
Building Red: Multi-Billion Parameter LLM from Scratch. Documenting architecture, scaling, and NumPy to PyTorch failures. Cybersec student, India.
Joined June 2025
- Tweets 49
- Following 20
- Followers 8
- Likes 120
11 Photos and videos







Pinned Tweet

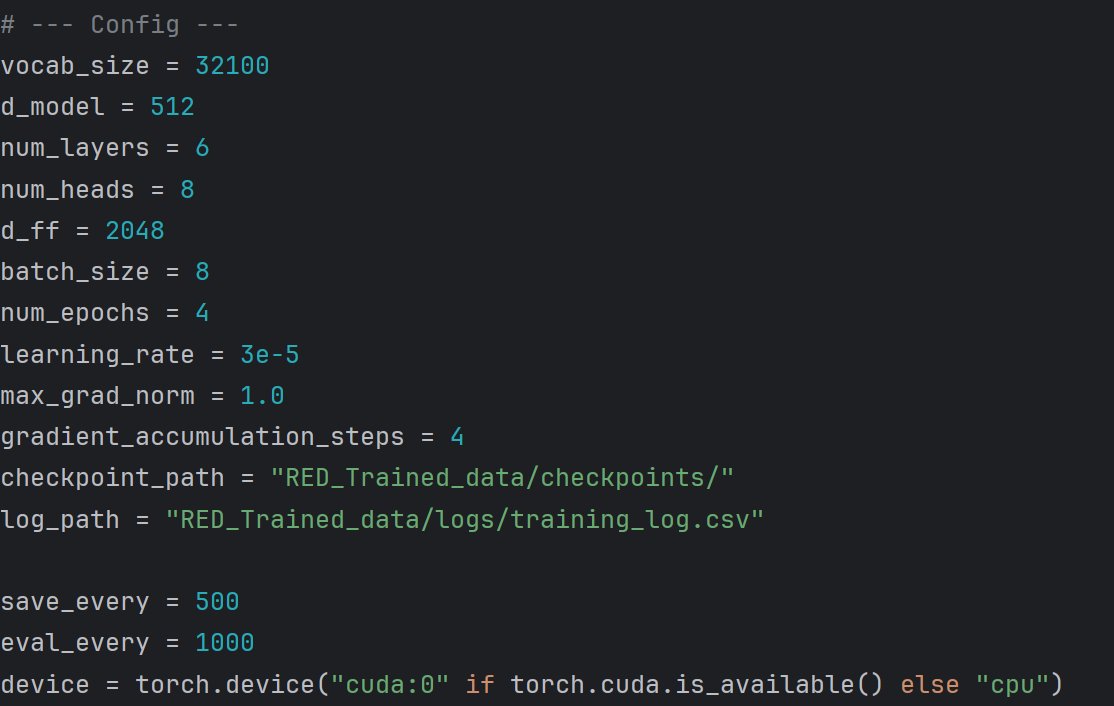
MDSP RESEARCH PAPER IS NOW LIVE! After months of research and real-world validation through Project Red, I’m excited to share my new paper:
Multi-Dimensional Strategic Planning (MDSP): A Formal Framework for High-Resilience Collaborative SystemsA structured maturity model that turns fragile 1D plans into robust 4D architectures — with built-in Resilience Rooms for error isolation and continuous improvement.
Full paper available here:
ResearchGate → researchgate.net/publication…
Academia.edu → academia.edu/166212366/MDSP_…
arXiv → Comming Soon
DOI → 10.13140/RG.2.2.19153.08801
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more
#AI #StrategicPlanning #Resilience #LLM #OpenSource #IndiaTech
1
45
Seeing raw math and physics parameters translate into precise 3D geometry for the first time is an incredible feeling.
We just generated the first functional Rao’s nozzle 3D model using Red CEM. It’s fully parametric, built entirely on C# picoGK, and goes from thrust/fuel specs to high-precision geometry in seconds.
It's very early stages, but the foundational pipeline is holding up beautifully.
A few angles of the initial mesh generation below. Full architecture breakdown in the replies. 👇
#Aerospace #ComputationalEngineering #SpaceTech #BuildInPublic


1
7
While Crimson-1 is running in the background, I started building a pipeline to automate rocket engine design.
Meet Red CEM (Computational Engineering Model) — currently in its initial stages.
You feed it the constraints (thrust, fuel type, weight, materials), and it calculates, optimizes, and outputs a complete 3D Rao’s nozzle geometry ready for simulation.
From raw specs to a 3D mesh in a single pipeline.
Early days, but the foundation is solid. Tracking progress daily.
Full breakdown on LinkedIn (link in bio)
#Aerospace #BuildInPublic #ComputationalEngineering #Python #SpaceTech
1
17
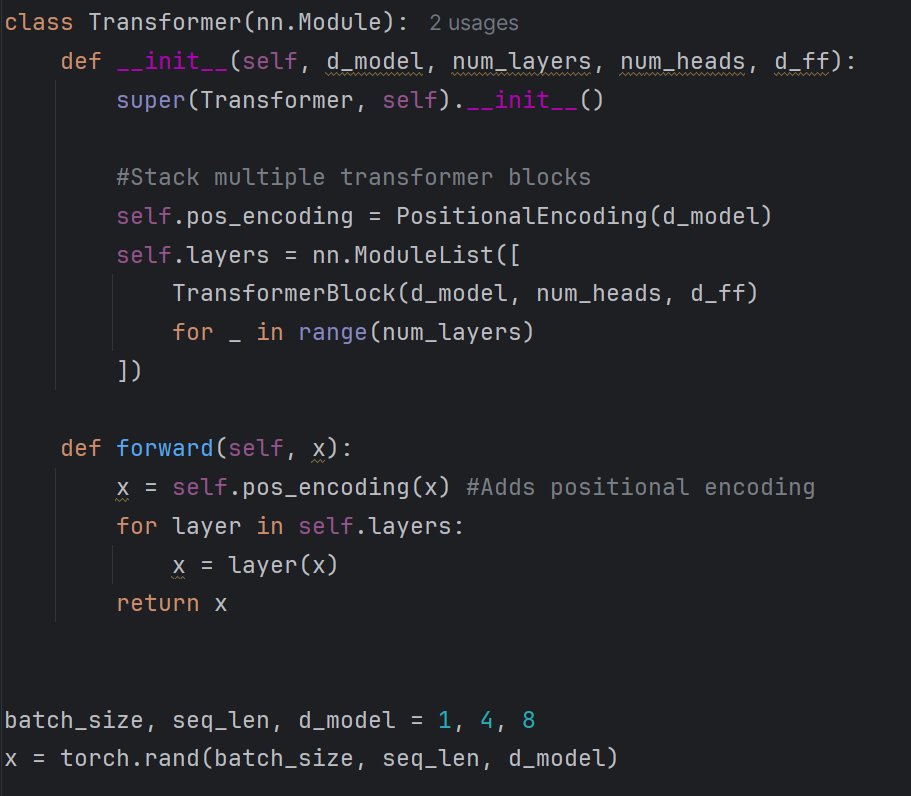
ENCODER WAS BEING IGNORED IN CRIMSON-1❌
While training Red Crimson-1, I discovered the decoder had become too dominant — the encoder was barely contributing.
Fixed it by forcing real cooperation: passing corrupted text through the encoder and reconstructing with the decoder (classic strategy) several proprietary architectural changes to balance the enc-dec ratio.
The model is now training with proper encoder-decoder collaboration.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more 📷
#AI #MachineLearning #LLM #PyTorch #IndiaTech
1
11
Starting September 2026, Google will block any Android app whose developer hasn't registered and provided government ID. This affects every Android device worldwide. Learn more: keepandroidopen.org @AlteredDeal #KeepAndroidOpen
1
18
STABILIZING ARCHITECTURE REVEALED A GRADIENT NUKE 💥
Average grad norm in my 350M model is hitting 100k–14M during normal batches while a 300B model only sees 3k–5k and a normal small model stays under 1k.
Normal clipping can’t fix this. It’s a deep architectural iceberg that can destroy the entire model.
Now doing full in-depth analysis of every layer.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more
#AI #MachineLearning #LLM #PyTorch #IndiaTech
2
37
MY MODEL JUST LOST 3 WEEKS OF TRAINING ☠️
After the latest upgrades, encoder decoder training became extremely unstable like balancing on a knife edge. Most people suggest training them separately, but that’s too slow and expensive on my hardware.
Now exploring lighter ways to stabilize joint training without full reset.Stay tuned for daily updates
Follow for more
#AI #LLM #PyTorch #Pretraining #IndiaTech
2
41
NEW 32K BPE TOKENIZER MAJOR UPGRADES DONE
Just completed a clean 32k vocabulary BPE tokenizer from scratch and implemented several major architectural pipeline upgrades.
It’s finally working decently — stable training, proper tokenization, and better flow.
Still a few minor bugs left to squash.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more
#AI #LLM #Tokenizer #PyTorch #BuildInPublic
2
32
MONTH OF TWEAKS REVEALED MORE PROBLEMS
Tokenizer collapse with corrupted tokens, span corruption broken (objective mismatch), encoder being ignored — model behaving like pure decoder-only.
And several other hidden issues.
It’s time for major architectural upgrades and fixes.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more
#AI #MachineLearning #LLM #PyTorch #Pretraining #IndiaTechCharacter
2
30
CAUSAL LM & SFT RESET MY PROGRESS 💥
Tried causal LM and SFT, seemed like improvement at first, but the model learned nothing real.
Weeks of training vanished in an instant: weights were at random init, no tained knowledge ❌
Now digging deep into the architecture to hunt and fix hidden bugs.
Cybersec student in India rebuilding from the core.
Stay tuned for daily chaos & comebacks
Full details on LinkedIn (link in bio)
Follow for more 🇮🇳
#AI #LLM #PyTorch #BuildInPublic #IndiaTech
2
36
PREFIX LM RUINED CRIMSON-1 ❌
Prefix LM caused the model to assign 49-50% confidence to PAD token (id=0, blank space). Tried fixing it but model broke completely, generated random noisy output. GPT-style prefix LM also failed on this encoder-decoder arch.
Asked @deepseek_ai @ChatGPTapp @claudeai @GeminiApp for suggestions. Claude said switch to decoder-only (encoder-decoder can't make real LLMs). Gemini disagreed, said encoder-decoder can be better but needs proper training.
DeepSeek suggested: 70k span corruption pretraining already done decent output → start fine-tuning now. ChatGPT agreed with DeepSeek but advised trying causal LM first.
That's exactly what I'm doing next.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more 🇮🇳
#AI #MachineLearning #LLM #PyTorch #Pretraining #IndiaTech
2
42
CRIMSON-1 HIT 70K STEPS - GRAMMAR IS STILL BROKEN
Pretraining with span corruption complete: model now attempts full sentences with proper structure. Success is partial - syntax is emerging, but coherence and grammar rules are inconsistent at best. Time to explicitly teach Crimson-1 grammar.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more
#AI #MachineLearning #LLM #Pretraining #PyTorch #IndiaTechCharacter
2
27
PRETRAINING ON 22M MODEL COMPLETED SUCCESSFULLY !✅
The small test run finished cleanly loss behaved, no crashes, gradients stayed sane.
Crimson-1 Mini training now begins.
But there’s a new bottleneck: not the code, not the GPU, but Windows WSL itself. Scripts are fully optimized and maxed out the OS layer is throttling everything.
Stay tuned for weekly updates
Full details on LinkedIn (link in bio)
Follow for more ! 🇮🇳
#AI #MachineLearning #LLM #PyTorch #Pretraining #IndiaTechCharacter
2
27
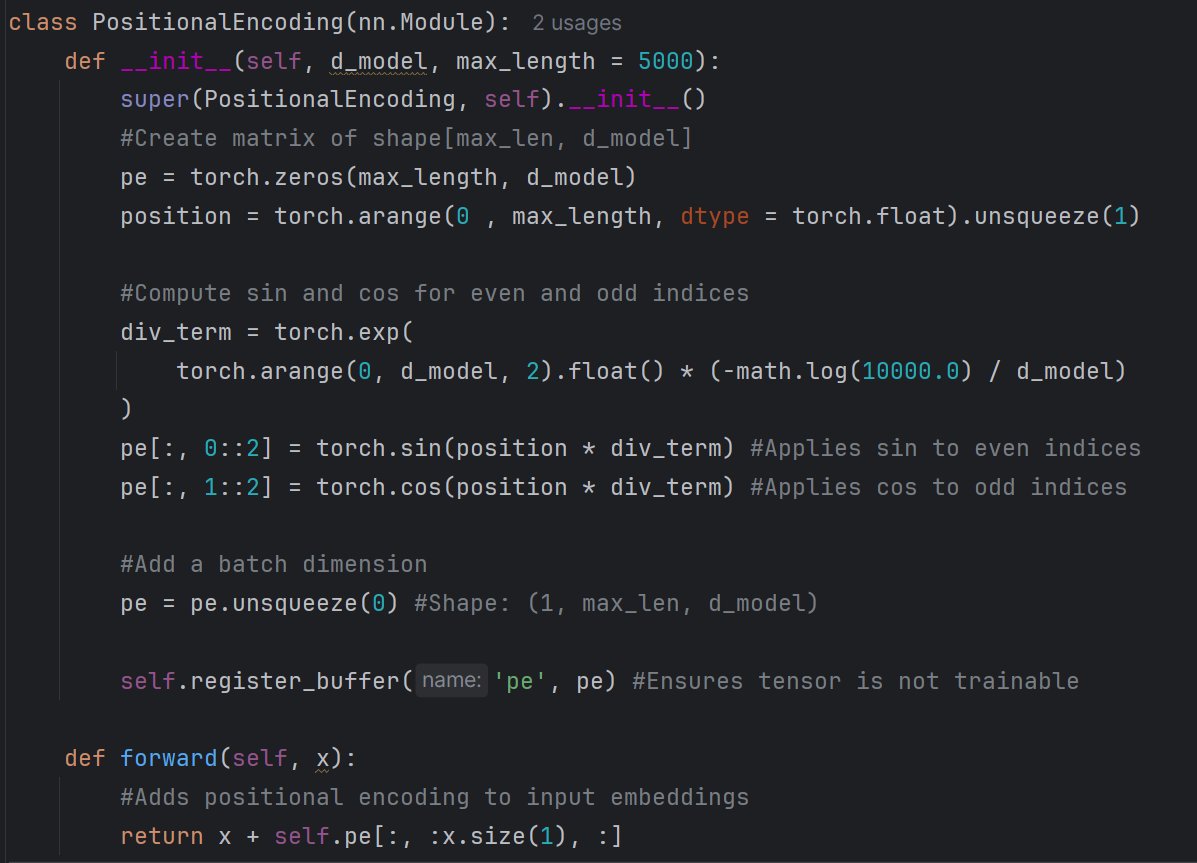
I Built a Custom 16k Tokenizer from Scratch
After several iterations, the new tokenizer is complete and has been fully tested perfect tokenization, clean vocab coverage, no edge-case failures.
It is now the default tokenizer for Crimson-1.
Pretraining phase officially begins today.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more 🇮🇳
#AI #MachineLearning #LLM #Tokenizer #Pretraining #IndiaTech
2
24
I Improved the Script, GPU Usage Stable at 7GB Max
After heavy optimization, the 407M parameter model now trains reliably with peak GPU consumption locked at 7GB (RTX 4060).
I also redesigned the custom T5 architecture from the ground up. It outperforms the default T5 and other variants (including @GoogleAI Gemma's T5 and PaLM T5) in stability, efficiency, and convergence speed.
Named it Crimson.
Stay tuned for daily updates
Full details on LinkedIn (link in bio)
Follow for more 🇮🇳
#AI #MachineLearning #LLM #PyTorch #DeepLearning #IndiaTech
2
25
WINDOWS TRAINING WAS A NIGHTMARE
Switched to WSL2 Ubuntu after endless memory leaks and crashes ate 20GB VRAM on simple runs.
Now debugging every script line-by-line hunting blocks, fixing cache overflows, and sealing leaks for good.
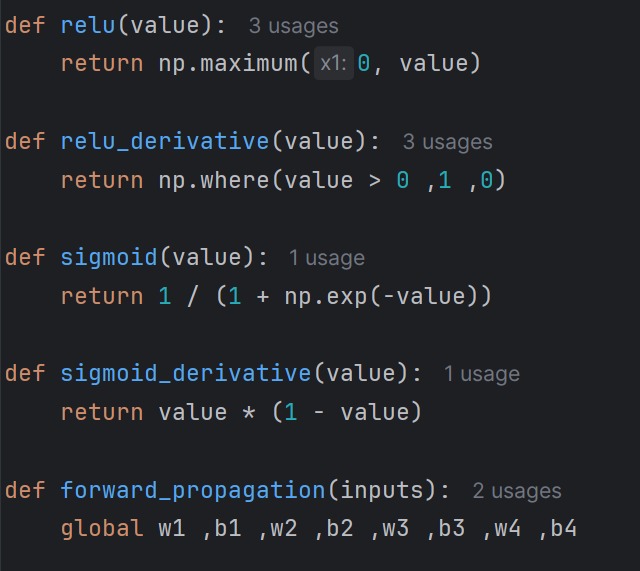
Also upgrading T5 arch: swapping ReLU for SiLU, adding RMSNorm gates, and reliability tweaks to lock in stability.
Cybersec student in India making the model unbreakable. Stay tuned for daily chaos & comebacks
Full details on LinkedIn (link in bio)
Code updates → github.com/RedAILabs/RED
Follow for more
#AI #LLM #PyTorch #BuildInPublic #IndiaTechCharacter #Transformers
2
45
I Built a Checkpoint Scaling Framework That Actually Works
After months of failures, REGENAURAv1.3 is live on GitHub, free for anyone building LLMs from scratch.
Key features:
- Upscale/downscale checkpoints without corruption
- Handles parameter changes seamlessly
- Inspired by SSAA/DLSS for neural weights
This saves weeks of retraining time.
If you're in AI dev, star it & try it out:
github.com/RedAILabs/REGENAU…
What's your biggest LLM training pain? Reply below.
#AI #MachineLearning #LLM #PyTorch #OpenSource #BuildInPublic #IndiaTechCharacter
2
24
REGENAURA BETA JUST DID THE IMPOSSIBLE ✅
Successfully downscaled DeepSeek 7B → 70M parameters using REGENAURA beta! No damage to the original teacher model pure distillation magic: Reduced tensor sizes safely (no corruption)
Trained the tiny 70M student with teacher guidance
Full student-teacher setup knowledge transfer without touching DeepSeek itself
Cybersec student in India turning massive models into pocket-sized beasts. Stay tuned for daily chaos & comebacks
Full details on LinkedIn (link in bio)
Stable code coming soon from REGENAURA v0.3 → github.com/RedAILabs/RED
Follow for more 🇮🇳
#AI #LLM #Distillation #PyTorch #DeepSeek #BuildInPublic #IndiaTech
2
43
REGENAURA PASSED ALPHA TESTING! !✅
After tons of crashes and tweaks, my upscaling/downscaling framework REGENAURA (Regenerative Expansion & Gradient-Enhanced Neural Adaptive Upscaling & Rescaling Algorithm) finally survived alpha testing clean migration, no corruption, weights transfer like butter.
Cybersec student in India turning checkpoint nightmares into smooth scaling magic.
Alpha & beta code too unstable for public eyes staying locked until stable.
Source code drops on GitHub only from REGENAURAv0.3 onward.
Stay tuned for daily chaos & comebacks
Full details on LinkedIn (link in bio)
Stable code coming soon → github.com/RedAILabs/RED
Follow for more 🇮🇳
#AI #LLM #PyTorch #BuildInPublic #IndiaTech #OpenSource
2
29