
12 Photos and videos










ReadyAI Revenue Dashboard is Live 🚀
Real-time demand for SN33's structured data pipeline
Starting today, anyone can watch demand for ReadyAI's structured data pipeline as it happens. Revenue, jobs, quotes, and tags produced. Data straight from the Subnet 33 Jobs API is refreshed every 8 hours,
The Early Signal
Exactly what we hoped for. Direct ReadyAI revenue is on a five-figure ARR pace and the curve is steepening week over week.
The Jobs API is open. Beyond our existing enterprise feeds, we're starting to see organic customers find it and plug in on their own. Submit data, pay in USDC over a single HTTP call, get structured output back.
What This Means for Alpha Holders
75% of this revenue goes directly to buying back SN33 alpha from the open market. Every job that flows through the pipeline, enterprise feed or organic API user, funds a buyback for the foreseeable future. All on-chain, all verifiable.
The dashboard you're looking at is the same demand that drives the buyback.
Dashboard: readyai.ai/dashboard
Back to building. Got some exciting news coming on our coding data pipeline and benchmarks to share shortly.
Docs and endpoint details for the API is available here: api.readyai.ai/jobs-api/docs
1
4
17
858
AI's impact on jobs is something we thing a lot about @ReadyAI_
Some perspetive from our founder @DavFields

10
374
ReadyAI retweeted

May 21
When we started @ReadyAI_ the thesis was simple: structured data is the bottleneck for AI, and Bittensor is the best way to produce it at scale. Today we can prove it. NYSE-listed customers paying for our data, those payments moving on-chain through x402, and 75% flowing into alpha buybacks. Dashboard goes live next week.

5
5
34
1,465
ReadyAI retweeted
May 8
Real customers. Real revenue. Coming fully on-chain this month.
ReadyAI Update and Roadmap:
→ 5 paying customers including a NYSE-listed REIT (SmartStop, $1.8B)
→ x402 payment rails going live May 18th with every API call settable and verifiable on-chain
→ 75% of enrichment revenue committed to SN33 alpha buybacks
→ Public dashboard shipping this month so anyone can audit demand
Full breakdown ↓
6
7
40
2,155
ReadyAI retweeted
May 4
We've been heads down on something. Coding agents are the trillion-dollar race for every major lab, and the high-quality structured data to make them work is the bottleneck. Context7 became the #1 MCP server (53K stars) solving current docs. But the hard problems live deeper from version-pinned breaking changes to expert reasoning mined from thousands of technical podcasts, coding intelligence that doesn't exist in any documentation. We're building that dataset. More this week.
3
3
30
1,067
ReadyAI retweeted
Apr 10
Getting my Claw into music this weekend...thanks @ReadyAI_
Grab any files you'd like here:
readyai.ai/

4
2
28
1,067
ReadyAI retweeted
Apr 10
Bittensor and decentralized AI is as important as ever.
This bump in the road will lead to improving the protocol and further resilience
Zoom out $TAO
Apr 10

If Martin is right, he also just wrote the product spec for open source distributed compute where broad swaths of groups, individuals and organizations contribute their compute resources to training runs for large param open source models.
There are lots of issues in figuring this out: homogeneity vs heterogeneity of the training clusters, orchestration, financial incentives etc etc etc but some early projects are good signal as to where this can go and that these limitations can be overcome (folding@home, Venice, Tao).
An attempted oligopoly on intelligence is the perfect boundary condition for a bottoms up uprising of fully open, fully distributed AI.
4
16
150
8,517

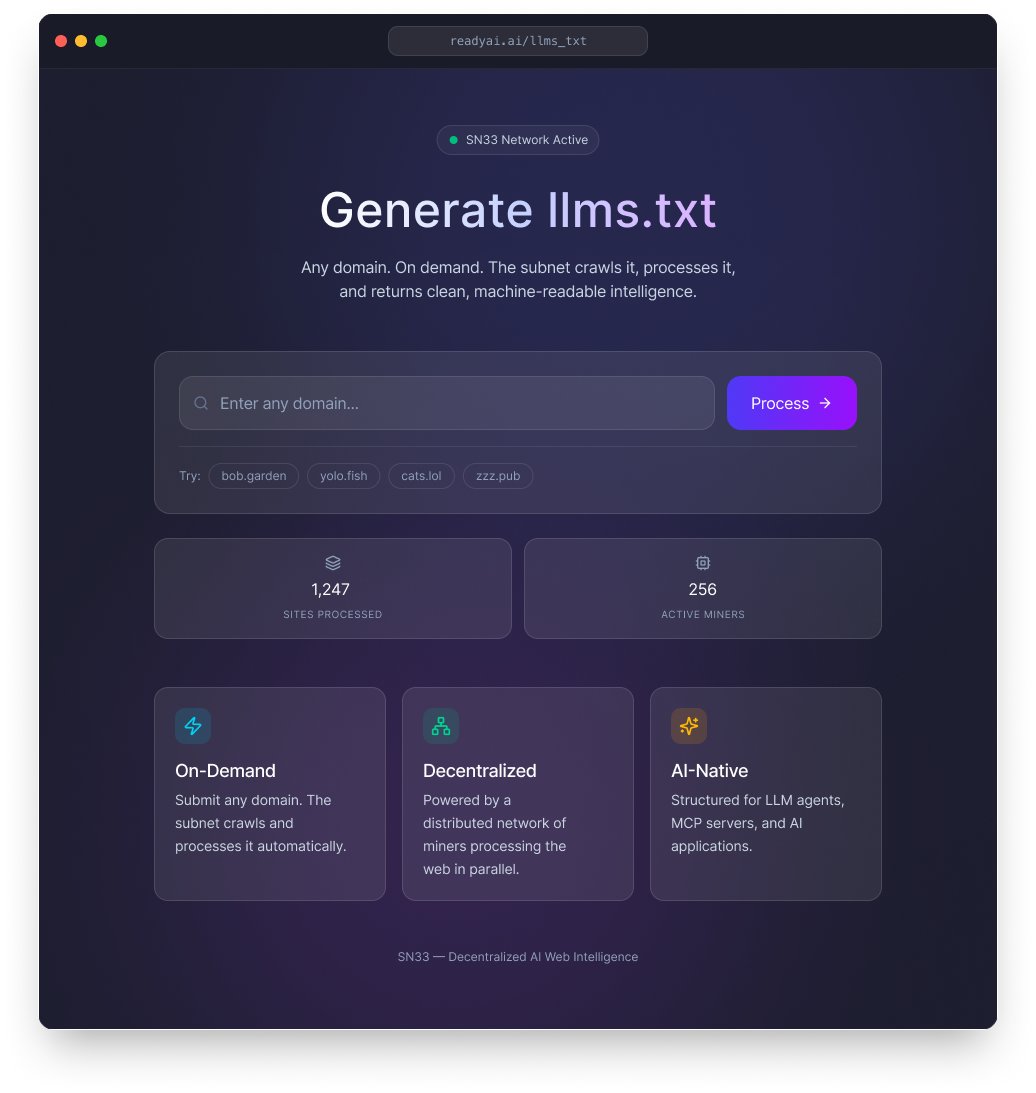
New on @ReadyAI_
Request an llms.txt file for any domain, free
Search a site → not in our 10K database? Hit "Request This Domain Now" → get your file queued on subnet
5 free requests per user. Every file is open-sourced on GitHub
Structured data for agents shouldn't be gated
2
5
24
1,171
ReadyAI retweeted
Apr 5
This is the best explanation for why
(1) Bittensor is unique amongst crypto projects and
(2) you often see crypto VCs hating on it
Bittensor provides the incentives for bootstrapping innovation across numerous experiments all at once without the need for VCs
$TAO
Apr 4

Yes emissions are used to bootstrap innovation, same as Uber, Amazon and countless of other big companies
You can chose between these 2:
-give those emissions to VC’s
-give those emissions to builders who devote their whole time to build out the network
Vc’s hate it because they can’t apply the VC playbook/had discounted access compared to the masses
6
15
80
5,032

SEO was built for humans browsing the web
The next version of search optimization is built for agents reading it
AEO/GEO ("agent engine optimization" or "generative engine optimization") is becoming a real category
An entire industry is forming around making your website legible to LLMs and autonomous agents instead of just Google crawlers
Right now every AI agent that needs info about a company or domain does the same thing; scrapes, parses HTML, and hopes for the best
Billions of redundant crawls; trillions of wasted tokens
llms.txt emerged as a proposed standard for this; a markdown file in a website's root directory that gives LLMs a clean structured summary of the site's content instead of forcing them to parse navigation menus, cookie banners, and JavaScript
Over 844k websites have already adopted it; Anthropic, Cloudflare, and Stripe among them
The problem is that no one has built the infrastructure to do this at scale across the entire web
The beauty of this is that the infrastructure powering it can be decentralized from day one; there's no reason for one company to own the machine-readable index of the entire web
So when you read the below announcement from subnet 33 you should look at it in the context of this broader agentic engine optimization (AEO)
How many "AEO experts" do you think currently exist?
Zero.
There's a huge opportunity for you to pick a niche and dominate
Once again, another Bittensor subnet tackling a forward thinking problem
Mar 30
We just launched a new readyai.ai
Type any domain into the search. If it's in our dataset, you get clean, structured intelligence instantly. No scraping. No parsing HTML. Just machine-readable data, ready for any AI agent.
10,000 websites crawled, cleaned, and structured by Subnet 33 so far. Growing to 100K by Q2, 1M by year end.
This is the beginning of something bigger: a marketplace for agentic data.
Right now, every AI agent that needs info about a company or domain scrapes, parses, and hopes. Billions of redundant crawls. Trillions of wasted tokens.
We're building the infrastructure layer that fixes this — an indexed, machine-readable web powered by decentralized compute.
14
5
82
9,692
ReadyAI retweeted
Mar 30
We just launched a new readyai.ai
Type any domain into the search. If it's in our dataset, you get clean, structured intelligence instantly. No scraping. No parsing HTML. Just machine-readable data, ready for any AI agent.
10,000 websites crawled, cleaned, and structured by Subnet 33 so far. Growing to 100K by Q2, 1M by year end.
This is the beginning of something bigger: a marketplace for agentic data.
Right now, every AI agent that needs info about a company or domain scrapes, parses, and hopes. Billions of redundant crawls. Trillions of wasted tokens.
We're building the infrastructure layer that fixes this — an indexed, machine-readable web powered by decentralized compute.
4
16
103
20,641

ReadyAI retweeted
Mar 18
Our recent breakthrough with enrichment tasks on the subnet has completely opened the floodgates. We can now create structured datasets from nearly any source, from llms.txt to deep coding data.
Will be sharing benchmark improvements with this coding data shortly
4
3
27
2,062
ReadyAI retweeted
Mar 12
The web wasn't built for AI agents. We're fixing that. First 1,000 domains live now, millions coming. Open source, decentralized, and free.
Frontend coming shortly to request llms.txt for any site
🚀 llms.txt are live on SN33
The llms.txt repository is now live. 🔗 github.com/afterpartyai/llms…
SN33 has processed the first batch with over 1,000 websites crawled, cleaned, and converted into structured llms.txt files by the subnet.
Semantic summaries ready for any LLM agent, MCP server, or AI app to consume instantly. No scraping. No parsing raw HTML. Just clean, machine-readable intelligence.
New batches will be pushed as the subnet keeps processing. The repo grows every week.
What's in the dataset:
→ Structured semantic summaries per domain
→ Named entities: people, orgs, products, technologies, concepts
→ Topic classification and key themes
→ Deterministic O(1) lookup by domain with no index file needed
→ Git-friendly structure that scales to millions of domains
This initial release covers ~1,000 domains as a pilot, but the pipeline scales to millions.
📍 Roadmap: 10K → 100K → 1M domains → continuous updates from new Common Crawl releases and soon from requests.
🌍 And the frontend is coming.
Any domain. You request it, the subnet processes it, you get an llms.txt back. We're putting the finishing touches on the public UI and it drops soon.
SN33 is becoming infrastructure. The web, made readable for machines and open to anyone, powered by decentralized infra.
Star the repo. Share it. And stay close. The next drop is right around the corner.
5
8
40
3,261