai), @kevinmpeterson1 (@BedrockRobotics), @robertnishihara & @istoica05 (Anyscale).
⏰ CFP closes June 20: na2.hubs.ly/H062cPc0

4
14
1,219
ray retweeted
Jun 10
Thanks for joining Ray Day: NYC! Two tracks — distributed training with Ray PyTorch and VLA fine-tuning — plus talks from @discord, @torc_robotics, @coinbase & Cubist.
Recap → na2.hubs.ly/H062d0F0
Next: Ray Summit SF, Aug 24–26 →na2.hubs.ly/H062gYk0
2
8
655
ray retweeted
Jun 9
Last chance to sign up for tomorrow's webinar!
Neil Wadhvana, Staff ML Engineer at @torc_robotics, will walk through how Torc consolidated its autonomy data processing stack to support multimodal AI at scale with Ray on Anyscale.
Don't miss the opportunity to learn:
- The trends driving growth in autonomous driving developments,
- An overview of Torc’s data loop from production to consumption,
- The internal trends in multimodal AI that drove need for consolidation,
- The before and after Ray was adopted as common compute framework.
na2.hubs.ly/H05Dgrf0
2
5
378
ray retweeted
Jun 9
Anyscale on Azure is now in public preview, and we're going deep on how it works. Join Daniel Arrizza (Field Engineer, Anyscale) and Paul Yu (Senior Cloud Advocate, Microsoft) for a working session on running production AI inside your own Azure tenant – where your data stays within your existing governance.
You will learn:
- Where Anyscale on Azure fits in your AI stack
- How it integrates with the Azure services you already use: Microsoft Entra ID, Azure RBAC, Azure Policy, Azure Monitor, and Microsoft Cost Management
- What you need to get started, from your Azure tenant to your first Ray cluster
- Plus a live demo: building, training, and serving a real AI workload on Anyscale in an Azure environment
na2.hubs.ly/H061t3b0
1
6
441

Jun 8
Impressive work from the Cosmos team. Check out the Cosmos 3 technical report: arxiv.org/pdf/2606.02800

Introducing Cosmos 3: Our latest frontier model for Physical AI
Cosmos 3 is the world’s first fully open omnimodel with native vision reasoning, world and action generation.
Today we’re releasing Super (32B) and Nano (8B) variants.
1
7
13
3,041
ray retweeted
Congratulations to @nvidia on the release! Super exciting to see two models trained with Ray back to back (MAI-Thinking-1 and Nemotron 3 Ultra).
Jun 5

Nemotron 3 Ultra is an impressive 550B parameter (55B active) MoE model. It was trained with Ray / Megatron / vLLM (via NeMo RL).
1
8
51
6,445
Jun 5
Nemotron 3 Ultra is an impressive 550B parameter (55B active) MoE model. It was trained with Ray / Megatron / vLLM (via NeMo RL).
Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
6
14
7,619
ray retweeted
Jun 4
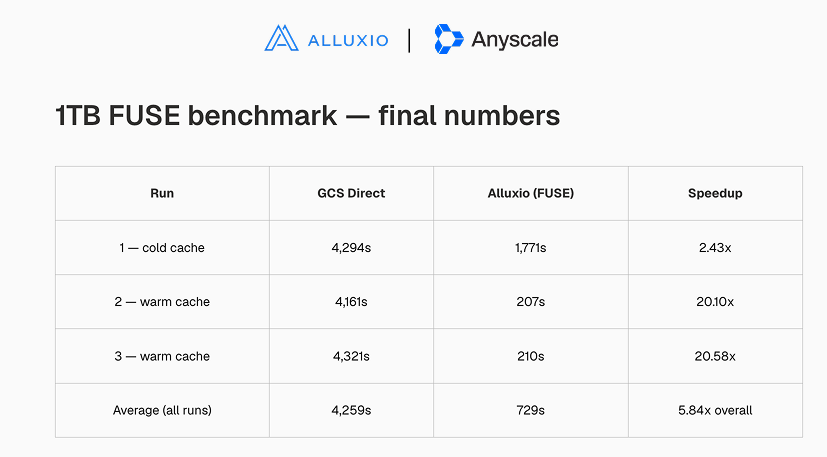
GPUs in Mumbai, training data in Iowa? Cross-region reads tax every epoch.
We put @Alluxio NVMe caching in front of the bucket with Ray Data on Anyscale: 1TB warm reads went 20x faster.
na2.hubs.ly/H05YMGW0
1
6
788
ray retweeted
Jun 4
The bottleneck in drug discovery isn't designing molecules, it's making them. onepot combines robotic synthesis with large-scale ML inference on Anyscale to predict which reactions will work before they run, achieving 3B compounds and 10B reactions scored.
Case study: na2.hubs.ly/H05PcCG0"
2
3
372