
14 Photos and videos

Pinned Tweet

3 Oct 2025
1/🧵
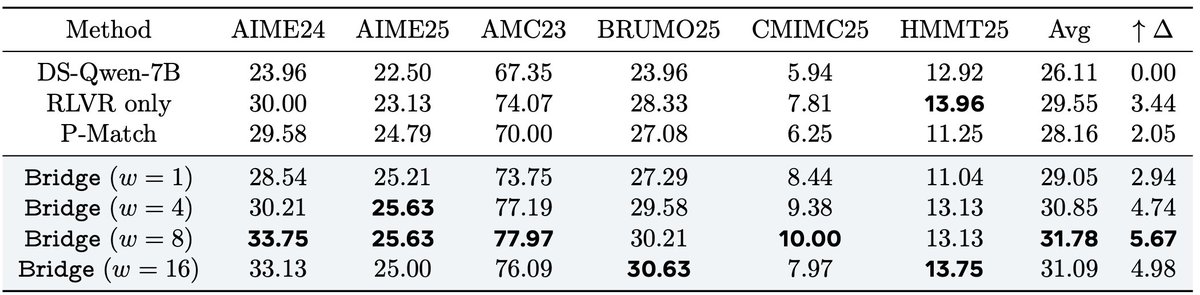
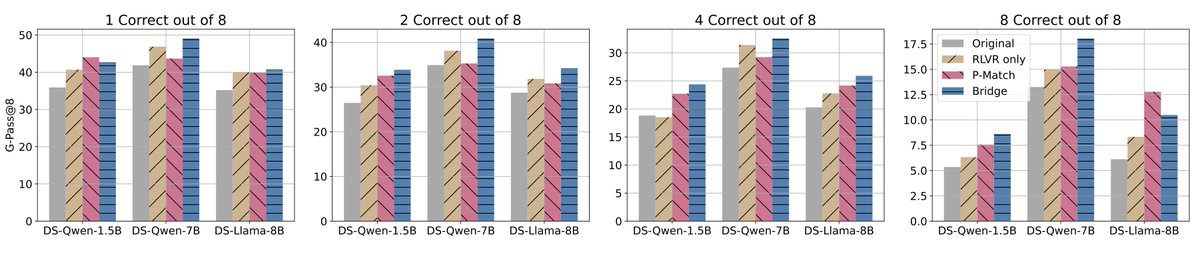
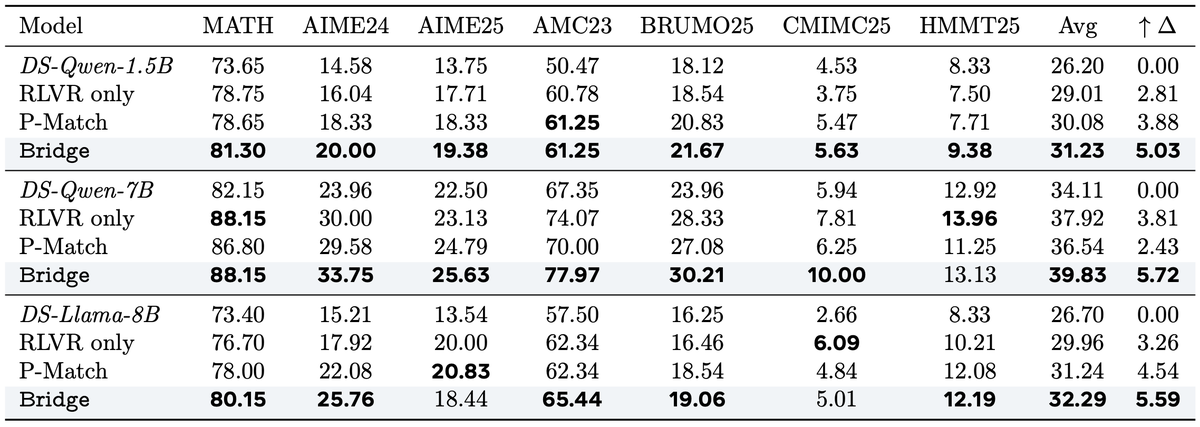
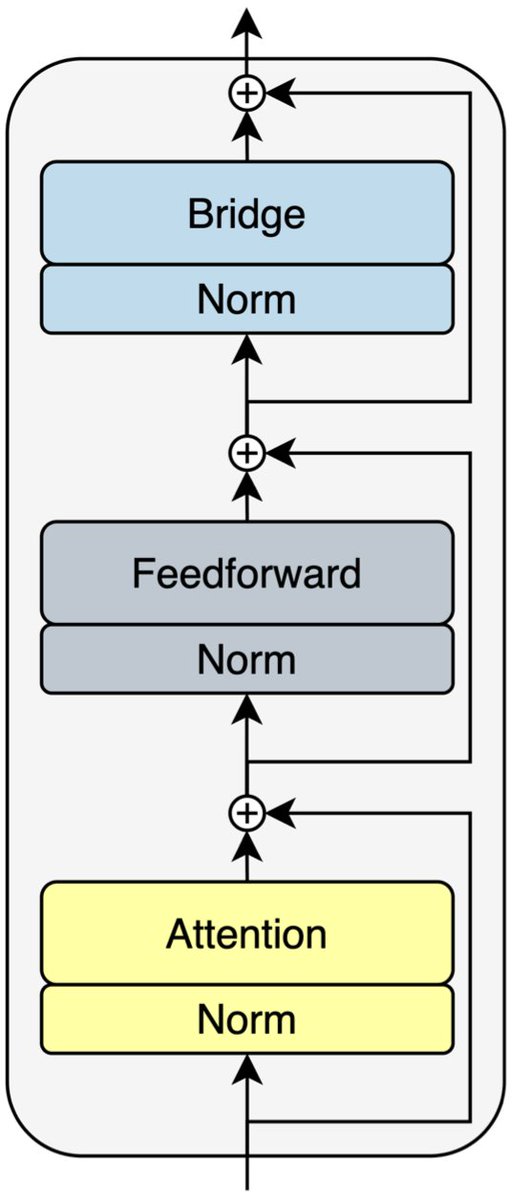
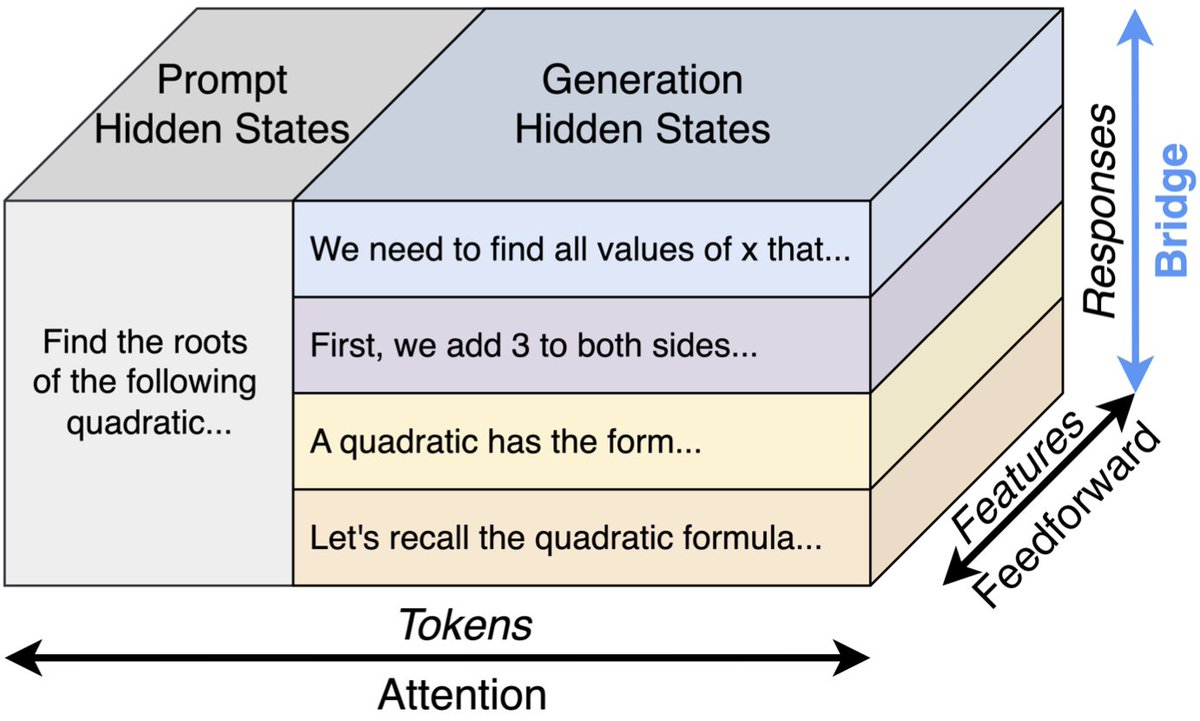
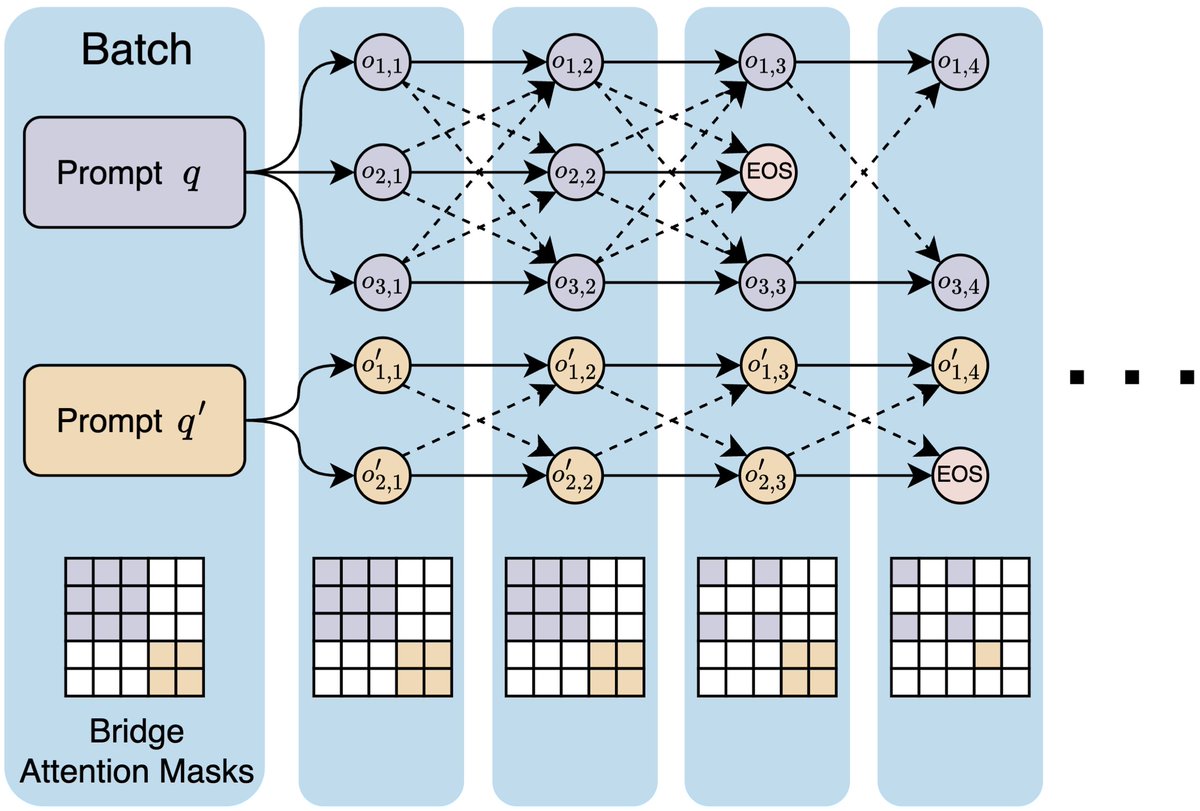
🎉Introducing Bridge🌉, our parallel LLM inference scaling method that shares info between all responses to an input prompt throughout the generation process! Bridge greatly improves the quality of individual responses and the entire response set!
📜arxiv.org/pdf/2510.01143
1
4
22
4,835
Harry Dong retweeted

Feb 18
Video generation models are improving fast—real-time autoregressive models now deliver high quality at low latency, and they’re quickly being adopted for world models and robotics applications. So what’s the problem? They’re still too slow on consumer hardware.
🚀 What if we told you that we can get true real-time 16 FPS video generation on a single RTX 5090? (1.5-12x over FA 2/3/4 on 5090, H100, B200)
Today we release MonarchRT 🦋, an efficient video attention that parameterizes attention maps as (tiled) Monarch matrices and delivers real E2E gains.
📄 Paper: arxiv.org/abs/2602.12271
🌐 Website: infini-ai-lab.github.io/Mona…
🔗 GitHub: github.com/Infini-AI-Lab/Mon…
🧵1/n
4
26
134
34,193
Harry Dong retweeted
Feb 10
RL is notoriously unstable under actor–policy mismatch 😥 — a common reality caused by kernel differences, MoE randomness, FP8 rollouts, or asynchronous pipelines.
But here’s a crazy thought 🤔
👉 What if you could RL-train a large model using rollouts generated only by a weaker, faster, and completely different model?
Sounds doomed from the start? 💩
We are releasing Jackpot 🎰.💡 enabling training Qwen3-8B-Base using only Qwen3-1.7B-Base generated rollouts
✨ Jackpot is surprisingly powerful:
• Enables cheap, fast rollouts to train stronger models
• Dramatically changes the cost–performance tradeoff of RL training
We release Jackpot 🎰 in the following format:
🌔Paper: arxiv.org/abs/2602.06107
🌕Code: github.com/Infini-AI-Lab/jac…
🌖Blog: infini-ai-lab.github.io/jpt_…
[1/n]

6
23
127
26,793
Jan 22
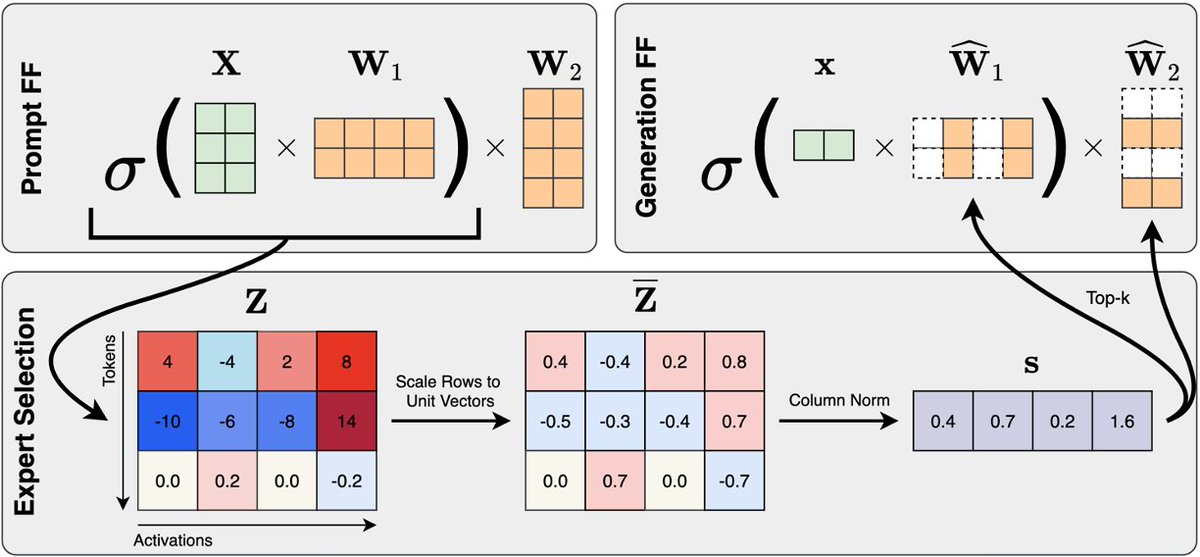
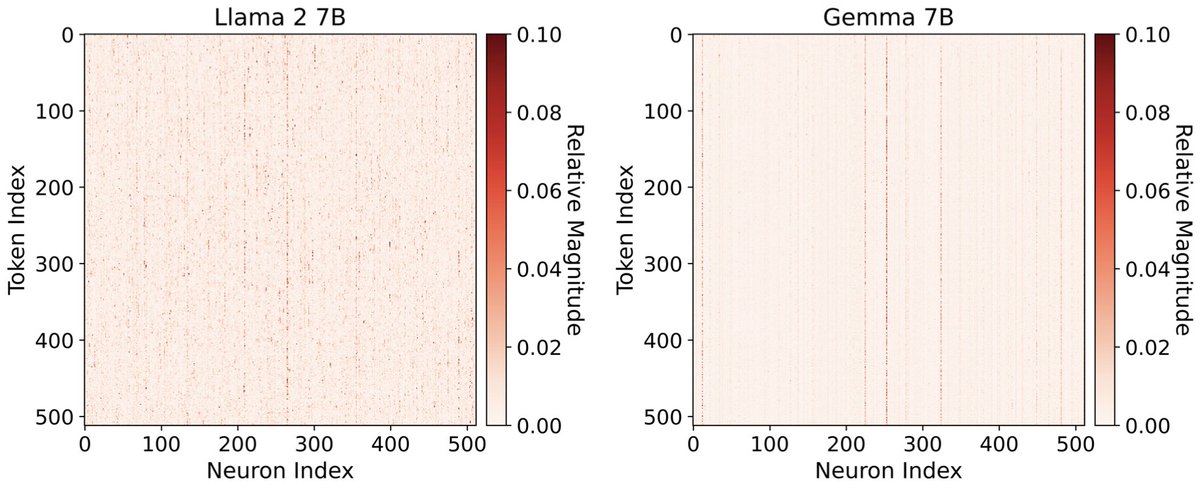
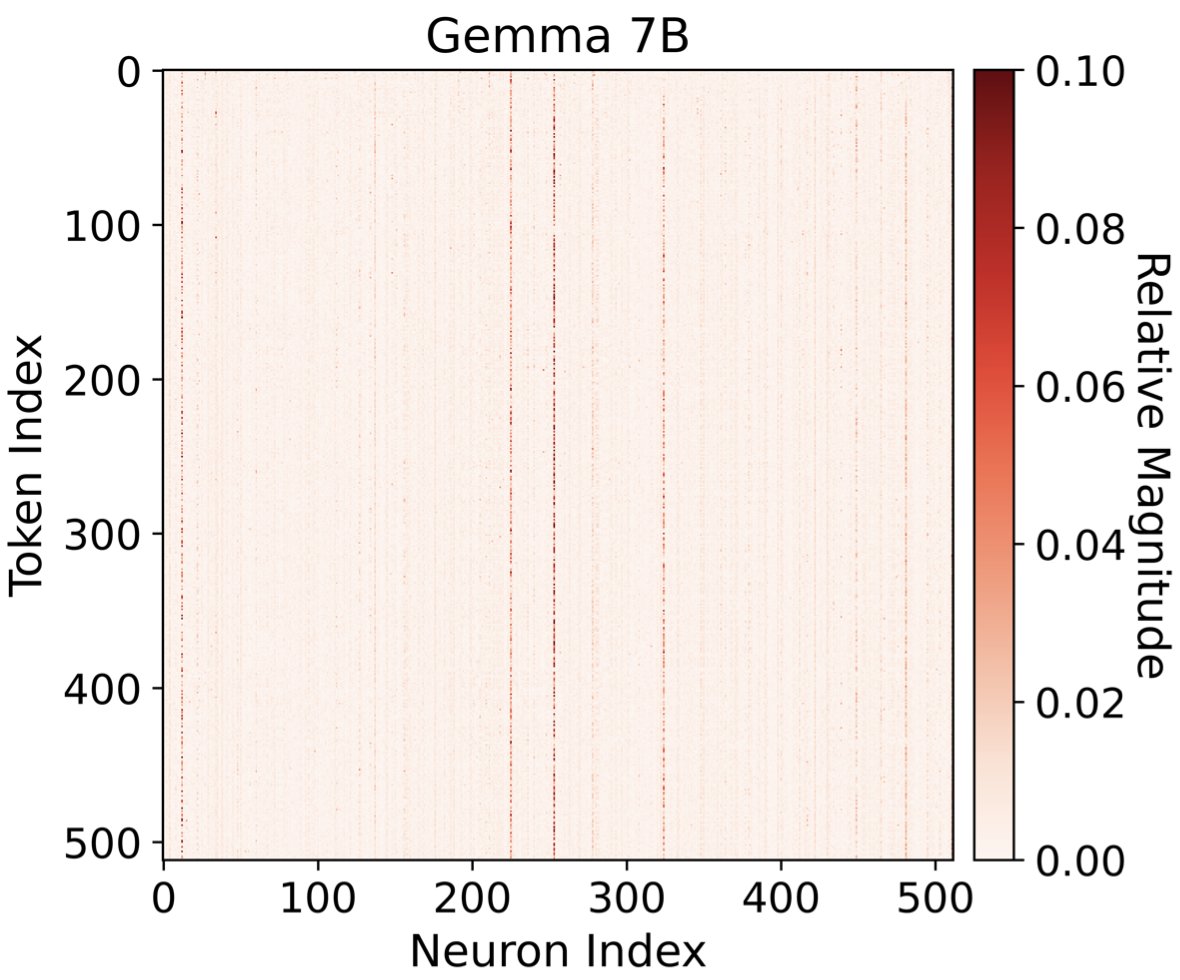
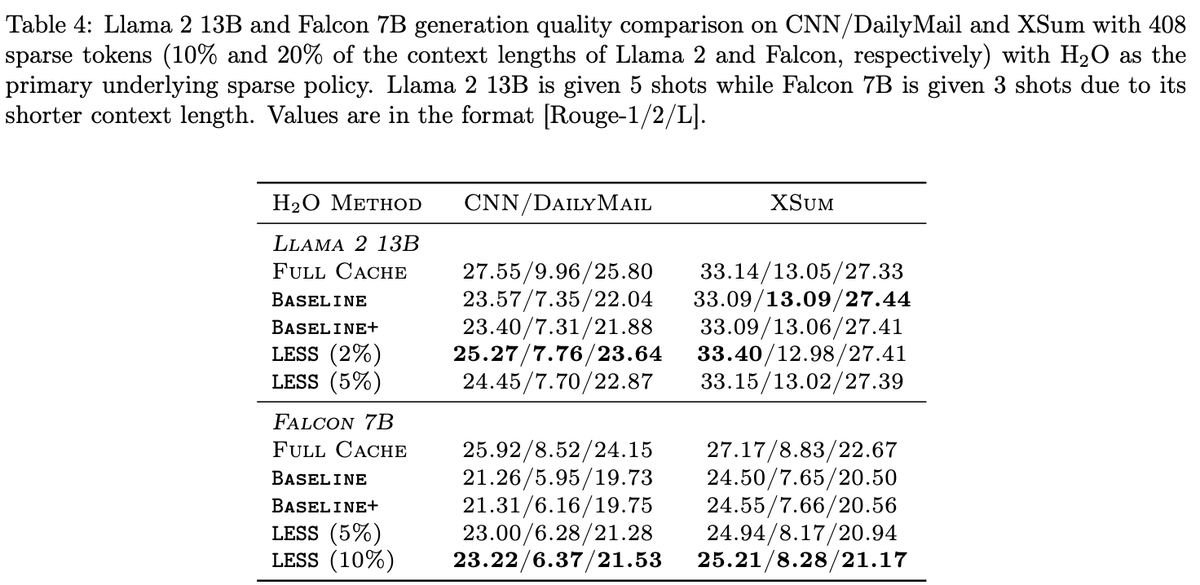
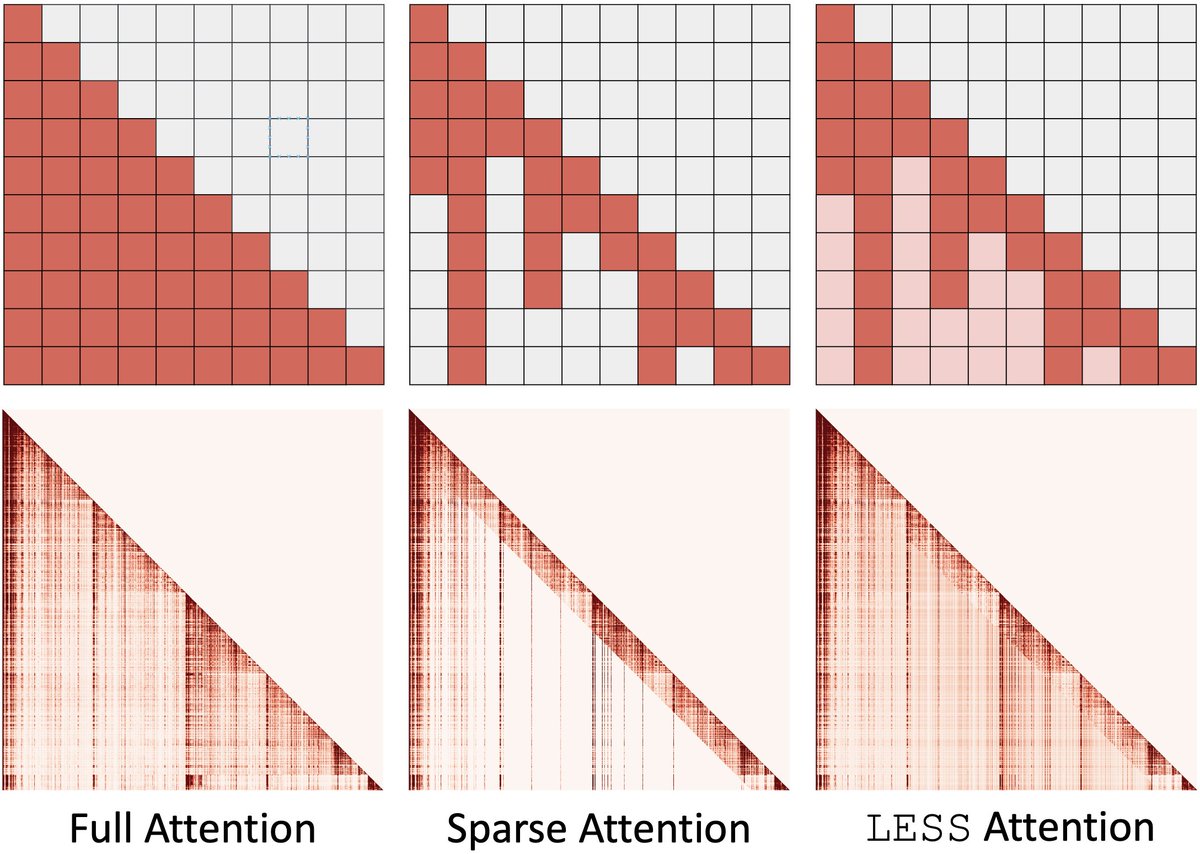
Very neat work led by @RJ_Sadhukhan to make LLMs more efficient, sparse, and interpretable!
Jan 22

Lookup memories are having a moment 😄
The whale 🐋 #deepseek dropped engram… and we dropped up-projections from our FFNs…perfect timing 😅
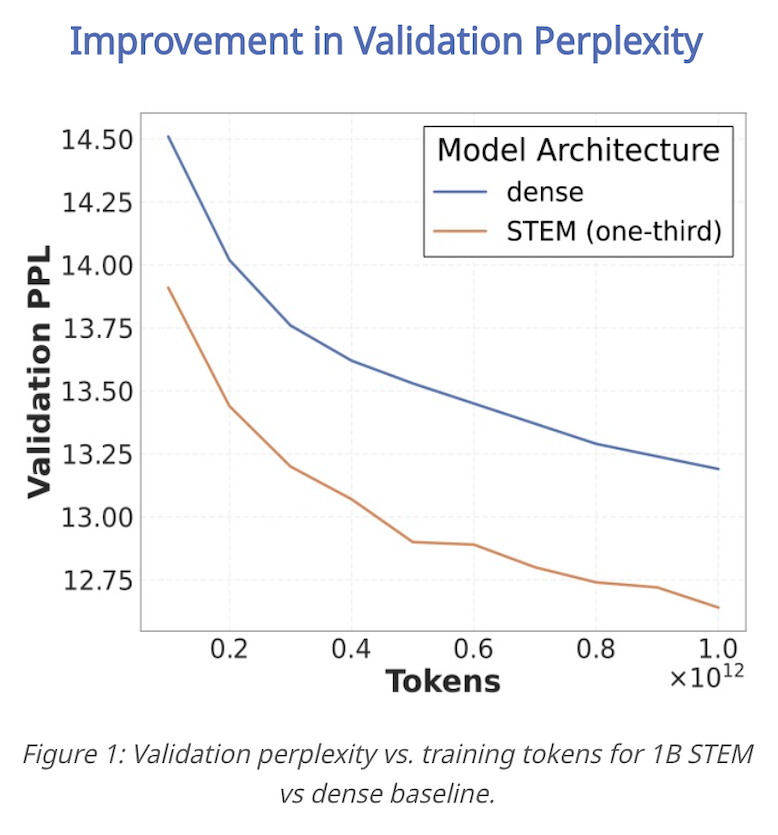
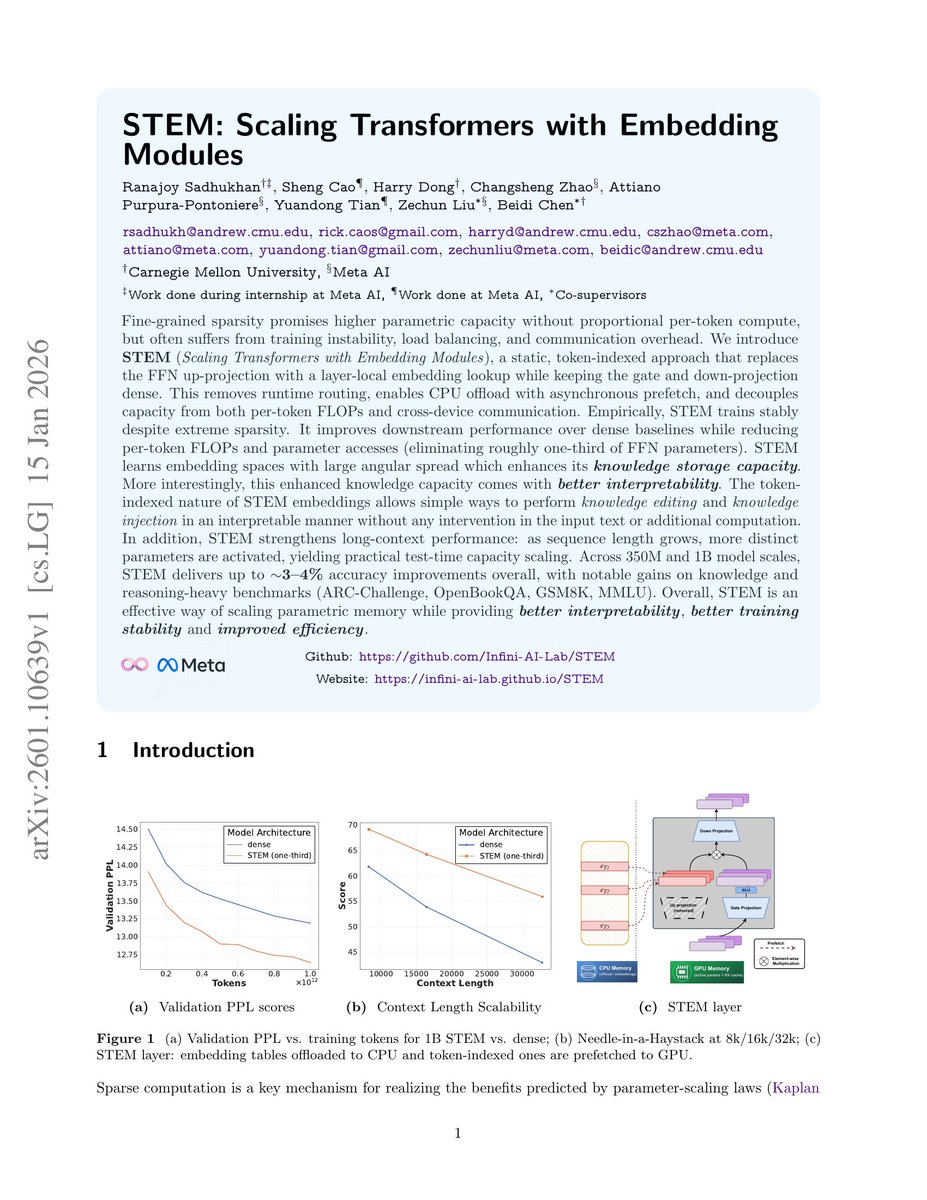
🥳 Introducing STEM: Scaling Transformers with Embedding Modules 🌱
A scalable way to boost parametric memory with extra perks:
✅ Stable training even at extreme sparsity
✅ Better quality for fewer training FLOPs (knowledge reasoning long-context gains)
✅ Efficient inference: ~33% FFN params removed CPU offload & async prefetch
✅ More interpretable → seamless knowledge editing 🔧🧠
Looking forward to DeepSeek v4… feels like we’ve only scratched the surface of embedding-lookup scaling 👀
📄Paper: arxiv.org/abs/2601.10639
🌐 Website: infini-ai-lab.github.io/STEM
🔗 GitHub: github.com/Infini-AI-Lab/STE…
5
183
Harry Dong retweeted

Jan 17
How timely!
Jan 16

Replacing the up projection in FFNs with token embeddings. As cited in the paper it feels similar to a hash based router for MoEs. Again Engram could be the beginning of studies around embeddings.
4
21
272
35,762
2 Dec 2025
At NeurIPS all week! Swing by the Efficient Reasoning workshop at 10:45-11:00 on Saturday to hear my oral presentation about our work on interdependent sampling for parallel generation!
3 Oct 2025

1/🧵
🎉Introducing Bridge🌉, our parallel LLM inference scaling method that shares info between all responses to an input prompt throughout the generation process! Bridge greatly improves the quality of individual responses and the entire response set!
📜arxiv.org/pdf/2510.01143
1
3
315
Harry Dong retweeted

8 Nov 2025
This will be presented as an oral talk at NeurIPS Workshop Efficient Reasoning! Stop by to listen to Harry if you plan to attend NeurIPS. Harry is also on the job market this year! @Real_HDong
3 Oct 2025
1/🧵
🎉Introducing Bridge🌉, our parallel LLM inference scaling method that shares info between all responses to an input prompt throughout the generation process! Bridge greatly improves the quality of individual responses and the entire response set!
📜arxiv.org/pdf/2510.01143
3
4
1,046
Harry Dong retweeted

23 Oct 2025
Excited to release our new preprint - we introduce Adaptive Patch Transformers (APT), a method to speed up vision transformers by using multiple different patch sizes within the same image!
10
29
229
29,987
Harry Dong retweeted

16 Oct 2025
New paper! I had a lot of fun working on scaling up RL with @agarwl_ @Devvrit_Khatri @louvishh and others. Check it out!
16 Oct 2025

Wish to build scaling laws for RL but not sure how to scale? Or what scales? Or would RL even scale predictably?
We introduce: The Art of Scaling Reinforcement Learning Compute for LLMs

3
7
69
12,082
Harry Dong retweeted
7 Oct 2025
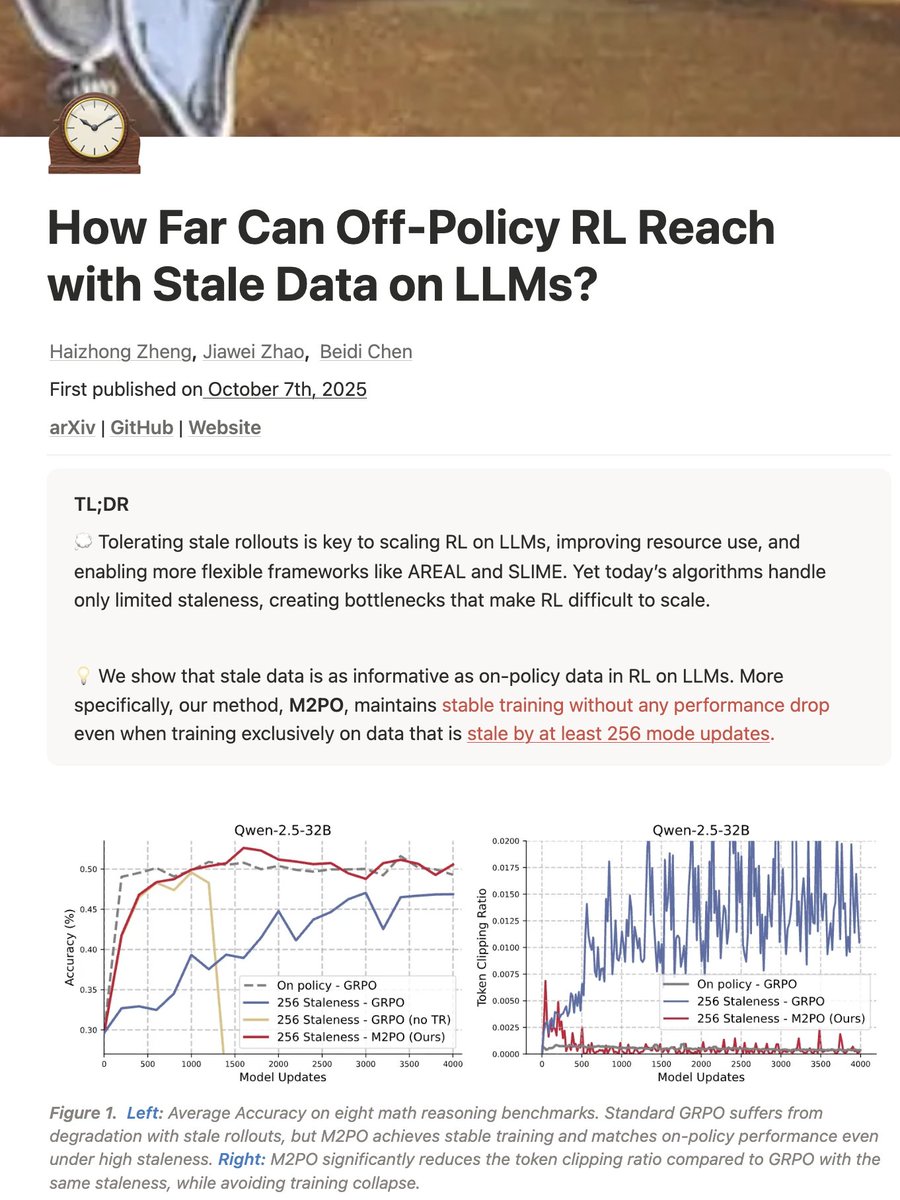
🤔Can we train RL on LLMs with extremely stale data?
🚀Our latest study says YES!
Stale data can be as informative as on-policy data, unlocking more scalable, efficient asynchronous RL for LLMs.
We introduce M2PO, an off-policy RL algorithm that keeps training stable and performant even when using data stale by 256 model updates.
🔗 Notion Blog: m2po.notion.site/rl-stale-m2…
📄 Paper: arxiv.org/abs/2510.01161
💻 GitHub: github.com/Infini-AI-Lab/M2P…
🧵 1/4
3
39
234
63,791
3 Oct 2025
1/🧵
🎉Introducing Bridge🌉, our parallel LLM inference scaling method that shares info between all responses to an input prompt throughout the generation process! Bridge greatly improves the quality of individual responses and the entire response set!
📜arxiv.org/pdf/2510.01143
1
4
22
4,835
3 Oct 2025
8/🧵
✨Key takeaway: By treating LLM features for parallel scaling as a single tensor unit instead of independent slices, each response can give/take info to/from other responses to improve individual response AND response set quality while maintaining total parallelism.
1
141
3 Oct 2025
9/🧵
More details in the full paper (Generalized Parallel Scaling with Interdependent Generations): arxiv.org/pdf/2510.01143
Big thank you to all my collaborators @brandfonbrener, @ErykHelenowski, Yun He, Mrinal Kumar, @Han_Fang_, @yuejiec, @karthikabinav
4
186
Harry Dong retweeted
16 Jun 2025
🔥 We introduce Multiverse, a new generative modeling framework for adaptive and lossless parallel generation.
🚀 Multiverse is the first open-source non-AR model to achieve AIME24 and AIME25 scores of 54% and 46%
🌐 Website: multiverse4fm.github.io/
🧵 1/n
6
78
222
121,041
Harry Dong retweeted
14 Feb 2025
🚀 RAG vs. Long-Context LLMs: The Real Battle ⚔️
🤯Turns out, simple-to-build RAG can match million-dollar long-context LLMs (LC LLMs) on most existing benchmarks.
🤡So, do we even need long-context models?
YES. Because today’s benchmarks are flawed:
⛳ Too Simple – Over-reliant on retrieval & QA.
⛳ Detectable Noise – RAG can filter out filler text easily.
⛳ Too Few – High-quality data requires huge human effort.
🔭 With LC LLMs hitting the ceiling, we need a benchmark that justifies their insane training costs.
🔥 Introducing 🐭🐷 GSM-Infinite – our synthetic long-context reasoning benchmark built to push LLMs to their real limits.
💎 Infinitely scalable in reasoning complexity & quantity
💎 Precision control over reasoning complexity
💎 Fully customizable RAG-proof context lengths 🚀
[1/n]
📄Paper: arxiv.org/abs/2502.05252
🖥️Code: github.com/Infini-AI-Lab/gsm…
🤗Huggingface datasets: huggingface.co/collections/I…
🏃Leaderboard: huggingface.co/spaces/Infini…

6
37
187
98,621